Apache Spark-1.0.1集群搭建
欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3866791.html
Apache Spark a fast and general engine for large-scale data processing
Spark是一个高效的分布式计算系统,相比Hadoop,它在性能上比Hadoop要高100倍。Spark是发源于美国加州大学伯克利分校AMPLab的集群计算平台,它克服了MapReduce在迭代式计算和交互式计算方面的不足,通过引入RDD(Resilient Distributed Datasets)数据表示模型,能够很好地解决MapReduce不易解决的问题。相比于MapReduce,Spark能够充分利用内存资源提高计算效率。
一、基本环境
包含三个节点:
master(Ubuntu Desktop版本) 192.168.145.128
slave1(Ubuntu Server版本) 192.168.145.129
slave2(Ubuntu Server版本) 192.168.145.130
操作系统:Ubuntu14.04 x64
JDK版本:jdk1.8.0_11
Hadoop版本:Hadoop-2.2.0
Scala版本:2.10.4(官网要求2.10.X)
Spark版本:1.0.1
取得《Spark-1.0.1 的make-distribution.sh编译、SBT编译、Maven编译 三种编译方法》中编译好的 spark-1.0.1-bin-2.2.0.tgz
Hadoop-2.2.0集群的安装见http://www.cnblogs.com/fesh/p/3766656.html
Scala的安装见 http://www.cnblogs.com/fesh/p/3805611.html
(注:Scala在master节点上安装好后,直接用scp命令分发到slave1、slave2,并在slave1和slave2配置环境变量即可)
在master节点和slave1节点分别配置/etc/hosts和/etc/hostname:(下面这些应该在安装Hadoop集群时已经配置好了)
/etc/hosts
192.168.145.128 master
192.168.145.129 slave1
192.168.145.130 slave2
/etc/hostname (master)
master
/etc/hostname (slave1)
slave1
/etc/hostname (slave2)
slave2
二、Spark配置
1、master节点文件配置
在master节点:
解压spark-1.0.1-bin-2.2.0.tgz
tar -zxvf spark-1.0.-bin-2.2..tgz
在/etc/profile中配置环境变量
#Set SPARK_HOME
export SPARK_HOME=/home/fesh/spark-1.0.-bin-2.2.
export PATH=$PATH:$SPARK_HOME/bin
在spark-1.0.1-bin-2.2.0/conf下配置文件spark-env.sh和slaves:
cp spark-env.sh.template spark-env.sh
sudo gedit spark-env.sh
在文件spark-env.sh末尾添加:
export HADOOP_CONF_DIR=/home/fesh/hadoop-2.2./etc/hadoop
export JAVA_HOME=/usr/lib/jvm/jdk1..0_11
export SCALA_HOME=/home/fesh/scala-2.10.
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=512M
export SPARK_EXECUTOR_MEMORY=512M export SPARK_EXECUTOR_INSTANCES= (下面这几项可以不配置,采用默认就可以了)
export SPARK_EXECUTOR_CORES=
export SPARK_DRIVER_MEMORY=512M
export SPARK_YARN_APP_NAME="spark 1.0.1"
在文件slaves中去掉localhohst并设置
master
slave1
slave2
2、分发文件
分发spark-1.0.1-bin-2.2.0文件到slave1节点
scp -r spark-1.0.-bin-2.2. slave1:~/
分发spark-1.0.1-bin-2.2.0文件到slave2节点
scp -r spark-1.0.1-bin-2.2.0 slave2:~/
三、启动Spark集群
首先启动Hadoop-2.2.0集群,然后在spark-1.0.1-bin-2.2.0根目录下启动Spark集群
sbin/start-all.sh

