01.SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql
第一次引入文件组的概念:http://www.cnblogs.com/dunitian/p/5276431.html
上次说了其他的解决方案(http://www.cnblogs.com/dunitian/p/6041745.html),就是没有说水平分库,这次好好说下。
上次共享的第一份大数据,这次正好来演示一下水平分库
1.模拟部分数据
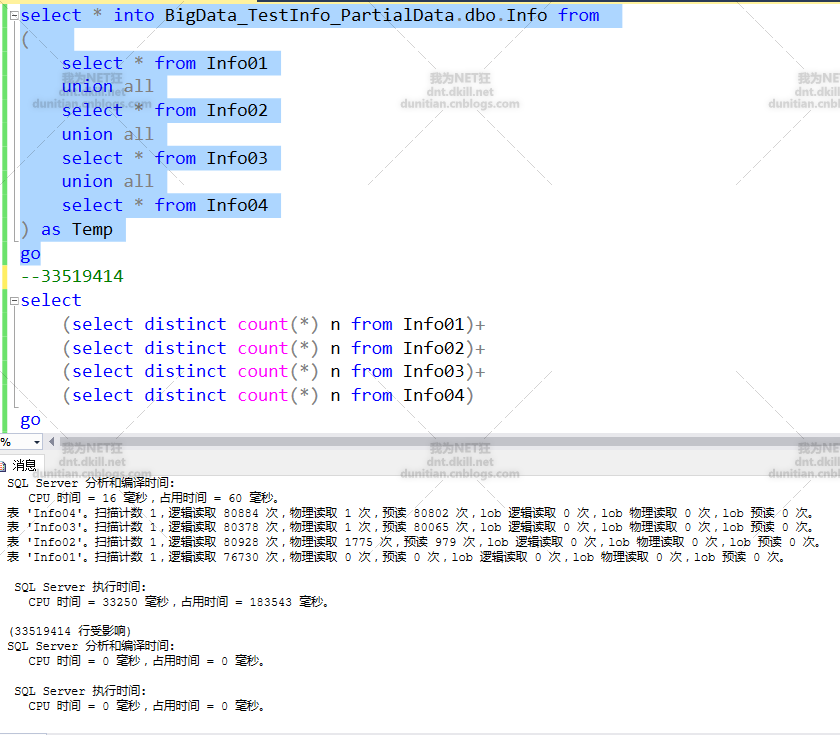
2.创建索引后,发现可以根据日期来分组
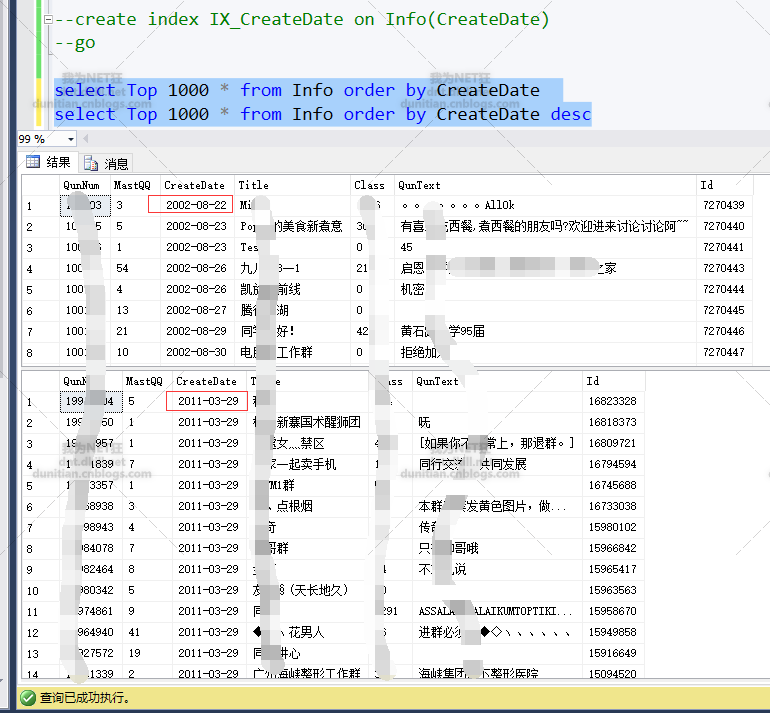
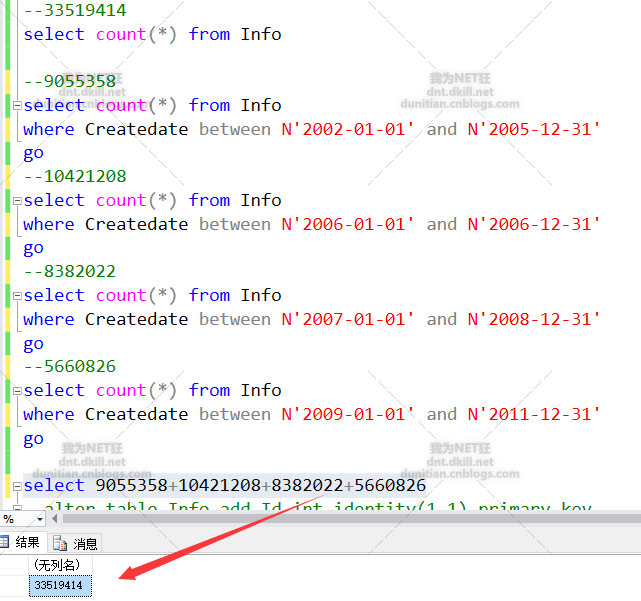
按数据量大致分一下
步入正轨
---------------------------------------------------------------------
GUI方法:
