java并发编程——Excutor
概述
Excutor这个接口用的不多,但是ThreadPoolExcutor这个就用的比较多了,ThreadPoolExcutor是Excutor的一个实现。Excutor体系难点没有,大部分的关键点和设计思路都在javadoc中描述的特别详细,但有必要做一下梳理,以便在后续开发场景中,更好地使用jdk提供的灵活的api。
Excutor接口主要用于解耦任务执行者和任务发起者,jdk8的javadoc写的非常详细。因此,Excutor这个系列的类都冲着这个目标来实现,当然,很多实现类更是在特定的场景领域做了加强实现,让开发者省时省心,如ThreadPoolExcutor对线程池的管理,ScheduledThreadPoolExecutor提供线程池功能的同时,还支持定时和定频任务。
An object that executes submitted
Runnabletasks. This interface provides a way of decoupling task submission from the mechanics of how each task will be run, including details of thread use, scheduling, etc.
类图
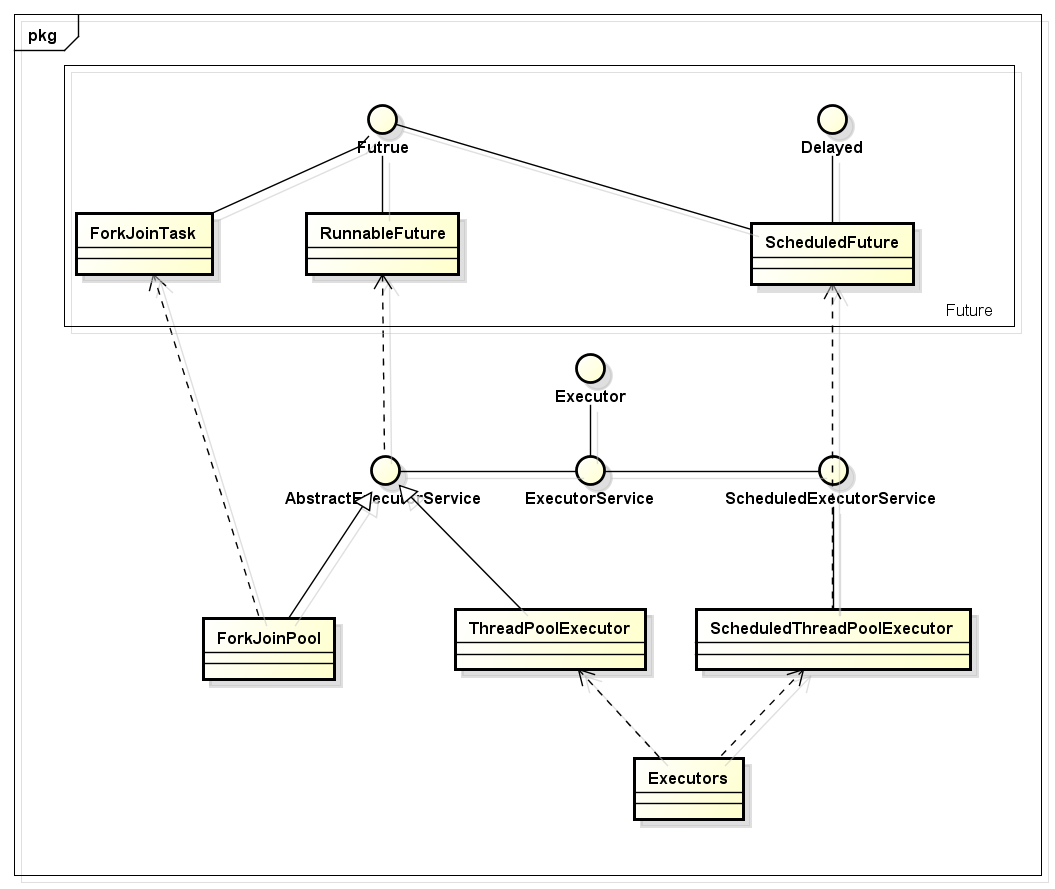
扩展的接口
ExecutorService
ExecutorService对Executor进行加强,可以跟踪/管理/停止任务。javadoc的描述:
An
Executorthat provides methods to manage termination and methods that can produce aFuturefor tracking progress of one or more asynchronous tasks.An
ExecutorServicecan be shut down, which will cause it to reject new tasks. Two different methods are provided for shutting down anExecutorService. Theshutdown()method will allow previously submitted tasks to execute before terminating, while theshutdownNow()method prevents waiting tasks from starting and attempts to stop currently executing tasks. Upon termination, an executor has no tasks actively executing, no tasks awaiting execution, and no new tasks can be submitted. An unusedExecutorServiceshould be shut down to allow reclamation of its resources.Method
submitextends base methodExecutor.execute(Runnable)by creating and returning aFuturethat can be used to cancel execution and/or wait for completion. MethodsinvokeAnyandinvokeAllperform the most commonly useful forms of bulk execution, executing a collection of tasks and then waiting for at least one, or all, to complete. (ClassExecutorCompletionServicecan be used to write customized variants of these methods.)
