ZooKeeper-基础介绍
What is ZooKeeper?
ZooKeeper为分布式应用设计的高性能(使用在大的分布式系统)、高可用(防止单点失败)、严格地有序访问(客户端可以实现复杂的同步原语)的协同服务。
ZooKeeper提供的服务包括:maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Design Goals
ZooKeeper is simple. ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchal namespace which is organized similarly to a standard file system.
ZooKeeper is replicated. Like the distributed processes it coordinates, ZooKeeper itself is intended to be replicated over a sets of hosts called an ensemble.
ZooKeeper is ordered. ZooKeeper stamps each update with a number that reflects the order of all ZooKeeper transactions.
ZooKeeper is fast. It is especially fast in "read-dominant" workloads. ZooKeeper applications run on thousands of machines, and it performs best where reads are more common than writes, at ratios of around 10:1.
The ZooKeeper Data Model
ZooKeeper在内存中维护一个由ZNode构成的层次树。ZNode可以类比成文件和目录。每个ZNode维护的数据结构中包括(1) version numbers for data changes(2)ACL that restricts who can do what.(3)timestamps.
The version number, together with the timestamp, allows ZooKeeper to validate the cache and to coordinate updates. Each time a znode's data changes, the version number increases. For instance, whenever a client retrieves data, it also receives the version of the data. And when a client performs an update or a delete, it must supply the version of the data of the znode it is changing. If the version it supplies doesn't match the actual version of the data, the update will fail. version number为 -1,则可以匹配任意znode的版本。

(1)数据访问是原子的。read一个znode的数据,只可能把该znode中的数据全部读取出来或者失败。write将替换掉znode中的所有数据或者失败。不存在部分读取和部分写入(ZooKeeper不支持append操作)。
(2)使用绝对路径来访问一个znode,路径使用java.lang.String来描述。
(3)每个ZNode最多存储1MB的数据,but the data should be much less than that on average。ZooKeeper was not designed to be a general database or large object store. Instead, it manages coordination data(configuration, status information, rendezvous)。如果需要存储大的数据,一般将数据存储到NFS或者HDFS,将指针存储到ZooKeeper中。
Ephemeral ZNodes & Persistent ZNodes
ZooKeeper中有两种类型的znode:ephemeral or persistent。ZooKeeper实例的create方法在创建znode的时候可以使用CreateMode指定znode的类型。

