Locust 测试结果通过Matplotlib生成趋势图
目的:
相信大家对于使用Loadrunner测试后的结果分析详细程度还是有比较深刻的感受的,每个请求,每个事务点等都会有各自的趋势指标,在同一张图标中展示。如下图:
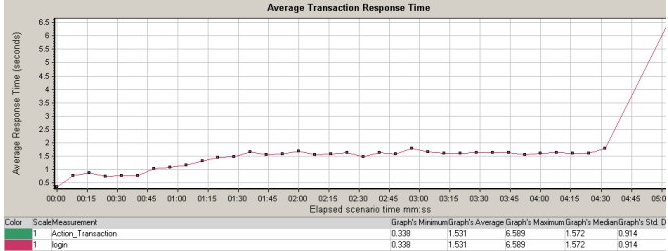
而Locust自身提供的chart趋势图缺很简单,如下图:
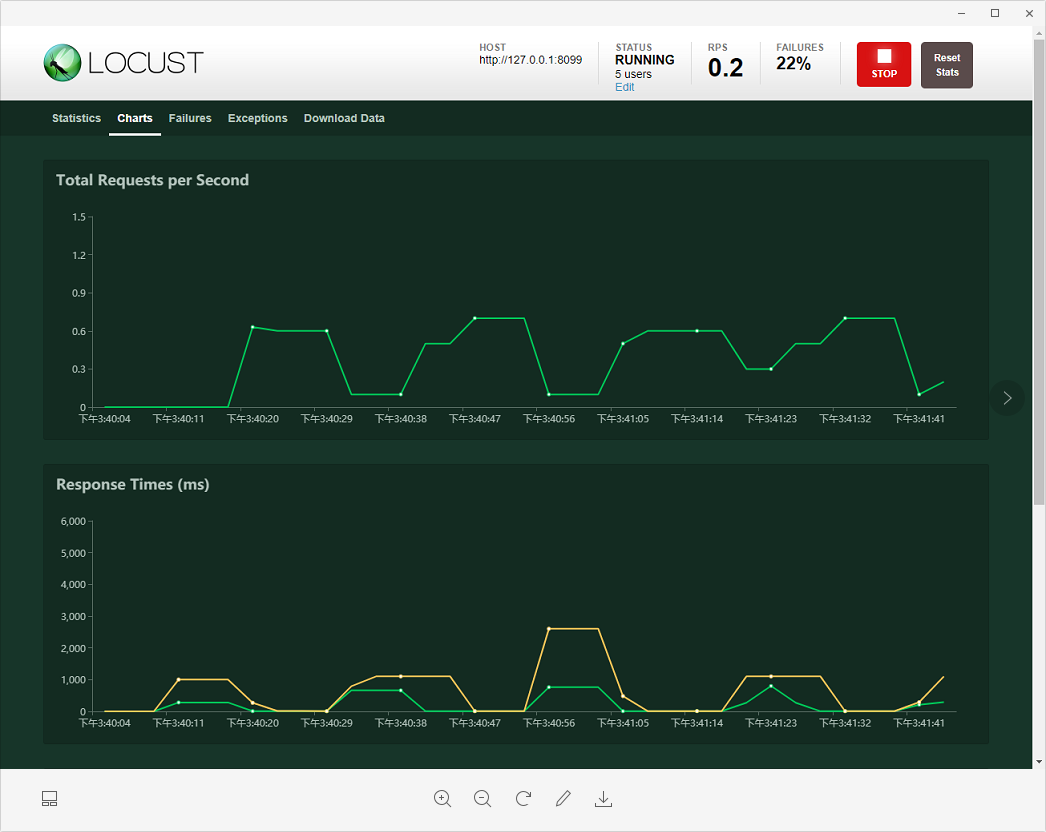
那么要达到Loadrunner对于每个请求的详细的描述,用locust能否实现呢?
答案是肯定的,那么我们想到就开始做!
