Scrapy学习篇(十三)之scrapy-splash
之前我们学习的内容都是抓取静态页面,每次请求,它的网页全部信息将会一次呈现出来。 但是,像比如一些购物网站,他们的商品信息都是js加载出来的,并且会有ajax异步加载。像这样的情况,直接使用scrapy的Request请求是拿不到我们想要的信息的,解决的方法就是使用scrapy-splash。
scrapy-splash加载js数据是基于Splash来实现的,Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT,而我们使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后,拿到的渲染之后的网页源代码。
准备环节
安装docker
在windows环境下,安装docker简便的方法是使用docker toolbox,由于Docker引擎的守护进程使用的是Linux的内核,所以我们不能够直接在windows中运行docker引擎。而是需要在你的机器上创建和获得一个Linux虚拟机,用这个虚拟机才可以在你的windows系统上运行Docker引擎,docker toolbox这个工具包里面集成了windows环境下运行docker必要的工具,当然也包括虚拟机了。
首先下载docker toolbox
执行安装程序,默认情况下,你的计算机会安装以下几个程序- Windows版的Docker客户端
- Docker Toolbox管理工具和ISO镜像
- Oracle VM 虚拟机
- Git 工具
当然,如果你之前已经安装过了Oracle VM 虚拟机 或者 Git 工具 ,那么你在安装的时候可以取消勾选这两个内容,之后,你只需要狂点下一步即可。安装完毕以后,找到Docker Quickstart Terminal图标,双击运行,稍等它自己配置一小段时间,你会看到以下的界面
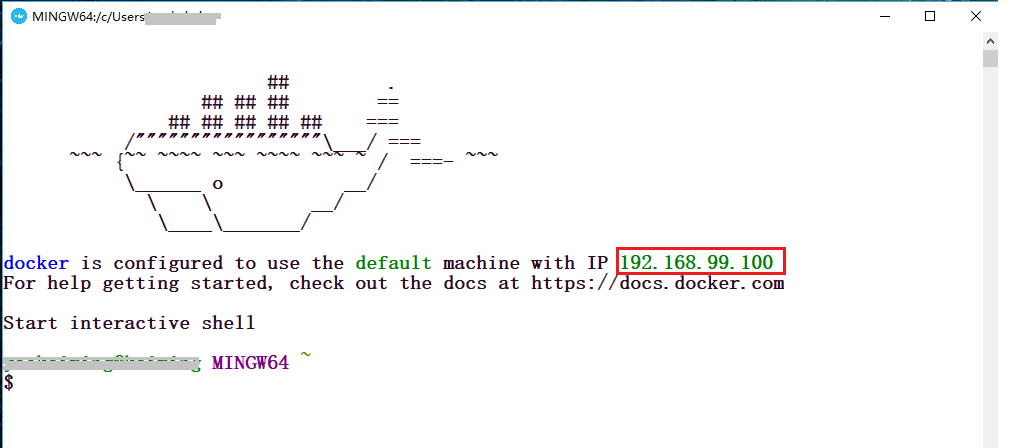
请注意上面画红框的地方,这是默认分配给你的ip,下面会用到。至此,docker工具就已经安装好了。安装Splash
双击运行Docker Quickstart Terminal,输入以下内容