CreateMode可以指定的类型如下。

Sequence numbers can be used to impose a global ordering on events in a distributed system and may be used by the client to infer the ordering.
ZooKeeper Watches
ZooKeeper的读操作getData(), getChildren(), exists() 可以决定是否设置watch,写操作create() ,delete(), setData()可以触发watch。ACL的操作与watch无关。
ZooKeeper的Watcher对象有两个功能:(1)通知ZooKeeper状态的改变(2)通知ZNode的改变。
ZooKeeper对watch的定义:A watch event is one-time trigger, sent to the client that set the watch, which occurs when the data for which the watch was set changes.
One-time trigger
One watch event will be sent to the client when the data has changed. For example, if a client does a getData("/znode1", true) and later the data for /znode1 is changed or deleted, the client will get a watch event for /znode1. If /znode1 changes again, no watch event will be sent unless the client has done another read that sets a new watch.
Sent to the client
This implies that an event is on the way to the client, but may not reach the client before the successful return code to the change operation reaches the client that initiated the change. Watches are sent asynchronously to watchers. ZooKeeper provides an ordering guarantee: a client will never see a change for which it has set a watch until it first sees the watch event. Network delays or other factors may cause different clients to see watches and return codes from updates at different times. The key point is that everything seen by the different clients will have a consistent order.
The data for which the watch was set
This refers to the different ways a node can change. It helps to think of ZooKeeper as maintaining two lists of watches: data watches and child watches. getData() and exists() set data watches. getChildren() sets child watches. Alternatively, it may help to think of watches being set according to the kind of data returned. getData() and exists() return information about the data of the node, whereas getChildren() returns a list of children. Thus, setData() will trigger data watches for the znode being set (assuming the set is successful). A successful create() will trigger a data watch for the znode being created and a child watch for the parent znode. A successful delete() will trigger both a data watch and a child watch (since there can be no more children) for a znode being deleted as well as a child watch for the parent znode.
Watch Triggers
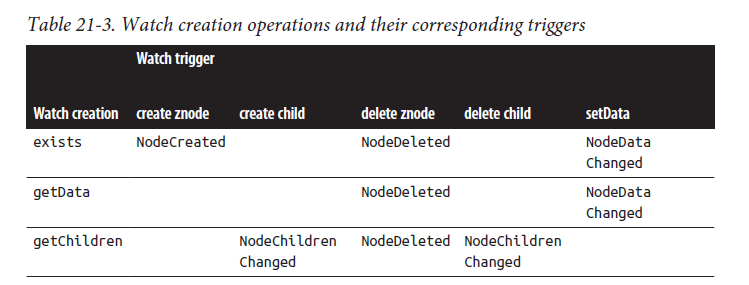
具体的说明如下:
• A watch set on an exists operation will be triggered when the znode being watched is created, deleted, or has its data updated.
• A watch set on a getData operation will be triggered when the znode being watched is deleted or has its data updated. No trigger can occur on creation because the znode must already exist for the getData operation to succeed.
• A watch set on a getChildren operation will be triggered when a child of the znode being watched is created or deleted, or when the znode itself is deleted. You can tell whether the znode or its child was deleted by looking at the watch event type: NodeDeleted shows the znode was deleted, and NodeChildrenChanged indicates that it was a child that was deleted.
What ZooKeeper Guarantees about Watches
With regard to watches, ZooKeeper maintains these guarantees:
Watches are ordered with respect to other events, other watches, and asynchronous replies. The ZooKeeper client libraries ensures that everything is dispatched in order.
A client will see a watch event for a znode it is watching before seeing the new data that corresponds to that znode.
The order of watch events from ZooKeeper corresponds to the order of the updates as seen by the ZooKeeper service.
Things to Remember about Watches
Watches are one time triggers; if you get a watch event and you want to get notified of future changes, you must set another watch.
Because watches are one time triggers and there is latency between getting the event and sending a new request to get a watch you cannot reliably see every change that happens to a node in ZooKeeper. Be prepared to handle the case where the znode changes multiple times between getting the event and setting the watch again. (You may not care, but at least realize it may happen.)
A watch object, or function/context pair, will only be triggered once for a given notification. For example, if the same watch object is registered for an exists and a getData call for the same file and that file is then deleted, the watch object would only be invoked once with the deletion notification for the file.
When you disconnect from a server (for example, when the server fails), you will not get any watches until the connection is reestablished. For this reason session events are sent to all outstanding watch handlers. Use session events to go into a safe mode: you will not be receiving events while disconnected, so your process should act conservatively in that mode.
Operations

delete和setData需要指定znode的版本号(-1可以匹配任意znode的版本号,通过exists方法的返回值可以得到版本号),版本号不匹配,那么操作将失败。更新操作是非阻塞的。
ZooKeeoer中的read操作有可能读取不到最新的数据,client使用sync,则可以得到最新的数据。
multi操作: batch together multiple primitive operations into a single unit that either succeeds or fails in its entirety。
APIs
ZooKeeper提供Java和C的语言支持,提供同步和异步的API。
同步的exists

异步的exists


ACLs
A znode is created with a list of ACLs, which determine who can perform certain operations on it.
ZooKeeper提供的认证方案:
 、
、
Clients may authenticate themselves after establishing a ZooKeeper session. Authentication is optional, although a znode’s ACL may require an authenticated client, in which case the client must authenticate itself to access the znode. Here is an example of using the digest scheme to authenticate with a username and password:
zk.addAuthInfo("digest", "tom:secret".getBytes());、
An ACL is the combination of an authentication scheme, an identity for that scheme, and a set of permissions. For example, if we wanted to give a client with the IP address 10.0.0.1 read access to a znode, we would set an ACL on the znode with the ip scheme, an ID of 10.0.0.1, and READ permission. In Java, we would create the ACL object as follows:
new ACL(Perms.READ,
new Id("ip", "10.0.0.1"));

Implementation
ZooKeeper的两种模式:
Standalone Mode:一个ZooKeeper的Server,测试环境下使用,不提供高可用和可靠性。
Replicated Mode:通过复制,实现高可用。只要ZooKeeper集群中超过半数Server可用,那么整个ZooKeeper服务就是可用的。Server的数量等于N,活着的Server数量需要大于等于N/2 + 1。假设N = 5,5/2 + 1 = 3,允许两个Server失败。假设N = 6,6/2 + 1 = 4,也允许两个Server失败。因此推荐使用奇数个Server构成ensemble(最少3个Server)。ZooKeeper runs in replicated mode on a cluster of machines called an ensemble.
ZooKeeper的核心理念:
all it has to do is ensure that every modification to the tree of znodes is replicated to a majority of the ensemble. If a minority of the machines fail, then a minimum of one machine will survive with the latest state. The other remaining replicas will eventually catch up with this state.
ZooKeeper使用Zab协议实现以上的理念,Zab协议包含两个阶段:

If the leader fails, the remaining machines hold another leader election and continue as before with the new leader. If the old leader later recovers, it then starts as a follower. Leader election is very fast, around 200 ms according to one published result, so performance does not noticeably degrade during an election. All machines in the ensemble write updates to disk before updating their in-memory copies of the znode tree. Read requests may be serviced from any machine, and because they involve only a lookup from memory, they are very fast.

Consistency
A follower may lag the leader by a number of updates.(因此ZooKeeper集群中将Server命名为Leader和Follower是比较恰当的)。This is a consequence of the fact that only a majority and not all members of the ensemble need to have persisted a change before it is committed.

Sessions
Zookeeper客户端拥有ZooKeeper集群中的服务器列表,客户端启动会连接列表中的一个Server。客户端连接上Server以后,Server为该客户端创建一个Session。客户端通过向Server发送ping请求(心跳)来维持Session的存活。
Time
ZooKeeper中基础的时间单位是tick time,其他的时间参数基于tick time设置(例如Session timeout)。
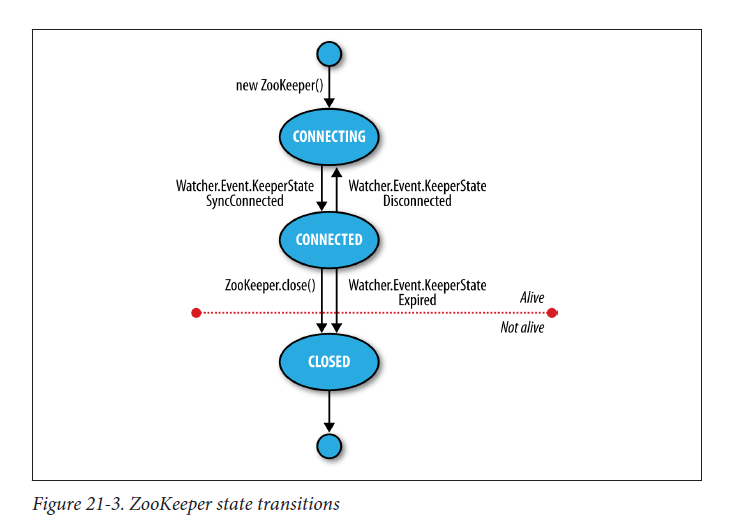
States
ZooKeeper对象在其生命周期拥有不同的State,新建的ZooKeeper实例的状态是CONNECTING,与Server建立起连接后,变成CONNECTED状态。如果ZooKeeper实例调用close方法或者session timeout,则变成CLOSED状态。通过调用getState方法可以获取到状态。
The most performance-critical part of ZooKeeper is the transaction log.
partial failure: when we don’t even know if an operation failed
参考:
https://zookeeper.apache.org/doc/current/index.html
Hadoop权威指南第4版
看了有收获的文章:
https://blog.csdn.net/u012152619/article/details/53053634
https://blog.csdn.net/liu857279611/article/details/70495413
ZooKeeper-基础介绍的更多相关文章
- zk系列一:zookeeper基础介绍
聊完kafka必不可少的需要再聊一聊zk了,下面开始 一.ZK是什么 ZooKeeper是分布式应用程序的高性能协调服务.它可以实现分布式的选主.统一配置管理,命名,分布式节点同步,分布式锁等分布式常 ...
- 【Hadoop离线基础总结】zookeeper的介绍以及集群环境搭建、网络编程和RPC的简单了解
ZooKeeper的介绍以及集群环境搭建.网络编程和RPC的简单了解 ZooKeeper介绍 概述 ZooKeeper是一个分布式协调服务的开源框架,主要用来解决分布式集群中应用系统的一致性问题.例如 ...
- [转]ZooKeeper学习第一期---Zookeeper简单介绍
ZooKeeper学习第一期---Zookeeper简单介绍 http://www.cnblogs.com/sunddenly/p/4033574.html 一.分布式协调技术 在给大家介绍ZooKe ...
- Hadoop系列-zookeeper基础