思路:
我们整理一下思路,按照步骤去达到我们的目的:
1. 首先我们需要知道每个请求的响应时间
2. 我们需要把每个请求的响应时间进行数据整理和拆分
3. 我们需要把整理好的数据生成图表
实施:
按照初步的思路,我们来按步骤进行实施:
1. 抓取每个请求的响应时间。
我们需要获取每个请求的响应时间,可以通过Locust本身自带的钩子函数打印成日志文件。

具体代码如下:
#!/usr/bin/python3.6
# -*- coding: UTF-8 -*-
# author:Lucien
# 基础包: 压力Log日志封装
from locust import events
import os
import time
import logging
from logging.handlers import RotatingFileHandler class loadLogger():
def __init__(self, filePath, fileName):
self.filePath = filePath # 存放文件的路径
self.fileName = fileName # 存放文件的名字
self.BACK_UP_COUNT = 5000 # 文件分割上限数
self.MAX_LOG_BYTES = 1024 * 1024 * 1 # 单个文件最大记录数1M
self.create_handler() # 初始化创建日志handler
self.create_logger() # 初始化创建Logger def create_handler(self): # 建立handler
self.success_handler = RotatingFileHandler(filename=os.path.join(self.filePath, self.fileName),
maxBytes=self.MAX_LOG_BYTES * 100, backupCount=self.BACK_UP_COUNT,
delay=1) # 分割文件处理按100m分割
formatter = logging.Formatter('%(asctime)s | %(name)s | %(levelname)s | %(message)s') # 设定输出格式
formatter.converter = time.gmtime # 时间转换
self.success_handler.setFormatter(formatter) # 格式加载到handler def create_logger(self): # 建立Logger
self.success_logger = logging.getLogger('request_success')
self.success_logger.propagate = False
self.success_logger.addHandler(self.success_handler) def success_request(self, request_type, name, response_time, response_length): # 成功日志输出格式加载到Logger中
msg = ' | '.join([str(request_type), name, str(response_time), str(response_length)])
self.success_logger.info(msg) def get_locust_Hook(self): # 钩子挂载到Locust中
events.request_success += self.success_request
以上为封装好的Log日志输出
在并发时带入log日志输出为本地文件存放,代码如下:
# !/usr/bin/python3.6
# -*- coding: UTF-8 -*-
# author: lucien
# 基础包: locust趋势图生成包
from locust import TaskSet, task, HttpLocust
from Performance_Core.performance_log import loadLogger
import os class file_server_stress(TaskSet):
def on_start(self):
'''警号,部门编号等'''
self.deptID = ''
self.pcMemberID = ''
self.phoneMemberID = ''
self.logger = loadLogger(filePath='E:\\PrintLog', fileName='11-12-logs') # 上传文件
@task(1)
def update_file(self):
payload = "xxx"
url = ':6061/file/upload/file'
headers = {
'content-type': "multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW",
'Cache-Control': "no-cache",
'Postman-Token': "9889c0b4-b91c-4b23-a713-cae4d60e623a"
}
response = self.client.post(url=url, data=payload, headers=headers, name='update_file', catch_response=True,
timeout=20)
print(response.text)
# 验证请求成功与失败
if response.status_code == 200:
self.logger.get_locust_Hook() #重点!此处挂载Log日志钩子
response.success()
else:
self.logger.get_locust_Hook()
response.failure('上传文件失败') class userbehavior(HttpLocust):
host = 'http://192.168.1.222'
task_set = file_server_stress
min_wait = 3000
max_wait = 5000 if __name__ == '__main__':
'''网页启动,在网页中输入127.0.0.1:8089'''
os.system('locust -f file_server_stress.py --web-host=127.0.0.1')
运行完测试后,我们将会得到一组log日志文件,样式如下:
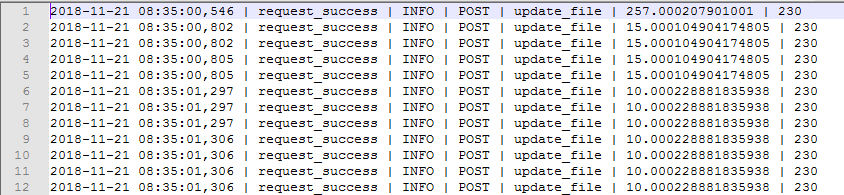
第一步顺利完成!
