day 68crm(5) 分页器的进一步优化,以及在stark上使用分页器,,以及,整理代码,以及stark组件search查询
前情提要: 本节内容
自定制分页器
保存及查询记录
代码整理,
stark组件search 查询
一:自定制分页器 page
1:创建类 Pagination # 自定制分页器
_ _init_ _ 属性说明

2: 分页器的数据说明,以及简单的数据去除

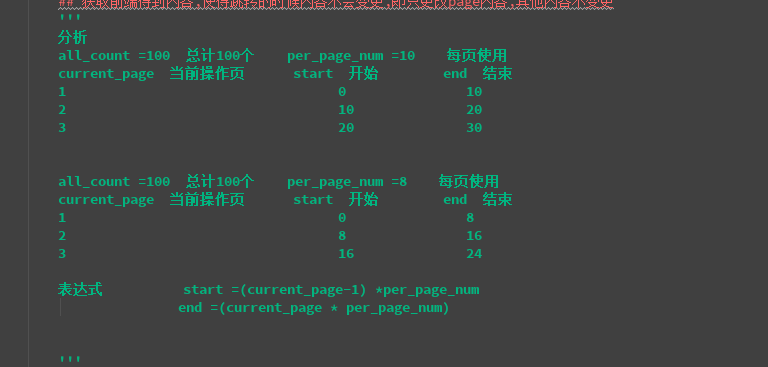
3 : 页面分析
如果总数为100个, 设置每页8个数据
结果展示如下
4: 展示每页的数据
设置展示本页开始数据索引和本页结束数据索引
由 3 可知 ,每页的展示情况

5 :展示页码
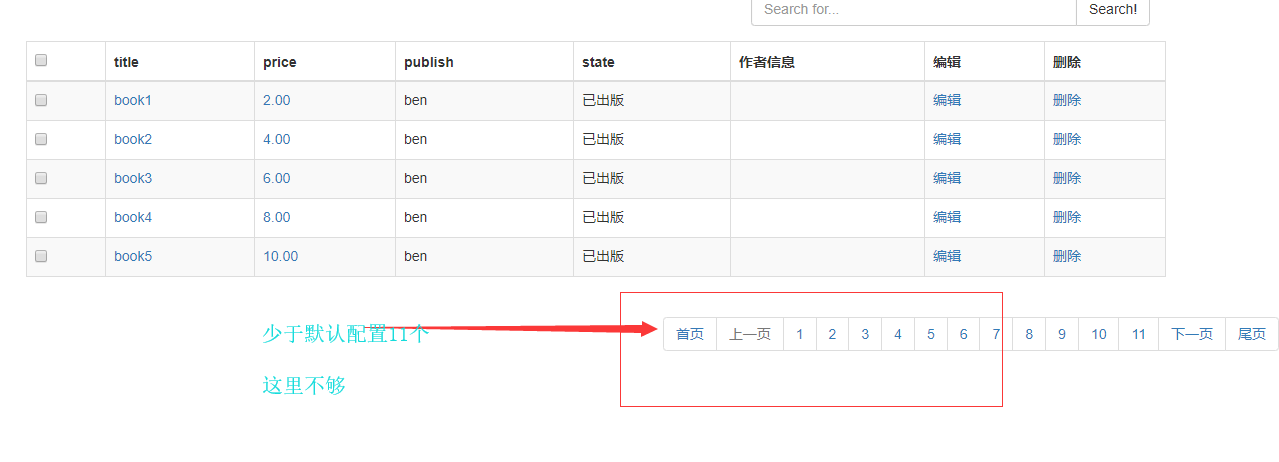
正常展示

显示最后一页
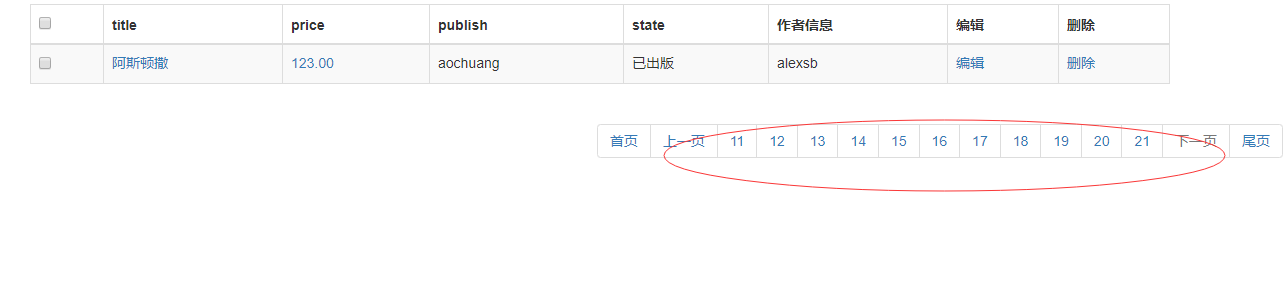
6 : 展示页码 情况
主要分为4种情况
7: 通过后台将前端页码展示进行渲染
知识点补充:
前面在源码中,request.GET 不允许进行修改值
所以用copy 进行深拷贝.
在源码中的_ _ copy _ _ 允许进行修改

这步操作的内容的意思的 当页码更改时,其他的参数不会被改动
这个里面有两个参数,

7 >1:先获取前端数据
7>2: 由于GET方法获取的内容不允许修改,所以进行深拷贝,为self.params, 此为字典形式
7>3 :通过key:valuse 进行新增值 ,这样原来传过来的其他值就不会有问题

7>4:
self.params.urlencode()
这句可以把字典传话成字符串的格式, 如
{'a':1 ,'b':2,'c':3} 转化成
a=1&b=2&c=3
结果:
最后返回加好标签内容的字符串