目前是刚刚初学完zookeeper,这篇文章主要是简单的对一些基本的概念进行梳理强化. zookeeper基础概念的理解 有时候计算机领域很多名词都是从一长串英文提取首字母缩写而来,但很不幸zooke ...
- Zookeeper基础教程(六):.net core使用Zookeeper
Demo代码已提交到gitee,感兴趣的更有可以直接克隆使用,地址:https://gitee.com/shanfeng1000/dotnetcore-demo/tree/master/Zookeep ...
- Zookeeper基础教程(五):C#实现Zookeeper分布式锁
分布式锁 互联网初期,我们系统一般都是单点部署,也就是在一台服务器完成系统的部署,后期随着用户量的增加,服务器的压力也越来越大,响应速度越来越慢,甚至出现服务器崩溃的情况. 为解决服务器压力太大,响应 ...
- Web3D编程入门总结——WebGL与Three.js基础介绍
/*在这里对这段时间学习的3D编程知识做个总结,以备再次出发.计划分成“webgl与three.js基础介绍”.“面向对象的基础3D场景框架编写”.“模型导入与简单3D游戏编写”三个部分,其他零散知识 ...
- C++ 迭代器 基础介绍
C++ 迭代器 基础介绍 迭代器提供对一个容器中的对象的访问方法,并且定义了容器中对象的范围.迭代器就如同一个指针.事实上,C++的指针也是一种迭代器.但是,迭代器不仅仅是指针,因此你不能认为他们一定 ...
- zookeeper_02:zookeeper基础
ZooKeeper基础概述 ZooKeeper维护一个小型的数据节点,这些节点被称为znode,采用类似于文件系统的层级树状结构进行管理. 针对一个znode,没有数据常常表达了重要的信息.比如,在主 ...
- Node.js学习笔记(一)基础介绍
什么是Node.js 官网介绍: Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js us ...
随机推荐
- Java的自动拆/装箱
作者:Alvin 关键字:语法糖 类 对象 参考 Java 中的语法糖 语法糖--这一篇全了解 浅谈 Integer 类 什么是Java中的自动拆装箱 深入剖析Java中的装箱和拆箱 前言 我们知道, ...
- java程序性能优化读书笔记-垃圾回收
衡量系统性能的点 执行速度:即响应时间 内存分配:内存分配是否合理,是否过多消耗内存或者存在内存泄露 启动时间:程序从启动到正常处理业务需要的时间 负载承受能力:当系统压力上升,系统执行速度和响应时间 ...
- 使用VS Code新建编译Flutter项目
本文的前提是你已经安装好了VS Code,并且安装了Flutter和Dart扩展插件. 1. 新建Flutter项目 查看——命令面板,或者Ctrl + Shift + P 输入 Flutter: N ...
- C#课后练手
猜拳(三局两胜)请输入您的手势:石头用户手势:石头 电脑手势:剪刀用户胜:1 电脑胜:0 请输入您的手势:石头用户手势:石头 电脑手势:石头用户胜:1 电脑胜: ...
- DNS DHCP 路由 FTP
第1章 网络基础 1.1 IP地址分类 IP地址的类别-按IP地址数值范围划分 IP地址的类别-按IP地址用途分类 IP地址的类别-按网络通信方式划分 1.2 局域网上网原理过程 DHCP原理过程详情 ...
- BootStap学习笔记(1)
移动设备优先: 为了让开发的网站对移动设备友好,确保适当的绘制和触屏缩放,需要在网页的head之中添加viewport meat标签:如下: <metaname="viewport& ...
- 使用Fiddler进行Web接口测试
一.Fiddler简介1.为什么是Fiddler?抓包工具有很多,小到最常用的web调试工具firebug,达到通用的强大的抓包工具wireshark.为什么使用fiddler?原因如下: A)Fir ...
- 拒绝滥用golang defer机制
原文链接 : http://www.bugclosed.com/post/17 defer机制 go语言中的defer提供了在函数返回前执行操作的机制,在需要资源回收的场景非常方便易用(比如文件关闭, ...
- node http模块搭建简单的服务和客户端
node-http Node.js提供了http模块,用于搭建HTTP服务端和客户端. 创建Web服务器 server.js /** * node-http 服务端 */ let http = req ...
- 【Py大法系列--01】20多行代码生成你的微信聊天机器人
前言 近期Stack Overflow公布了一项调查显示,Python已经成了发展最快的主流编程语言,Python搭乘着数据科学和机器学习以及人工智能的浪潮,席卷了整个技术圈.越来越多的人想了解.想学 ...