理清Java中的编码解码转换
1、字符集及编码方式
概括:字符编码方式及大端小端
详细:彻底理解字符编码
可以通过Charset.availableCharsets()获取Java支持的字符集,以JDK8为例,得到其支持的字符集:
SortedMap<String, Charset> charsets = Charset.availableCharsets();
System.out.println(charsets.size());
for (String key : charsets.keySet()) {
System.out.println(key + ": " + charsets.get(key));
} //结果
169
Big5: Big5
Big5-HKSCS: Big5-HKSCS
CESU-8: CESU-8
EUC-JP: EUC-JP
EUC-KR: EUC-KR
GB18030: GB18030
GB2312: GB2312
GBK: GBK
IBM-Thai: IBM-Thai
IBM00858: IBM00858
IBM01140: IBM01140
IBM01141: IBM01141
IBM01142: IBM01142
IBM01143: IBM01143
IBM01144: IBM01144
IBM01145: IBM01145
IBM01146: IBM01146
IBM01147: IBM01147
IBM01148: IBM01148
IBM01149: IBM01149
IBM037: IBM037
IBM1026: IBM1026
IBM1047: IBM1047
IBM273: IBM273
IBM277: IBM277
IBM278: IBM278
IBM280: IBM280
IBM284: IBM284
IBM285: IBM285
IBM290: IBM290
IBM297: IBM297
IBM420: IBM420
IBM424: IBM424
IBM437: IBM437
IBM500: IBM500
IBM775: IBM775
IBM850: IBM850
IBM852: IBM852
IBM855: IBM855
IBM857: IBM857
IBM860: IBM860
IBM861: IBM861
IBM862: IBM862
IBM863: IBM863
IBM864: IBM864
IBM865: IBM865
IBM866: IBM866
IBM868: IBM868
IBM869: IBM869
IBM870: IBM870
IBM871: IBM871
IBM918: IBM918
ISO-2022-CN: ISO-2022-CN
ISO-2022-JP: ISO-2022-JP
ISO-2022-JP-2: ISO-2022-JP-2
ISO-2022-KR: ISO-2022-KR
ISO-8859-1: ISO-8859-1
ISO-8859-13: ISO-8859-13
ISO-8859-15: ISO-8859-15
ISO-8859-2: ISO-8859-2
ISO-8859-3: ISO-8859-3
ISO-8859-4: ISO-8859-4
ISO-8859-5: ISO-8859-5
ISO-8859-6: ISO-8859-6
ISO-8859-7: ISO-8859-7
ISO-8859-8: ISO-8859-8
ISO-8859-9: ISO-8859-9
JIS_X0201: JIS_X0201
JIS_X0212-1990: JIS_X0212-1990
KOI8-R: KOI8-R
KOI8-U: KOI8-U
Shift_JIS: Shift_JIS
TIS-620: TIS-620
US-ASCII: US-ASCII
UTF-16: UTF-16
UTF-16BE: UTF-16BE
UTF-16LE: UTF-16LE
UTF-32: UTF-32
UTF-32BE: UTF-32BE
UTF-32LE: UTF-32LE
UTF-8: UTF-8
windows-1250: windows-1250
windows-1251: windows-1251