docker pull scrapinghub/splash
这个命令是拉取Splash镜像,等待一算时间,就可以了。下面就是启动Splash
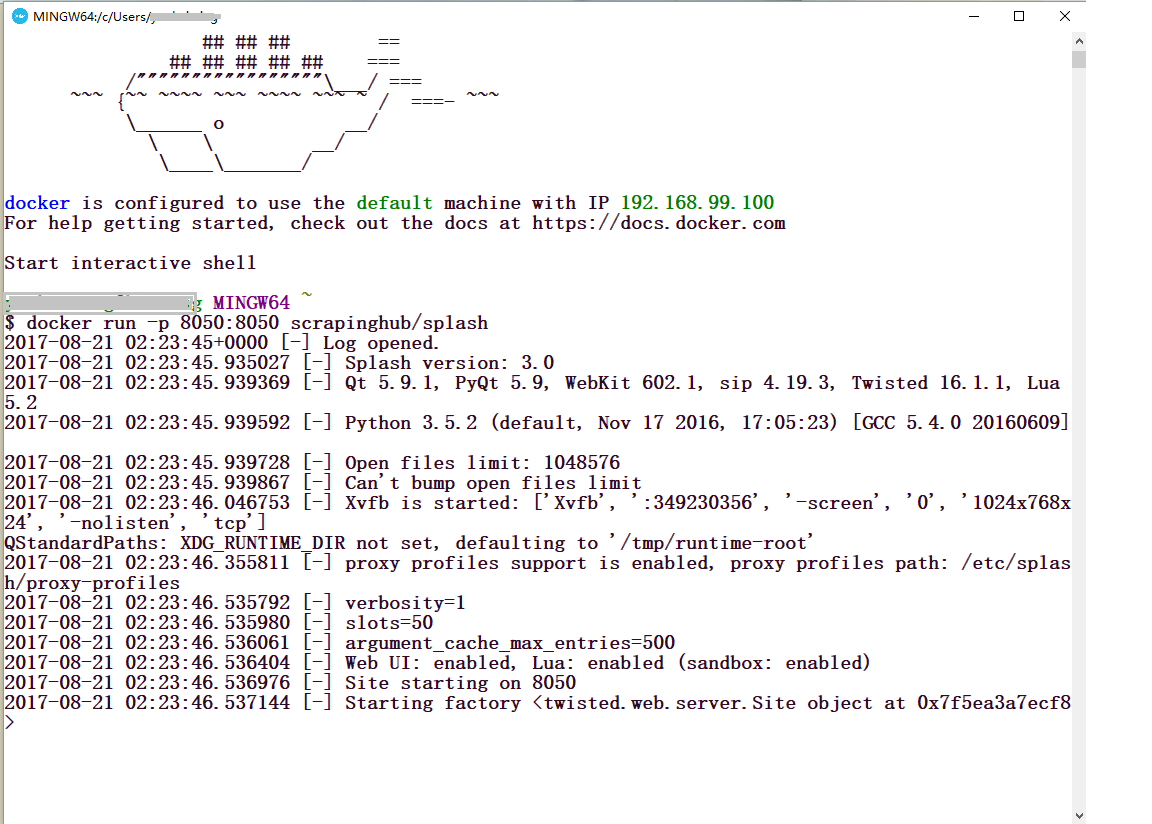
docker run -p 8050:8050 scrapinghub/splash
这个命令就是在计算机的8050端口启动Splash渲染服务
你会看到以下的图示内容。
这个时候,打开你的浏览器,输入
192.168.99.100:8050你会看到出现了这样的界面。
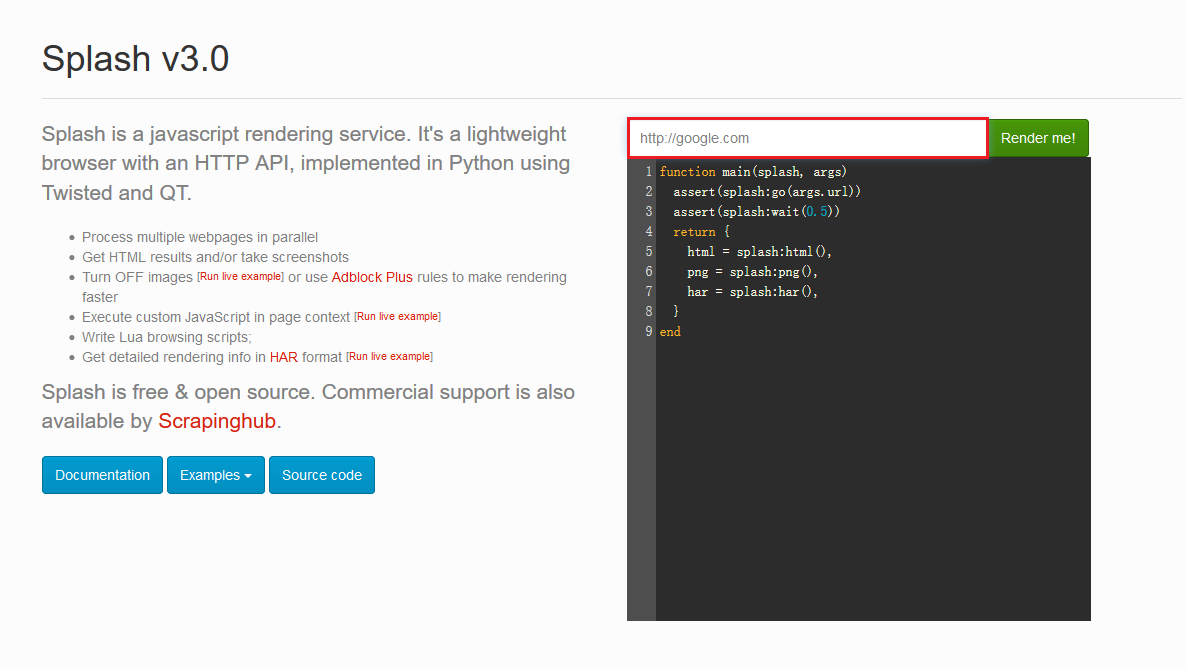
你可以在上图红色框框的地方输入任意的网址,点击后面的Render me! 来查看渲染之后的样子。安装scrapy-splash
pip install scrapy-splash至此,我们的准备环节已经全部结束了。
测试
下面我们就创建一个项目来测试一下,是否真的实现了我们想要的功能。
不使用scrapy-splash
为了有一个直观的对比,我们首先不使用scrapy- splash,来看一下是什么效果,我们以淘宝商品信息为例,新建一个名为taobao的项目,在spider.py文件里面输入下面的内容。
import scrapy
class Spider(scrapy.Spider):
name = 'taobao'
allowed_domains = []
start_urls = ['https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self,response):
titele = response.xpath('//div[@class="row row-2 title"]/a/text()').extract()
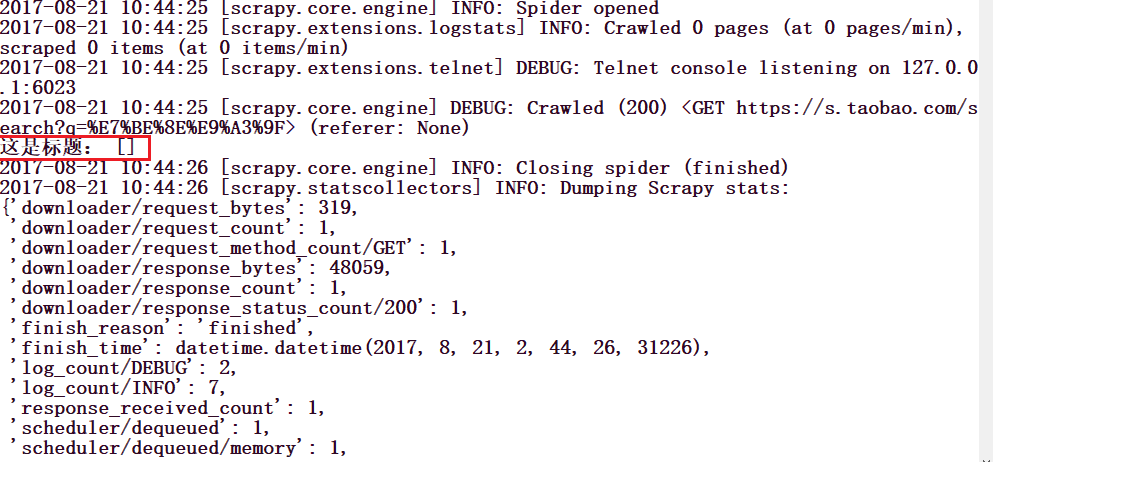
print('这是标题:', titele)
我们打印出淘宝美食的名称,你会看到这样的信息:
使用scrapy-splash
下面我们使用scrapy-splash来实现一下,看一下会出现什么样的效果:
使用scrapy-splash需要一些额外的配置,下面一一列举:
