hbase的架构
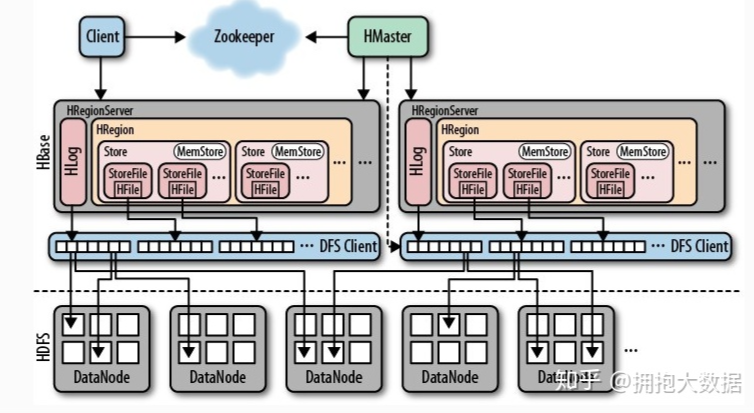
HBase中的存储包括HMaster、HRegionSever、HRegion、HLog、Store、MemStore、StoreFile、HFile等角色构成,具体如下
HMaster的作用
1.为HRegionServer分配HRegion
2.负责HRegionServer的负载均衡
3.发现失效的HRegionServer并重新分配
4.HDFS上的垃圾文件回收
5.处理Schema更新请求
HRegionServer的作用
1.维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求
2.负责切分正在运行过程中变得过大的HRegion可以看到,Client访问HBase上的数据并不需要HMaster参与,寻址访问ZooKeeper和HRegionServer,数据读写访问HRegionServer,HMaster仅仅维护Table和Region的元数据信息,Table的元数据信息保存在ZooKeeper上,负载很低。HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列簇创建一个Store对象,每个Store都会有一个MemStore和0或多个StoreFile与之对应,每个StoreFile都会对应一个HFile,HFile就是实际的存储文件。因此,一个HRegion有多少列簇就有多少个Store。
3 一个HRegionServer会有多个HRegion和一个HLog。
HRegion的作用
Table在行的方向上分割为多个HRegion,HRegion是HBase中分布式存储和负载均衡的最小单元,即不同的HRegion可以分别在不同的HRegionServer上,但同一个HRegion是不会拆分到多个HRegionServer上的。HRegion按大小分割,每个表一般只有一个HRegion,随着数据不断插入表,HRegion不断增大,当HRegion的某个列簇达到一个阀值(默认256M)时就会分成两个新的HRegion。 1、<表名,StartRowKey, 创建时间> 2、由目录表(-ROOT-和.META.)记录该Region的EndRowKey HRegion定位:HRegion被分配给哪个HRegionServer是完全动态的,所以需要机制来定位HRegion具体在哪个HRegionServer,HBase使用三层结构来定位HRegion: 1、通过zk里的文件/hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。 2、通过-ROOT-表查找.META.表的第一个表中相应的HRegion位置。其实-ROOT-表是.META.表的第一个region; .META.表中的每一个Region在-ROOT-表中都是一行记录。 3、通过.META.表找到所要的用户表HRegion的位置。用户表的每个HRegion在.META.表中都是一行记录。 -ROOT-表永远不会被分隔为多个HRegion,保证了最多需要三次跳转,就能定位到任意的region。Client会将查询的位置信息保存缓存起来,缓存不会主动失效,因此如果Client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的HRegion,其中三次用来发现缓存失效,另外三次用来获取位置信息。 Store
每一个HRegion由一个或多个Store组成,至少是一个Store,HBase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个MemStore和0或者多个StoreFile组成。 HBase以Store的大小来判断是否需要切分HRegion。
MemStore
MemStore 是放在内存里的,保存修改的数据即keyValues。当MemStore的大小达到一个阀值(默认64MB)时,MemStore会被Flush到文件,
即生成一个快照。目前HBase会有一个线程来负责MemStore的Flush操作。
StoreFile
MemStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
HFile
HBase中KeyValue数据的存储格式,是Hadoop的二进制格式文件。 首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。hbase的优化
写入数据方面
Auto Flash
通过调用HTable.setAutoFlushTo(false)方法可以将HTable写客户端自动flush关闭,这样可以批量写入数据到HBase,而不是有一条put就执行一次更新,只有当put填满客户端写缓存的时候,才会向HBase服务端发起写请求。默认情况下auto flush是开启的。
Write Buffer
通过调用HTable.setWriteBufferSize(writeBufferSize)方法可以设置HTable客户端的写buffer大小,如果新设置的buffer小于当前写buffer中的数据时,buffer将会被flush到服务端。其中,writeBufferSize的单位是byte字节数,可以根基实际写入数据量的多少来设置该值。
