【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战
作者:白宁超
2017年1月3日18:26:33
摘要:随着机器学习和深度学习的热潮,各种图书层出不穷。然而多数是基础理论知识介绍,缺乏实现的深入理解。本系列文章是作者结合视频学习和书籍基础的笔记所得。本系列文章将采用理论结合实践方式编写。首先介绍机器学习和深度学习的范畴,然后介绍关于训练集、测试集等介绍。接着分别介绍机器学习常用算法,分别是监督学习之分类(决策树、临近取样、支持向量机、神经网络算法)监督学习之回归(线性回归、非线性回归)非监督学习(K-means聚类、Hierarchical聚类)。本文采用各个算法理论知识介绍,然后结合python具体实现源码和案例分析的方式(本文原创编著,转载注明出处:KNN算法虹膜图片识别实战(4))
目录
- 【Machine Learning】Python开发工具:Anaconda+Sublime(1)
- 【Machine Learning】机器学习及其基础概念简介(2)
- 【Machine Learning】决策树在商品购买力能力预测案例中的算法实现(3)
- 【Machine Learning】KNN算法虹膜图片识别实战(4)
1 K-近邻算法(KNN, k-NearestNeighbor)
1.1 概念介绍
- 在k-NN分类中,输出是一个分类族群。一个对象的分类是由其邻居的“多数表决”确定的,k个最近邻居(k为正整数,通常较小)中最常见的分类决定了赋予该对象的类别。若k = 1,则该对象的类别直接由最近的一个节点赋予。
- 在k-NN回归中,输出是该对象的属性值。该值是其k个最近邻居的值的平均值。
最近邻居法采用向量空间模型来分类,概念为相同类别的案例,彼此的相似度高,而可以借由计算与已知类别案例之相似度,来评估未知类别案例可能的分类。K-NN是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。k-近邻算法是所有的机器学习算法中最简单的之一。无论是分类还是回归,衡量邻居的权重都非常有用,使较近邻居的权重比较远邻居的权重大。例如,一种常见的加权方案是给每个邻居权重赋值为1/ d,其中d是到邻居的距离。邻居都取自一组已经正确分类(在回归的情况下,指属性值正确)的对象。虽然没要求明确的训练步骤,但这也可以当作是此算法的一个训练样本集。k-近邻算法的缺点是对数据的局部结构非常敏感。本算法与K-平均算法(另一流行的机器学习技术)没有任何关系,请勿与之混淆。
1.2 举例分析一
我们提取电影的主要特征信息,特征选择:电影名称、打斗次数、接吻次数、电影类型。主要借助打斗和接吻特征判断电影属于那种类型(爱情片/动作片).将采用KNN的方法进行模型训练,因为KNN属于有监督学习,因此设定一定规模的训练集进行模型训练,然后对测试数据进行分类预测,具体如图1所示:
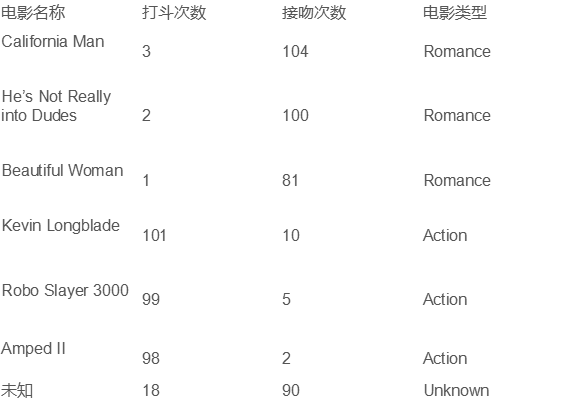
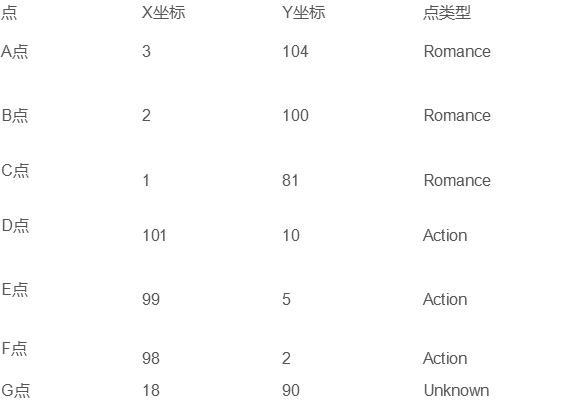
图2 电影信息特征转化
下面判断未知电影G点属于Romance或Action那种类型?不妨以图3形式化描述更好理解,假设黑色的豆子是动作片,绿色豆子是历史片,红色的豆子是爱情片。一部新电影G点到底属于哪个类型。主要判定G点周围的点属于哪个类型,至于G点周围如何设定,这就是K值的设置。K值不同直接影响分类结果,这个后续详细介绍。K的设定一般都是1,3,5,7,9等这样的奇数。其理由是因为采用少数服从多数的原理,不然设为偶数出现中立的情况就没有办法分类了。下图中绿色的原点周围大多属于绿豆,所以规为绿色豆子即【爱情片】。具体算法和代码后文介绍。 
1.3 举例分析二
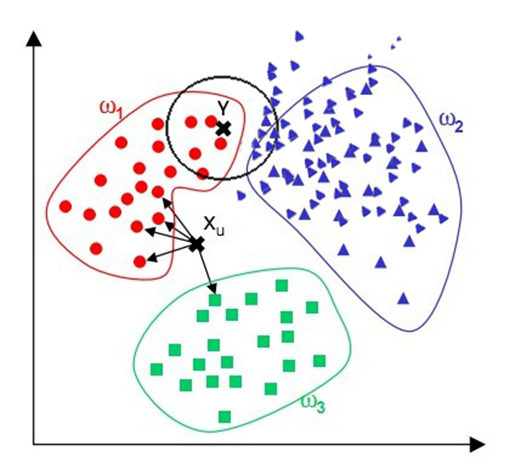
绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。如图4所示:

2 K-近邻算法详述
2.1 算法步骤
- 准备数据,对数据进行预处理
- 选用合适的数据结构存储训练数据和测试元组
- 为了判断未知实例的类别,以所有已知类别的实例作为参照
- 选择参数K
- 维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列
- 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
- 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
- 计算未知实例与所有已知实例的距离
- 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