整段page 代码
# -*- coding: utf- -*-
# @Time : // :
# @Author : Endless-cloud
# @Site :
# @File : page.py
# @Software: PyCharm
'''
┏┓ ┏┓+ +
┏┛┻━━━┛┻┓ + +
┃ ┃
┃ ━ ┃ ++ + + +
████━████ ┃+
┃ ┃ +
┃ ┻ ┃
┃ ┃ + +
┗━┓ ┏━┛
┃ ┃
┃ ┃ + + + +
┃ ┃ Code is far away from bug with the animal protecting
┃ ┃ + 神兽保佑,代码无bug
┃ ┃
┃ ┃ +
┃ ┗━━━┓ + +
┃ ┣┓
┃ ┏┛
┗┓┓┏━┳┓┏┛ + + + +
┃┫┫ ┃┫┫
┗┻┛ ┗┻┛+ + + +
''' class Pagination(object): # 自定制分页器
def __init__(self, request, current_page, all_data, per_page_num=, max_page_count=):
""" :param request: 当前操作界面的请求内容
:param current_page: 当前页
:param all_data: 分页数据中的所有内容
:param per_page_num: 每页显示的数据条数
:param max_page_count: 最多显示的页码个数
""" try:
current_page = int(current_page) # 转化当前操作页内容
except Exception as e: # 确保当前操作的内容为数字,如不是数字则强制使页码转化成第一页
current_page =
if current_page < : # 确保穿过来的参数不能为负数
current_page =
self.current_page = current_page # 设定属性 当前页
self.all_count = len(all_data) # 设定转化过数量总数通过len
self.per_page_num = per_page_num # 每页最多多少个 all_pager, tmp = divmod(self.all_count, self.per_page_num)
# all_pager 总页数
# tmp 余数多少
if tmp: # 如果有余数
all_pager += # 那么页数加1
self.all_pager = all_pager # 总页数
self.max_page_count = max_page_count # 最多显示多少页
self.max_pager_count_half = int((self.max_page_count - ) / ) # 最大显示页对半分开数量
self.request = request # 获取当前操作的请求 # request.GET ,获取的是querydict 源码中不予许修改
import copy
self.params = copy.deepcopy(self.request.GET) # 从新深复制一遍GET内容,因为request不允许修改
## 获取前端得到内容,使得跳转的时候内容不会变更,即只更改page内容,其他内容不变更
'''
分析
all_count = 总计100个 per_page_num = 每页使用
current_page 当前操作页 start 开始 end 结束 all_count = 总计100个 per_page_num = 每页使用
current_page 当前操作页 start 开始 end 结束 表达式 start =(current_page-) *per_page_num
end =(current_page * per_page_num) ''' @property
def start(self): # 展示数据页开始
return (self.current_page - ) * self.per_page_num # 当前操作页- *每页个数 @property
def end(self): # 展示数据也结尾
return self.current_page * self.per_page_num # 当前操作页*每页个数 '''
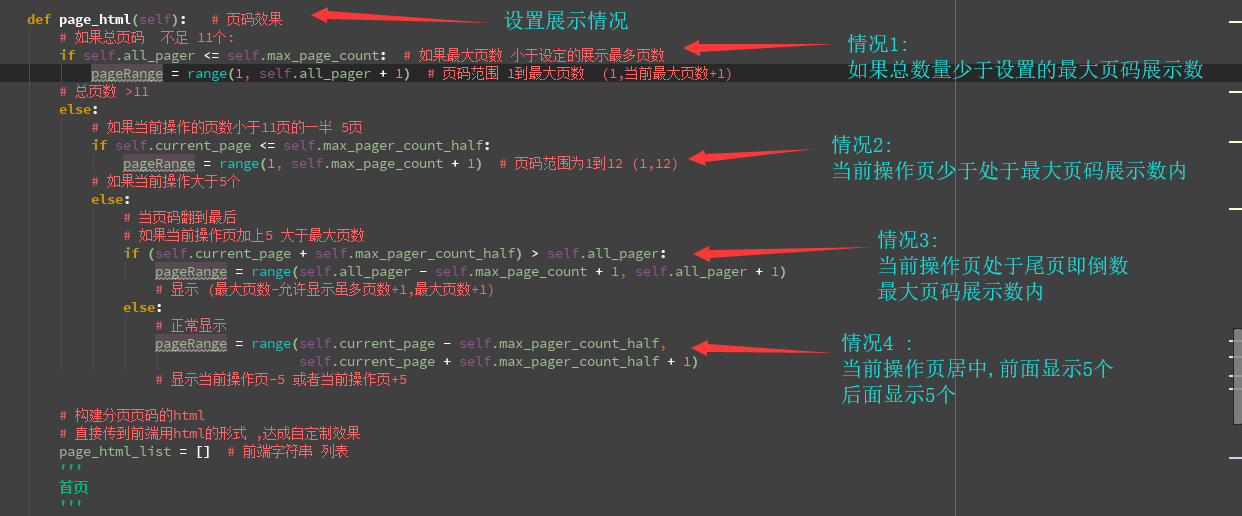
4种情况:
:当操作页面不足显示最多页码个数
:当操作页面内容显示在前11个内(不足减5)
:当操作页面内容显示在后11个内(不足加5)
:正常显示 ''' def page_html(self): # 页码效果
# 如果总页码 不足 11个:
if self.all_pager <= self.max_page_count: # 如果最大页数 小于设定的展示最多页数
pageRange = range(, self.all_pager + ) # 页码范围 1到最大页数 (,当前最大页数+)
# 总页数 >
else:
# 如果当前操作的页数小于11页的一半 5页
if self.current_page <= self.max_pager_count_half:
pageRange = range(, self.max_page_count + ) # 页码范围为1到12 (,)
# 如果当前操作大于5个
else:
# 当页码翻到最后
# 如果当前操作页加上5 大于最大页数
if (self.current_page + self.max_pager_count_half) > self.all_pager:
pageRange = range(self.all_pager - self.max_page_count + , self.all_pager + )
# 显示 (最大页数-允许显示虽多页数+,最大页数+)
else:
# 正常显示
pageRange = range(self.current_page - self.max_pager_count_half,
self.current_page + self.max_pager_count_half + )
# 显示当前操作页- 或者当前操作页+ # 构建分页页码的html
# 直接传到前端用html的形式 ,达成自定制效果
page_html_list = [] # 前端字符串 列表
'''
首页
'''