ExecutorService按照典型使用场景,又扩展为了AbstractExecutorService和ScheduledExecutorService ,前者作为实时任务处理的接口,后者作为定时/定频任务的处理接口。
AbstractExecutorService
AbstractExecutorService定位为实时任务的处理,因此submit返回FutureTask对象,调用方可以通过该对象对任务进行跟踪处理。
Provides default implementations of
ExecutorServiceexecution methods. This class implements thesubmit,invokeAnyandinvokeAllmethods using aRunnableFuturereturned bynewTaskFor, which defaults to theFutureTaskclass provided in this package. For example, the implementation ofsubmit(Runnable)creates an associatedRunnableFuturethat is executed and returned. Subclasses may override thenewTaskFormethods to returnRunnableFutureimplementations other thanFutureTask.
ScheduledExecutorService
ScheduledExecutorService 扩展了ExecutorService,加入了定时和定频控制;实际上ScheduledExecutorService 也支持也提供实时执行api(excute()),而且,其默认当delay参数值为0或者负数时,当着实时任务处理。ScheduledExecutorService 的submit方法返回的是ScheduledFutureTask。javadoc的描述:
An
ExecutorServicethat can schedule commands to run after a given delay, or to execute periodically.The
schedulemethods create tasks with various delays and return a task object that can be used to cancel or check execution. ThescheduleAtFixedRateandscheduleWithFixedDelaymethods create and execute tasks that run periodically until cancelled.Commands submitted using the
Executor.execute(Runnable)andExecutorServicesubmitmethods are scheduled with a requested delay of zero. Zero and negative delays (but not periods) are also allowed inschedulemethods, and are treated as requests for immediate execution.
有用的实现
ThreadPoolExecutor
ThreadPoolExecutor平时用的比较多,通常情况下,使用Executors工具类的三个方法就够用,如果需要自定义线程池,需要重点关注queue和线程池大小几个参数的配合使用。javadoc写的比较详细,摘抄下来,标粗的部分是重点:
An
ExecutorServicethat executes each submitted task using one of possibly several pooled threads, normally configured usingExecutorsfactory methods.Thread pools address two different problems: they usually provide improved performance when executing large numbers of asynchronous tasks, due to reduced per-task invocation overhead, and they provide a means of bounding and managing the resources, including threads, consumed when executing a collection of tasks. Each
ThreadPoolExecutoralso maintains some basic statistics, such as the number of completed tasks.To be useful across a wide range of contexts, this class provides many adjustable parameters and extensibility hooks. However, programmers are urged to use the more convenient
Executorsfactory methodsExecutors.newCachedThreadPool()(unbounded thread pool, with automatic thread reclamation),Executors.newFixedThreadPool(int)(fixed size thread pool) andExecutors.newSingleThreadExecutor()(single background thread), that preconfigure settings for the most common usage scenarios. Otherwise, use the following guide when manually configuring and tuning this class:
- Core and maximum pool sizes
-
A
ThreadPoolExecutorwill automatically adjust the pool size (seegetPoolSize()) according to the bounds set by corePoolSize (seegetCorePoolSize()) and maximumPoolSize (seegetMaximumPoolSize()). When a new task is submitted in methodexecute(Runnable), and fewer than corePoolSize threads are running, a new thread is created to handle the request, even if other worker threads are idle. If there are more than corePoolSize but less than maximumPoolSize threads running, a new thread will be created only if the queue is full. By setting corePoolSize and maximumPoolSize the same, you create a fixed-size thread pool. By setting maximumPoolSize to an essentially unbounded value such asInteger.MAX_VALUE, you allow the pool to accommodate an arbitrary number of concurrent tasks. Most typically, core and maximum pool sizes are set only upon construction, but they may also be changed dynamically usingsetCorePoolSize(int)andsetMaximumPoolSize(int). - 总结了下threadSize、queueSize、taskSize之间的关系图:

- On-demand construction
-
By default, even core threads are initially created and started only when new tasks arrive, but this can be overridden dynamically using method
prestartCoreThread()orprestartAllCoreThreads(). You probably want to prestart threads if you construct the pool with a non-empty queue. - Creating new threads 使用自定义的factory可以对线程进行分组,并设置不同的优先级。
-
New threads are created using a