在settings.py文件中,你需要额外的填写下面的一些内容
# 渲染服务的url
SPLASH_URL = 'http://192.168.99.100:8050'
#下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
在spider.py文件中,填入下面的代码:
import scrapy
from scrapy_splash import SplashRequest
class Spider(scrapy.Spider):
name = 'taobao'
allowed_domains = []
start_urls = ['https://s.taobao.com/search?q=%E7%BE%8E%E9%A3%9F']
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url=url, callback=self.parse,
args={'wait':1}, endpoint='render.html')
def parse(self, response):
titele = response.xpath('//div[@class="row row-2 title"]/a/text()').extract()
print('这是标题:', titele)
记住不要忘记导入SplashRequest。
下面就是运行这个项目,记得在docker里面先把splash渲染服务运行起来。
结果如下图所示。

看的出来,我们需要的内容已经打印出来了,内容有点乱,我们可以使用正则来进行匹配,但是这已经不是我们这一小节的主要内容了,你可以自己尝试一下。
Scrapy学习篇(十三)之scrapy-splash的更多相关文章
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy学习篇(七)之Item Pipeline
在之前的Scrapy学习篇(四)之数据的存储的章节中,我们其实已经使用了Item Pipeline,那一章节主要的目的是形成一个笼统的认识,知道scrapy能干些什么,但是,为了形成一个更加全面的体系 ...