windows-1252: windows-1252
windows-1253: windows-1253
windows-1254: windows-1254
windows-1255: windows-1255
windows-1256: windows-1256
windows-1257: windows-1257
windows-1258: windows-1258
windows-31j: windows-31j
x-Big5-HKSCS-2001: x-Big5-HKSCS-2001
x-Big5-Solaris: x-Big5-Solaris
x-euc-jp-linux: x-euc-jp-linux
x-EUC-TW: x-EUC-TW
x-eucJP-Open: x-eucJP-Open
x-IBM1006: x-IBM1006
x-IBM1025: x-IBM1025
x-IBM1046: x-IBM1046
x-IBM1097: x-IBM1097
x-IBM1098: x-IBM1098
x-IBM1112: x-IBM1112
x-IBM1122: x-IBM1122
x-IBM1123: x-IBM1123
x-IBM1124: x-IBM1124
x-IBM1364: x-IBM1364
x-IBM1381: x-IBM1381
x-IBM1383: x-IBM1383
x-IBM300: x-IBM300
x-IBM33722: x-IBM33722
x-IBM737: x-IBM737
x-IBM833: x-IBM833
x-IBM834: x-IBM834
x-IBM856: x-IBM856
x-IBM874: x-IBM874
x-IBM875: x-IBM875
x-IBM921: x-IBM921
x-IBM922: x-IBM922
x-IBM930: x-IBM930
x-IBM933: x-IBM933
x-IBM935: x-IBM935
x-IBM937: x-IBM937
x-IBM939: x-IBM939
x-IBM942: x-IBM942
x-IBM942C: x-IBM942C
x-IBM943: x-IBM943
x-IBM943C: x-IBM943C
x-IBM948: x-IBM948
x-IBM949: x-IBM949
x-IBM949C: x-IBM949C
x-IBM950: x-IBM950
x-IBM964: x-IBM964
x-IBM970: x-IBM970
x-ISCII91: x-ISCII91
x-ISO-2022-CN-CNS: x-ISO-2022-CN-CNS
x-ISO-2022-CN-GB: x-ISO-2022-CN-GB
x-iso-8859-11: x-iso-8859-11
x-JIS0208: x-JIS0208
x-JISAutoDetect: x-JISAutoDetect
x-Johab: x-Johab
x-MacArabic: x-MacArabic
x-MacCentralEurope: x-MacCentralEurope
x-MacCroatian: x-MacCroatian
x-MacCyrillic: x-MacCyrillic
x-MacDingbat: x-MacDingbat
x-MacGreek: x-MacGreek
x-MacHebrew: x-MacHebrew
x-MacIceland: x-MacIceland
x-MacRoman: x-MacRoman
x-MacRomania: x-MacRomania
x-MacSymbol: x-MacSymbol
x-MacThai: x-MacThai
x-MacTurkish: x-MacTurkish
x-MacUkraine: x-MacUkraine
x-MS932_0213: x-MS932_0213
x-MS950-HKSCS: x-MS950-HKSCS
x-MS950-HKSCS-XP: x-MS950-HKSCS-XP
x-mswin-936: x-mswin-936
x-PCK: x-PCK
x-SJIS_0213: x-SJIS_0213
x-UTF-16LE-BOM: x-UTF-16LE-BOM
