Faster R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年
paper链接:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
&创新点
设计Region Proposal Networks【RPN】,利用CNN卷积操作后的特征图生成region proposals,代替了Selective Search、EdgeBoxes等方法,速度上提升明显;
训练Region Proposal Networks与检测网络【Fast R-CNN】共享卷积层,大幅提高网络的检测速度。
&问题是什么
继Fast R-CNN后,在CPU上实现的区域建议算法Selective Search【2s/image】、EdgeBoxes【0.2s/image】等成了物体检测速度提升上的最大瓶颈。
&如何解决问题
。测试过程
Faster R-CNN统一的网络结构如下图所示,可以简单看作RPN网络+Fast R-CNN网络。
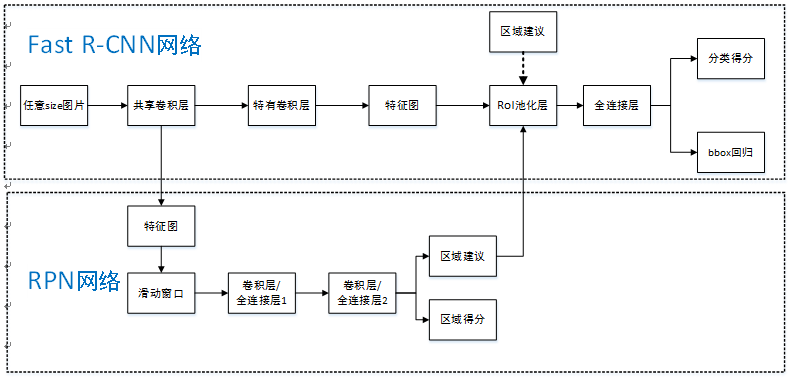
注意:上图Fast R-CNN中含特有卷积层,博主认为不是所有卷积层都参与共享。
首先向CNN网络【ZF或VGG-16】输入任意大小图片;
经过CNN网络前向传播至最后共享的卷积层,一方面得到供RPN网络输入的特征图,另一方面继续前向传播至特有卷积层,产生更高维特征图;
供RPN网络输入的特征图经过RPN网络得到区域建议和区域得分,并对区域得分采用非极大值抑制【阈值为0.7】,输出其Top-N【文中为300】得分的区域建议给RoI池化层;
第2步得到的高维特征图和第3步输出的区域建议同时输入RoI池化层,提取对应区域建议的特征;
第4步得到的区域建议特征通过全连接层后,输出该区域的分类得分以及回归后的bounding-box。
。解释分析
RPN网络结构是什么?实现什么功能?具体如何实现?
单个RPN网络结构如下图:
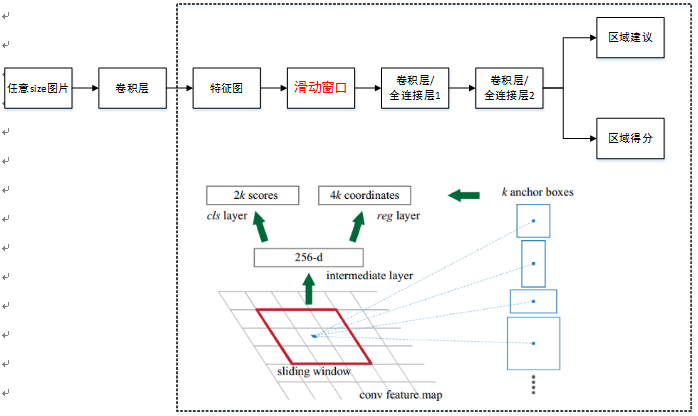
注意:上图中卷积层/全连接层表示卷积层或者全连接层,作者在论文中表示这两层实际上是全连接层,但是网络在所有滑窗位置共享全连接层,可以很自然地用n×n卷积核【论文中设计为3×3】跟随两个并行的1×1卷积核实现,文中这么解释的,博主并不是很懂,尴尬。功能:实现attention机制,如图所示,RPN在CNN卷积层后增加滑动窗口操作以及两个卷积层完成区域建议功能,第一个卷积层将特征图每个滑窗位置编码成一个特征向量,第二个卷积层对应每个滑窗位置输出k个区域得分和k个回归后的区域建议,并对得分区域进行非极大值抑制后输出得分Top-N【文中为300】区域,告诉检测网络应该注意哪些区域,本质上实现了Selective Search、EdgeBoxes等方法的功能。
具体实现:
①首先套用ImageNet上常用的图像分类网络,本文中试验了两种网络:ZF或VGG-16,利用这两种网络的部分卷积层产生原始图像的特征图;② 对于①中特征图,用n×n【论文中设计为3×3,n=3看起来很小,但是要考虑到这是非常高层的feature map,其size本身也没有多大,因此9个矩形中,每个矩形窗框都是可以感知到很大范围的】的滑动窗口在特征图上滑动扫描【代替了从原始图滑窗获取特征】,每个滑窗位置通过卷积层1映射到一个低维的特征向量【ZF网络:256维;VGG-16网络:512维,低维是相对于特征图大小W×H,typically~60×40=2400】后采用ReLU,并为每个滑窗位置考虑k种【论文中k=9】可能的参考窗口【论文中称为anchors,见下解释】,这就意味着每个滑窗位置会同时预测最多9个区域建议【超出边界的不考虑】,对于一个W×H的特征图,就会产生W×H×k个区域建议;
③步骤②中的低维特征向量输入两个并行连接的卷积层2:reg窗口回归层【位置精修】和cls窗口分类层,分别用于回归区域建议产生bounding-box【超出图像边界的裁剪到图像边缘位置】和对区域建议是否为前景或背景打分,这里由于每个滑窗位置产生k个区域建议,所以reg层有4k个输出来编码【平移缩放参数】k个区域建议的坐标,cls层有2k个得分估计k个区域建议为前景或者背景的概率
Anchors是什么?有什么用?
Anchors是一组大小固定的参考窗口:三种尺度{128^2,256^2,512^2}×三种长宽比{1:1,1:2,2:1},如下图所示,表示RPN网络中对特征图滑窗时每个滑窗位置所对应的原图区域中9种可能的大小,相当于模板,对任意图像任意滑窗位置都是这9中模板。继而根据图像大小计算滑窗中心点对应原图区域的中心点,通过中心点和size就可以得到滑窗位置和原图位置的映射关系,由此原图位置并根据与Ground Truth重复率贴上正负标签,让RPN学习该Anchors是否有物体即可。
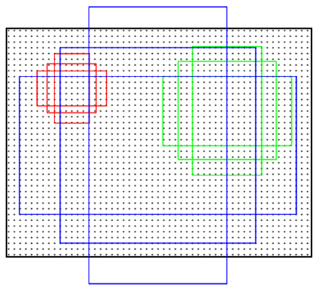
作者在文中表示采用Anchors这种方法具有平移不变性,就是说在图像中平移了物体,窗口建议也会跟着平移。同时这种方式也减少了整个模型的size,输出层512×(4+2)×9=2.8×10^4个参数【512是前一层特征维度,(4+2)×9是9个Anchors的前景背景得分和平移缩放参数】,而MultiBox有1536×(4+1)×800=6.1×10^6个参数,而较小的参数可以在小数据集上减少过拟合风险。当然,在RPN网络中我们只需要找到大致的地方,无论是位置还是尺寸,后面的工作都可以完成,这样的话采用小网络进行简单的学习【估计和猜差不多,反正有50%概率】,还不如用深度网络【还可以实现卷积共享】,固定尺度变化,固定长宽比变化,固定采样方式来大致判断是否是物体以及所对应的位置并降低任务复杂度。
Anchors为什么考虑以上三种尺度和长宽比?