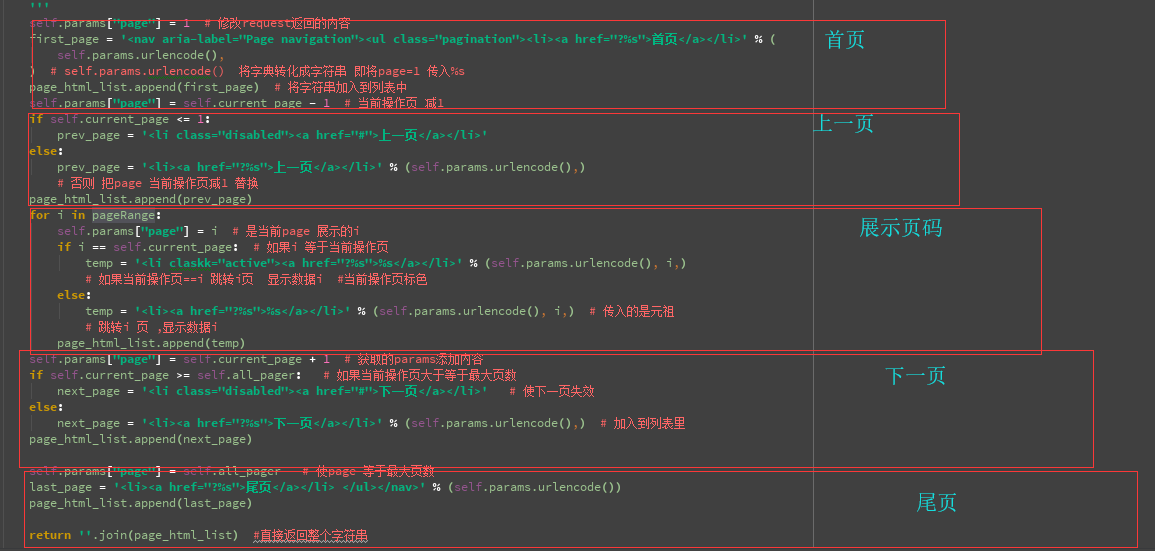
self.params["page"] = # 修改request返回的内容
first_page = '<nav aria-label="Page navigation"><ul class="pagination"><li><a href="?%s">首页</a></li>' % (
self.params.urlencode(),
) # self.params.urlencode() 将字典转化成字符串 即将page= 传入%s
page_html_list.append(first_page) # 将字符串加入到列表中
self.params["page"] = self.current_page - # 当前操作页 减1
if self.current_page <= :
prev_page = '<li class="disabled"><a href="#">上一页</a></li>'
else:
prev_page = '<li><a href="?%s">上一页</a></li>' % (self.params.urlencode(),)
# 否则 把page 当前操作页减1 替换
page_html_list.append(prev_page)
for i in pageRange:
self.params["page"] = i # 是当前page 展示的i
if i == self.current_page: # 如果i 等于当前操作页
temp = '<li claskk="active"><a href="?%s">%s</a></li>' % (self.params.urlencode(), i,)
# 如果当前操作页==i 跳转i页 显示数据i #当前操作页标色
else:
temp = '<li><a href="?%s">%s</a></li>' % (self.params.urlencode(), i,) # 传入的是元祖
# 跳转i 页 ,显示数据i
page_html_list.append(temp)
self.params["page"] = self.current_page + # 获取的params添加内容
if self.current_page >= self.all_pager: # 如果当前操作页大于等于最大页数
next_page = '<li class="disabled"><a href="#">下一页</a></li>' # 使下一页失效
else:
next_page = '<li><a href="?%s">下一页</a></li>' % (self.params.urlencode(),) # 加入到列表里
page_html_list.append(next_page) self.params["page"] = self.all_pager # 使page 等于最大页数
last_page = '<li><a href="?%s">尾页</a></li> </ul></nav>' % (self.params.urlencode())
page_html_list.append(last_page) return ''.join(page_html_list) #直接返回整个字符串
二:stites 中的内容大整改 ,(把所有展示数据单独建立一个类)
原:数据内容
header_list = [] # 定制一个空别表
for field_or_func in self.get_new_list_display():
# 如果是多对多的
if callable(field_or_func):
val = field_or_func(self, header=True)
header_list.append(val)
# header_list.append(field_or_func.__name__)
# 如果是普通属性
else: if field_or_func == "__str__":
val = self.model._meta.model_name.upper()
else:
field_obj = self.model._meta.get_field(field_or_func)
val = field_obj.verbose_name # 自定义属性名 header_list.append(val) # 构建展示数据
new_data = []
for obj in queryset:
temp = []
for field_or_func in self.get_new_list_display():
if callable(field_or_func):
val = field_or_func(self, obj) # 获取函数返回值,传入obj进行从操作数据 elif not field_or_func == "__str__":
from django.db.models.fields.related import ManyToManyField
field_obj = self.model._meta.get_field(field_or_func) # 获取模型对象
# 判断是否为多对多属性
if type(field_obj) == ManyToManyField:
raise Exception("list_display不能是多对多字段!")
# 判断是否有选择属性
if field_obj.choices:
val = getattr(obj, "get_%s_display" % field_or_func)()
# 调用这个方法,反射方法,调用方法获取对应的内容
else:
val = getattr(obj, field_or_func)
if field_or_func in self.list_display_links:
val = mark_safe("<a href='%s'>%s</a>" % (self.get_change_url(obj), val)) else:
val = getattr(obj, field_or_func)() temp.append(val)
# print(">>>>>>>>>>>>",temp)
new_data.append(temp)
今:整改部分
1 :创建一个类
在原来的地方通过实例对象调用内容
2:函数说明