X-UTF-32BE-BOM: X-UTF-32BE-BOM
X-UTF-32LE-BOM: X-UTF-32LE-BOM
x-windows-50220: x-windows-50220
x-windows-50221: x-windows-50221
x-windows-874: x-windows-874
x-windows-949: x-windows-949
x-windows-950: x-windows-950
x-windows-iso2022jp: x-windows-iso2022jp
2、Java中的几种编码格式
2.1、文件、项目、工作空间的编码格式
默认是【文件编码格式】继承于【项目编码格式】继承于【工作空间编码格式】继承于【系统编码格式】。都可以自己设置。
以eclipse里为例:
- 【工作空间编码格式】设置:在Winodws->Preferences->General->Workspace里设置Text file encoding,默认继承于【系统编码格式】如简体中文环境下是GBK。这样每次新建工程默认都会以此编码
- 【项目编码格式】设置:在项目右键->Source里设置Text file encoding,默认继承于【工作空间编码格式】。这样在项目下新建文件如java源文件会以此编码。
- 【文件编码格式】设置:在文件右键->Source里设置Text file encoding,默认继承于【项目编码格式】。
值得注意的是,若在eclipse里保存了.java文件后又用上述方式修改了该文件的编码方式,则可能会出现乱码,并且新输入的代码可能也保存不了,提示输入的有些字符无法用当前编码方式映射保存。乱码原因是用新指定的编码格式来解码原来格式编码成的文件,保存不了原因是新输入的有些字符如中文无法用新编码格式如ISO8859-1编码。所以要修改已写好的.java文件的编码方式,为避免乱码等问题可以在文本编辑器中打开并另存为其他格式。
2.2、运行环境的编码格式
和外部进行数据交换(如读文件时)的时候所用的编码格式。可以通过 Charset.defaultCharset().name() 查看默认编码格式,继承于【文件编码格式】。
Charset.defaultCharset()方法如下:可见 Charset.defaultCharset()优先采用 [调用此方法(直接或间接调用)的main函数所在的文件的] file.encoding,无法确认的话用UTF-8,
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
String csn = AccessController.doPrivileged(
new GetPropertyAction("file.encoding"));
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}
需要注意的是,上面的file.encoding指的是main函数所在文件的编码方式,而不是Charset.defaultCharset()代码所在文件的编码方式。如有file1.java、file2.java两个文件,其编码方式不同,file1.java有个静态方法getFileEncoding()返回Charset.defaultCharset(),则file2.java里调用file1.getFileEncoding()得到的是file2.java的编码方式。
另,可在程序里获取file.encoding等system properties:
Properties prop = System.getProperties();
Iterator it = prop.keySet().iterator();
while (it.hasNext()) {
String key = it.next().toString();
System.out.println(key + ": " + prop.getProperty(key));
}
结果中有几个值得注意的属性:
file.encoding: UTF-16 //即前面提到的file.encoding
sun.jnu.encoding: GBK //网上说与文件命名、命令行参数等有关
