python爬取github数据
爬虫流程
在上周写完用scrapy爬去知乎用户信息的爬虫之后,github上star个数一下就在公司小组内部排的上名次了,我还信誓旦旦的跟上级吹牛皮说如果再写一个,都不好意思和你再提star了,怕你们伤心。上级不屑的说,那就写一个爬虫爬一爬github,找一找python大牛,公司也正好在找人。临危受命,格外激动,当天就去研究github网站,琢磨怎么解析页面以及爬虫的运行策略。意外的发现github提供了非常nice的API以及文档文档,让我对github的爱已经深入骨髓。
说了这么多废话,讲讲真题吧。我需要下载github用户还有他们的reposities数据,展开方式也很简单,根据一个用户的following以及follower关系,遍历整个用户网就可以下载所有的数据了,听说github注册用户才几百万,一下就把所有的数据爬下来想想还有点小激动呢,下面是流程图:
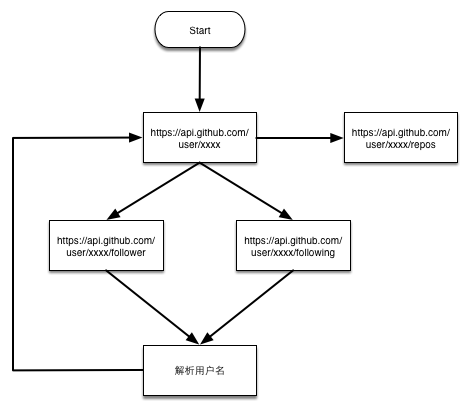
这是我根据这个流程实现的代码,网址:https://github.com/LiuRoy/github_spider
递归实现
运行命令
看到这么简单的流程,内心的第一想法就是先简单的写一个递归实现呗,要是性能差再慢慢优化,所以第一版代码很快就完成了(在目录recursion下)。数据存储使用mongo,重复请求判断使用的redis,写mongo数据采用celery的异步调用,需要rabbitmq服务正常启动,在settings.py正确配置后,使用下面的步骤启动:
- 进入github_spider目录
- 执行命令
celery -A github_spider.worker worker loglevel=info启动异步任务 - 执行命令
python github_spider/recursion/main.py启动爬虫
运行结果
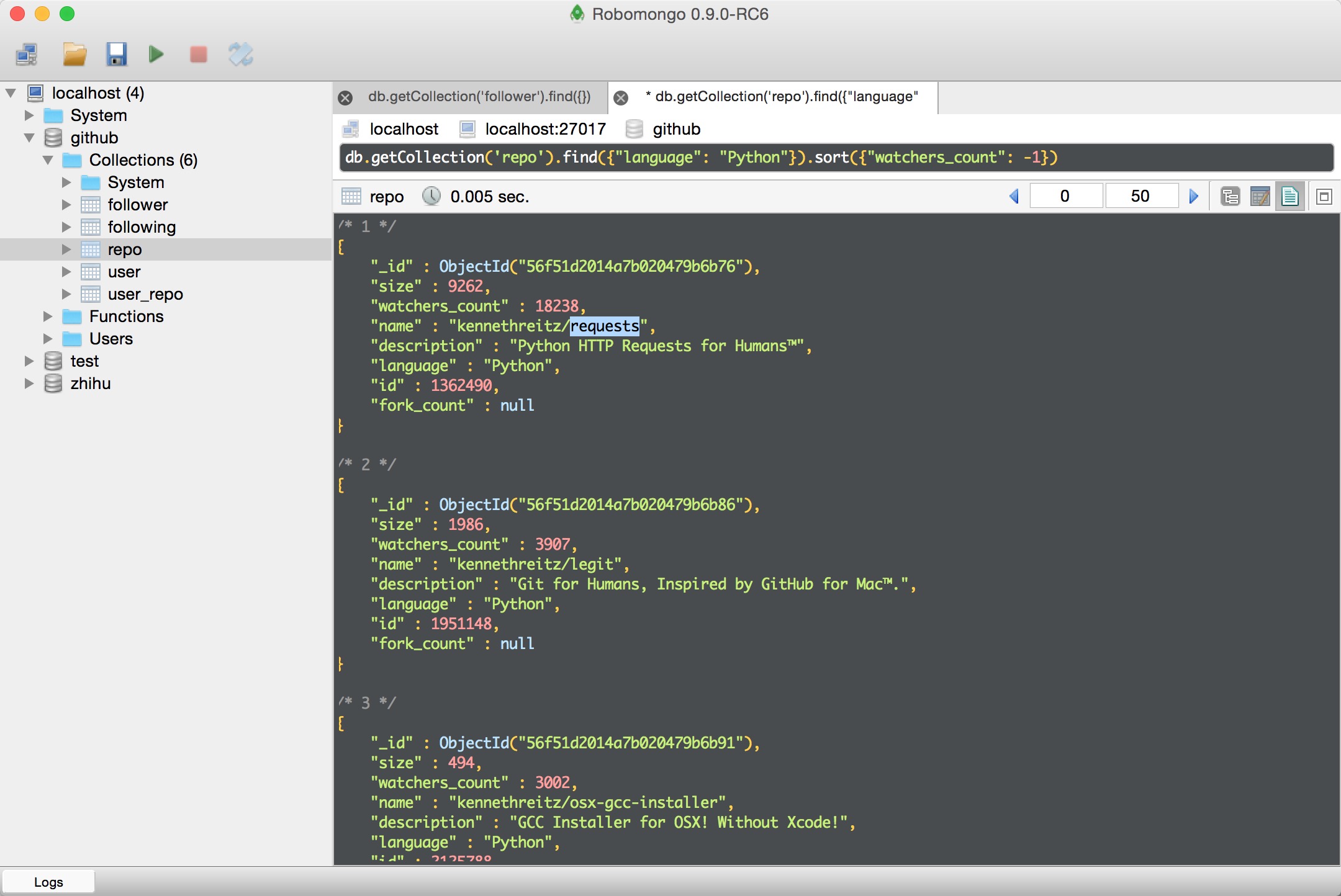
因为每个请求延时很高,爬虫运行效率很慢,访问了几千个请求之后拿到了部分数据,这是按照查看数降序排列的python项目:
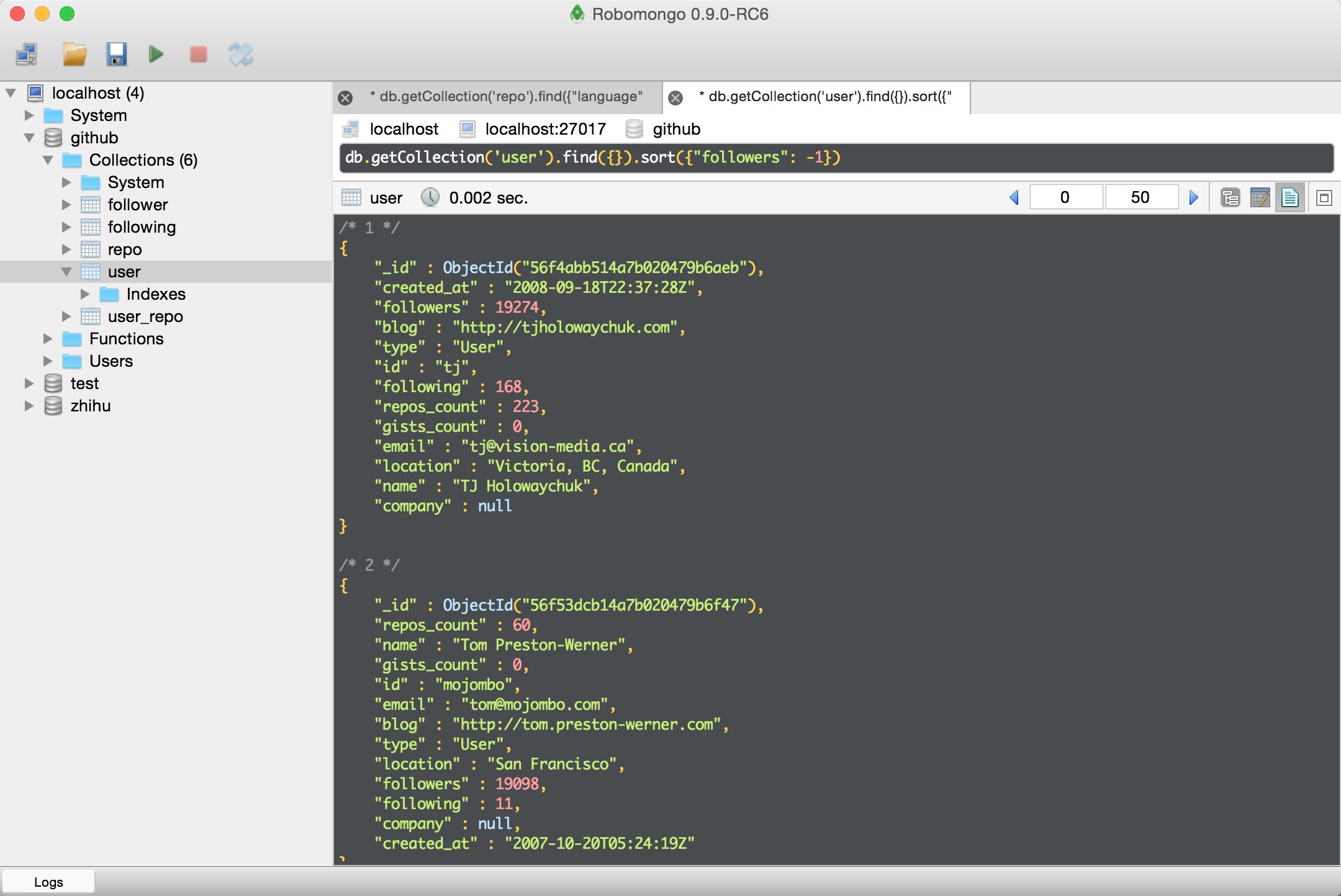
这是按粉丝数降序排列的用户列表
运行缺陷