对于slave1节点

对于slave2节点

四、查看信息
1、进入Spark集群的Web页面
在master节点上,浏览器访问: http://master:8080

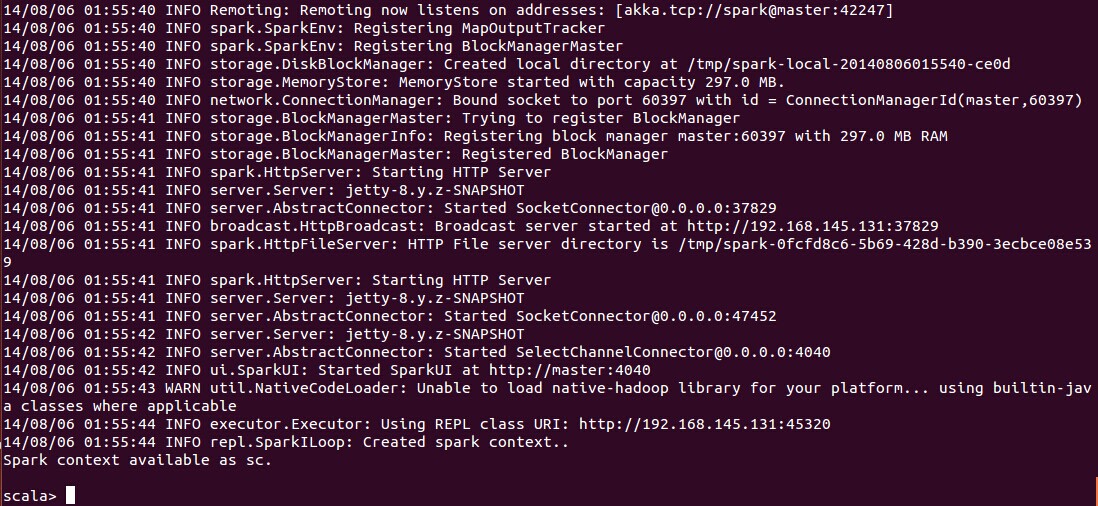
2、控制台查看
进入{SPARK_HOME}/bin目录,使用 spark-shell 控制台

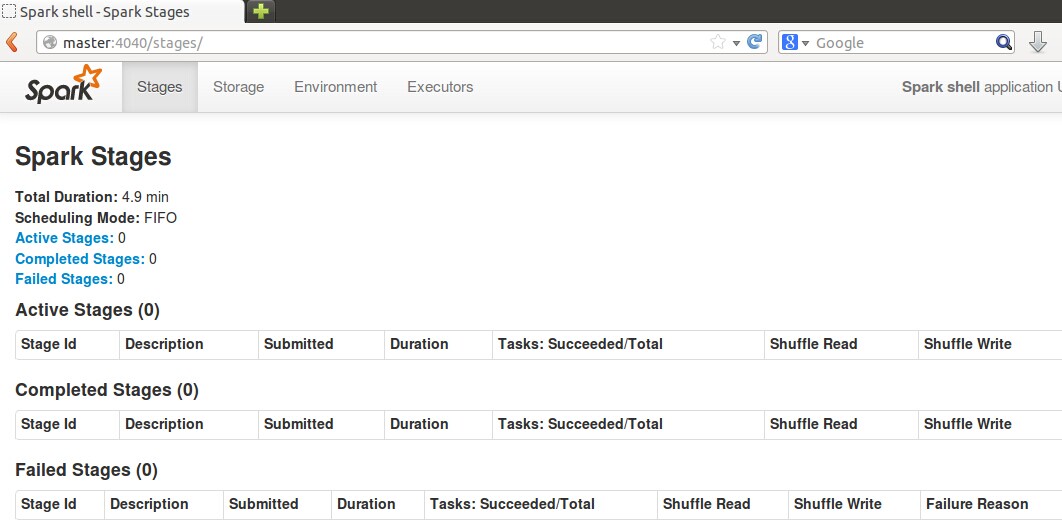
3、Web查看SparkUI
在master节点,浏览器进入 http://master:4040
五、停止Spark集群
sbin/stop-all.sh