sun.io.unicode.encoding: UnicodeLittle //应该是Java内部编码,UTF-16L
sun.cpu.endian: little //CPU为小端
这里的file.encoding指的是main函数所在文件的编码方式。
2.3、内部的编码格式
Unicode-16编码,是Java程序内部所用的编码格式。所有外部字符内容在Java 程序内全部转换成此编码格式。
.java文件中的字符串等(3.1)、外部文件、网络资源、数据库资源等读入后转为内部编码格式的数据;写出时从内部编码格式转为指定格式的数据;字符串在内存中也可按指定编码格式进行转换(3.2)。详见章节3。
3、Java中的数据编解码转换
.class文件:UTF-8格式
JVM内部:UTF-16格式
解码:
读:从外部读入(转换为Java内部编码UTF-16):read;用于显示:文本编辑器打开显示
解码成字符(串):new string(byte[])
编码:
写:用于保存或输出到外部(与字符流相关的才需编码,将字符按编码方式转成字节流后输出;若是字节流则直接输出,无需编码)或与外界(网络、数据库等)交互:与字符相关的write,如InputStreamReader、OutputStreamWriter、BufferedWriter等
转变成字节:String.getBytes()
字符(串)与byte[]之间转换时需要提供编码格式参数(然而很多时候我们没提供,其实此时采用了默认格式,即file.encoding)
String值始终是以内部编码格式(UTF-16)存储
3.1、默认转换:Java源文件到.class文件到内存
即编译器根据.java文件的编码格式读出其中的内容并编译成UTF-8格式的.class文件,包括字符串等;运行时JVM按UTF-8格式读取.class文件到内存中。
- 保存:保存.java文件时,以file.encoding将文件内容编码成二进制存入文件。
- 编译:运行javac时若没有用-encoding参数指定源文件的编码方式,则以默认格式Charset.defaultCharset()即file.encoding来解码.java文件并编译成UTF-8格式.class文件。
- 运行:运行Java程序时JVM以UTF-8格式解码.class文件并读入到内存中,此时包括字符串等都以UTF-16格式存在于内存中了。
上述过程一般不需用户干预,除非用户指定其他参数否则可以看出其就是用file.encoding格式来读.java文件并转成内部UTF-16格式的数据,因此这些默认转换一般不会出错。
3.2、运行中转换:网络文件、本地文件、数据库中的内容等
3.2.1、读入
- 从本地文件中读到内存:按字节读流的话结果(byte[])与程序运行环境的编码格式方式无关,只与文件的编码方式有关;按字符(串)读则与运行环境采用什么编码格式有关,需要将之指定为本地文件的编码方式或父集。这样在读时会以指定编码格式来解码被读取的文件,转变成内部的UTF-16格式于内存中。
- 从网络文件中读到内存:与上类似。对于与浏览器交互的程序,如Servlet、JSP(也是转换成Servlet放在Web容器临时目录)等,若没有指定编码方式,则默认以ISO8859-1解码接收到的参数、编码返回的数据给浏览器。过程图如下:
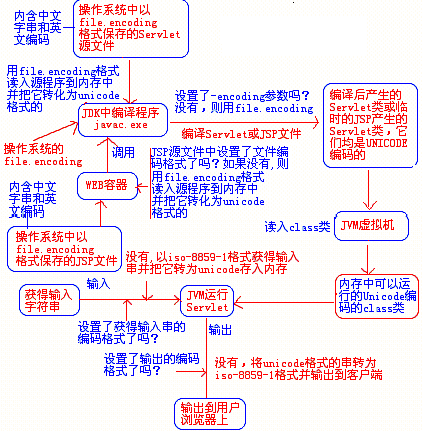
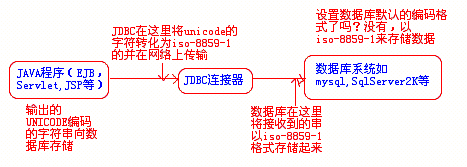
- 从数据库中读取到内存:与上类似,只不过默认编码格式也为8859-1。对于几乎所有数据库的JDBC驱动程序,默认的在JAVA程序和数据库之间传递数据都是以ISO-8859-1为默认编码格式的,所以,我们的程序在向数据库内存储包含中文的数据时,JDBC首先是把程序内部的UNICODE编码格式的数据转化为ISO-8859-1的格式,然后传递到数据库中,在数据库保存数据时,它默认即以ISO-8859-1保存。所以,这是为什么我们常常在数据库中读出的中文数据是乱码。 过程图如下:
3.2.2、写出
- 从内存中写入到文件:将内存中UTF-16格式的内容 编码成 程序运行环境的编格式的内容,写出到文件。
