scrapy 知乎用户信息爬虫
zhihu_spider
此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧。代码地址:https://github.com/LiuRoy/zhihu_spider,欢迎各位大神指出问题,另外知乎也欢迎大家关注哈 ^_^.
流程图
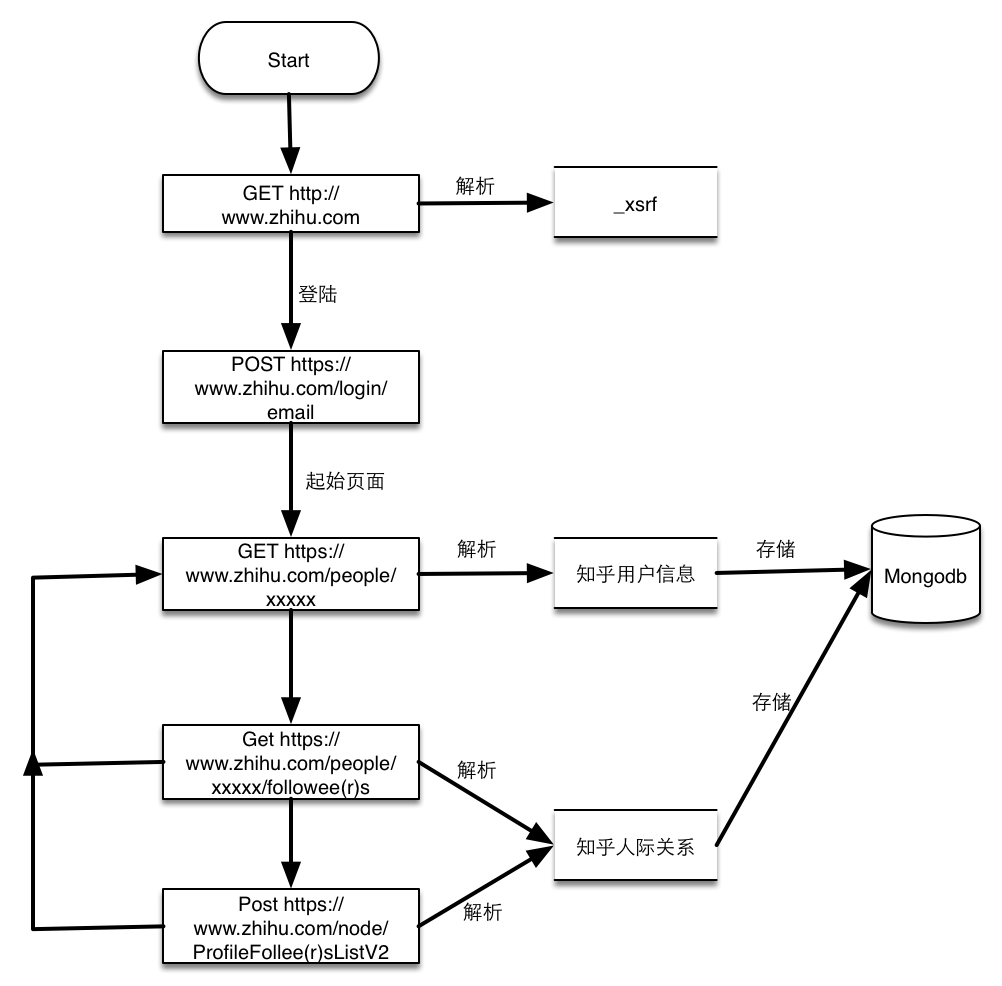
- 请求https://www.zhihu.com获取页面中的_xsrf数据,知乎开启了跨站请求伪造功能,所有的POST请求都必须带上此参数。
- 提交用户名,密码已经第一步解析的_xsrf参数到https://www.zhihu.com/login/email,登陆获取cookies
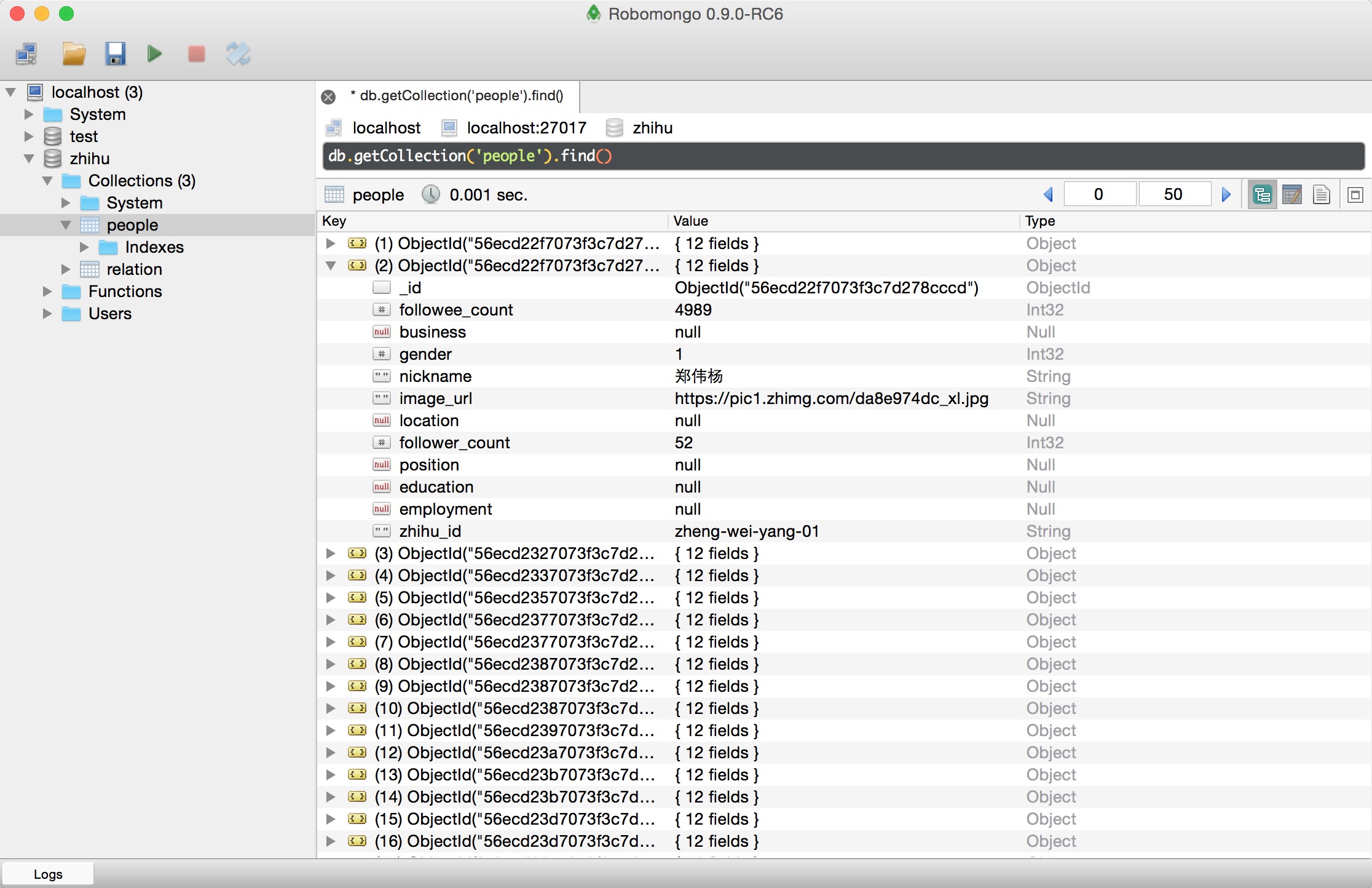