作为一个有追求的程序员,当然不能因为一点小成就满足,总结一下递归实现的几个缺陷:
- 因为是深度优先,当整个用户图很大的时候,单机递归可能造成内存溢出从而使程序崩溃,只能在单机短时间运行。
- 单个请求延时过长,数据下载速度太慢。
- 针对一段时间内访问失败的链接没有重试机制,存在数据丢失的可能。
异步优化
针对这种I/O耗时的问题,解决方法也就那几种,要么多并发,要么走异步访问,要么双管齐下。针对上面的问题2,我最开始的解决方式是异步请求API。因为最开始写代码的时候考虑到了这点,代码对调用方法已经做过优化,很快就改好了,实现方式使用了grequests。这个库和requests是同一个作者,代码也非常的简单,就是讲request请求用gevent做了一个简单的封装,可以非阻塞的请求数据。
但是当我运行之后,发现程序很快运行结束,一查发现公网IP被github封掉了,当时心中千万只草泥马奔腾而过,没办法只能祭出爬虫的终极杀器--代理。又专门写了一个辅助脚本从网上爬取免费的HTTPS代理存放在redis中,路径proxy/extract.py,每次请求的时候都带上代理,运行错误重试自动更换代理并把错误代理清楚。本来网上免费的HTTPS代理就很少,而且很多还不能用,由于大量的报错重试,访问速度不仅没有原来快,而且比原来慢一大截,此路不通只能走多并发实现了。
队列实现
实现原理
采取广度优先的遍历的方式,可以把要访问的网址存放在队列中,再套用生产者消费者的模式就可以很容易的实现多并发,从而解决上面的问题2。如果某段时间内一直失败,只需要将数据再仍会队列就可以彻底解决问题3。不仅如此,这种方式还可以支持中断后继续运行,程序流程图如下:
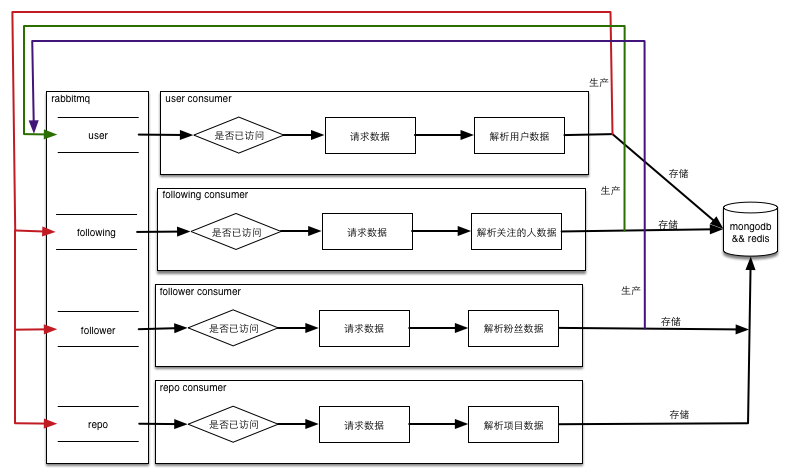
运行程序
为了实现多级部署(虽然我就只有一台机器),消息队列使用了rabbitmq,需要创建名为github,类型是direct的exchange,然后创建四个名称分别为user, repo, follower, following的队列,详细的绑定关系见下图:
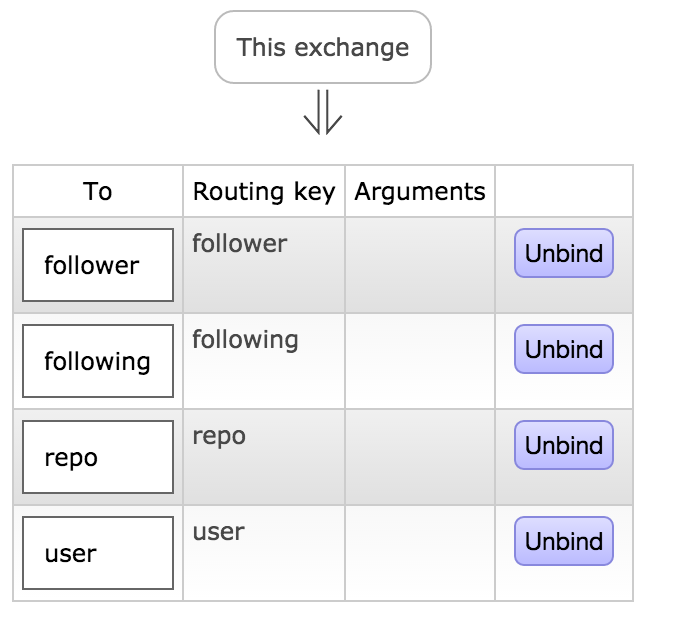
详细的启动步骤如下:
- 进入github_spider目录
- 执行命令