- 根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别
- 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。
2.2 距离的衡量方法:

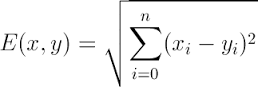
2.3 算法优缺点
- 简单、易于理解、容易实现
- 无需估计参数
- 无需训练
- 通过对K的选择可具备丢噪音数据的健壮性
- 适合对稀有事件进行分类
- 特别适合于多分类问题(multi-modal,对象具有多个类别标签),kNN比SVM的表现要好
- 当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
- 需要大量空间储存所有已知实例
- 可理解性差,无法给出像决策树那样的规则
- 算法复杂度高(需要比较所有已知实例与要分类的实例)
- 分类效率:事先对样本属性进行约简,删除对分类结果影响较小的属性,快速的得出待分类样本的类别。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
- 分类效果:采用权值的方法(和该样本距离小的邻居权值大)来改进,Han等人于2002年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k nearest neighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。[
- 考虑距离,根据距离加上权重。比如: 1/d (d: 距离)
参数选择
如何选择一个最佳的K值取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响,但会使类别之间的界限变得模糊。一个较好的K值能通过各种启发式技术(见超参数优化)来获取。噪声和非相关性特征的存在,或特征尺度与它们的重要性不一致会使K近邻算法的准确性严重降低。对于选取和缩放特征来改善分类已经作了很多研究。一个普遍的做法是利用进化算法优化功能扩展,还有一种较普遍的方法是利用训练样本的互信息进行选择特征。在二元(两类)分类问题中,选取k为奇数有助于避免两个分类平票的情形。在此问题下,选取最佳经验k值的方法是自助法。
属性
原始朴素的算法通过计算测试点到存储样本点的距离是比较容易实现的,但它属于计算密集型的,特别是当训练样本集变大时,计算量也会跟着增大。多年来,许多用来减少不必要距离评价的近邻搜索算法已经被提出来。使用一种合适的近邻搜索算法能使K近邻算法的计算变得简单许多。
近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍[8]。对于一些K值,K近邻保证错误率不会超过贝叶斯的。
决策边界
近邻算法能用一种有效的方式隐含的计算决策边界。另外,它也可以显式的计算决策边界,以及有效率的这样做计算,使得计算复杂度是边界复杂度的函数。
3 K-近邻算法图片识别分类
3.1 KNN对虹膜图片分类处理


3.2 调用ython的机器学习库sklearn实现虹膜分类
下图8对应数据集:萼片长度,萼片宽度,花瓣长度,花瓣宽度,虹膜类别。数据集下载

from sklearn import neighbors
from sklearn import datasets
'''
Description:python调用机器学习库scikit-learn的K临近算法,实现花瓣分类
Author:Bai Ningchao
DateTime:2017年1月3日15:07:25
Blog URL:http://www.cnblogs.com/baiboy/
Document:http://scikit-learn.org/stable/modules/neighbors.html
''' knn=neighbors.KNeighborsClassifier() iris=datasets.load_iris() # print(iris)
'传入参数,data是花的特征数据,样本数据;target是分类的数据,归为哪类。'
knn.fit(iris.data,iris.target) 'knn预测分类,参数是 萼片和花瓣的长度和宽度'
predictedlabel = knn.predict([[0.1,0.2,0.3,0.4]]) print('分类结果[0:setosa][1:versicolor][2:virginica]:\n',predictedlabel,':setosa' if predictedlabel[0]==0 else 'versicolor or virginica')