- 访问用户主页,以我的主页为例https://www.zhihu.com/people/weizhi-xiazhi, 如下图:
- 解析的用户信息包括昵称,头像链接,个人基本信息还有关注人的数量和粉丝的数量。这个页面还能获取关注人页面和粉丝页面。
- 由上一步获取的分页列表页面和关注人页面获取用户人际关系,这两个页面类似,唯一麻烦的是得到的静态页面最多只有二十个,获取全部的人员必须通过POST请求,解析到的个人主页再由上一步来解析。
代码解释
scrapy文档非常详细,在此我就不详细讲解,你所能碰到的任何疑问都可以在文档中找到解答。
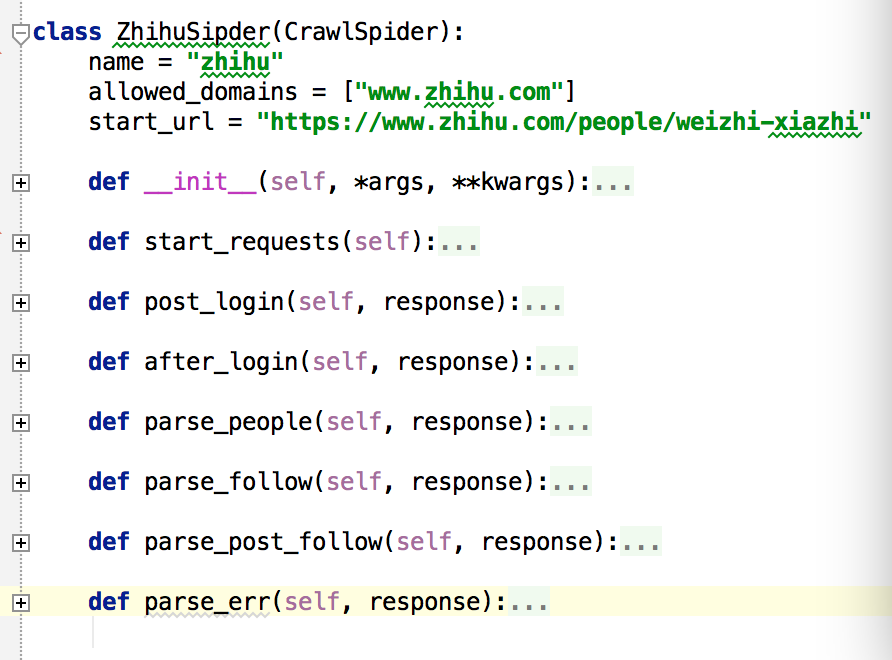
- 爬虫框架从start_requests开始执行,此部分会提交知乎主页的访问请求给引擎,并设置回调函数为post_login.