ThreadFactory. If not otherwise specified, aExecutors.defaultThreadFactory()is used, that creates threads to all be in the sameThreadGroupand with the sameNORM_PRIORITYpriority and non-daemon status. By supplying a different ThreadFactory, you can alter the thread's name, thread group, priority, daemon status, etc. If aThreadFactoryfails to create a thread when asked by returning null fromnewThread, the executor will continue, but might not be able to execute any tasks. Threads should possess the "modifyThread"RuntimePermission. If worker threads or other threads using the pool do not possess this permission, service may be degraded: configuration changes may not take effect in a timely manner, and a shutdown pool may remain in a state in which termination is possible but not completed. - Keep-alive times
-
If the pool currently has more than corePoolSize threads, excess threads will be terminated if they have been idle for more than the keepAliveTime (see
getKeepAliveTime(TimeUnit)). This provides a means of reducing resource consumption when the pool is not being actively used. If the pool becomes more active later, new threads will be constructed. This parameter can also be changed dynamically using methodsetKeepAliveTime(long, TimeUnit). Using a value ofLong.MAX_VALUETimeUnit.NANOSECONDSeffectively disables idle threads from ever terminating prior to shut down. By default, the keep-alive policy applies only when there are more than corePoolSize threads. But methodallowCoreThreadTimeOut(boolean)can be used to apply this time-out policy to core threads as well, so long as the keepAliveTime value is non-zero. - Queuing 重点关注:直接传送,无界队列,有界队列的特定,及其典型使用场景。
-
Any
BlockingQueuemay be used to transfer and hold submitted tasks. The use of this queue interacts with pool sizing:- If fewer than corePoolSize threads are running, the Executor always prefers adding a new thread rather than queuing.
- If corePoolSize or more threads are running, the Executor always prefers queuing a request rather than adding a new thread.
- If a request cannot be queued, a new thread is created unless this would exceed maximumPoolSize, in which case, the task will be rejected.
There are three general strategies for queuing:
- Direct handoffs. A good default choice for a work queue is a
SynchronousQueuethat hands off tasks to threads without otherwise holding them. Here, an attempt to queue a task will fail if no threads are immediately available to run it, so a new thread will be constructed. This policy avoids lockups when handling sets of requests that might have internal dependencies. Direct handoffs generally require unbounded maximumPoolSizes to avoid rejection of new submitted tasks. This in turn admits the possibility of unbounded thread growth when commands continue to arrive on average faster than they can be processed. - Unbounded queues. Using an unbounded queue (for example a
LinkedBlockingQueuewithout a predefined capacity) will cause new tasks to wait in the queue when all corePoolSize threads are busy. Thus, no more than corePoolSize threads will ever be created. (And the value of the maximumPoolSize therefore doesn't have any effect.) This may be appropriate when each task is completely independent of others, so tasks cannot affect each others execution; for example, in a web page server. While this style of queuing can be useful in smoothing out transient bursts of requests, it admits the possibility of unbounded work queue growth when commands continue to arrive on average faster than they can be processed. - Bounded queues. A bounded queue (for example, an
ArrayBlockingQueue) helps prevent resource exhaustion when used with finite maximumPoolSizes, but can be more difficult to tune and control. Queue sizes and maximum pool sizes may be traded off for each other: Using large queues and small pools minimizes CPU usage, OS resources, and context-switching overhead, but can lead to artificially low throughput. If tasks frequently block (for example if they are I/O bound), a system may be able to schedule time for more threads than you otherwise allow. Use of small queues generally requires larger pool sizes, which keeps CPUs busier but may encounter unacceptable scheduling overhead, which also decreases throughput.
