【AppScan】入门工作原理详解
AppScan,即 AppScan standard edition。其安装在 Windows 操作系统上,可以对网站等 Web 应用进行自动化的应用安全扫描和测试。Rational AppScan(简称 AppScan)其实是一个产品家族,包括众多的应用安全扫描产品,从开发阶段的源代码扫描的 AppScan source edition,到针对 Web 应用进行快速扫描的 AppScan standard edition,以及进行安全管理和汇总整合的 AppScan enterprise Edition 等。我们经常说的 AppScan 就是指的桌面版本的 AppScan,即 AppScan standard edition。其安装在 Windows 操作系统上,可以对网站等 Web 应用进行自动化的应用安全扫描和测试。
AppScan 三个核心要素
- 通过搜索(爬行)发现整个 Web 应用结构
- 根据分析,发送修改的 HTTP Request 进行攻击尝试(扫描规则库)
- 通过对于 Respone 的分析验证是否存在安全漏洞
AppScan 扫描原理:扫描规则库 + 爬行 + 测试

步骤 1:探索(又叫爬行,爬网)
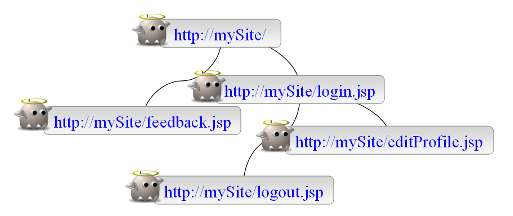
步骤 2:测试(针对找到的页面,生成测试,进行安全攻击)

所以,简言之,AppScan 的核心是提供一个扫描规则库,然后利用自动化的“探索”技术得到众多的页面和页面参数,进而对这些页面和页面参数进行安全性测试。“扫描规则库”,“探索”,“测试”就构成了 AppScan 的核心三要素。而在安全扫描过程中,如何进行优化,就要结合这三个要素,看哪些部分需要优化,应该如何优化。
AppScan 结果文件
- 扫描配置信息:扫描配置信息,如扫描的目标网站地址,录制的登陆过程脚本等,选择的扫描设置等都保存在 Scan 文件中。