celery -A github_spider.worker worker loglevel=info启动异步任务 - 执行命令
python github_spider/proxy/extract.py更新代理 - 执行命令
python github_spider/queue/main.py启动脚本
队列状态图:

python爬取github数据的更多相关文章
- 如何使用Python爬取基金数据,并可视化显示
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于Will的大食堂,作者打饭大叔 前言 美国疫情越来越严峻,大选也进入 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- Python爬取房产数据,在地图上展现!
小伙伴,我又来了,这次我们写的是用python爬虫爬取乌鲁木齐的房产数据并展示在地图上,地图工具我用的是 BDP个人版-免费在线数据分析软件,数据可视化软件 ,这个可以导入csv或者excel数据. ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- 用python爬取微博数据并生成词云
很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,放在今天应该比较应景. 一年一度的虐汪节,是继续蹲在角落默 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
随机推荐
- TODO:macOS编译PHP7.1
TODO:macOS编译PHP7.1 本文主要介绍在macOS上编译PHP7.1,有兴趣的朋友可以去尝试一下. 1.下载PHP7.1源码,建议到PHP官网下载纯净到源码包php-7.1.0.tar.g ...
- html5标签canvas函数drawImage使用方法
html5中标签canvas,函数drawImage(): 使用drawImage()方法绘制图像.绘图环境提供了该方法的三个不同版本.参数传递三种形式: drawImage(image,x,y):在 ...
- JavaScript动画-磁性吸附