3:调用说明

requset ,当前操作请求 对应requset
self ,当前操作自定义配置类, 对应config_obj
quseryset 当前操作数据对应 queryset
4:分页包调用以及配置
4>1知识点:
ruquset.GET.get("筛选内容",默认值=None)
即如果不写默认值则为空,这里写为1 即,没获取到时候为1
4:>2 创建配置每页个数接口
前提:设置接口

4>3:最后返回的是分好页的数据(通过切片 [索引:索引])

4>4:抬头部分

4>5:展示数据
5:前端做的修改

前端效果

# -*- coding: utf- -*-
# @Time : // :
# @Author : Endless-cloud
# @Site :
# @File : stites.py
# @Software: PyCharm
'''
┏┓ ┏┓+ +
┏┛┻━━━┛┻┓ + +
┃ ┃
┃ ━ ┃ ++ + + +
████━████ ┃+
┃ ┃ +
┃ ┻ ┃
┃ ┃ + +
┗━┓ ┏━┛
┃ ┃
┃ ┃ + + + +
┃ ┃ Code is far away from bug with the animal protecting
┃ ┃ + 神兽保佑,代码无bug
┃ ┃
┃ ┃ +
┃ ┗━━━┓ + +
┃ ┣┓
┃ ┏┛
┗┓┓┏━┳┓┏┛ + + + +
┃┫┫ ┃┫┫
┗┻┛ ┗┻┛+ + + +
''' from django.urls import path, re_path from app01.models import *
from django.shortcuts import HttpResponse, render, redirect from django.utils.safestring import mark_safe
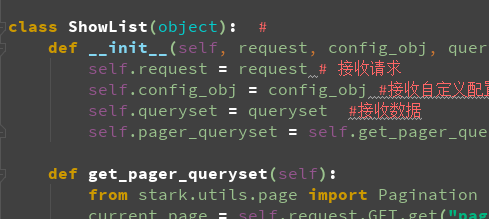
from django.urls import reverse class ShowList(object): #
def __init__(self, request, config_obj, queryset):
self.request = request # 接收请求
self.config_obj = config_obj #接收自定义配置类
self.queryset = queryset #接收数据
self.pager_queryset = self.get_pager_queryset() # 实例分页对象获取内容 def get_pager_queryset(self):
from stark.utils.page import Pagination # 导入自己写的分页包
current_page = self.request.GET.get("page", ) # 当前操作页
self.pagination = Pagination(self.request, current_page, self.queryset,
per_page_num=self.config_obj.per_page_num or )
queryset = self.queryset[self.pagination.start:self.pagination.end]
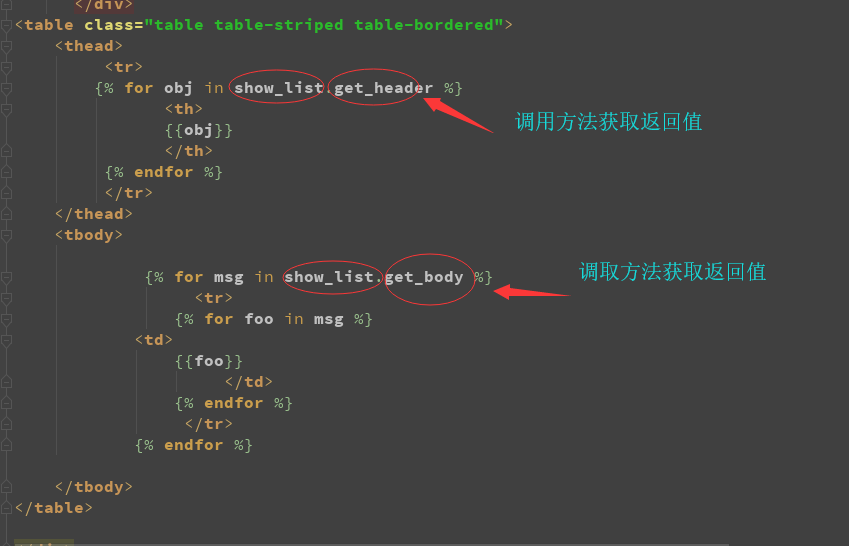
return queryset def get_header(self):
header_list = [] # 定制一个空别表
for field_or_func in self.config_obj.get_new_list_display(): # 替换成config_obj 代用,self 代表原自定义配置类
# 如果是多对多的
if callable(field_or_func):
val = field_or_func(self, header=True)
header_list.append(val)
# header_list.append(field_or_func.__name__)
# 如果是普通属性
else: if field_or_func == "__str__":
val = self.config_obj.model._meta.model_name.upper()
else:
field_obj = self.config_obj.model._meta.get_field(field_or_func)
val = field_obj.verbose_name # 自定义属性名 header_list.append(val)
return header_list #f返回前端的内容
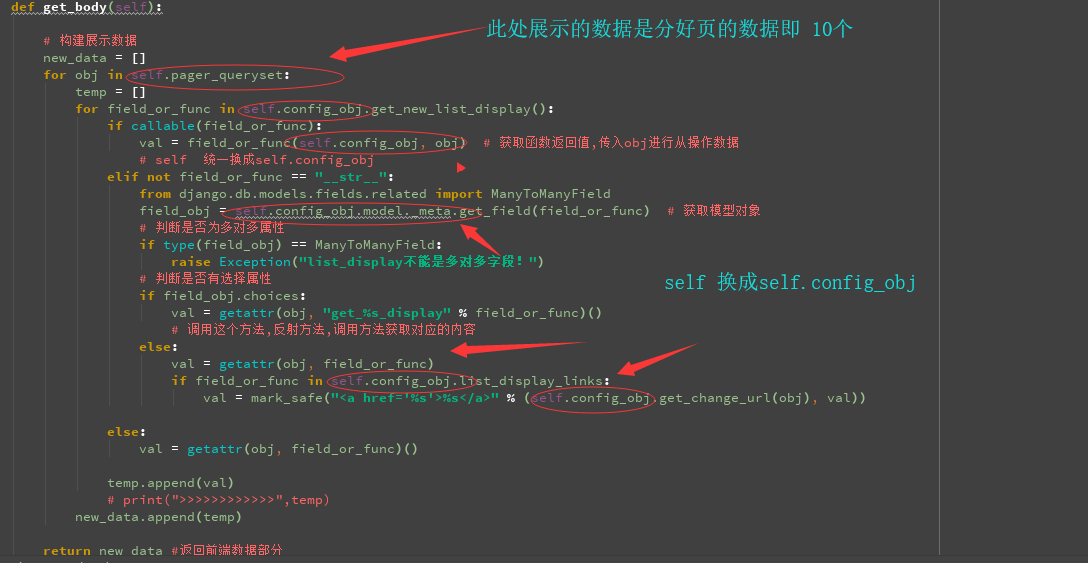
def get_body(self): # 构建展示数据
new_data = []
for obj in self.pager_queryset:
temp = []
for field_or_func in self.config_obj.get_new_list_display():
if callable(field_or_func):
val = field_or_func(self.config_obj, obj) # 获取函数返回值,传入obj进行从操作数据
# self 统一换成self.config_obj
elif not field_or_func == "__str__":
from django.db.models.fields.related import ManyToManyField
field_obj = self.config_obj.model._meta.get_field(field_or_func) # 获取模型对象
# 判断是否为多对多属性
if type(field_obj) == ManyToManyField:
raise Exception("list_display不能是多对多字段!")
# 判断是否有选择属性
if field_obj.choices:
val = getattr(obj, "get_%s_display" % field_or_func)()
# 调用这个方法,反射方法,调用方法获取对应的内容
else:
val = getattr(obj, field_or_func)
if field_or_func in self.config_obj.list_display_links:
val = mark_safe("<a href='%s'>%s</a>" % (self.config_obj.get_change_url(obj), val)) else:
val = getattr(obj, field_or_func)() temp.append(val)
# print(">>>>>>>>>>>>",temp)
new_data.append(temp) return new_data #返回前端数据部分
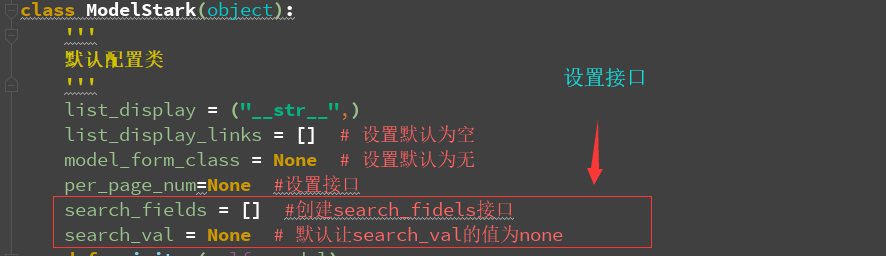