文中对Anchors的尺度以及长宽比选取进行了实验,如下图所示:
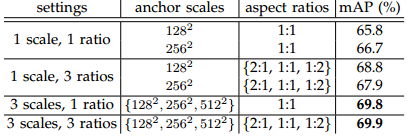
实验实在VGG-16模型下,采用PASCAL VOC 2007训练集和PASCAL VOC 2007测试集得到。相比于只采用单一尺度和长宽比,单尺度多长宽比和多尺度单长宽比都能提升mAP,表明多size的anchors可以提高mAP,作者在这里选取了最高mAP的3种尺度和3种长宽比。如何处理多尺度多长宽比问题?即如何使24×24和1080×720的车辆同时在一个训练好的网络中都能正确识别?
文中展示了两种解决多尺度多长宽比问题:一种是使用图像金字塔,对伸缩到不同size的输入图像进行特征提取,虽然有效但是费时;
另一种是使用滤波器金字塔或者滑动窗口金字塔,对输入图像采用不同size的滤波器分别进行卷积操作,这两种方式都需要枚举图像或者滤波器size;
作者提出了一种叫Anchors金字塔的方法来解决多尺度多长宽比的问题,在RPN网络中对特征图滑窗时,对滑窗位置中心进行多尺度多长宽比的采样,并对多尺度多长宽比的anchor boxes区域进行回归和分类,利用Anchors金字塔就仅仅依赖于单一尺度的图像和特征图和单一大小的卷积核,就可以解决多尺度多长宽比问题,这种对推荐区域采样的模型不管是速度还是准确率都能取得很好的性能。同传统滑窗方法提取区域建议方法相比,RPN网络有什么优势?
传统方法是训练一个能检测物体的网络,然后对整张图片进行滑窗判断,由于无法判断区域建议的尺度和长宽比,所以需要多次缩放,这样找出一张图片有物体的区域就会很慢;
虽然RPN网络也是用滑动窗口策略,但是滑动窗口实在卷积层特征图上进行的,维度较原始图像降低了很多倍【中间进行了多次max pooling 操作】,RPN采取了9种不同尺度不同长宽比的anchors,同时最后进行了bounding-box回归,即使是这9种anchors外的区域也能得到一个跟目标比较接近的区域建议。
。训练过程
RPN网络预训练
样本 来源 正样本 ILSVRC20XX 负样本 ILSVRC20XX 样本中只有类别标签;
文中一带而过RPN网络被ImageNet网络【ZF或VGG-16】进行了有监督预训练,利用其训练好的网络参数初始化;
用标准差0.01均值为0的高斯分布对新增的层随机初始化。Fast R-CNN网络预训练
样本 来源 正样本 ILSVRC20XX 负样本 ILSVRC20XX 样本中只有类别标签;
文中一带而过Fast R-CNN网络被ImageNet网络【ZF或VGG-16】进行了有监督预训练,利用其训练好的网络参数初始化。RPN网络微调训练
RPN网络样本 来源 正样本 与Ground Truth相交IoU最大的anchors【以防后一种方式下没有正样本】+与Ground Truth相交IoU>0.7的anchors 负样本 与Ground Truth相交IoU<0.3的anchors PASCAL VOC 数据集中既有物体类别标签,也有物体位置标签;
正样本仅表示前景,负样本仅表示背景;
回归操作仅针对正样本进行;
训练时弃用所有超出图像边界的anchors,否则在训练过程中会产生较大难以处理的修正误差项,导致训练过程无法收敛;
对去掉超出边界后的anchors集采用非极大值抑制,最终一张图有2000个anchors用于训练【详细见下】;
对于ZF网络微调所有层,对VGG-16网络仅微调conv3_1及conv3_1以上的层,以便节省内存。SGD mini-batch采样方式:同Fast R-CNN网络,采取”image-centric”方式采样,即采用层次采样,先对图像取样,再对anchors取样,同一图像的anchors共享计算和内存。每个mini-batch包含从一张图中随机提取的256个anchors,正负样本比例为1:1【当然可以对一张图所有anchors进行优化,但由于负样本过多最终模型会对正样本预测准确率很低】来计算一个mini-batch的损失函数,如果一张图中不够128个正样本,拿负样本补凑齐。
训练超参数选择:在PASCAL VOC数据集上前60k次迭代学习率为0.001,后20k次迭代学习率为0.0001;动量设置为0.9,权重衰减设置为0.0005。
一张图片多任务目标函数【分类损失+回归损失】具体如下:
L({pi},{ti})=1Ncls∑iLcls(pi,pi∗)+λ1Nreg∑ipi∗Lreg(ti,ti∗)" style="text-align: center; position: relative;">L({pi},{ti})=1Ncls∑iLcls(pi,p∗i)+λ1Nreg∑ip∗iLreg(ti,t∗i)L({pi},{ti})=1Ncls∑iLcls(pi,pi∗)+λ1Nreg∑ipi∗Lreg(ti,ti∗)解释说明:
其中,i表示一个mini-batch中某个anchor的下标,pi" style="position: relative;">pipi表示anchor i预测为物体的概率;当anchor为正样本时,pi∗=1" style="position: relative;">p∗i=1pi∗=1,当anchor为负样本时pi∗=0" style="position: relative;">p∗i=0pi∗=0,由此可以看出回归损失项仅在anchor为正样本情况下才被激活;
ti" style="position: relative;">titi表示正样本anchor到预测区域的4个平移缩放参数【以anchor为基准的变换】;ti∗" style="position: relative;">t∗iti∗表示正样本anchor到Ground Truth的4个平移缩放参数【以anchor为基准的变换】;
分类损失函数Lcls " style="position: relative;">Lcls Lcls 是一个二值【是物体或者不是物体】分类器,Lcls(pi,pi∗)=−log[pi∗pi+(1−pi∗)(1−pi)] " style="position: relative;">Lcls(pi,p∗i)=−log[p∗ipi+(1−p∗i)(1−pi)] Lcls(pi,pi∗)=−log[pi∗pi+(1−pi∗)(1−pi)] ;
归回损失函数Lreg(ti,ti∗)=R(ti−ti∗)" style="position: relative;">Lreg(ti,t∗i)=R(ti−t∗i)Lreg(ti,ti∗)=R(ti−ti∗)【两种变换之差越小越好】,R函数定义如下:
smoothL1(x)={0.5x2,if |x|<1|x|−0.5otherwise" style="text-align: center; position: relative;">smoothL1(x)={0.5x2,|x|−0.5if |x|<1otherwisesmoothL1(x)={0.5x2,if |x|<1|x|−0.5otherwiseλ" style="position: relative;">λλ参数用来权衡分类损失Lcls " style="position: relative;">Lcls Lcls 和回归损失Lreg" style="position: relative;">LregLreg,默认值λ=10" style="position: relative;">λ=10λ=10【文中实验表明 λ" style="position: relative;">λλ从1变化到100对mAP影响不超过1%】;
Ncls" style="position: relative;">NclsNcls和Nreg" style="position: relative;">NregNreg分别用来标准化分类损失项Lcls " style="position: relative;">Lcls Lcls 和回归损失项Lreg" style="position: relative;">LregLreg,默认用mini-batch size=256设置Ncls" style="position: relative;">NclsNcls,用anchor位置数目~2400初始化Nreg" style="position: relative;">NregNreg,文中也说明标准化操作并不是必须的,可以简化省略。
Fast R-CNN网络微调训练
Fast R-CNN网络样本 来源 正样本 Ground Truth +与Ground Truth相交IoU>阈值的区域建议 负样本 与Ground Truth相交IoU<阈值的区域建议 PASCAL VOC 数据集中既有物体类别标签,也有物体位置标签;
