python之旅:字符编码
一 了解字符编码的知识储备
一 计算机基础知识
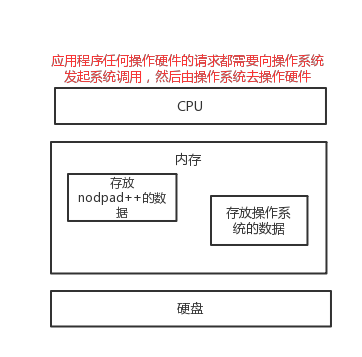
知识储备:cpu、内存、硬盘
二 文本编辑器存取文件的原理(nodepad++,pycharm,word)
#1、打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失 #2、要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。 #3、在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。结论:在编写py的程序的时候,是没有语法的限制的,编辑的结果跟编写一个普通的文本文件是没有任何区别,
只有把py程序交给python解释并且在运行的第三个阶段才有了语言意义
三 python解释器执行py文件的原理 ,例如python test.py
#第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器 #第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名) #第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码,当执行到name="egon"时,会开辟内存空间存放字符串"egon")
四 总结python解释器与文件本编辑的异同
#1、相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样 #2、不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法。
二 字符编码介绍
一 什么是字符编码
计算机要想工作必须通电,即用‘电’驱使计算机干活,也就是说‘电’的特性决定了计算机的特性。电的特性即高低电平(人类从逻辑上将二进制数1对应高电平,
二进制数0对应低电平),关于磁盘的磁特性也是同样的道理。结论:计算机只认识数字 很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符? 必须经过一个过程:
#字符--------(翻译过程)------->数字 #这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
二 以下两个场景下涉及到字符编码的问题:
#1、一个python文件中的内容是由一堆字符组成的,存取均涉及到字符编码问题(python文件并未执行,前两个阶段均属于该范畴) #2、python中的数据类型字符串是由一串字符组成的(python文件执行时,即第三个阶段)
三 字符编码的发展史(了解)
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。

因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
四 总结字符编码(重要)

基于目前的现状,内存中的编码固定就是unicode,我们唯一可变的就是硬盘的上对应的字符编码。
此时你可能会觉得,那如果我们以后开发软时统一都用unicode编码,那么不就都统一了吗,关于统一这一点你的思路是没错的,但我们不可会使用unicode编码来编写程序的文件,因为在通篇都是英文的情况下,耗费的空间几乎会多出一倍,这样在软件读入内存或写入磁盘时,都会徒增IO次数,从而降低程序的执行效率。因而我们以后在编写程序的文件时应该统一使用一个更为精准的字符编码utf-8(用1Bytes存英文,3Bytes存中文),再次强调,内存中的编码固定使用unicode。
1、在存入磁盘时,需要将unicode转成一种更为精准的格式,utf-8:全称Unicode Transformation Format,将数据量控制到最精简
2、在读入内存时,需要将utf-8转成unicode
所以我们需要明确:内存中用unicode是为了兼容万国软件,即便是硬盘中有各国编码编写的软件,unicode也有相对应的映射关系,但在现在的开发中,程序员普遍使用utf-8编码了,估计在将来的某一天等所有老的软件都淘汰掉了情况下,就可以变成:内存utf-8<->硬盘utf-8的形式了。
!!!总结非常重要的两点!!!
#1、保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码 #2、在内存中写的所有字符,一视同仁,都是unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是unicode转换成其他编码格式的过程了
python之旅:字符编码的更多相关文章
- python基础_字符编码
字符编码的历史 阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII 阶段二:为了满足中文,中国人定制了GBK 阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的 ...
- 第1章 Python基础之字符编码
阅读目录 一.什么是字符编码 二.字符编码分类 三.字符编码转换关系 3.1 程序运行原理 3.2 终极揭秘 3.3 补充 总结 回到顶部 一.什么是字符编码 计算机要想工作必须通电,也就是说'电'驱 ...