- Rejected tasks
-
New tasks submitted in method
execute(Runnable)will be rejected when the Executor has been shut down, and also when the Executor uses finite bounds for both maximum threads and work queue capacity, and is saturated. In either case, theexecutemethod invokes theRejectedExecutionHandler.rejectedExecution(Runnable, ThreadPoolExecutor)method of itsRejectedExecutionHandler. Four predefined handler policies are provided:- In the default
ThreadPoolExecutor.AbortPolicy, the handler throws a runtimeRejectedExecutionExceptionupon rejection. - In
ThreadPoolExecutor.CallerRunsPolicy, the thread that invokesexecuteitself runs the task. This provides a simple feedback control mechanism that will slow down the rate that new tasks are submitted. - In
ThreadPoolExecutor.DiscardPolicy, a task that cannot be executed is simply dropped. - In
ThreadPoolExecutor.DiscardOldestPolicy, if the executor is not shut down, the task at the head of the work queue is dropped, and then execution is retried (which can fail again, causing this to be repeated.)
It is possible to define and use other kinds of
RejectedExecutionHandlerclasses. Doing so requires some care especially when policies are designed to work only under particular capacity or queuing policies. - In the default
- Hook methods 用于扩展线程池的功能
-
This class provides
protectedoverridablebeforeExecute(Thread, Runnable)andafterExecute(Runnable, Throwable)methods that are called before and after execution of each task. These can be used to manipulate the execution environment; for example, reinitializing ThreadLocals, gathering statistics, or adding log entries. Additionally, methodterminated()can be overridden to perform any special processing that needs to be done once the Executor has fully terminated.If hook or callback methods throw exceptions, internal worker threads may in turn fail and abruptly terminate.
ForkJoinPool
ForkJoinPool遵循‘分而治之’的思想,先将任务拆分,如果需要,最后再讲任务执行结果合并,返回。其只能执行ForkJoinTask类型的任务,其中RecursiveTask任务,在执行后有返回结果,而RecursiveAction则没有返回结果,适合于事件驱动类的task。
Excutors
Excutors是工具类,提供了创建典型ThreadPoolExcutor和ScheduledThreadPoolExecutor实例的api,开发过程中通常不会自己手动创建线程池,多使用这个工具类的api完成。
总结
java cocurrent package中的Excutor体系,主要提供了实时和定时(含定频)的Excutor,支持单个线程,也支持线程池;他们的职责在于将任务执行者和任务发布者解耦。
实时任务处理可以当着定时任务的特例,ScheduledThreadPoolExecutor也提供了支持实时任务的api。
线程池创建通常使用Excutors搞定,典型的线程池:单个、固定大小线程池、可调节大小线程池,自定义线程池时,需要调配好queue大小和线程池大小的关系。
使用submit api将任务提交给线程池,根据实际场景,通过对应的Future接口实现类的api对任务执行情况进行监控,必要时可以将执行中的任务停止。
使用流程:创建线程池,创建任务,提交任务,跟踪并处理任务结果。
java并发编程——Excutor的更多相关文章
- Java并发编程原理与实战三十一:Future&FutureTask 浅析
一.Futrue模式有什么用?------>正所谓技术来源与生活,这里举个栗子.在家里,我们都有煮菜的经验.(如果没有的话,你们还怎样来泡女朋友呢?你懂得).现在女票要你煮四菜一汤,这汤是鸡汤, ...
- Java 并发编程 Executor 框架
本文部分摘自<Java 并发编程的艺术> Excutor 框架 1. 两级调度模型 在 HotSpot VM 的线程模型中,Java 线程被一对一映射为本地操作系统线程.在上层,Java ...