正样本表示每类物品的Ground Truth以及与Ground Truth重叠度超过某一阈值的区域建议,负样本表示同Ground Truth重叠度小于某一阈值的区域建议;
回归操作仅针对正样本进行。RPN网络、Fast R-CNN网络联合训练
训练网络结构示意图如下所示:
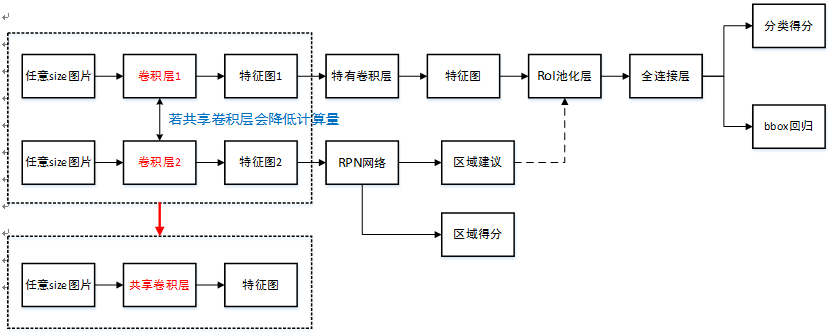
如上图所示,RPN网络、Fast R-CNN网络联合训练是为了让两个网络共享卷积层,降低计算量。
文中通过4步训练算法,交替优化学习至共享特征:
① 进行上面RPN网络预训练,和以区域建议为目的的RPN网络end-to-end微调训练;
② 进行上面Fast R-CNN网络预训练,用第①步中得到的区域建议进行以检测为目的的Fast R-CNN网络end-to-end微调训练【此时无共享卷积层】;
③ 使用第②步中微调后的Fast R-CNN网络重新初始化RPN网络,固定共享卷积层【即设置学习率为0,不更新】,仅微调RPN网络独有的层【此时共享卷积层】;
④ 固定第③步中共享卷积层,利用第③步中得到的区域建议,仅微调Fast R-CNN独有的层,至此形成统一网络如上图所示。
。解释分析
RPN网络中bounding-box回归怎么理解?同Fast R-CNN中的bounding-box回归相比有什么区别?
对于bounding-box回归,采用以下公式:tx=(x−xa)/waty=(y−ya)/ha" style="text-align: center; position: relative;">tx=(x−xa)/waty=(y−ya)/hatx=(x−xa)/waty=(y−ya)/hatw=log(w/wa)th=log(h/ha)" style="text-align: center; position: relative;">tw=log(w/wa)th=log(h/ha)tw=log(w/wa)th=log(h/ha)tx∗=(x∗−xa)/waty∗=(y∗−ya)/ha" style="text-align: center; position: relative;">t∗x=(x∗−xa)/wat∗y=(y∗−ya)/hatx∗=(x∗−xa)/waty∗=(y∗−ya)/hatw∗=log(w∗/wa)th∗=log(h∗/ha)" style="text-align: center; position: relative;">t∗w=log(w∗/wa)t∗h=log(h∗/ha)tw∗=log(w∗/wa)th∗=log(h∗/ha)其中,x,y,w,h表示窗口中心坐标和窗口的宽度和高度,变量x" style="position: relative;">xx,xa" style="position: relative;">xaxa和x∗" style="position: relative;">x∗x∗分别表示预测窗口、anchor窗口和Ground Truth的坐标【y,w,h同理】,因此这可以被认为是一个从anchor窗口到附近Ground Truth的bounding-box 回归;
RPN网络中bounding-box回归的实质其实就是计算出预测窗口。这里以anchor窗口为基准,计算Ground Truth对其的平移缩放变化参数,以及预测窗口【可能第一次迭代就是anchor】对其的平移缩放参数,因为是以anchor窗口为基准,所以只要使这两组参数越接近,以此构建目标函数求最小值,那预测窗口就越接近Ground Truth,达到回归的目的;
文中提到, Fast R-CNN中基于RoI的bounding-box回归所输入的特征是在特征图上对任意size的RoIs进行Pool操作提取的,所有size RoI共享回归参数,而在Faster R-CNN中,用来bounding-box回归所输入的特征是在特征图上相同的空间size【3×3】上提取的,为了解决不同尺度变化的问题,同时训练和学习了k个不同的回归器,依次对应为上述9种anchors,这k个回归量并不分享权重。因此尽管特征提取上空间是固定的【3×3】,但由于anchors的设计,仍能够预测不同size的窗口。
文中提到了三种共享特征网络的训练方式?