▓▓▓▓▓▓ 大致介绍 磁性吸附是以模拟拖拽为基础添加一个拖拽时范围的限定而来的一个效果,如果对模拟拖拽有疑问的同学请移步模拟拖拽. 源代码.效果:点这里 ▓▓▓▓▓▓ 范围限定(可视区) 先来看一个 ...
- 基于ASP.NET/C#开发国外支付平台(Paypal)学习心得。
最近一直在研究Paypal的支付平台,因为本人之前没有接触过接口这一块,新来一家公司比较不清楚流程就要求开发两个支付平台一个是支付宝(这边就不再这篇文章里面赘述了),但还是花了2-3天的时间通 ...
- celery使用的一些小坑和技巧(非从无到有的过程)
纯粹是记录一下自己在刚开始使用的时候遇到的一些坑,以及自己是怎样通过配合redis来解决问题的.文章分为三个部分,一是怎样跑起来,并且怎样监控相关的队列和任务:二是遇到的几个坑:三是给一些自己配合re ...
- GJM : C#设计模式(1)——单例模式
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- iOS 数据存储之SQLite3的使用
SQLite3是iOS内嵌的数据库,SQLite3在存储和检索大量数据方面非常有效,它使得不必将每个对象都加到内存中.还能够对数据进行负责的聚合,与使用对象执行这些操作相比,获得结果的速度更快. SQ ...
- Android 解析XML文件和生成XML文件
解析XML文件 public static void initXML(Context context) { //can't create in /data/media/0 because permis ...
- Android(4)—Mono For Android 第一个App应用程序
0.前言 年前就计划着写这篇博客,总结一下自己做的第一个App,却一直被新项目所累,今天抽空把它写完,记录并回顾一下相关知识点,也为刚学习Mono的同学提供佐证->C#也是开发Android的! ...
- centos6.X使用Apache+Mono搭建asp.net 环境
mark 一下时间 2016年1月19日09:42:49 mono是指由Novell公司(由Xamarin发起,并由Miguel de lcaza领导的,一个致力于开创·NET在Linux上使用的开 ...