class ModelStark(object):
'''
默认配置类
'''
list_display = ("__str__",)
list_display_links = [] # 设置默认为空
model_form_class = None # 设置默认为无
per_page_num=None #设置接口
search_fields = [] #创建search_fidels接口
search_val = None # 默认让search_val的值为none
def __init__(self, model):
self.model = model
self.model_name = self.model._meta.model_name
self.app_label = self.model._meta.app_label # 反向解析当前访问表的增删改查URL def get_list_url(self):
# 反向解析当前表的删除的URL
list_url = reverse("%s_%s_list" % (self.app_label, self.model_name))
return list_url def get_add_url(self, obj=None):
# 反向解析当前表的删除的URL
add_url = reverse("%s_%s_add" % (self.app_label, self.model_name))
return add_url def get_delete_url(self, obj):
# 反向解析当前表的删除的URL
delete_url = reverse("%s_%s_delete" % (self.app_label, self.model_name), args=(obj.pk,))
return delete_url def get_change_url(self, obj):
# 反向解析当前表的change的URL
change_url = reverse("%s_%s_change" % (self.app_label, self.model_name), args=(obj.pk,))
return change_url def get_new_list_display(self):
temp = []
temp.extend(self.list_display) # 继承原来的列表内容
temp.append(ModelStark.show_editbtn) # 注意传过来的是属性
temp.append(ModelStark.show_delbtn) # 注意传过来的是属性
temp.insert(, ModelStark.show_checkbox)
# temp.insert(,self.show_checkbox())
# 同上不加括号,把方法名加入到列表方便掉用
return temp def show_checkbox(self, obj=None, header=False):
# 展示选择列
if header:
return mark_safe("<input type='checkbox'>")
return mark_safe("<input type='checkbox'>") def show_delbtn(self, obj=None, header=False):
if header:
return "删除" return mark_safe("<a href='%s'>删除</a>" % self.get_delete_url(obj)) def show_editbtn(self, obj=None, header=False):
if header:
return "编辑"
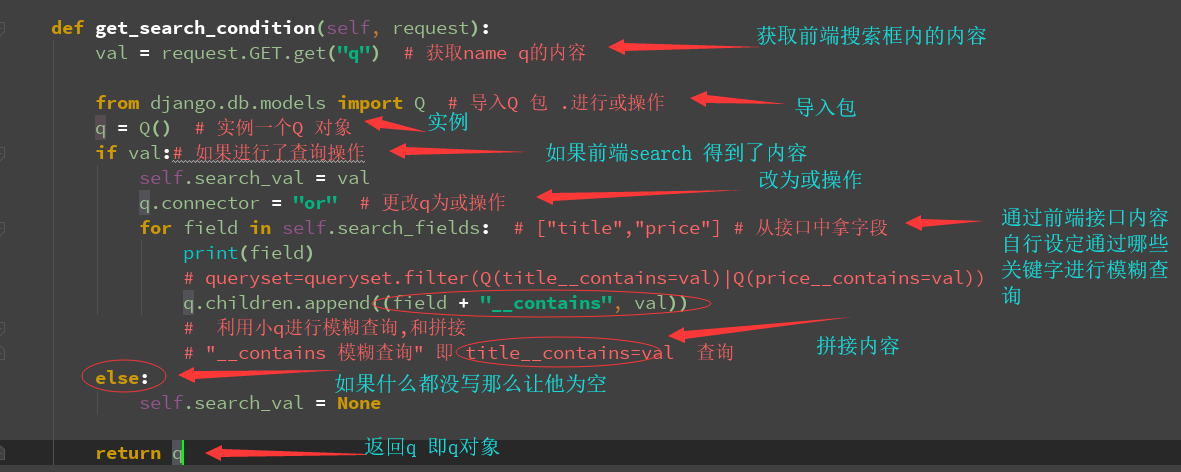
return mark_safe("<a href='%s'>编辑</a>" % self.get_change_url(obj)) def get_search_condition(self, request):
val = request.GET.get("q") # 获取name q的内容 from django.db.models import Q # 导入Q 包 .进行或操作
q = Q() # 实例一个Q 对象
if val:# 如果进行了查询操作
self.search_val = val
q.connector = "or" # 更改q为或操作
for field in self.search_fields: # ["title","price"] # 从接口中拿字段
print(field)
# queryset=queryset.filter(Q(title__contains=val)|Q(price__contains=val))
q.children.append((field + "__contains", val))
# 利用小q进行模糊查询,和拼接
# "__contains 模糊查询" 即 title__contains=val 查询
else:
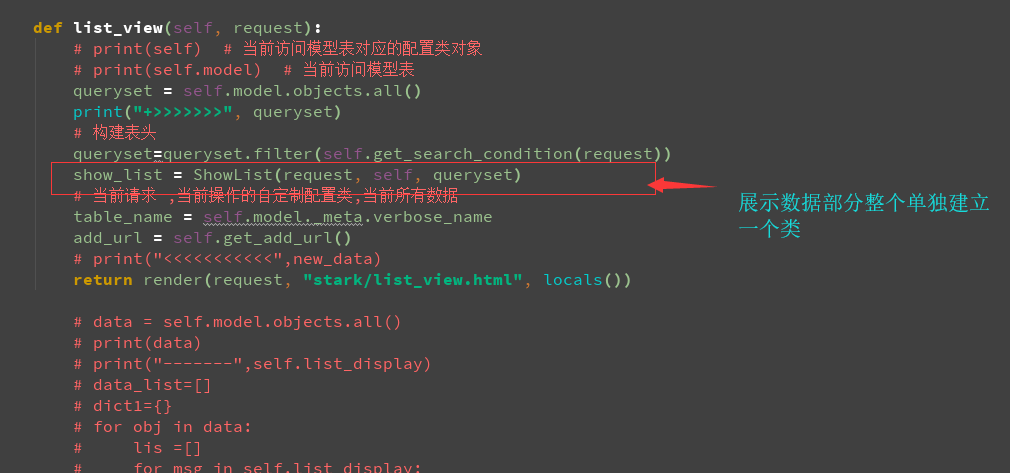
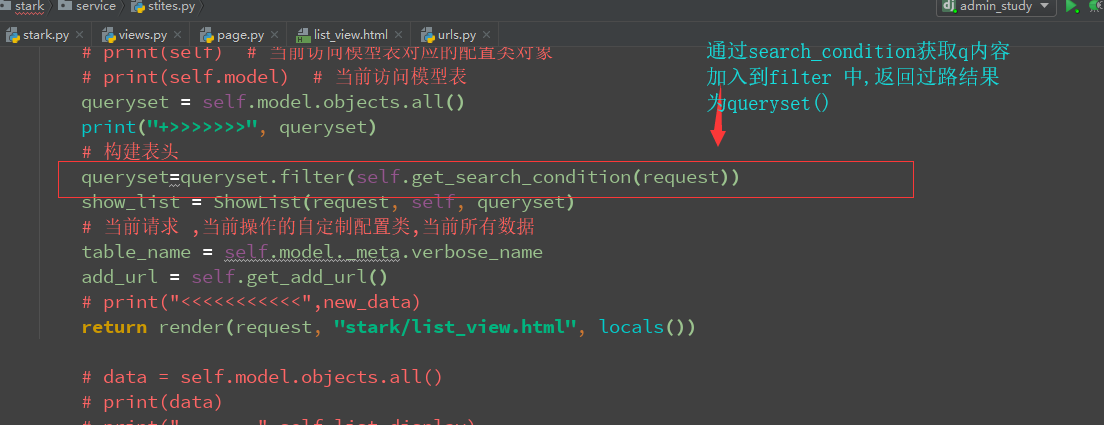
self.search_val = None return q def list_view(self, request):
# print(self) # 当前访问模型表对应的配置类对象
# print(self.model) # 当前访问模型表
queryset = self.model.objects.all()
print("+>>>>>>>", queryset)
# 构建表头
queryset=queryset.filter(self.get_search_condition(request))
show_list = ShowList(request, self, queryset)
# 当前请求 ,当前操作的自定制配置类,当前所有数据
table_name = self.model._meta.verbose_name
add_url = self.get_add_url()
# print("<<<<<<<<<<<",new_data)
return render(request, "stark/list_view.html", locals()) # data = self.model.objects.all()
# print(data)
# print("-------",self.list_display)
# data_list=[]
# dict1={}
# for obj in data:
# lis =[]
# for msg in self.list_display:
# lis.append(getattr(obj,msg))
# data_list.append(lis)
# print("jjjjjjjjj",data_list)
# return render(request, 'stark/list_view.html', {
# "data_list":data_list,
# "list_display":self.list_display
# }) def get_model_form(self): # 创建获取model_form 内容函数
from django.forms import ModelForm # 导入包