- post_login解析主页获取_xsrf保存为成员变量中,并提交登陆的POST请求,设置回调函数为after_login.
- after_login拿到登陆后的cookie,提交一个start_url的GET请求给爬虫引擎,设置回调函数parse_people.
- parse_people解析个人主页,一次提交关注人和粉丝列表页面到爬虫引擎,回调函数是parse_follow, 并把解析好的个人数据提交爬虫引擎写入mongo。
- parse_follow会解析用户列表,同时把动态的人员列表POST请求发送只引擎,回调函数是parse_post_follow,把解析好的用户主页链接请求也发送到引擎,人员关系写入mongo。
- parse_post_follow单纯解析用户列表,提交用户主页请求至引擎。
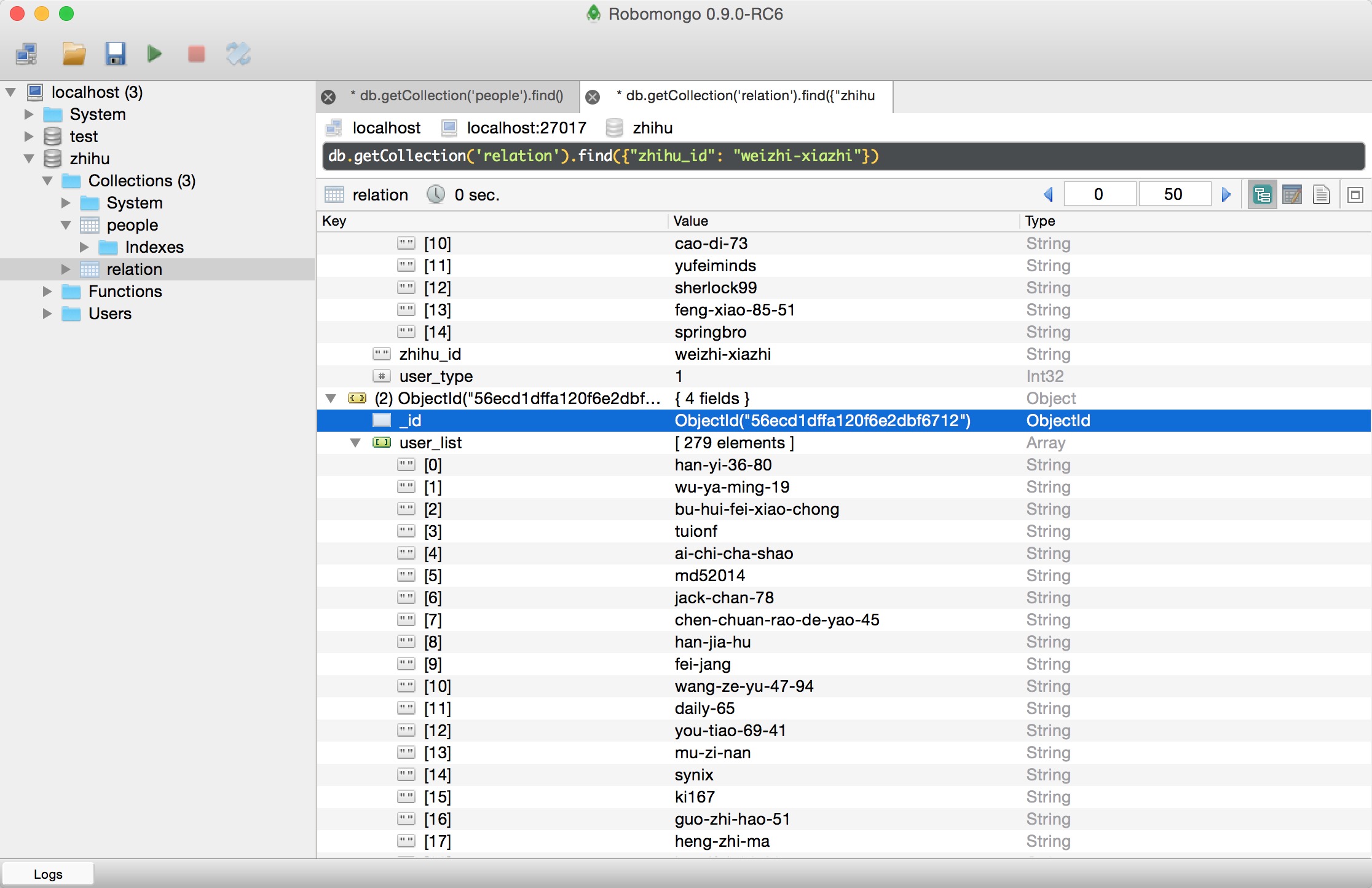
效果图
scrapy 知乎用户信息爬虫的更多相关文章
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- python3编写网络爬虫22-爬取知乎用户信息
思路 选定起始人 选一个关注数或者粉丝数多的大V作为爬虫起始点 获取粉丝和关注列表 通过知乎接口获得该大V的粉丝列表和关注列表 获取列表用户信息 获取列表每个用户的详细信息 获取每个用户的粉丝和关注 ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写
思路分析: (1)选定起始人(即选择关注数和粉丝数较多的人--大V) (2)获取该大V的个人信息 (3)获取关注列表用户信息 (4)获取粉丝列表用户信息 (5)重复(2)(3)(4)步实现全知乎用户爬 ...
- 爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账 ...
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python之爬虫(二十一) Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
随机推荐
- Shell替换
如果表达式中包含特殊字符,Shell 将会进行替换.例如,在双引号中使用变量就是一种替换,转义字符也是一种替换. #!/bin/bash a= echo -e "Value of a is ...
- ArcGIS 10.0紧凑型切片读写方法
