boosting方法
概述
Boosting基本思想: 通过改变训练数据的概率分布(训练数据的权值分布),学习多个弱分类器,并将它们线性组合,构成强分类器。
Boosting算法要求基学习器能对特定的数据分布进行学习,这可通过“重赋权法”(re-weighting)实施。对无法接受带权样本的基学习算法,则可通过“重采样法”(re-sampling)来处理。若采用“重采样法”,则可获得“重启动”机会以避免训练过程过早停止。可根据当前分布重新对训练样本进行采样,再基于新的采样结果重新训练处基学习器。
提升方法AdaBoost算法
1、提升方法的基本思路
(1)提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。未被正确分类的样本受到后一轮弱分类器更大的关注。
(2)AdaBoost 采用加权多数表决,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用。
2、AdaBoost算法


注意:修改: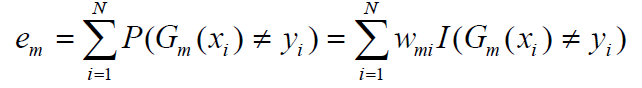
3、一个例子




AdaBoost算法的训练误差分析



AdaBoost算法的解释
1.前向分布算法

2、前向分布算法与AdaBoost算法
AdaBoost算法可以由前向分布算法推导得出,主要依据如下定理:

证明参考这位大神:https://blog.csdn.net/thriving_fcl/article/details/50877957
证明太精彩了,唯一不明白就是样本权值更新公式。
提升树
1、提升树模型
提升树模型可以表示为决策树的加法模型:
其中,
2、提升树算法
用平方误差损失函数的回归问题,用指数损失函数的分类问题,以及用一般损失函数的一般决策问题。
(1)分类问题同上面说过的例子,基分类器换做决策树就行了。下面看一下回归问题:



(2)一个例子



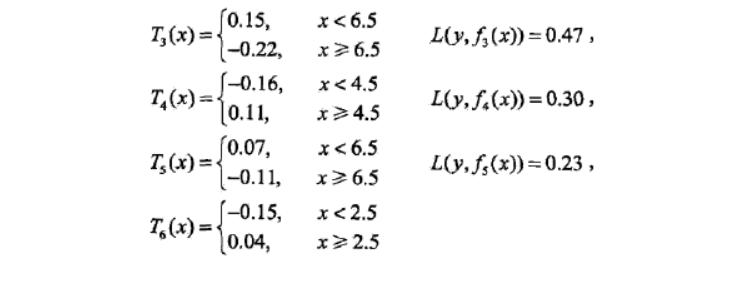

3、梯度提升


总而言之

最后小结一下GBDT算法的优缺点。
优点:
- 预测精度高
- 适合低维数据
- 能处理非线性数据
缺点:
- 并行麻烦(因为上下两棵树有联系)
- 如果数据维度较高时会加大算法的计算复杂度
boosting方法的更多相关文章
- 以Random Forests和AdaBoost为例介绍下bagging和boosting方法
我们学过决策树.朴素贝叶斯.SVM.K近邻等分类器算法,他们各有优缺点:自然的,我们可以将这些分类器组合起来成为一个性能更好的分类器,这种组合结果被称为 集成方法 (ensemble method)或 ...
- 两篇将rf和boosting方法用在搜索排序上的paper
在网上看到关于排序学习的早期文章,这两篇文章大致都使用了Random Forest和Boosting方法. 一.paper 1.Web-Search Ranking with Initialized ...
- 统计学习方法笔记 -- Boosting方法
AdaBoost算法 基本思想是,对于一个复杂的问题,单独用一个分类算法判断比较困难,那么我们就用一组分类器来进行综合判断,得到结果,"三个臭皮匠顶一个诸葛亮" 专业的说法, 强可 ...
- class-提升方法Boosting
1 AdaBoost算法2 AdaBoost训练误差分析3 AdaBoost algorithm 另外的解释3.1 前向分步算法3.2 前向分步算法与AdaBoost4 提升树4.1 提升树模型4.2 ...
- Boosting(提升方法)之AdaBoost
集成学习(ensemble learning)通过构建并结合多个个体学习器来完成学习任务,也被称为基于委员会的学习. 集成学习构建多个个体学习器时分两种情况:一种情况是所有的个体学习器都是同一种类型的 ...
- 集成方法 Boosting原理
1.Boosting方法思路 Boosting方法通过将一系列的基本分类器组合,生成更好的强学习器 基本分类器是通过迭代生成的,每一轮的迭代,会使误分类点的权重增大 Boosting方法常用的算法是A ...
- 常用的模型集成方法介绍:bagging、boosting 、stacking
本文介绍了集成学习的各种概念,并给出了一些必要的关键信息,以便读者能很好地理解和使用相关方法,并且能够在有需要的时候设计出合适的解决方案. 本文将讨论一些众所周知的概念,如自助法.自助聚合(baggi ...
- boosting、adaboost
1.boosting Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数.他是一种框架算法,主要是通过对样本集的操作获 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
随机推荐
- unity3d-物理引擎
简介 物理引擎就是在游戏中模拟真实的物理效果,比如,场景中有两个立方体对象,一个在空中,一个在地面上,在空中的立方体开始自由下落,然后与地面上的立方体对象发生碰撞,而物理引擎就是用来模拟真实碰撞的效果 ...
- Leetcode: Binary Tree Inorder Transversal
Given a binary tree, return the inorder traversal of its nodes' values. For example: Given binary tr ...
- Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- 【转】Java中Synchronized的用法
<编程思想之多线程与多进程(1)——以操作系统的角度述说线程与进程>一文详细讲述了线程.进程的关系及在操作系统中的表现,这是多线程学习必须了解的基础.本文将接着讲一下Java线程同步中的一 ...
- linux常用命令:diff 命令
diff 命令是 linux上非常重要的工具,用于比较文件的内容,特别是比较两个版本不同的文件以找到改动的地方.diff在命令行中打印每一个行的改动.最新版本的diff还支持二进制文件.diff程序的 ...
- 页面点击,不是a标签也会刷新原因
页面点击,不是a标签也会刷新原因 点击事件冒泡,触发了a链接导致整个页面刷新了.直接阻止 事件冒泡即可 例子: $("tr .am-text-danger").click(func ...
- wamp下配置多域名和访问路径的方法
wamp下配置多域名和访问路径的方法 1.到安装目录下,打开配置httpd.confD:\wamp\bin\apache\Apache2.2.21\conf\httpd.conf也可以通过wamp图标 ...
- mysql jdbc性能优化之mybatis/callablestatement调用存储过程mysql jdbc产生不必要的元数据查询(已解决,cpu负载减少20%)
INFO | jvm 1 | 2016/08/25 15:17:01 | 16-08-25 15:17:01 DEBUG pool-1-thread-371dao.ITaskDao.callProce ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 05: 配置yum源
1.1 将镜像复制到本地创建yum源 1.将准备好的系统镜像放到指定的目录,本次目录指定在:/dawnfs/sourcecode 2.创建挂载目录:mkdir /mnt/yum 3.挂载镜像: mou ...