class BaseModelForm(ModelForm): # 创建modelform类,继承modelform
class Meta: # 创建可调用内容
model = self.model # 导入当前操作模型对象
fields = "__all__" # 获取全部 return self.model_form_class or BaseModelForm # 如果有内容就传入内容,没有就走默认的Base的
# 有的时候需要重新写class BasemodelForm类并继承他 def add_view(self, request): # 视图函数add_view
BaseModelForm = self.get_model_form() # 通过get_model_form运行获取类
if request.method == "GET":
form_obj = BaseModelForm() # 实例化对象获取内容
return render(request, "stark/add_view.html", locals()) # 传到前端内容(属性)
else:
form_obj = BaseModelForm(request.POST) # 向渲染的模型类中加入数据
if form_obj.is_valid(): # 判断接收数据是否可用
form_obj.save() # 将数据保存到数据库
return redirect(self.get_list_url()) # 跳转
else:
return render(request, "stark/add_view.html", locals()) def change_view(self, request, id): # 创建change_view路由 ,传入request,id,通过反向解析获取id
BaseModelForm = self.get_model_form() # 通过方法获取modelform类
edit_obj = self.model.objects.filter(pk=id).first() # 通过id获取当前操作对象
if request.method == "GET":
form_obj = BaseModelForm(instance=edit_obj) # 通过instance参数,进行控制为传入对象可以到前端进行渲染
return render(request, "stark/change_view.html", locals())
else:
form_obj = BaseModelForm(request.POST, instance=edit_obj) # 接收前端内容,instance对象,是内容进行覆盖
if form_obj.is_valid():
form_obj.save() # 数据保存
return redirect(self.get_list_url())
else:
return render(request, "stark/change_view.html", locals()) def delete_view(self, request, id): # 接收反向解析传过来的id
if request.method == "POST":
self.model.objects.filter(pk=id).delete() # 接收id 删除主键
return redirect(self.get_list_url()) # 跳转
list_url = self.get_list_url() # 把展示界面传过去.方便用户取消 return render(request, "stark/delete_view.html", locals()) # 新建删除html @property
def get_urls(self):
temp = [
path("", self.list_view, name="%s_%s_list" % (self.app_label, self.model_name)),
path("add/", self.add_view, name="%s_%s_add" % (self.app_label, self.model_name)),
re_path("(\d+)/change/", self.change_view, name="%s_%s_change" % (self.app_label, self.model_name)),
re_path("(\d+)/delete/", self.delete_view, name="%s_%s_delete" % (self.app_label, self.model_name)),
] return (temp, None, None) class StarkSite:
'''
stark全局类
''' def __init__(self):
self._registry = {} def register(self, model, admin_class=None, **options):
admin_class = admin_class or ModelStark
self._registry[model] = admin_class(model) def get_urls(self):
# 动态为注册的模型类创建增删改查URL
temp = []
# {Book:ModelAdmin(Book),Publish:ModelAdmin(Publish)}
for model, config_obj in self._registry.items():
# print("---->", model, config_obj)
model_name = model._meta.model_name
app_label = model._meta.app_label
temp.append(
path("%s/%s/" % (app_label, model_name), config_obj.get_urls)
) '''
path("stark/app01/book",self.list_view)
path("stark/app01/book/add",self.add_view)
path("stark/app01/publish",self.list_view)
path("stark/app01/publish/add",self.add_view) ''' return temp @property
def urls(self):
return self.get_urls(), None, None site = StarkSite()
三:stark 中的search内容
知识点: django中的Q()使用
实例化Q 以后可以进行更改内容且 通过字符串进行修改
接口内容
注册接口内容