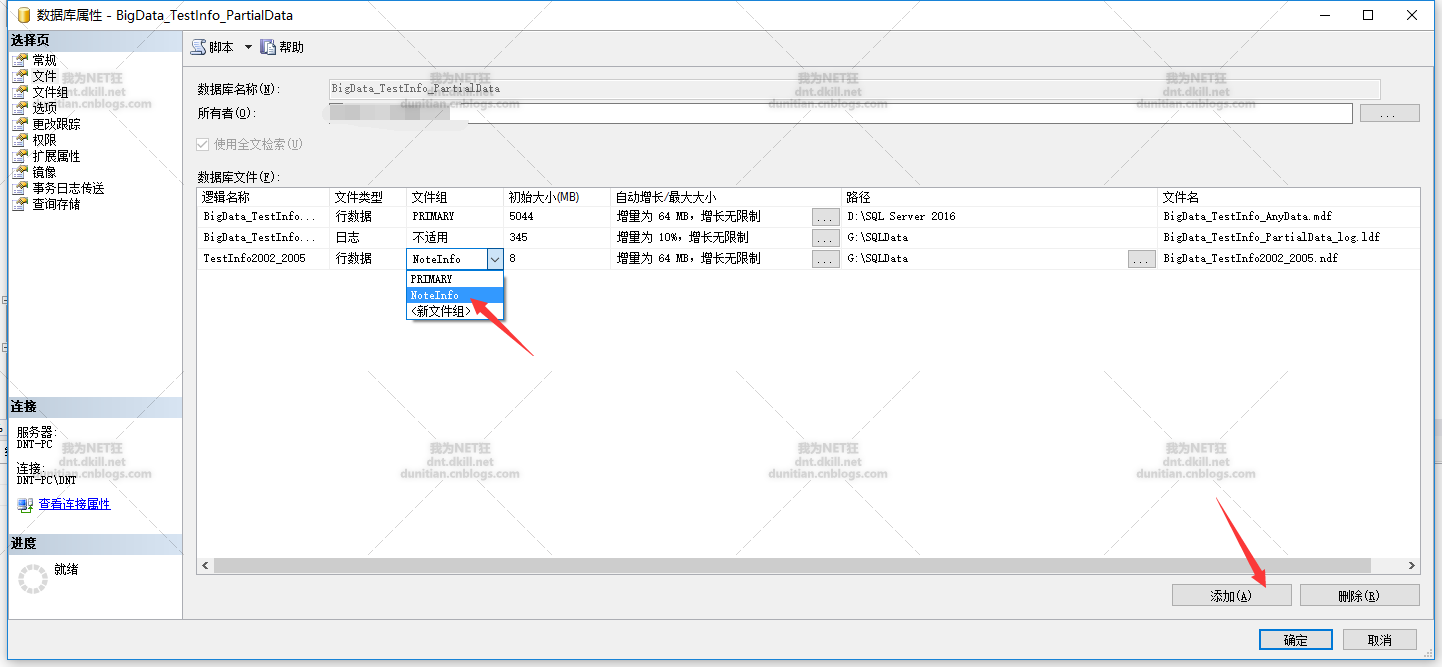
3.0创建文件组

添加文件到文件组
命令操作:
alter database BigData_TestInfo_PartialData add filegroup Info
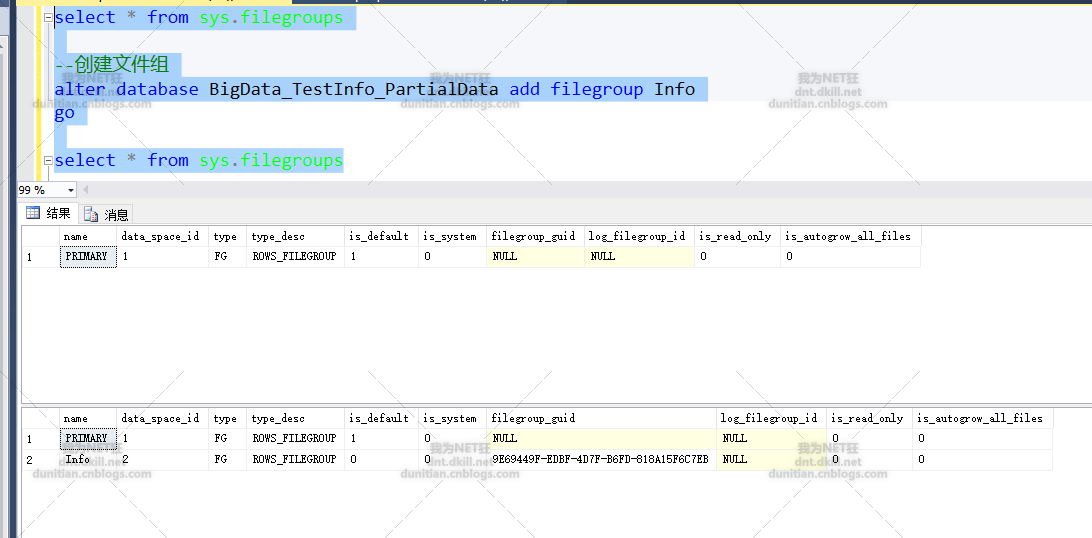
alter database BigData_TestInfo_PartialData add file(name=N'TestInfo2006',filename=N'G:\SQLData\BigData_TestInfo2006.ndf') to filegroup Info
注意:BigData_TestInfo2006.ndf是数据库自己创建的,不需要自己手动创建(有些同志手动创建了,然后报错。。。。呃,有点哭笑不得了)
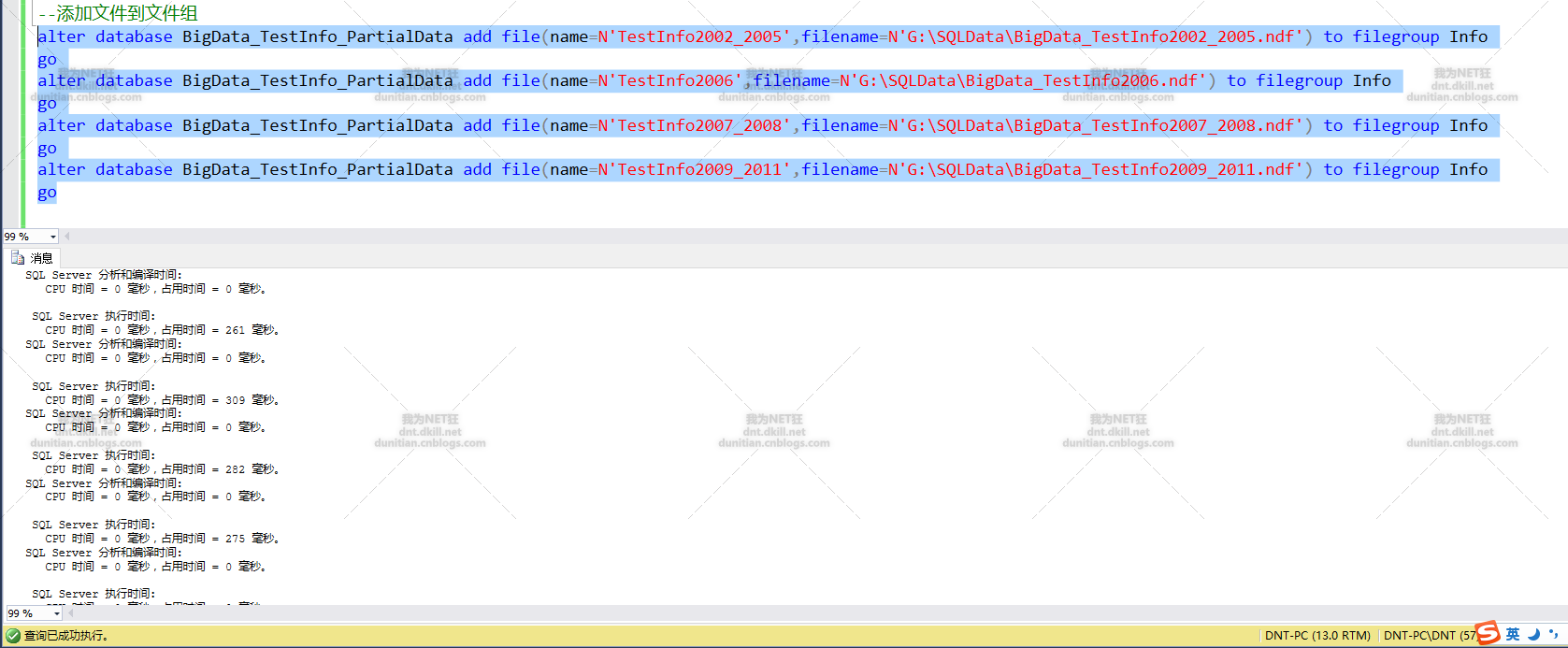
查询看看:select * from sys.filegroups