运行结果如图9:

3.3 KNN 实现Implementation
1 加载数据集,split划分数据集为训练集和测试集。
'加载数据集,split划分数据集为训练集和测试集'
def loadDataset(filename,split,trainingSet=[],testSet=[]):
with open(filename,'r') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
# print(dataset[:20])
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
# print(dataset[x])
else:
testSet.append(dataset[x])
# print('-->',dataset[x])
运行结果:
Train set: 104
Test set: 46
2 返回最近的K个近邻距离
'返回最近的K个label'
def getNeighbors(trainingSet,testInstance,k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
3 距离计算:
'计算距离'
def euclideanDistance(instance1,instance2,length):
distance = 0
for x in range(length):
distance += pow((instance1[x]-instance2[x]),2)
return math.sqrt(distance)
或者
import math
def ComputeEuclideanDistance(x1, y1, x2, y2):
d = math.sqrt(math.pow((x1-x2), 2) + math.pow((y1-y2), 2))
return d d_ag = ComputeEuclideanDistance(3, 104, 18, 90) print d_ag
4 根据投票进行分类划分'
'根据投票进行分类划分'
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(),key=operator.itemgetter(1),reverse=True)
return sortedVotes[0][0]
预测结果(部分结果):
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-setosa', actual='Iris-setosa'
>predicted='Iris-versicolor', actual='Iris-versicolor'
>predicted='Iris-versicolor', actual='Iris-versicolor'
>predicted='Iris-versicolor', actual='Iris-versicolor'
>predicted='Iris-versicolor', actual='Iris-versicolor'
>predicted='Iris-versicolor', actual='Iris-versicolor'
测试数据结果预测:
5 计算准确率
'预测结果,算出精确度'
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet)))*100.0
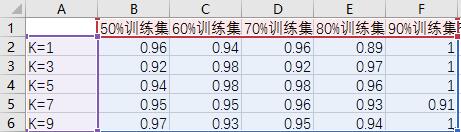
训练集大小不同和K值设置不同对预测准确率性能影响如表1:
表1 虹膜花分类K值与训练数据集对准确率影响关系表
6 完整的KNN虹膜图片分类源码
import csv
import math
import random
import operator '''
Description:python调用机器学习库scikit-learn的K临近算法,实现花瓣分类
Author:Bai Ningchao
DateTime:2017年1月3日15:07:25
Blog URL:http://www.cnblogs.com/baiboy/
Document:http://scikit-learn.org/stable/modules/neighbors.html
''' '加载数据集,split划分数据集为训练集和测试集'
def loadDataset(filename,split,trainingSet=[],testSet=[]):
with open(filename,'r') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