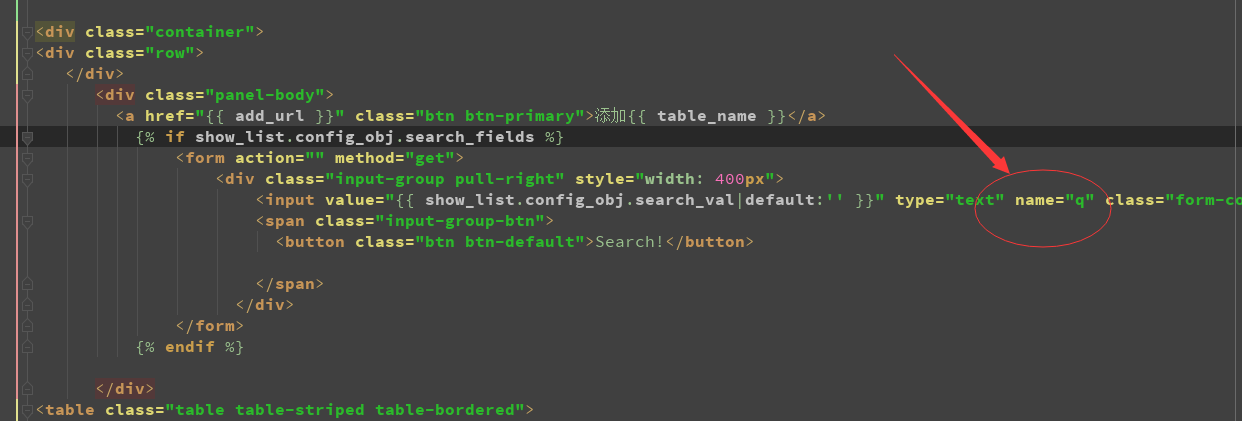
1 :前端代码内容
设置name=q 进行from 表单数据操作
通过if
进行判断如果有配置search_fidleds 接口则显示出搜索框,否则
不显示搜索框
2:stites 数据
_ _contains 进行数据模糊查询
3: 数据通过search 进行数据过滤
效果展示:
通过''阿'' 进行 搜索