参考:
1、http://spark.apache.org/docs/latest/running-on-yarn.html
2、http://spark.apache.org/docs/latest/configuration.html
Apache Spark-1.0.1集群搭建的更多相关文章
- spark 2.0.2 集群搭建
由于之前已经搭建过hadoop相关环境,现在搭建spark的预备工作只有scala环境了 一,配置scala环境 1.解压tar包后,编辑/etc/profile 2.source /etc/prof ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Redis 5.0.5集群搭建
Redis 5.0.5集群搭建 一.概述 Redis3.0版本之后支持Cluster. 1.1.redis cluster的现状 目前redis支持的cluster特性: 1):节点自动发现 2):s ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- CDH 6.0.1 集群搭建 「Before install」
从这一篇文章开始会有三篇文章依次介绍集群搭建 「Before install」 「Process」 「After install」 继上一篇使用 docker 部署单机 CDH 的文章,当我们使用 d ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
- CDH 6.0.1 集群搭建 「After install」
集群搭建完成之后其实还有很多配置工作要做,这里我列举一些我去做的一些. 首先是去把 zk 的角色重新分配一下,不知道是不是我在配置的时候遗漏了什么在启动之后就有报警说目前只能检查到一个节点.去将 zk ...
- ubuntu18.04 flink-1.9.0 Standalone集群搭建
集群规划 Master JobManager Standby JobManager Task Manager Zookeeper flink01 √ √ flink02 √ √ flink03 √ √ ...
- java_redis3.0.3集群搭建
redis3.0版本之后支持Cluster,具体介绍redis集群我就不多说,了解请看redis中文简介. 首先,直接访问redis.io官网,下载redis.tar.gz,现在版本3.0.3,我下面 ...
随机推荐
- C#利用SMTP服务器发送邮件
使用.net(C#)发送邮件学习手册(带成功案例) 1.了解发送邮件的三种方式 2.实例介绍使用client.DeliveryMethod = System.Net.Mail.SmtpDelivery ...
- @proprety数组字典字符串用copy和strong区别(深浅拷贝)
//// @proprety数组字典字符串用copy和strong区别(深浅拷贝).h// IOS笔记//// /* _proprety________copy_strong_________h ...
- 源码分析:Java对象的内存分配
Java对象的分配,根据其过程,将其分为快速分配和慢速分配两种形式,其中快速分配使用无锁的指针碰撞技术在新生代的Eden区上进行分配,而慢速分配根据堆的实现方式.GC的实现方式.代的实现方式不同而具有 ...
- trace工具,c++/c#/python
下载地址: http://files.cnblogs.com/files/wjx0912/xtrace.rar 很方便的调试工具,已在c#, vc2015, python2.7.10环境下测试. 闭 ...
- IE6与 javascript:void(0)
遇到过几次这种问题,现在总结一下. 代码: <a onclick="window.location.href='http://www.google.com'" href=&q ...
- Android AChartEngine 去除折线图黑边
通常使用AChartEngine画出的折线图,如果背景不是黑色,则会在折线图的坐标轴旁边出现黑边,如图所示: 试了好多设置,最后终于发现,去除黑边的设置是: mRenderer.setMarginsC ...
- 不使用spring的情况下原生java代码两种方式操作mongodb数据库
由于更改了mongodb3.0数据库的密码,导致这几天storm组对数据进行处理的时候,一直在报mongodb数据库连接不上的异常. 主要原因实际上是和mongodb本身无关的,因为他们改的是配置 ...
- TMS320C54x系列DSP指令和编程指南——第2章 通目标文件格式介绍
第2章 通用目标文件格式介绍 汇编器和连接器可以产生在TMS320C54x器件上执行的目标文件,这些目标文件的格式称为通用目标文件格式(COFF).采用COFF格式有利于程序的模式化编程,因为它支持用 ...
- PLSQL 逻辑多线程
PROCEDURE get_sheetid(i_topic IN VARCHAR2, o_newsheetid OUT VARCHAR2) IS PRAGMA AUTONOMOUS_TRANSA ...
- java gui 下拉框中项删除按钮
http://www.cnblogs.com/kangls/archive/2013/03/21/2972943.html http://m.blog.csdn.net/blog/ycb1689/74 ...