- 所有访问到页面信息:针对每个发现的页面,即使没有进行测试,在探索过程也会访问该页面并纪录 http request/response 信息;所以如果探索的页面访问的时候返回的页面内容比较多,页面比较大,那么即使只做了探索根本没有扫描,整个 Scan 文件也会很大。
- 测试阶段,记录测试成功的测试变体和页面访问信息:针对每个页面都会发送多次测试(测试变体),每次测试都会有 Request/response 信息,这些信息如果测试通过,即发现了一个安全问题,则会把该测试变体对应得 request/response 都会纪录下来,保存在 .scan 文件中;由于 AppScan 的扫描测试用例库全面,对于每种安全威胁漏洞,都会发送多个安全测试变体(Variant)进行测试,比如对于 XSS 问题,AppScan 发送了 100 个变体,其中 30 个执行失败,70 个变体执行成功,则会纪录 70 次执行成功的具体变体信息,以及每个变体对应的 Request/Response 信息。这就是一个很大的数据量。这些信息保存以后,就可以在不连接在网站的情况下进行结果分析,快速显示当时测试的页面快照等。
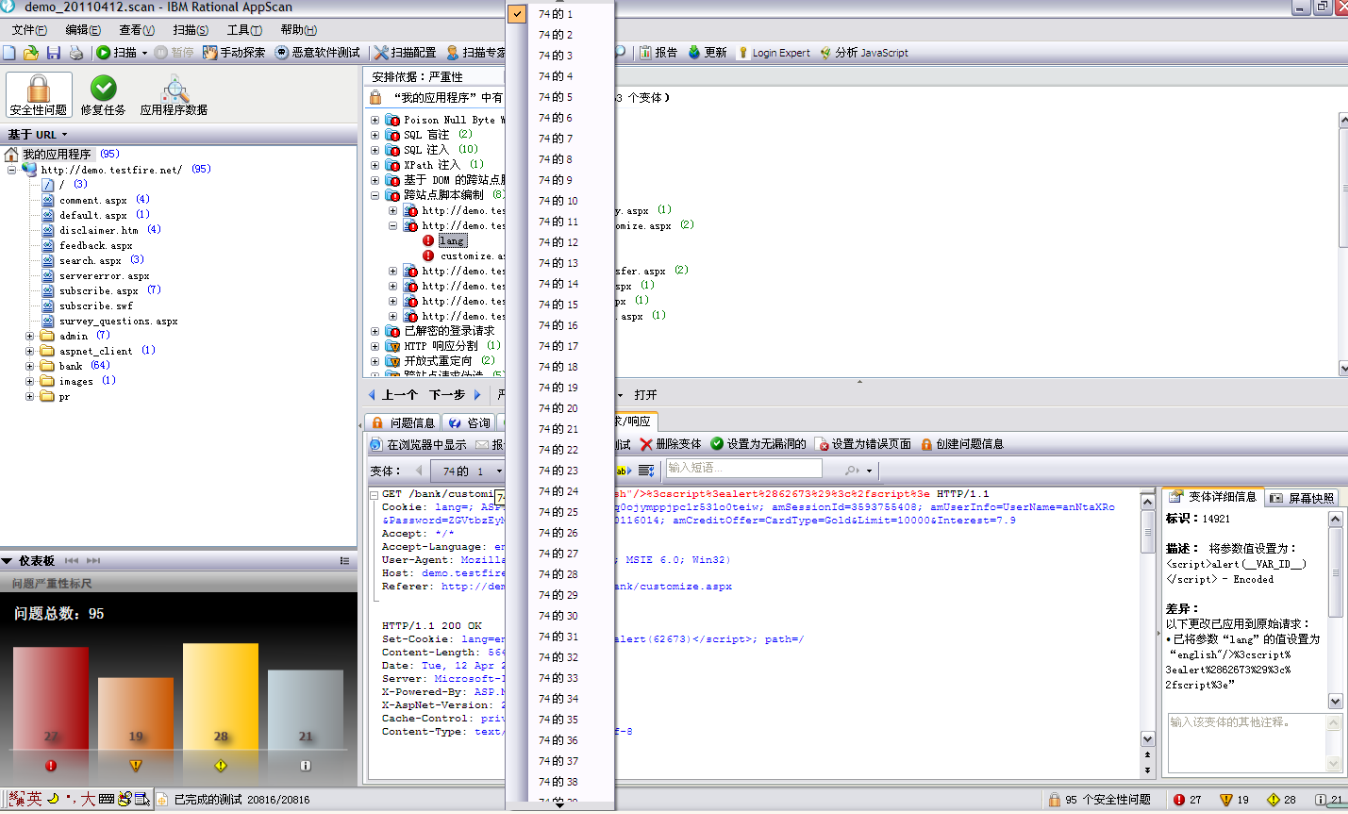
所以针对 AppScan 标准版来说,由于需要保存的信息比较多,结果文件是会比较大的,最根本的方法还是有针对性地进行扫描和测试,使用排除页面等排除冗余页面,把一个大的系统分解为多个小的扫描任务等。
大型网站技术特点分析
- 网站规模(页面个数,页面参数)
- 扫描策略的选择
- 扫描设置
- 选择合适的,最小化的扫描规则
- 分解扫描任务,把一个大的扫描任务分解为多个小的扫描任务
- 根据页面特点,设置可以过滤的类似页面(冗余页面)
参考博主:https://www.cnblogs.com/mawenqiangios/p/8573525.html
【AppScan】入门工作原理详解的更多相关文章
- AppScan入门工作原理详解
AppScan,即 AppScan standard edition.其安装在 Windows 操作系统上,可以对网站等 Web 应用进行自动化的应用安全扫描和测试. Rational AppScan ...