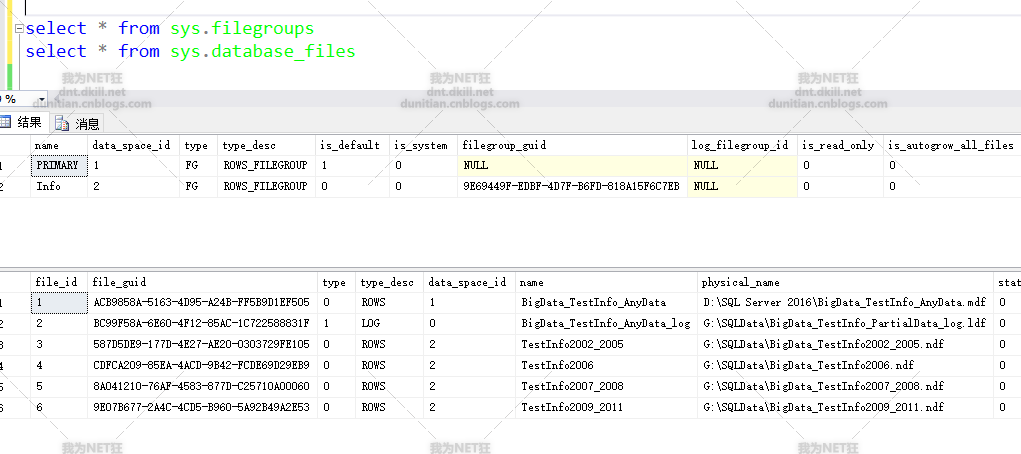
水平分区走起:一般就几步,1.创建分区函数 2.创建分区方案 3.创建分区表
GUI方法
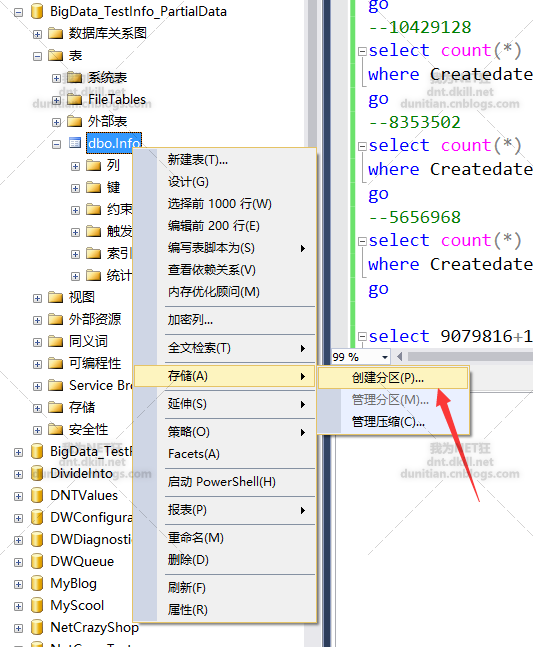
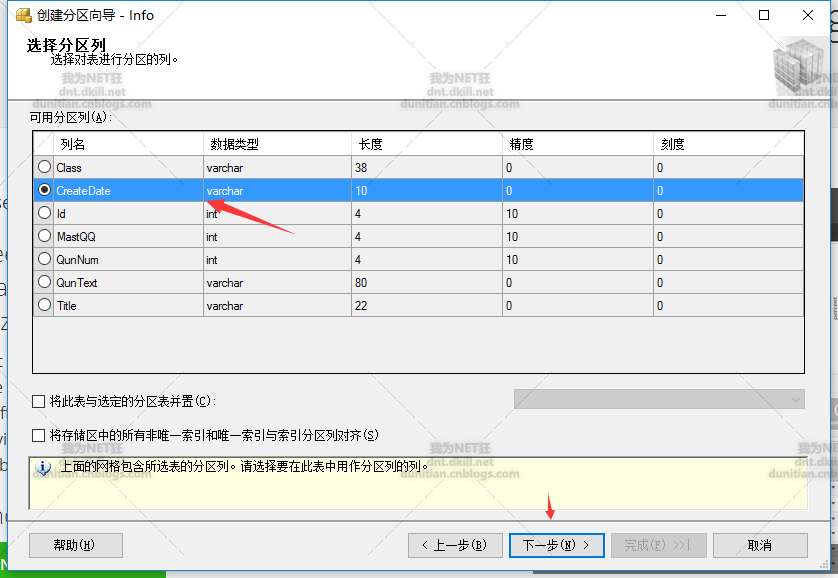
分区函数
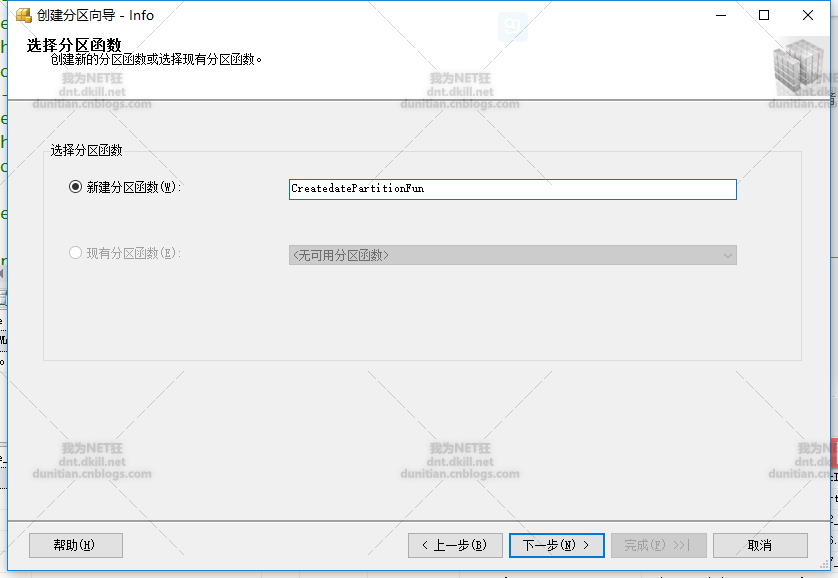
分区方案
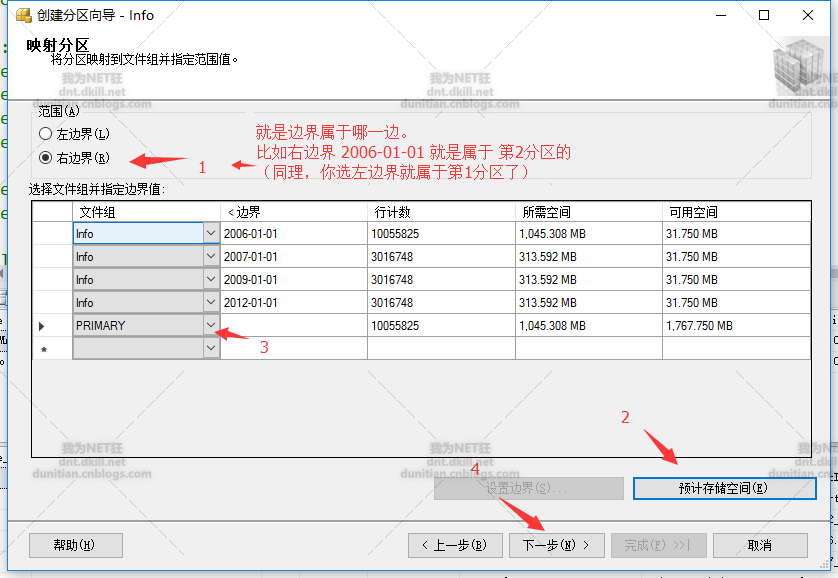
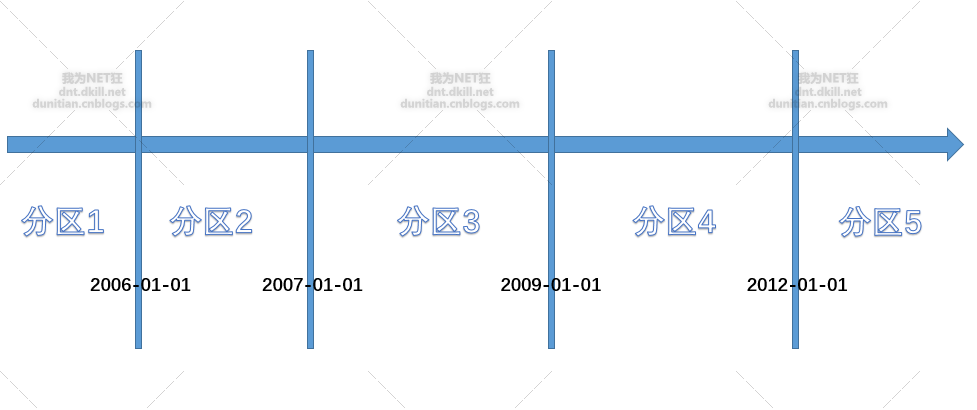
上一张图有些人可能不懂,用PPT画张概念图:
创建脚本
系统生成脚本:
use [BigData_TestInfo_PartialData]
go begin transaction create partition function [CreatedatePartitionFun](varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01') create