- 【Java并发编程实战】----- AQS(四):CLH同步队列
在[Java并发编程实战]-–"J.U.C":CLH队列锁提过,AQS里面的CLH队列是CLH同步锁的一种变形.其主要从两方面进行了改造:节点的结构与节点等待机制.在结构上引入了头 ...
- 【Java并发编程实战】----- AQS(三):阻塞、唤醒:LockSupport
在上篇博客([Java并发编程实战]----- AQS(二):获取锁.释放锁)中提到,当一个线程加入到CLH队列中时,如果不是头节点是需要判断该节点是否需要挂起:在释放锁后,需要唤醒该线程的继任节点 ...
- 【Java并发编程实战】----- AQS(二):获取锁、释放锁
上篇博客稍微介绍了一下AQS,下面我们来关注下AQS的所获取和锁释放. AQS锁获取 AQS包含如下几个方法: acquire(int arg):以独占模式获取对象,忽略中断. acquireInte ...
- 【Java并发编程实战】-----“J.U.C”:CLH队列锁
在前面介绍的几篇博客中总是提到CLH队列,在AQS中CLH队列是维护一组线程的严格按照FIFO的队列.他能够确保无饥饿,严格的先来先服务的公平性.下图是CLH队列节点的示意图: 在CLH队列的节点QN ...
- 【Java并发编程实战】-----“J.U.C”:CountDownlatch
上篇博文([Java并发编程实战]-----"J.U.C":CyclicBarrier)LZ介绍了CyclicBarrier.CyclicBarrier所描述的是"允许一 ...
- 【Java并发编程实战】-----“J.U.C”:CyclicBarrier
在上篇博客([Java并发编程实战]-----"J.U.C":Semaphore)中,LZ介绍了Semaphore,下面LZ介绍CyclicBarrier.在JDK API中是这么 ...
- 【Java并发编程实战】-----“J.U.C”:ReentrantReadWriteLock
ReentrantLock实现了标准的互斥操作,也就是说在某一时刻只有有一个线程持有锁.ReentrantLock采用这种独占的保守锁直接,在一定程度上减低了吞吐量.在这种情况下任何的"读/ ...
随机推荐
- 铁乐学Python_Day33_网络编程Socket模块1
铁乐学Python_Day33_网络编程Socket模块1 部份内容摘自授课老师的博客http://www.cnblogs.com/Eva-J/ 理解socket Socket是应用层与TCP/IP协 ...
- Windows下使用Git Bash上传项目到GitHub
http://blog.csdn.net/qq_28304687/article/details/69959238?locationNum=8&fps=1
- (1)I/O流 (2)线程
1.I/O流1.1 ObjectOutputStream类(重点)(1)基本概念 java.io.ObjectOutputStream类主要用于将Java对象整体写入到输出流中. 只能将支持 java ...
- codeforces 1007B Pave the Parallelepiped
codeforces 1007B Pave the Parallelepiped 题意 题解 代码 #include<bits/stdc++.h> using namespace std; ...
- 4种Java日志管理方法
java开发中常见的几种日志管理方案有以下4种: 1. Commons-logging + log4j 2. log4j 3. slf4j + log4j + commmons-logging 4. ...
- acl 4 year statistics
- mybatis #{}和${}的区别是什么
#{}和${}的区别是什么?正确的答案是:#{}是预编译处理,${}是字符串替换.(1)mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法 ...
- zookeeper 快速入门
分布式系统简介 在分布式系统中另一个需要解决的重要问题就是数据的复制.我们日常开发中,很多人会碰到一个问题:客户端C1更新了一个值K1由V1更新到V2.但是客户端C2无法立即读取到K的最新值.上面的例 ...
- [JSOI2018]潜入行动
题目 我好菜啊,嘤嘤嘤 原来本地访问数组负下标不会报\(RE\)或者\(WA\),甚至能跑出正解啊 这道题还是非常呆的 我们发现\(k\)很小,于是断定这是一个树上背包 发现在一个点上安装控制器并不能 ...
- Day5 JDBC
JDBC的简介 Java Database Connectivity:连接数据库技术. SUN公司为了简化.统一对数据库的操作,定义了一套Java操作数据库的规范(接口),使用同一套程序操作不同的数 ...