2. 对日志文件进行数据分析和拆分
我们所得到的所有日志记录都会混合在日志文件中,我们需要把它提取出来,并且通过groupby来拆分不同的请求
提取日志文件,我们可以用到python的强项,数据分析支持库Pandas和Numpy
首先,我们通过Pandas提取日志文件:
headers = ['time', 'label', 'loglevel', 'method', 'name', 'response_time', 'size']
self.data = pandas.read_csv(filename, sep='|', names=headers)
读取日志文件后生成DATAFRAME的pandas数据独有格式
其次,我们通过对读取的文件处理后进行排序
self.sorted_data = self.data.sort_values(by=['time', 'name'], ascending=[True, True])
按时间和请求名称,将序排列
最后,我们对排序后的数据进行分组
self.grouped_data = self.sorted_data.groupby('name')
自此,我们数据处理工作大体准备完成
3.把数据生成图表
需要把数据生成图表,自然离不开matplotlib了
按照matplolib里,plot方法,把x轴和y轴 按照time 和 response_time 生成相应的折线图,最后生成的趋势图如下:
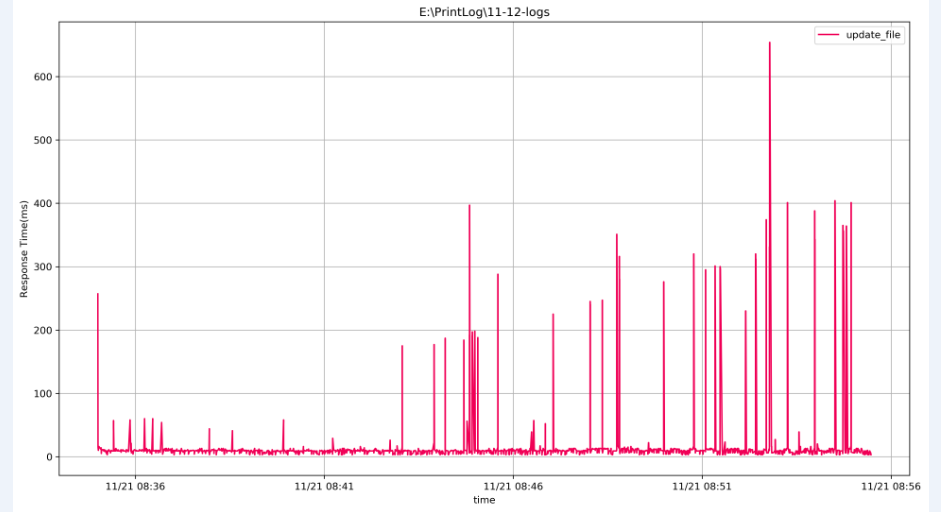
大功告成!
最后附上实际代码,供有需要的同学参考,也可以自行改良:
# !/usr/bin/python3.6
# -*- coding: UTF-8 -*-
# author: lucien
# 基础包: locust趋势图生成包
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import dates hex_colors = [
'#FF7500',
'#F00056',
'#0EB83A',
'#00BC12',
'#1BD1A5',
'#0C8918',
'#0AA344',
'#2ADD9C',
'#3DE1AD',
'#424C50',
'#DB5A6B',
'#FF4E20',
'#3EEDE7',
'#4B5CC4',
'#70F3FF',
'#2E4E7E',
'#3B2E7E',
'#425066',
'#8D4BBB',
'#815476',
'#808080',
'#161823',
'#50616D',
'#725E82',
'#A78E44',
'#8C4356',
'#F47983',
'#B36D61',
'#C93756',
'#FF2121',
'#C83C23',
'#9D2933',
'#FFF143',
'#FF0097',
'#A98175',
'#C32136',
'#6E511E',
'#F20C00',
'#F9906F',
'#FF8936',
'#DC3023',
'#EAFF56',
'#FFA400',
'#60281E',
'#44CEF6',
'#F0C239',
'#A88462',
'#B35C44',
'#B25D25',
'#C89B40',
'#D9B611',
'#827100',
'#C3272B',
'#7C4B00',
'#BDDD22',
'#789262',
'#FF8C31',
'#C91F37',
'#00E500',
'#177CB0',
'#065279',
] class data_analyse():
def __init__(self, filename):
self.filename = filename
self.xfmt = dates.DateFormatter('%m/%d %H:%M')
self._init_graph() # 初始化趋势图大小
self._set_graph() # 初始化趋势图样式 headers = ['time', 'label', 'loglevel', 'method', 'name', 'response_time', 'size'] # 命名字段标题
self.data = pd.read_csv(filename, sep='|', names=headers) # 从文件获取内容为DATAFRAME格式
for col in headers[-2:]: # 转换response_time和size为int型
self.data[col] = self.data[col].apply(lambda x: int(x))
for col in headers[0:-2]: # 取消掉所有非int型的空格
self.data[col] = self.data[col].apply(lambda x: x.strip())
self.data['time'] = self.data['time'].apply(