# print(dataset[:20])
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
# print(dataset[x])
else:
testSet.append(dataset[x])
# print('-->',dataset[x]) '计算距离'
def euclideanDistance(instance1,instance2,length):
distance = 0
for x in range(length):
distance += pow((instance1[x]-instance2[x]),2)
return math.sqrt(distance) '返回最近的K个label'
def getNeighbors(trainingSet,testInstance,k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors '根据投票进行分类划分'
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(),key=operator.itemgetter(1),reverse=True)
return sortedVotes[0][0] '预测结果,算出精确度'
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet)))*100.0 def main():
trainingSet = []
testSet = []
split = 0.7 # 2/3训练集,1/3测试集
loadDataset(r'../datafile/irisdata.txt',split,trainingSet,testSet)
print('Train set: ' + repr(len(trainingSet)))
print('Test set: ' + repr(len(testSet)))
#generate predictions
predictions = []
k =5
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print ('>predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
print ('predictions: ' + repr(predictions))
accuracy = getAccuracy(testSet,predictions)
print('Accuracy: ' + repr(accuracy) + '%') if __name__ == '__main__':
main()
3.4 实验结果对比分析
折线图如图10所示:
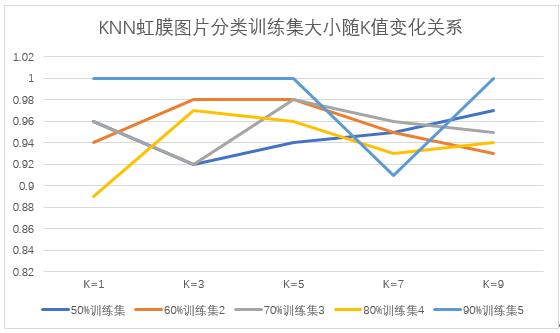
图10 折线图实验结果分析
条形图如图11所示:
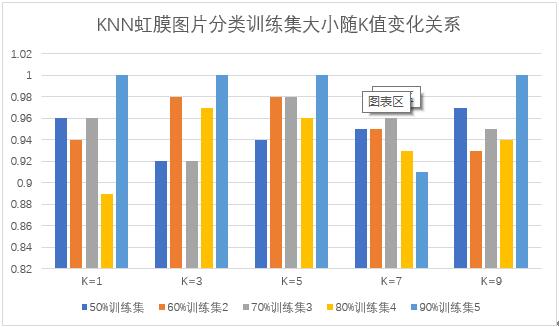
图11 条形图实验结果分析
实验结果:
- 上图结果表明,训练集的规模和K的取值,直接影响实验的分类性能。
- 当K值确定时,在K=1时候,分类效率最差,模型稳定性也差,随着训练集规模变化较为明显。当K=5和K=7时,训练集规模对模型影响相对稳定。综合比较K=5取得的平均准确率较高。
- 当训练集确定时,90%的训练集取得的实验效果最好,但是不稳定,70%训练集综合效果最好。
误差分析:
- 数据集划分误差:因为训练集和测试集的划分是随机的,存在一定误差
- 数据集规模误差:数据集采用150条,太小了,存在一定偶然性。
- 数据平衡误差:本实验数据较为平衡,在其他情况下,数据稀疏性对实验结果有一定影响。
误差改进:
- 检查数据是否存在稀疏性,保持平衡
- 扩大规模,使其符合一定的大数定律
- 多次进行实验取平均值比较
3.5 分享
4 参考文献
4 维基百科KNN
【Machine Learning】KNN算法虹膜图片识别的更多相关文章
- Machine Learning:机器学习算法
原文链接:https://riboseyim.github.io/2018/02/10/Machine-Learning-Algorithms/ 摘要 机器学习算法分类:监督学习.半监督学习.无监督学 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- knn算法手写字识别案例
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os from sklearn.neighb ...