① 交替训练
训练RPN,得到的区域建议来训练Fast R-CNN网络进行微调;此时网络用来初始化RPN网络,迭代此过程【文中所有实验采用】;② 近似联合训练
如上图所示,合并两个网络进行训练,前向计算产生的区域建议被固定以训练Fast R-CNN;反向计算到共享卷积层时RPN网络损失和Fast R-CNN网络损失叠加进行优化,但此时把区域建议【Fast R-CNN输入,需要计算梯度并更新】当成固定值看待,忽视了Fast R-CNN一个输入:区域建议的导数,则无法更新训练,所以称之为近似联合训练。实验发现,这种方法得到和交替训练相近的结果,还能减少20%~25%的训练时间,公开的python代码中使用这种方法;③ 联合训练
需要RoI池化层对区域建议可微,需要RoI变形层实现,具体请参考这片paper:Instance-aware Semantic Segmentation via Multi-task Network Cascades。图像Scale细节问题?
文中提到训练和检测RPN、Fast R-CNN都使用单一尺度,统一缩放图像短边至600像素;
在缩放的图像上,对于ZF网络和VGG-16网络的最后卷积层总共的步长是16像素,因此在缩放前典型的PASCAL图像上大约是10像素【~500×375;600/16=375/10】。网上关于Faster R-CNN中三种尺度这么解释:
原始尺度:原始输入的大小,不受任何限制,不影响性能;
归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定,这个参数和anchor的相对大小决定了想要检测的目标范围;
网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224×224。
以上6行博主并不懂,还需要仔细研究源码。理清文中anchors的数目。
文中提到对于1000×600的一张图像,大约有20000(~60×40×9)个anchors,忽略超出边界的anchors剩下6000个anchors,利用非极大值抑制去掉重叠区域,剩2000个区域建议用于训练;
测试时在2000个区域建议中选择Top-N【文中为300】个区域建议用于Fast R-CNN检测。
&结果怎么样
PASCAL VOC实验【使用ZF网络】
属性 数目 目标类别 20 PASCAL VOC 2007训练集 5k PASCAL VOC 2007测试集 5k a.第1组实验
目的:验证RPN方法的有效性;
做法:ZF检测网络训练和测试时分别使用Selective Search、EdgeBoxes和RPN+ZF【共享】方法,Selective Search、EdgeBoxes测试时使用2000窗口建议,RPN+ZF测试时采用300窗口建议;
结果:RPN+ZF方法获得59.9%的mAP,由于卷积层共享并且只有300个候选窗口,RPN+ZF方法检测速度更快;b.第2组实验
目的:验证RPN和ZF检测网络共享卷积层的影响;
做法:在之前所述4步训练算法进行到第2步后停止;
结果:未实现卷积层共享的RPN+ZF的方法获得58.7%的mAP,这由于4步训练算法的第3步使用了微调后检测器特征来微调RPN网络,使得建议窗口质量得到提高;c.第3组实验
目的:使用不同RPN候选窗数目下,评估其对检测网络mAP的影响;
做法:使用Selective Search方法训练检测网络ZF并固定不变【RPN与ZF没有共享卷积层】,测试时采用不同RPN候选窗数目进行;
结果:测试时300候选窗RPN获得56.8%的mAP,这是由于训练和测试的区域建议方法不一致造成;使用Top-100窗口建议仍然有55.1%的mAP,说明Top-100结果比较准确;未使用非极大值抑制的6000个区域建议全部使用进行检测获得55.2%的mAP,说明非极大值抑制并未损坏精度,反而可能减少了误报;d.第4组实验
目的:验证RPN网络cls窗口分类层影响;
做法:使用Selective Search方法训练检测网络ZF并固定不变【RPN与ZF没有共享卷积层】,移除RPN网络中cls窗口分类层【缺少分数就没有了非极大值抑制和Top排名】,从未评分的窗口建议中随机采用N个 ;