lambda x: datetime.strptime(x, '%Y-%m-%d %H:%M:%S,%f')) # time转化为时间格式
self.sorted_data = self.data.sort_values(by=['time', 'name'], ascending=[True, True]) # 对数据按照time和name进行降序排列
self.grouped_data = self.sorted_data.groupby('name') # 对降序排列的数据,按名称分组
self.requests_counts = np.array([[key, len(group)] for key, group in self.grouped_data]) # 构建请求名和请求次数数组 def _init_graph(self): # 设定趋势图大小
left, width = 0.1, 0.8
bottom, height = 0.1, 0.8
self.trend_scatter = [left, bottom, width, height] def _set_graph(self): # 生成基本趋势图样式
plt.clf() # 清除figure中所有axes
self.ax_plot = plt.axes(self.trend_scatter) # 套用axes大小
self.ax_plot.grid(True) # 打开网格
self.ax_plot.set_ylabel('Response Time(ms)') # 纵坐标标题
self.ax_plot.set_xlabel('time') # 横坐标标题
self.ax_plot.figure.set_size_inches(15, 8) # 画板大小
self.ax_plot.xaxis.set_major_locator(dates.MinuteLocator(interval=5)) # 设定横坐标日期格式为5min间隔
self.ax_plot.xaxis.set_major_formatter(self.xfmt) # 设定横坐标格式 def generate_trend(self): # 生成趋势图
start_index = 0
legend_list = []
for index, request in enumerate(self.requests_counts): # 为数组添加index标签
name, count = request[0], int(request[1]) # 获取请求名和请求次数
end_index = start_index + count
x = self.grouped_data.get_group(name)['time'][start_index: end_index] # 设置x轴数据
y = self.grouped_data.get_group(name)['response_time'][start_index:end_index] # 设置y轴数据
self.ax_plot.plot(x, y, '-', color=hex_colors[index + 1]) # 画图
legend_list.append(name) # 添加请求名到legend中
plt.legend(legend_list) # 打印legend
# plt.show() # 打印趋势图
plt.title(self.filename)
plt.savefig(fname='.'.join([self.filename, 'png']), dpi=300, bbox_inches='tight') # 保存趋势图 if __name__ == '__main__':
data = data_analyse('E:\\PrintLog\\logs')
print(data.sorted_data.info())
# data.generate_trend()
如要转载,请标明出处
Locust 测试结果通过Matplotlib生成趋势图的更多相关文章
- python3 读取txt文件数据,绘制趋势图,matplotlib模块
python3 读取txt文件数据,绘制趋势图 test1.txt内容如下: 时间/min cpu使用率/% 内存使用率/% 01/12-17:06 0.01 7.61 01/12-17:07 0.0 ...
- tensorflow 升级到1.9-rc0,生成静态图frozen graph.pb本地测试正常, 在其他版本(eg1.4版本)或者android下运行出错NodeDef mentions attr 'dilations' not in Op<name=Conv2D; signature=input:T, filter:T -> output:T; attr=T:type,allowed=[DT_
这时节点定义找不到NodeDef attr 'dilations' not in,说明执行版本的NodeDef不在节点定义上,两个不一致,分别是执行inference的代码和生成静态图节点不一致(当然 ...