- 内存中转换:
- 内存中数据编码格式转换:转换时一般都要指定某种编码格式,未指定的话采用Charset.defaultCharset()即file.encoding
- String转byte[]如getBytes():Java内部编码格式(UTF-16)的数据转换成指定格式的数据
- byte[]转String:以指定格式将byte[]数据解码成字符串
- 其他
- 内存中数据编码格式转换:转换时一般都要指定某种编码格式,未指定的话采用Charset.defaultCharset()即file.encoding
3.2.3、console交互:(包含上述的读和写过程)
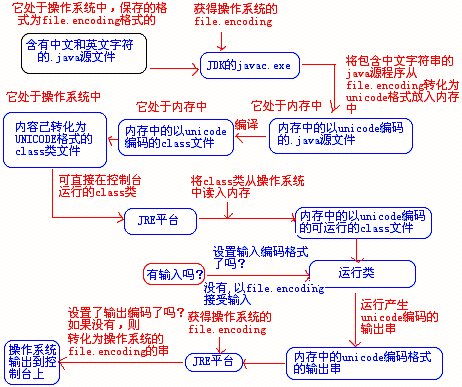
- 这种情况,运行该类首先需要JVM支持,即操作系统中必须安装有JRE。运行过程是这样的:首先java启动JVM,此时JVM读出操作系统中保存的class文件并把内容读入内存中,此时内存中为UNICODE格式的class类,然后JVM运行它,如果此时此类需要接收用户输入,则类会默认用file.encoding编码格式对用户输入的串进行编码并转化为unicode保存入内存(用户可以设置输入流的编码格式)。程序运行后,产生的字符串(UNICODE编码的)再回交给JVM,最后JRE把此字符串再转化为file.encoding格式(用户可以设置输出流的编码格式)传递给操作系统显示接口并输出到界面上。 过程图如下:
以 下面代码为例,涉及到多次编解码转换(假定文件以UTF-8编码即file.encoding为UTF-8):
FileWriter fw = new FileWriter("文件1.txt");
fw.write(new String("abc".getBytes("GBK"),"UTF-16"));
fw.close();
- 默认转换
- 编码:保存.java源文件时,"abc"在文件中以file.encoding的格式编码成二进制存着。
- 解码编码:编译时,编译器以file.encoding格式解码.java文件并编译成Java内部编码格式即UTF-16格式的.class文件。
- 解码:程序运行时,JVM加载.class文件,以内部编码格式UTF-16解码.class文件,故"abc"以此格式存在内存中。
- 程序中转换
- 编码:"abc".getBytes("GBK")将内存中UTF-16格式的"abc"编码成GBK格式,得到字节数组。
- 解码:new String(bytes,"UTF-16"))将上步的GBK格式的字节数组解码成UTF-16的字符串。
- 编码:fw.write()以FileWriter的默认编码方式Charset.defaultCharset()将上步的String编码成二进制写到文件里,当然也可以指定所用的编码方式。所以要正确显示文件里的内容,需要以写入时的相应编码方式来解码打开。
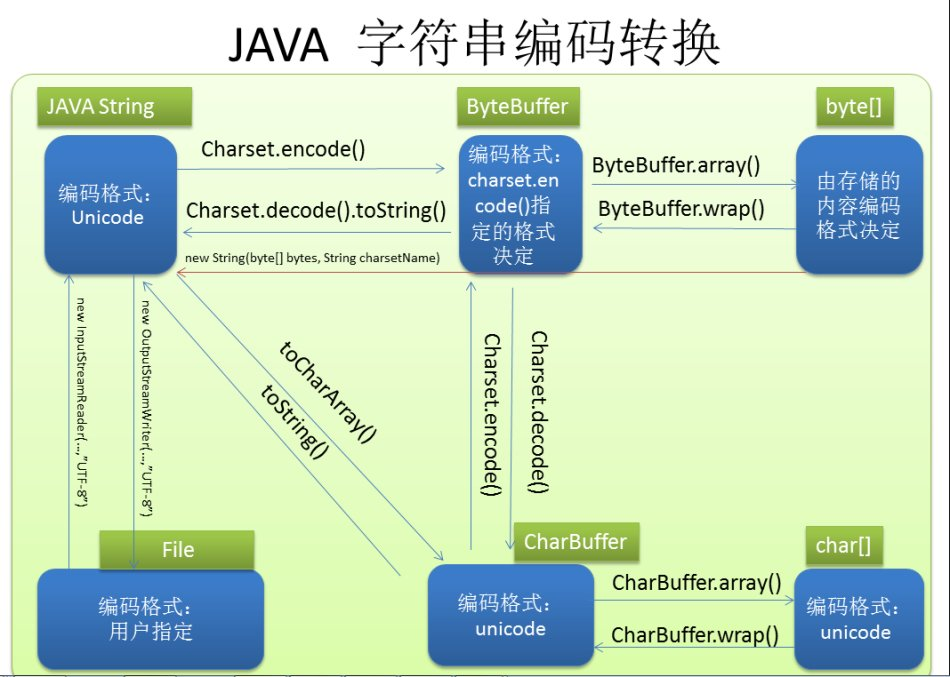
另附一张不是很贴切的图,关于String、char[]、byte[]之间的转换:
4、参考资料
[1]、http://www.voidcn.com/blog/u013678930/article/p-6166506.html
[2]、http://www.iteye.com/topic/112049
[3]、http://1035054540-qq-com.iteye.com/blog/1856060
[4]、http://www.bianceng.cn/java/j149.htm
理清Java中的编码解码转换的更多相关文章
- Java 字符编码(二)Java 中的编解码
Java 字符编码(二)Java 中的编解码 java.nio.charset 包中提供了一套处理字符编码的工具类,主要有 Charset.CharsetDecoder.CharsetEncoder. ...
- Javascript中Base64编码解码的使用实例
Javascript为我们提供了一个简单的方法来实现字符串的Base64编码和解码,分别是window.btoa()函数和window.atob()函数. 1 var encodedStr = win ...