partition scheme [CreatedatePartitionScheme] as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary]) alter table [dbo].[Info] drop constraint [PK__Info__3214EC07B2FE10C8] alter table [dbo].[Info] add primary key nonclustered
(
[Id] asc
)with (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] set ansi_padding on create clustered index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info]
(
[CreateDate]
)with (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [CreatedatePartitionScheme]([CreateDate]) drop index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info] commit transaction
go
命令方式创建(根据上面生成的命令逆推)
创建分区函数和架构(方案)
create partition function CreatedatePartitionFun(varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01')

create partition scheme CreatedatePartitionScheme as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary])
创建分区表
尚未创建表的情况

已经创建了表(基本上都是这种情况)
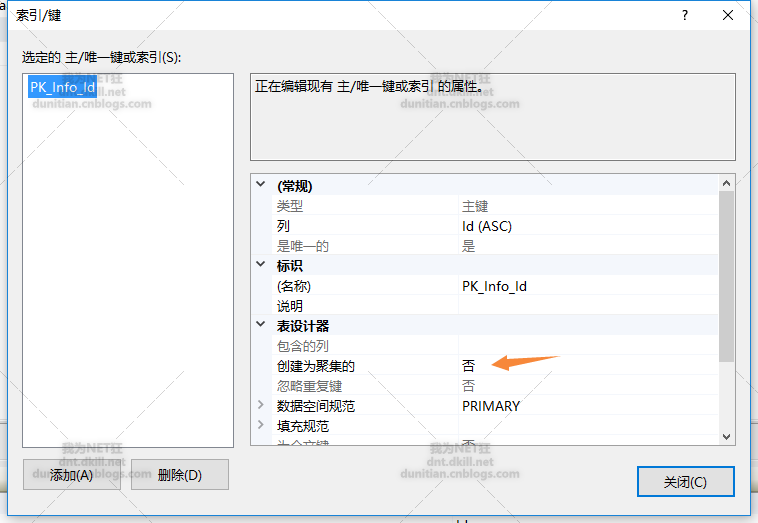
主要就两步,把主键变为非聚集索引+创建分区聚集索引
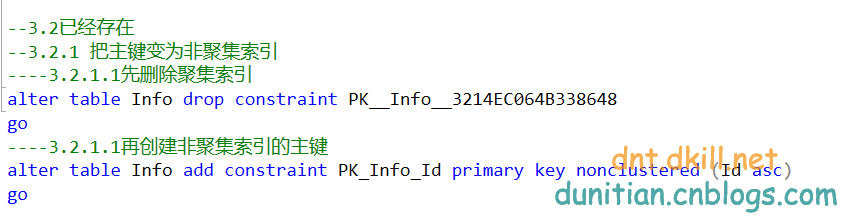
alter table Info drop constraint PK__Info__3214EC064B338648
alter table Info add constraint PK_Info_Id primary key nonclustered (Id asc)

create clustered index IX_Info_CreateDate on Info(CreateDate) on CreatedatePartitionScheme(CreateDate)
测试:基本上是均匀分散在各个文件中,生产环境的时候可以把这些文件放各个磁盘

参考文章:
http://www.cnblogs.com/gaizai/p/3582024.html
http://www.cnblogs.com/lyhabc/p/3480917.html
http://www.cnblogs.com/libingql/p/4087598.html
http://www.cnblogs.com/CareySon/p/3252670.html
http://database.51cto.com/art/201009/225448.htm
http://www.cnblogs.com/knowledgesea/p/3696912.html
http://www.cnblogs.com/CareySon/archive/2011/12/30/2307766.html
http://www.cnblogs.com/lykbk/p/erererert343243434388773437878.html
01.SQLServer性能优化之---水平分库扩展的更多相关文章
- 02.SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 第一次引入文件组的概念:http://www.cnblogs.com/dunitian/ ...
- SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 第一次引入文件组的概念:http://www.cnblogs.com/dunitia ...
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- SQLServer性能优化专题
SQLServer性能优化专题 01.SQLServer性能优化之----强大的文件组----分盘存储(水平分库) http://www.cnblogs.com/dunitian/p/5276431. ...
- 02.SQLServer性能优化之---牛逼的OSQL----大数据导入
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 上一篇:01.SQLServer性能优化之----强大的文件组----分盘存储 http ...
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- SQLServer性能优化之---数据库级日记监控
上节回顾:https://www.cnblogs.com/dotnetcrazy/p/11029323.html 4.6.6.SQLServer监控 脚本示意:https://github.com/l ...
- Linux性能优化从入门到实战:01 Linux性能优化学习路线
我通过阅读各种相关书籍,从操作系统原理.到 Linux内核,再到硬件驱动程序等等. 把观察到的性能问题跟系统原理关联起来,特别是把系统从应用程序.库函数.系统调用.再到内核和硬件等不同的层级贯 ...
- SqlServer性能优化和工具Profiler(转)
合理的优化和熟练的运用Profiler会让你更好的掌握系统的sql语句和存储过程的效率 目录 第1章 如何打开SQL Server Profile. 3 第2章 SQL Server Profile. ...
随机推荐
- Microsoft Loves Linux
微软新任CEO纳德拉提出的“Microsoft Loves Linux”,并且微软宣布.NET框架的开源,近期Microsoft不但宣布了Linux平台的SQL Server,还宣布了Microsof ...
- InnoDB体系结构学习笔记
后台线程 Master Thread 核心的后台线程,主要负责将缓冲池的数据异步刷新到磁盘,保证数据的一致性,包括(脏页的刷新).合并插入缓冲.(UNDO页的回收)等 IO Thread 4个writ ...
- mysql 学习总结
MYSQL的增.删.查.改 注册.授权 #创建一个对数据库中的表有一些操作权限的用户,其中OPERATION可以用all privileges替换,DBNAME.TABLENAME可以用*替换,表 ...
- AFNetworking 3.0 源码解读 总结(干货)(上)
养成记笔记的习惯,对于一个软件工程师来说,我觉得很重要.记得在知乎上看到过一个问题,说是人类最大的缺点是什么?我个人觉得记忆算是一个缺点.它就像时间一样,会自己消散. 前言 终于写完了 AFNetwo ...
- Git初探--笔记整理和Git命令详解
几个重要的概念 首先先明确几个概念: WorkPlace : 工作区 Index: 暂存区 Repository: 本地仓库/版本库 Remote: 远程仓库 当在Remote(如Github)上面c ...
- CSS 3学习——transition 过渡
以下内容根据官方规范翻译以及自己的理解整理. 1.介绍 这篇文档介绍能够实现隐式过渡的CSS新特性.文档中介绍的CSS新特性描述了CSS属性的值如何在给定的时间内平滑地从一个值变为另一个值. 2.过渡 ...
- C#通过NPOI操作Excel
参考页面: http://www.yuanjiaocheng.net/webapi/create-crud-api-1-post.html http://www.yuanjiaocheng.net/w ...
- BPM与 SAP & Oracle EBS集成解决方案分享
一.需求分析 SAP和Oracle EBS都是作为全球顶级的的ERP产 品,得到了众多客户的青睐.然而由于系统庞大.价格昂贵以及定位不同,客户在实施过程中经常会面临以下困惑: 1.SAP如何实现&qu ...
- PMON failed to acquire latch, see PMON dump
前几天,一台Oracle数据库(Oracle Database 10g Release 10.2.0.4.0 - 64bit Production)监控出现"PMON failed to a ...
- [转] 从知名外企到创业公司做CTO是一种怎样的体验?
这是我近期接受51CTO记者李玲玲采访的一篇文章,分享给大家. 作者:李玲玲来源:51cto.com|2016-12-30 15:47 http://cio.51cto.com/art/201612/ ...