- tpcc-mysql安装测试与使用生成对比图
1:下载tpcc-mysql的压缩包,从下面的网站进行下载 https://github.com/Percona-Lab/tpcc-mysql 也可直接从叶总博客直接下载: http://imysql ...
- 利用powerdesigner反向数据库结构,生成ER图
参考月下狼~图腾~:<利用powerdesigner反向数据库结构,生成ER图> https://www.zybuluo.com/Jpz/note/123582 首先新建一个"P ...
- matplotlib 生成 eps 插入到 tex
matplotlib 生成 eps 插入到 tex matplotlib 生成 eps,就可以插入到 tex 中,而且是矢量图,放大不失真. 而且因为图中的元素都是嵌入到 pdf 中,所以图中的文字也 ...
- Selenium HTMLTestRunner 执行测试成功但无法生成报告
为什么用PyCharm或者Eclipse执行测试成功但无法生成HTMLTestRunner报告 最近遇到一些人问这样的问题: 他们的代码写的没问题,执行也成功了,但就是无法生成HTMLTestRunn ...
- 【PowerDesigner】【4】连接数据库并生成ER图
文字版: 1,File→Reverse Engineer→Database...., 2,新窗口database reverse engineering打开后,填写名称(Model name),选择数 ...
- 用python做自己主动化測试--绘制系统性能趋势图和科学计算
在性能測试中.我们常常须要画出CPU memory 或者IO的趋势图. 预计大学里.大多数人都学习过matlib, 领略了matlib绘图的强大. python提供了强大的绘图模块matplotlib ...
- WPF数据可视化-趋势图
环境: 系统: Window 7以上: 工具:VS2013及以上. 研发语言及工程: C# WPF 应用程序 效果: 简介: 不需要调用第三方Dll, 仅仅在WPF中使用贝塞尔曲线,不到500 ...
随机推荐
- MVC ---- ckeditor 批量绑定 blur 事件
在项目遇到个问题,就是把循环出来的ckeditor 批量添加 blur 事件,折腾了2天 终于搞定 @{ ].Rows) { <table class="ui-jqgrid-btabl ...
- BZOJ 2669 【CQOI2012】 局部极小值
题目链接:局部极小值 这是一道\(dp\)好题. 由于需要保证某些位置比周围都要小,那么我们可以从小到大把每个数依次填入,保证每个局部极小值填入之前周围都不能填,就只需要在加入的时候计数了. 由于局部 ...
- vijos1904 学姐的幸运数字
本文版权归ljh2000和博客园共有,欢迎转载,但须保留此声明,并给出原文链接,谢谢合作. 本文作者:ljh2000 作者博客:http://www.cnblogs.com/ljh2000-jump/ ...
- js 捕捉滚轮的滚动
滚动方向区分为正负: <!DOCTYPE html> <html> <head lang="en"> <meta charset=&quo ...
- DEV-C++设置C++11标准
DEV-C++默认的标准是C++98,改成C++11的方法如下: Tools -> Compiler Options -> Setting -> Code Generation -& ...
- jenkins 插件,下载地址
http://updates.jenkins-ci.org/download/plugins/ 通常我们需要下载的插件有如下几个:
- 《F4+2团队项目需求改进与系统设计》
任务一 a.分析<动态的太阳系模型项目需求规格说明书>初稿的不足. 任务概述描述的有些不具体,功能的规定不详细,在此次作业进行了修改. b.参考<构建之法>8.5节功能的定位和 ...
- MongoDB分片集群环境搭建记录
--创建配置服务器mongod.exe --logpath "G:\USERDATA\MONGODB\Test2\Log\mongodb.log" --logappend --db ...
- Appium 坑
1. [Android]click没有反应 https://testerhome.com/topics/9610 在某些手机上有个安全选项,需要在开发者选项->安全设置(允许模拟点击),打开开关
- 牛客练习赛22-C-dp+bitset
链接:https://www.nowcoder.com/acm/contest/132/C来源:牛客网 题目描述 一共有 n个数,第 i 个数是 xi xi 可以取 [li , ri] 中任意的一个 ...