WAL Flag
在HBase中,客户端向集群中的RegionServer提交数据时(Put/Delete操作),首先会写到WAL(Write Ahead Log)日志,即HLog,一个RegionServer上的所有Region共享一个HLog,只有当WAL日志写成功后,再接着写MemStore,然后客户端被通知提交数据成功,如果写WAL日志失败,客户端被告知提交失败,这样做的好处是可以做到RegionServer宕机后的数据恢复。
对于不太重要的数据,可以在Put/Delete操作时,通过调用Put.setWriteToWAL(false)或Delete.setWriteToWAL(false)函数,放弃写WAL日志,以提高数据写入的性能。
注:如果关闭WAL日志,一旦RegionServer宕机,Put/Delete的数据将会无法根据WAL日志进行恢复。
Compression 压缩
数据量大,边压边写也会提升性能的,毕竟IO是大数据的最严重的瓶颈,哪怕使用了SSD也是一样。众多的压缩方式中,推荐使用SNAPPY。从压缩率和压缩速度来看,性价比最高。
HColumnDescriptor hcd = new HColumnDescriptor(familyName);
hcd.setCompressionType(Algorithm.SNAPPY);
批量写
通过调用HTable.put(Put)方法可以将一个指定的row key记录写入HBase,同样HBase提供了另一个方法:通过调用HTable.put(List<Put>)方法可以将指定的row key列表,批量写入多行记录,这样做的好处是批量执行,只需要一次网络I/O开销,这对于对数据实时性要求高,网络传输RTT高的情景下可能带来明显的性能提升。
多线程并发写
在客户端开启多个 HTable 写线程,每个写线程负责一个 HTable 对象的 flush 操作,这样结合定时 flush 和写 buffer(writeBufferSize),可以既保证在数据量小的时候,数据可以在较短时间内被 flush(如1秒内),同时又保证在数据量大的时候,写 buffer 一满就及时进行 flush。读数据方面
批量读
通过调用 HTable.get(Get) 方法可以根据一个指定的 row key 获取一行记录,同样 HBase 提供了另一个方法:通过调用 HTable.get(List) 方法可以根据一个指定的 row key 列表,批量获取多行记录,这样做的好处是批量执行,只需要一次网络 I/O 开销,这对于对数据实时性要求高而且网络传输 RTT 高的情景下可能带来明显的性能提升。
缓存查询结果
对于频繁查询 HBase 的应用场景,可以考虑在应用程序中做缓存,当有新的查询请求时,首先在缓存中查找,如果存在则直接返回,不再查询 HBase;否则对 HBase 发起读请求查询,然后在应用程序中将查询结果缓存起来。至于缓存的替换策略,可以考虑 LRU 等常用的策略。
数据及集群管理
预分区
默认情况下,在创建HBase表的时候会自动创建一个Region分区,当导入数据的时候,所有的HBase客户端都向Region写数据,知道这个Region足够大才进行切分,一种可以加快批量写入速度的方法是通过预先创建一些空的Regions,这样当数据写入HBase的时候,会按照Region分区情况,在进群内做数据的负载均衡。
Rowkey优化
rowkey是按照字典存储,因此设置rowkey时,要充分利用排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放到一块。
rowkey若是递增生成的,建议不要使用正序直接写入,可以使用字符串反转方式写入,使得rowkey大致均衡分布,这样设计的好处是能将RegionServer的负载均衡,否则容易产生所有新数据都在集中在一个RegionServer上堆积的现象,这一点还可以结合table的与分区设计。
减少Column Family数量
不要在一张表中定义太多的column family。目前HBase并不能很好的处理超过2-3个column family的表,因为某个column family在flush的时候,它临近的column family也会因关联效应被触发flush,最终导致系统产生更过的I/O;
设置最大版本数
创建表的时候,可以通过 HColumnDescriptor.setMaxVersions(int maxVersions) 设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置 setMaxVersions(1)。
缓存策略(setCaching)
创建表的时候,可以通过HColumnDEscriptor.setInMemory(true)将表放到RegionServer的缓存中,保证在读取的时候被cache命中。
设置存储生命期
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命周期,过期数据将自动被删除
磁盘配置
每台RegionServer管理10-1000个Regions。每个Region在1-2G,则每台server最少要10G,最大要1000*2G=2TB,考虑3备份,需要6TB。方案1是3块2TB磁盘,2是12块500G磁盘,带宽足够时,后者能提供更大的吞吐率,更细力度的冗余备份,更快速的单盘故障恢复。