- 永久修改python默认的字符编码为utf-8
这个修改说来简单,其实不同的系统,修改起来还真不一样.下面来罗列下3中情况 首先所有修改的动作都是要创建一个叫 sitecustomize.py的文件,为什么要创建这个文件呢,是因为python在启动 ...
- Python基础之字符编码
前言 字符编码非常容易出问题,我们要牢记几句话: 1.用什么编码保存的,就要用什么编码打开 2.程序的执行,是先将文件读入内存中 3.unicode是父编码,只能encode解码成其他编码格式 utf ...
- python 基础之字符编码和文件处理
一.字符编码 (1)计算机基础知识 (2)python 解释器执行py文件的原理 <1>python 解释器启动 <2>python解释器相当于一个文本编辑器,打开txt.py ...
- Python系列之 - 字符编码问题
1.内存和硬盘都是用来存储的. CPU:速度快 硬盘:永久保存 2.文本编辑器存取文件的原理(nodepad++,pycharm,word) 打开编辑器就可以启动一个进程,是在内存中的,所以在编辑器编 ...
- (Python基础)字符编码与转码
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧 ...
- Python编程Day7——字符编码、字符与字节、文件操作
一.字符编码 重点 ***** 1. 什么是字符编码:将人识别的字符转换计算机能识别的01,转换的规则就是字符编码表2. 常用的编码表:ascii.unicode.GBK.Shift_JIS.Euc- ...
- Python全栈开发之路 【第三篇】:Python基础之字符编码和文件操作
本节内容 一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成 ...
- 第一章:python基础语法| 字符编码| 条件语句...
1.编程语言介绍 编程就是写代码,让计算机帮你做事情.计算机底层是电路,只认识二进制0和1.机器语言&汇编语言语言进化历史:机器.汇编.高级.机器语言只接受二进制代码:汇编语言是采用英文缩写的 ...
随机推荐
- TCP协议数据包及攻击分析
TCP/IP协议栈中一些报文的含义和作用 URG: Urget pointer is valid (紧急指针字段值有效) SYN: 表示建立连接 FIN: 表示关闭连接 ACK: 表示响应 PSH: ...
- 第二阶段每日站立会议Second Day
昨天我在手机端安装cpp后进行界面效果测试以及进一步完善 今天对图片显示的大小进行调整 遇到的问题:当图片太小时,显示一块灰色区域,不美观
- ASP.NET MVC5 学习系列之初探MVC
一.由问题看本质 (一)什么是MVC? MVC是Model-View-Controller的简称.它是在1970年引入的软件设计模式.MVC 模式强迫关注分离 — 域模型和控制器逻辑与UI是松耦合关系 ...
- 我对git的认识
Git 真的是不了解 也没听说过git 所以真的不知道从何谈起 所以就参考度娘啦! Git是一个开源的分布式版本控制系统,用以有效.高速的处理从很小到非常大的项目版本管理.Git 是 Linus To ...
- asp.net如何隐藏表格(table)的一行
直接用jquery $("#id1").click(function(){ $("#trId").css("display""no ...
- 删除一个数字之后数列gcd最大
★实验任务 顾名思义,互质序列是满足序列元素的 gcd 为 1 的序列.比如[1,2,3], [4,7,8],都是互质序列.[3,6,9]不是互质序列.现在并不要求你找出一个互质 序列,那样太简单了! ...
- Head First Java & final
- Java join & yield
Thread.yield()方法作用是:暂停当前正在执行的线程对象,并执行其他线程. yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会.因此,使用yie ...
- java杂项
简单介绍==和equals区别==是判断两个变量或实例是不是指向同一个内存空间equals是判断两个变量或实例所指向的内存空间的值是不是相同 final, finally, finalize的区别fi ...
- [51CTO]反客为主 ,Linux 成为微软 Azure 上最流行的操作系统
反客为主 ,Linux 成为微软 Azure 上最流行的操作系统 [世界上唯一确定不变的就是世界在不停的变化] 三年前,微软云计算 Azure 平台 CTO Mark Russinovich 说有四分 ...