- 块级格式化上下文(block formatting context)、浮动和绝对定位的工作原理详解
CSS的可视化格式模型中具有一个非常重要地位的概念——定位方案.定位方案用以控制元素的布局,在CSS2.1中,有三种定位方案——普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inli ...
- log4j-over-slf4j工作原理详解
log4j-over-slf4j工作原理详解 摘自:https://blog.csdn.net/john1337/article/details/76152906 置顶 2017年07月26日 17: ...
- Appscan工作原理详解
AppScan,即 AppScan standard edition.其安装在 Windows 操作系统上,可以对网站等 Web 应用进行自动化的应用安全扫描和测试. Rational AppScan ...
- ASP.NET页面与IIS底层交互和工作原理详解
转载自:http://www.cnblogs.com/lidabo/archive/2012/03/13/2393200.html 第一回: 引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是 ...
- ASP.NET页面与IIS底层交互和工作原理详解(第一回)
引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是站在一个比较高的层次上讲解Asp.Net.他们耐心.细致地告诉你如何一步步拖放控件.设置控件属性.编写CodeBehind代码,以实现某个特定 ...
- 交换机工作原理、MAC地址表、路由器工作原理详解
一:MAC地址表详解 说到MAC地址表,就不得不说一下交换机的工作原理了,因为交换机是根据MAC地址表转发数据帧的.在交换机中有一张记录着局域网主机MAC地址与交换机接口的对应关系的表,交换机就是根据 ...
- HTTP响应报文与工作原理详解
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
- 【转】HTTP响应报文与工作原理详解
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
随机推荐
- 在一般处理程序清理cookie
清理cookie在ashx里面很奇怪,因为直接设置过期时间并不能成功,cookie还是会存在.所以需要添加一个同名的Cookie设置过期时间覆盖 HttpCookie cookie = null; / ...
- sql 存储过程带有模糊查询条件
一个简单的存储过程: Create procedure [dbo].[Proc_SeachJob] (@startRecordIndex int, @endRecordIndex int, @seac ...
- tinymce与prism代码高亮实现及汉化的配置
简单介绍:TinyMCE是一个轻量级的基于浏览器的所见即所得编辑器,由JavaScript写成.它对IE6+和Firefox1.5+都有着非常良好的支持.功能方强大,并且功能配置灵活简单.另一特点是加 ...
- 设置TeeChart的提示文本
使用第三方Steema的TeeChart控件,设置鼠标放在某一线条点上,显示某一点的数据标签问题(虚线型十字光标基准线,放在线上显示对应点的二维坐标轴数据数据),调用InitTeeChartTipTo ...
- 474. Ones and Zeroes
In the computer world, use restricted resource you have to generate maximum benefit is what we alway ...
- 鸡肋点搭配ClickJacking攻击-获取管理员权限
作者:jing0102 前言 有一段时间没做测试了,偶尔的时候也会去挖挖洞.本文章要写的东西是我利用ClickJacking拿下管理员权限的测试过程.但在说明过程之前,先带大家了解一下ClickJac ...
- Instant low voltage or power off to make computer power burn down
严重则可造成硬盘直接报废! 原理:瞬间低压或者断电,滤波电容上存储的电能已经被使用,此时再瞬间供电则会重新对电容充电,而限流电阻还没有恢复到保护状态,于是会产生很大的冲击电流,从而导致了全桥元件或保险 ...
- lamp-linux-1
LAMP编程之Linux(1) LAMP:Linux Apache MySQL PHP LNMP:Linux Nginx MySQL PHP WAMP:Windows Apache MySQL PHP ...
- html基础整理(01居中 盒子问题)
01 文字居中 将一段文字置于容器的水平中点,只要设置text-align属性即可: text-align:center; 02 容器水平居中 先为该容器设置一个明确宽度,然后将margin的水平 ...
- jquery源码解析:jQuery队列操作queue方法实现的原理
我们先来看一下jQuery中有关队列操作的方法集: 从上图可以看出,既有静态方法,又有实例方法.queue方法,相当于数组中的push操作.dequeue相当于数组的shift操作.举个例子: fun ...