分配何时的内存给RegionServer
在不影响其他服务的情况下,越大越好。在HBase的conf目录下的hbase-env.sh的最后添加export HBASE_REGIONSERVER_OPTS="- Xmx16000m $HBASE_REGIONSERVER_OPTS"
其中16000m为分配给REgionServer的内存大小。
写数据的备份数
备份数与读性能是成正比,与写性能成反比,且备份数影响高可用性。有两种配置方式,一种是将hdfs-site.xml拷贝到hbase的conf目录下,然后在其中添加或修改配置项dfs.replication的值为要设置的备份数,这种修改所有的HBase用户都生效。另一种方式是改写HBase代码,让HBase支持针对列族设置备份数,在创建表时,设置列族备份数,默认为3,此种备份数支队设置的列族生效。
客户端一次从服务器拉取的数量
通过配置一次拉取较大的数据量可以减少客户端获取数据的时间,但是他会占用客户端的内存,有三个地方可以进行配置
在HBase的conf配置文件中进行配置hbase.client.scanner.caching;
通过调用HTble.setScannerCaching(int scannerCaching)进行配置;
通过调用Sacn.setCaching(int caching)进行配置,三者的优先级越来越高。
客户端拉取的时候指定列族
scan是指定需要column family,可以减少网络传输数据量,否则默认scan操作会返回整行所有column family的数据
拉取完数据之后关闭ResultScanner
通过 scan 取完数据后,记得要关闭 ResultScanner,否则 RegionServer 可能会出现问题(对应的 Server 资源无法释放)。
RegionServer的请求处理IO线程数
较少的IO线程适用于处理单次请求内存消耗较高的Big Put场景(大容量单词Put或设置了较大cache的scan,均数据Big Put)或RegionServer的内存比较紧张的场景。
较多的IO线程,适用于单次请求内存消耗低,TPS要求(每次事务处理量)非常高的场景。这只该值的时候,以监控内存为主要参考
在hbase-site.xml配置文件中配置项为hbase.regionserver.handle.count
Region大小设置
配置项hbase.hregion.max.filesize,所属配置文件为hbase-site.xml,默认大小是256m。
在当前RegionServer上单个Region的最大存储空间,单个Region超过该值时,这个Region会被自动split成更小的Region。小Region对split和compaction友好,因为拆分Region或compact小Region里的StoreFile速度非常快,内存占用低。缺点是split和compaction会很频繁,特别是数量较多的小Region不同的split,compaction,会导致集群响应时间波动很大,Region数量太多不仅给管理上带来麻烦,设置会引起一些HBase个bug。一般 512M 以下的都算小 Region。大 Region 则不太适合经常 split 和 compaction,因为做一次 compact 和 split 会产生较长时间的停顿,对应用的读写性能冲击非常大。
此外,大 Region 意味着较大的 StoreFile,compaction 时对内存也是一个挑战。如果你的应用场景中,某个时间点的访问量较低,那么在此时做 compact 和 split,既能顺利完成 split 和 compaction,又能保证绝大多数时间平稳的读写性能。compaction 是无法避免的,split 可以从自动调整为手动。只要通过将这个参数值调大到某个很难达到的值,比如 100G,就可以间接禁用自动 split(RegionServer 不会对未到达 100G 的 Region 做 split)。再配合 RegionSplitter 这个工具,在需要 split 时,手动 split。手动 split 在灵活性和稳定性上比起自动 split 要高很多,而且管理成本增加不多,比较推荐 online 实时系统使用。内存方面,小 Region 在设置 memstore 的大小值上比较灵活,大 Region 则过大过小都不行,过大会导致 flush 时 app 的 IO wait 增高,过小则因 StoreFile 过多影响读性能。hbase的架构的更多相关文章
- Hbase系统架构
HBase 系统架构 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列 ...
- HBase 系统架构
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型.它存储的是 ...
- Hbase的架构原理、核心概念
Hbase的架构原理.核心概念 1.Hbase的表.行.列.列族 2.核心组件: Table和region Table在行的方向上分割为多个HRegion, 一个region由[startkey,en ...