- [Machine Learning]k-NN
k-NN最近邻算法 基本思想: 对未知样本X,从训练样本集中获取与其最相近的k个样本,利用这k个样本的类别预测未知样本X的类别. 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大 ...
- 机器学习(Machine Learning)算法总结-决策树
一.机器学习基本概念总结 分类(classification):目标标记为类别型的数据(离散型数据)回归(regression):目标标记为连续型数据 有监督学习(supervised learnin ...
- 【Machine Learning】Python开发工具:Anaconda+Sublime
Python开发工具:Anaconda+Sublime 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- Python 手写数字识别-knn算法应用
在上一篇博文中,我们对KNN算法思想及流程有了初步的了解,KNN是采用测量不同特征值之间的距离方法进行分类,也就是说对于每个样本数据,需要和训练集中的所有数据进行欧氏距离计算.这里简述KNN算法的特点 ...
随机推荐
- 发布:.NET开发人员必备的可视化调试工具(你值的拥有)
1:如何使用 1:点击下载:.NET可视化调试工具 (更新于2016-12-29 19:11:00) (终于彻底兼容了部分VS环境下无法使用的问题) 2:解压RAR后执行:CYQ.VisualierS ...
- ABP文档 - 目录
ABP框架 概览 介绍 多层结构 模块系统 启动配置 多租户 集成OWIN 共同结构 依赖注入 会话 缓存 日志 设置管理 时间 领域层 实体 值对象(新) 仓储 领域服务 工作单元 领域事件(Eve ...
- 三分钟学会用 js + css3 打造酷炫3D相册
之前发过该文,后来不知怎么回事不见了,现在重新发一下. 中秋主题的3D旋转相册 如图,这是通过Javascript和css3来实现的.整个案例只有不到80行代码,我希望通过这个案例,让正处于迷茫期的j ...
- 如何正确使用日志Log
title: 如何正确使用日志Log date: 2015-01-08 12:54:46 categories: [Python] tags: [Python,log] --- 文章首发地址:http ...
- 使用Java原生代理实现AOP
### 本文由博主柒.原创,转载请注明出处 ### 完整源码下载地址 [https://github.com/MatrixSeven/JavaAOP](https://github.com/Matri ...
- mount报错: you must specify the filesystem type
在linux mount /dev/vdb 到 /home 分区时报错: # mount /dev/vdb /homemount: you must specify the filesystem ty ...
- Nginx反向代理,负载均衡,redis session共享,keepalived高可用
相关知识自行搜索,直接上干货... 使用的资源: nginx主服务器一台,nginx备服务器一台,使用keepalived进行宕机切换. tomcat服务器两台,由nginx进行反向代理和负载均衡,此 ...
- 看图理解JWT如何用于单点登录
单点登录是我比较喜欢的一个技术解决方案,一方面他能够提高产品使用的便利性,另一方面他分离了各个应用都需要的登录服务,对性能以及工作量都有好处.自从上次研究过JWT如何应用于会话管理,加之以前的项目中也 ...
- NodeJs支付宝移动支付签名及验签
非常感谢 :http://www.jianshu.com/p/8513e995ff3a?utm_campaign=hugo&utm_medium=reader_share&utm_co ...
- Java—恶心的java.lang.NumberFormatException解决
项目中要把十六进制字符串转化为十进制, 用到了到了Integer.parseInt(str1.trim(), 16):这个是不是后抛出java.lang.NumberFormatException异常 ...