- Scrapy学习篇(九)之文件与图片下载
Media Pipeline Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方 ...
- Scrapy学习篇(六)之Selector选择器
当我们取得了网页的response之后,最关键的就是如何从繁杂的网页中把我们需要的数据提取出来,python从网页中提取数据的包很多,常用的有下面的几个: BeautifulSoup它基于HTML代码 ...
- Scrapy学习篇(五)之Spiders
Spiders Spider类定义了如何爬取某个网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item).简而言之,Spider就是你定义爬取的动作及分析某个网 ...
- Scrapy学习篇(一)之框架
概览 在具体的学习scrapy之前,我们先对scrapy的架构做一个简单的了解,之后所有的内容都是基于此架构实现的,在初学阶段只需要简单的了解即可,之后的学习中,你会对此架构有更深的理解.下面是scr ...
- Scrapy学习篇(八)之settings
Scrapy设定(settings)提供了定制Scrapy组件的方法.你可以控制包括核心(core),插件(extension),pipeline及spider组件.设定为代码提供了提取以key-va ...
- Scrapy学习篇(三)之创建项目和Scrapy的安装
安装Scrapy 了解了Scrapy的框架和部分命令行之后,创建项目,开始使用之前,当然是安装Scrapy框架了. 关于Scrapy框架的安装,请参考:https://cuiqingcai.com/5 ...
- Scrapy学习篇(二)之常用命令行工具
简介 Scrapy是通过Scrapy命令行工具进行控制的,包括创建新的项目,爬虫的启动,相关的设置,Scrapy提供了两种内置的命令,分别是全局命令和项目命令,顾名思义,全局命令就是在任意位置都可以执 ...
随机推荐
- 使用.htaccess文件
禁止对无索引文件的目录进行文件列表展示 默认情况下,当我们访问网站的某个无索引文件(如index.html,index.htm或 index.php)目录时,服务器会显示该目录的文件和子目录列表,这是 ...
- dir 使用,统计文件数量
dir /b /a-d | find /v /c "$$$$" >1.log--※ 来源:·水木社区 newsmth.net·[FROM: 125.46.17.*] 今天去水 ...
- as3 关闭加载流
/** Loader 取消加载**/ function closeQueueLoader():void { if (cur_loader && cur_loader.contentLo ...
- event bManualResult
MSDN: bManualReset [in] If this parameter is TRUE, the function creates a manual-reset event object, ...
- intelij创建MapReduce工程
1.创建一个maven工程 2.POM文件 <?xml version="1.0" encoding="UTF-8"?><project xm ...
- 判断是否有TrueType字体
function IsTrueTypeAvailable : bool;var {$IFDEF WIN32} rs : TRasterizerStatus; {$ELSE} rs : TRaste ...
- scala private 和 private[this] 的区别
class PackageStudy { private var a = 0 private[this] var b = 1 // 只能在类内部使用,对象都不能直接使用 def getb(): Int ...
- javascript中this之说
this是在运行时基于函数的执行环境绑定的:在全局函数中,this等于window,而当函数被作为某个对象的方法调用时,this等于那个对象.不过,匿名函数的执行环境具有全局性,因此其this对象通常 ...
- Java ReentrantLock和synchronized两种锁定机制的对比
多线程和并发性并不是什么新内容,但是 Java 语言设计中的创新之一就是,它是第一个直接把跨平台线程模型和正规的内存模型集成到语言中的主流语言.核心类库包含一个 Thread 类,可以用它来构建.启动 ...
- MySQL8 重置改root密码及开放远程访问
1. 修改配置文件 先修改配置文件:vim /etc/my.conf 在 [mysqld] 下加上下面这行 skip-grant-tables 重启 mysql 服务: service mysqld ...