- HBase体系架构和集群安装
大家好,今天分享的是HBase体系架构和HBase集群安装.承接上两篇文章<HBase简介>和<HBase数据模型>,点击回顾这2篇文章,有助于更好地理解本文. 一.HBase ...
- HBase系统架构及数据结构(转)
原文链接:Hbase系统架构及数据结构 HBase中的表一般有这样的特点: 1 大:一个表可以有上亿行,上百万列 2 面向列:面向列(族)的存储和权限控制,列(族)独立检索. 3 稀疏:对于为空(nu ...
- Hbase系统架构简述
由于最近要开始深入的学习一下hbase,所以,先大概了解了hbase的基本架构,在此简单的记录一下. Hbase的逻辑视图 Hbase的物理存储 HRegion Table中所有行都按照row key ...
- HBase 系统架构及数据结构
一.基本概念 2.1 Row Key (行键) 2.2 Column Family(列族) 2.3 Column Qualifier (列限定符) 2.4 Column ...
- HBase 学习之路(二)—— HBase系统架构及数据结构
一.基本概念 一个典型的Hbase Table 表如下: 1.1 Row Key (行键) Row Key是用来检索记录的主键.想要访问HBase Table中的数据,只有以下三种方式: 通过指定的R ...
- HBase 系列(二)—— HBase 系统架构及数据结构
一.基本概念 一个典型的 Hbase Table 表如下: 1.1 Row Key (行键) Row Key 是用来检索记录的主键.想要访问 HBase Table 中的数据,只有以下三种方式: 通过 ...
- 分布式结构化存储系统-HBase基本架构
分布式结构化存储系统-HBase基本架构 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在大数据领域中,除了直接以文件形式保存数据外,还有大量结构化和半结构化的数据,这类数据通常需 ...
随机推荐
- 9.150 Predefined macros
9.150 Predefined macros The ARM compiler predefines a number of macros. These macros provide informa ...
- windows中如何将python脚本以服务运行
一.下载nssm工具 NSSM介绍 NSSM(the Non-Sucking Service Manager)是Windows环境下一款免安装的服务管理软件,它可以将应用封装成服务,使之像window ...
- 全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:38 Python 常用复合数据类型-使用列表实现堆栈.队列和双端队列 摘要: 在 Python 中,列表(list)是一种非常灵活的数据结构,可以用来实现堆栈(st ...
- 【前端js】之小数点保留时的四舍五入问题
项目遇到金额小数点保留位数,极个别的数会差一分,经调查是因为js的问题. 解决办法: # 方法一:保留两位小数 function keepTwoDecimal(num) { var result = ...
- spark 怎么读写 elasticsearch
参考文章: https://www.bmc.com/blogs/spark-elasticsearch-hadoop/ https://blog.pythian.com/updating-elasti ...
- 小tips:npm与npx的区别
npm npm是Node.js的软件包管理器,其目标是自动化的依赖性和软件包管理. 这意味着,可以在package.json文件中为项目指定所有依赖项(软件包),当需要为其安装依赖项时,只要运行npm ...
- C++17新特性探索:拥抱std::optional,让代码更优雅、更安全
std::optional 背景 在编程时,我们经常会遇到可能会返回/传递/使用一个确定类型对象的场景.也就是说,这个对象可能有一个确定类型的值也可能没有任何值.因此,我们需要一种方法来模拟类似指针的 ...
- Yarn 3.0 Plug'n'Play (PnP) 安装和迁移
前言 以前用 npm, 后来 yarn 火了就用 yarn. 后来 yarn 2.0 大改版, Angular 不支持就一直没用. 一直到去年的 Angular 13 才开始支持. 最近又开始写 An ...
- ASP.NET Core Library – Excel 读写
前言 以前写过 EPPlus 的笔记, 但后来 EPPlus 开始收费了.... (这好像是 .NET 生态的宿命) 在找替代方案中看中了微软的 Open XML SDK. 但经过一番折腾, 它确实太 ...
- 阿里面试让聊一聊Redis 的内存淘汰(驱逐)策略
大家好,我是 V 哥,粉丝小A面试阿里,说被问到 Redis 的内存淘汰策略的问题,整理这个笔记给他参考,也分享给大家,如果你遇到这个问题,会怎么回答呢? Redis 的内存淘汰策略是指当Redis的 ...