首先介绍一下ArcGIS10.0的缓存机制: 切片方案 切片方案包括缓存的比例级别.切片尺寸和切片原点.这些属性定义缓存边界的存在位置,在某些客户端中叠加缓存时匹配这些属性十分重要.图像格式和抗锯齿等 ...
- 由Dapper QueryMultiple 返回数据的问题得出==》Dapper QueryMultiple并不会帮我们识别多个返回值的顺序
异常汇总:http://www.cnblogs.com/dunitian/p/4523006.html#dapper 今天帮群友整理Dapper基础教程的时候手脚快了点,然后遇到了一个小问题,Dapp ...
- Linux 常用命令(持续补充)
常用命令: command &:将进程放在后台执行 ctrl + z:暂停当前进程 并放入后台 jobs:查看当前后台任务 bg( %id):将任务转为后台执行 fg( %id):将任务调回前 ...
- 年度巨献-WPF项目开发过程中WPF小知识点汇总(原创+摘抄)
WPF中Style的使用 Styel在英文中解释为”样式“,在Web开发中,css为层叠样式表,自从.net3.0推出WPF以来,WPF也有样式一说,通过设置样式,使其WPF控件外观更加美化同时减少了 ...
- node中子进程同步输出
管道 通过"child_process"模块fork出来的子进程都是返回一个ChildProcess对象实例,ChildProcess类比较特殊无法手动创建该对象实例,只能使用fo ...
- 谈谈JS中的函数节流
好吧,一直在秋招中,都没怎么写博客了...今天赶紧来补一补才行...我发现,在面试中,讲到函数节流好像可以加分,尽管这并不是特别高深的技术,下面就聊聊吧! ^_^ 备注:以下内容部分来自<Jav ...
- “RazorEngine.Templating.TemplateParsingException”类型的异常在 RazorEngine.NET4.0.dll 中发生,但未在用户代码中进行处理 其他信息: Expected model identifier.
这个问题是由于在cshtml中 引用了model这个单词 它可能和Model在解析时有冲突. 解决方法:把model换成别的单词就可以了.
- Maven 代理设置
在maven的安装目录下 %MAVEN_HOME%/conf/setting.xml 中进行设置 <proxies> <!-- proxy | Specificatio ...
- 用django创建一个项目
首先你得安装好python和django,然后配置好环境变量,安装python就不说了,从配置环境变量开始 1.配置环境变量 在我的电脑处点击右键,或者打开 控制面板\系统和安全\系统 -> 左 ...