python编码问题总结
最近利用python抓取一些网上的数据,遇到了编码的问题。非常头痛,总结一下用到的解决方案。
- linux中vim下查看文件编码的命令 set fileencoding
- python中一个强力的编码检测包 chardet ,使用方法非常简单。linux下利用pip install chardet实现简单安装
import chardet
f = open('file','r')
fencoding=chardet.detect(f.read())
print fencoding
fencoding输出格式 {'confidence': 0.96630842899499614, 'encoding': 'GB2312'} ,只能判断是否为某种编码的概率。比较准确的结果了。输入参数为str类型。
- 了解python中str的编码后可以利用decode和encode来实现编码的转换。
一般流程是str利用decode方法根据str的编码将其解码为unicode字符串类型,然后利用encode根据特定的编码将unicode字符串类型转换为特定的编码。python中str和unicode属于两种不同的类型,如下。
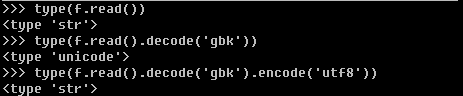
- 一般情况下window默认编码gbk,linux默认编码utf8
- python编程中 系统编码,python编码,文件编码 的概念。
系统编码:默认写源码的编辑器的编码方式。它代表源码文件内的所有内容都是根据词方式编码成二进制码流。存入到磁盘中的。linux下通过locale命令查看。
python编码:指python内设置的解码方式。如果不设定的话,python默认的是ascii解码方式。如果python源代码文件中不出现中文的话,这个地方怎么设定应该不会问题。
设定方法:在源码文件开头(一定是第一行):#-*-coding:UTF-8-*-,源码文件的设置解码方式是UTF-8 或者
import sys
reload(sys)
sys.setdefaultencoding('UTF-8')
文件编码:文本的编码方式,linux下vim利用set fileencoding查看。
- 一般情况下输出乱码的原因就是 没有按照系统解码的方式进行编码。
比如print s, s类型为str,linux系统下系统默认编码为utf8编码,s在输出前就应该编码为utf8。如果s为gbk编码就应该这样输出。print s.decode('gbk').encode('utf8')才能输出中文。
window下面情况相同,window默认编码为gbk编码,所以s输出前必须编码为gbk。
- python处理中一般处理unicode类型。这样输出前直接编码即可。
python编码问题总结的更多相关文章
- (转载) 浅谈python编码处理
最近业务中需要用 Python 写一些脚本.尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些,我还是决定用中文输出日志信息. 很快,我就遇到了异常: UnicodeEncodeError: ...
- Python 编码简单说
先说说什么是编码. 编码(encoding)就是把一个字符映射到计算机底层使用的二进制码.编码方案(encoding scheme)规定了字符串是如何编码的. python编码,其实就是对python ...
- Python之路3【知识点】白话Python编码和文件操作
Python文件头部模板 先说个小知识点:如何在创建文件的时候自动添加文件的头部信息! 通过:file--settings 每次都通过file--setings打开设置页面太麻烦了!可以通过:View ...
- python编码规范
python编码规范 文件及目录规范 文件保存为 utf-8 格式. 程序首行必须为编码声明:# -*- coding:utf-8 -*- 文件名全部小写. 代码风格 空格 设置用空格符替换TAB符. ...
- 【转】python编码的问题
摘要: 为了在源代码中支持非ASCII字符,必须在源文件的第一行或者第二行显示地指定编码格式: # coding=utf-8 或者是: #!/usr/bin/python # -*- coding: ...
- 【转】python编码规范
http://blog.csdn.net/willhuo/article/details/49300441 决定开始Python之路了,利用业余时间,争取更深入学习Python.编程语言不是艺术,而是 ...
- python 编码 UnicodeDecodeError
将一个py脚本从Centos转到win运行,出错如下: UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: il ...
- Python编码/文件读取/多线程
Python编码/文件读取/多线程 个人笔记~~记录才有成长 编码/文件读取/多线程 编码 常用的一般是gbk.utf-8,而在python中字符串一般是用Unicode来操作,这样才能按照单个字 ...
- 关于Python编码,超诡异的,我也是醉了
Python的编码问题,真是让人醉了.最近碰到的问题还真不少.比如中文文件名.csv .python对外呈现不一致啊,感觉好不公平. 没图说个JB,下面立马上图. 我早些时候的其他脚本,csv都是 ...
- 规范的python编码
规范的 python 编码令人赏心悦目,令代码的表达逻辑更清晰,使得工程代码更容易被维护和交流: 编码规范包括对于代码书写格式的约束,不良语法的禁用和推荐的编码手法,下面做些简要的描述: 1. 代码规 ...
随机推荐
- 通过NAT转发实现私网对外发布信息
我们可以在防火墙的外部网卡上绑定多个合法IP地址,然后通过ip映射使发给其中某一个IP地址的包转发至内部某一用户的WWW服务器上,然后再将该内部WWW服务器响应包伪装成该合法IP发出的包. 具体的IP ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——重新编译CDH5.0.2 HADOOP点滴
本文参考博文Hadoop2.2.0遇到64位操作系统平台报错,重新编译Hadoop 由于我采用的tarball方式安装hadoop,其lib/native下根本没有内容,启动hdfs时报这个经典的na ...
- sql产生随机时间
--建立过程 CREATE PROCEDURE GetTime @BeginTime VARCHAR(5), @EndTime VARCHAR(5), @RandTime VA ...
- 【matlab】=size(img)的其中两种用法&zeros( )
i1=imread('D:\Work\1.png'); i1=rgb2gray(i1); [m,n]=size(i1); 返回图片的尺寸信息, 并存储在m.n中.其中m中存储的是行数,n中存储的是列数 ...
- 禁止requests请求https的提示InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. For more
提示这个 InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from ...
- pycharm 对代码做静态检查
对于下面这种情况,java c这些提前编译的语言,不给你运行机会就立马报错了,但对于动态语言运行之后才能报错,用运行的方法来检查代码错误是在是太坑了,这是py对比静态语言的巨大劣势,尤其是代码文件多行 ...
- SpringMVC------报错:java.lang.ClassNotFoundException: org.springframework.web.filter.CharacterEncodingFilter
详细信息: java.lang.ClassNotFoundException: org.springframework.web.filter.CharacterEncodingFilter 严重: E ...
- Eclipse------导入项目后出现Java compiler level does not match the version of the installed Java project facet
报错信息:Java compiler level does not match the version of the installed Java project facet 解决方法: 1.点击工具 ...
- SQLServer------基本操作
代码: --新增字段 ) --编辑字段名称 --注意: 更改对象名的任一部分都可能会破坏脚本和存储过程 EXEC sp_rename 'FTTxUser.[Modifiersss]','Creator ...
- Oracle的动态SQL
例1:传递表名,和Where条件删除数据 CREATE OR REPLACE PROCEDURE raise_emp_salary (column_value NUMBER, emp_column V ...