day 68crm(5) 分页器的进一步优化,以及在stark上使用分页器,,以及,整理代码,以及stark组件search查询的更多相关文章
- EF之结构进一步优化
针对之前的使用,做了进一步优化 1.将DAL对象缓存起来 2.仓储类不依赖固定构造的DbContext,执行操作的时候,从线程中动态读取DbContext,这一步也是为了方便将DAL对象缓存起来,解决 ...
- 采用DTO和DAO对JDBC程序进行进一步优化
采用DTO和DAO对JDBC程序进行进一步优化 DTO:数据传输对象,主要用于远程调用等需要远程调用对象的地方DAO:数据访问对象,主要实现封装数据库的访问,通过它可以把数据库中的表转换成DTO类 引 ...
- 进一步优化SPA的首屏打开速度(模块化与懒载入) by 嗡
前言 单页应用的优点在于一次载入全部页面资源,利用本地计算能力渲染页面.提高页面切换速度与用户体验.但缺点在于全部页面资源将被一次性下载完,此时封装出来的静态资源包体积较大,使得第一次打开SPA页面时 ...
- 如何优化运行在webkit上的web app
如何优化运行在webkit上的web app 近来公司有个web app 项目运行在移动版android系统上,发现在电脑上跑的很流畅的web页面在移动版webkit上非常不流畅.根本无法和nativ ...
- 从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
首发于公众号:计算机视觉life 旗下知识星球「从零开始学习SLAM」 这可能是最清晰讲解g2o代码框架的文章 理解图优化,一步步带你看懂g2o框架 小白:师兄师兄,最近我在看SLAM的优化算法,有种 ...
- [Codeforces 1197E]Culture Code(线段树优化建图+DAG上最短路)
[Codeforces 1197E]Culture Code(线段树优化建图+DAG上最短路) 题面 有n个空心物品,每个物品有外部体积\(out_i\)和内部体积\(in_i\),如果\(in_i& ...
- SSE图像算法优化系列二十一:基于DCT变换图像去噪算法的进一步优化(100W像素30ms)。
在优化IPOL网站中基于DCT(离散余弦变换)的图像去噪算法(附源代码) 一文中,我们曾经优化过基于DCT变换的图像去噪算法,在那文所提供的Demo中,处理一副1000*1000左右的灰度噪音图像耗时 ...
- JavaScript中国象棋程序(8) - 进一步优化
在这最后一节,我们的主要工作是使用开局库.对根节点的搜索分离出来.以及引入PVS(Principal Variation Search,)主要变例搜索. 8.1.开局库 这一节我们引入book.js文 ...
- 进一步优化ListView
之前我已经分享过一篇:viewHodler的通用写法,就是专门用来优化listview的加载的,但是对于复杂的布局,我们还需要在listview滑动和不滑动时进行自己的处理,今天我看到一篇文章就是讲这 ...
随机推荐
- easyui-从数据库读取创建无极菜单
easyui-tree基础必须知道这个如下: 树控件使用<ul>元素定义.标签能够定义分支和子节点.节点都定义在<ul>列表内的<li>元素中.以下显示的元素将被用 ...
- 记录下 UTF6 GBK 转换函数
int GBK2UTF8(char *szGbk,char *szUtf8,int Len) { // 先将多字节GBK(CP_ACP或ANSI)转换成宽字符UTF-16 // 得到转换后,所需要的内 ...
- linux下集成开发环境之ECLIPSE--在线调试、编译程序
裸机开发流程 1.编写裸机程序:2.调试裸机程序:3.生成2进制映象(编译.链接.格式转换):4.烧写/运行2进制映象. 注意:我们自己开发的程序等等需要下载到开发板的Nandflash(类似于硬盘功 ...
- Windows10(uwp)开发中的侧滑
还是在持续的开发一款Windows10的应用中,除了上篇博客讲讲我在Windows10(uwp)开发中遇到的一些坑,其实还有很多不完善的地方,比如(UIElement.Foreground).(Gra ...
- Django(3)
https://www.cnblogs.com/yuanchenqi/articles/7429279.html
- Spring Boot的自动配置的原理浅析
一.原理描述 Spring Boot在进行SpringApplication对象实例化时会加载META-INF/spring.factories文件,将该配置文件中的配置载入到Spring容器. 二. ...
- tomcat自动关闭了。
测试方法: 1.狂点抽取大量数据的接口 结果: jvm里面的现成崩溃.导致tomcat错误. 思路: 最近发现tomcat老是自动关闭,开始也发现了,不过没放在心上,直到今天,请求一提交到服务器,to ...
- 3) Maven 目录结构
进入maven根目录 cmd 命令 tree E:. │ LICENSE.txt │ NOTICE.txt │ README.txt │ ├─bin │ m2.conf │ mvn │ mvn.bat ...
- Selenium2+python自动化之读取Excel数据(xlrd)
前言 当登录的账号有多个的时候,我们一般用excel存放测试数据,本节课介绍,python读取excel方法,并保存为字典格式. 一.环境准备 1.先安装xlrd模块,打开cmd,输入pip inst ...
- Android Studio生成get,set,tostring,构造方法
如何在AndroidStudio开发Android应用程序的时候,在对象模型中生成快捷方式生成get,set,tostring,构造方法等: 有两种方式: 第一种方式:Code –> Gener ...