- java中16进制转换10进制
java中16进制转换10进制 public static void main(String[] args) { String str = "04e1"; String myStr ...
- java中如何把图片转换成二进制流的代码
在学习期间,把开发过程经常用到的一些代码段做个备份,下边代码内容是关于java中如何把图片转换成二进制流的代码,应该能对各朋友也有用处. public byte[] SetImageToByteArr ...
- Java中的线程状态转换和线程控制常用方法
Java 中的线程状态转换: [注]:不是 start 之后就立刻开始执行, 只是就绪了(CPU 可能正在运行其他的线程). [注]:只有被 CPU 调度之后,线程才开始执行, 当 CPU 分配给你的 ...
- java中的进制转换
java中的进制转换及转换函数 转自:https://blog.csdn.net/V0218/article/details/74945203 Java的进制转换 进制转换原理 十进制 转 二进制: ...
- java中文乱码解决之道(六)-----javaWeb中的编码解码
在上篇博客中LZ介绍了前面两种场景(IO.内存)中的java编码解码操作,其实在这两种场景中我们只需要在编码解码过程中设置正确的编码解码方式一般而言是不会出现乱码的.对于我们从事java开发的人而言, ...
- java中文乱码解决之道(六)—–javaWeb中的编码解码
在上篇博客中LZ介绍了前面两种场景(IO.内存)中的java编码解码操作,其实在这两种场景中我们只需要在编码解码过程中设置正确的编码解码方式一般而言是不会出现乱码的.对于我们从事java开发的人而言, ...
- java IO之 编码 (码表 编码 解码 转换流)
编码 什么是编码? 计算机中存储的都是二进制,但是要显示的时候,就是我们看到的却可以有中国 ,a 1 等字符 计算机中是没有存储字符的,但是我们却看到了.计算机在存储这些信息的时候,根据一个有规 则 ...
随机推荐
- jstorm集群部署
jstorm集群部署下载 Install JStorm Take jstorm-0.9.6.zip as an example unzip jstorm-0.9.6.1.zip vi ~/.bashr ...
- Linux Process VS Thread VS LWP
Process program program==code+data; 一个进程可以对应多个程序,一个程序也可以变成多个进程.程序可以作为一种软件资源长期保存,以文件的形式存放在硬盘 process: ...
- springmvc和struts2的区别
springmvc和struts2的区别 1.springmvc基于方法开发的,struts2基于类开发的. 2.单例和多例的区别:springmvc在映射的时候,通过形参来接收参数的,是将url和c ...
- docker核心原理
容器概念. docker是一种容器,应用沙箱机制实现虚拟化.能在一台宿主机里面独立多个虚拟环境,互不影响.在这个容器里面可以运行着我饿们的业务,输入输出.可以和宿主机交互. 使用方法. 拉取镜像 do ...
- 每天一个linux命令目录
出处:http://www.cnblogs.com/peida/archive/2012/12/05/2803591.html 开始详细系统的学习linux常用命令,坚持每天一个命令,所以这个系列为每 ...
- Android的NDK技术
Android的NDK技术
- windows 2012 r2下安装sharepoint 2013错误解决
日前,我在安装sharepoint 2013时,需要预部署一些软件,我们知道运行产品准备工具“prerequisiteinstaller”后就可以自动下载安装配置这些软件,但是使用系统为windows ...
- Ubuntu nginx 配置404错误页面
1.创建自己的404.html页面: 2.更改nginx.conf在http定义区域加入: /etc/nginx# vim nginx.conf 下添加 fastcgi_intercept_error ...
- [WPF系列]-数据邦定之DataTemplate 对 ItemsControl 进行样式和模板处理
引言 即使 ItemsControl 不是 DataTemplate 所用于的唯一控件类型,将 ItemsControl 绑定到集合仍然很常见. 在 DataTemplate 中有哪些内容一节中, ...
- SSTABLE简介
SSTABLE数据组织:http://blog.csdn.net/tankles/article/details/7663905