结果:N=1000时,mAP为55.8%影响不大,但N=100时mAP为44.6%,说明cls窗口分类层的评分准确度高,影响检测结果精度;e.第5组实验
目的:验证RPN网络reg窗口回归层影响;
做法:使用Selective Search方法训练检测网络ZF并固定不变【RPN与ZF没有共享卷积层】,移除RPN网络reg窗口回归层【候选区域直接变成没有回归的anchor boxes】;
结果:选择Top-300进行实验,mAP掉到了52.1%,说明窗口回归提高了区域建议的质量,虽然说anchor boxes能应对不同尺度和宽高比,但是对于精确检测远远不够;f.第6组实验
目的:验证优质量网络对RPN产生区域建议的影响;
做法:使用Selective Search方法训练检测网络ZF并固定不变【RPN与ZF没有共享卷积层】,采用VGG-16网络训练RPN提供候选区域;
结果:与第3组实验测试时300候选窗RPN获得56.8%的mAP相比,采用VGG-16训练RPN使得mAP达到59.2%,表明VGG-16+RPN提供区域建议质量更高【不像死板板的Selective Search,RPN可以从更好的网络中获利进行变化】,因此RPN和检测网络同时采用VGG-16并共享卷积层会如何呢?结果见下。RPN网络和检测网络同时采用VGG-16并共享卷积层,在PASCAL VOC 2007训练集上训练,测试集上获得69.9%的mAP;在联合数据集如PASCAL VOC 2007和2012训练集上训练RPN网络和检测网络,PASCAL VOC 2007测试集上mAP会更高。
对于检测速度而言,采用ZF模型,可以达到17fps;采用VGG-16模型,可以达到5fps,由于卷积共享,RPN网络仅仅花10ms计算额外的层,而且,由于仅仅选取Top-N【文中为300】进行检测,检测网络中的非极大值抑制、池化、全连接以及softmax层花费时间是极短的。
召回率分析。所谓召回率即区域建议网络找出的为真的窗口与Ground Truth的比值【IoU大于阈值即为真】,文中实验表明Selective Search、EdgeBoxes方法从Top-2000、Top-1000到Top-300的召回率下降明显,区域建议越少下降越明显,而RPN网络召回率下降很少,说明RPN网络Top-300区域建议已经同Ground Truth相差无己,目的性更明确。
MS COCO实验【使用VGG-16网络】
属性 数目 目标类别 80 Microsoft COCO训练集 80k Microsoft COCO验证集 40k Microsoft COCO测试集 20k 采用8-GPU并行训练,则RPN有效mini-batch 为8张图,Fast R-CNN有效mini-batch为16张图;
RPN和Fast R-CNN以0.003【由0.001改为0.003,由于有效mini-batch被改变了】的学习率迭代240k次,以0.0003的学习率迭代80k次;
对于anchors,在三种尺度三种长宽比基础上增加了64^2的尺度,这是为了处理Microsoft COCO数据集上的小目标【新数据集上不直接套用这一点值得学习】;
增加定义负样本IoU,重叠阈值由[0.1,0.5) 到[0,0.5),这能提升COOC数据集上mAP;
使用COCO训练集训练,COCO测试集上获得42.1%的mAP @0.5 和21.5%的mAP @[.5,.95]。6.与VGG-16相比,利用ResNet-101网络,在COCO验证集上mAP从41.5%/21.2%(@0.5/@[.5,.95])变化到48.4%/27.2%,归功于RPN网络可以从更好的特征提取网络中学到更好的区域建议。
7.由于Microsoft COCO数据集种类包含PASCAL VOC数据集种类,文中在Microsoft COCO数据集上训练,在PASCAL VOC数据集上测试,验证大数据量下训练是否有助于提高mAP?
采用VGG-16模型,当仅仅利用Microsoft COCO数据集训练时,PASCAL VOC 2007测试集上mAP达到76.1%【泛化能力强,未过拟合】;当利用Microsoft COCO数据集训练的模型初始化,PASCAL VOC 2007+2012训练集进行微调,PASCAL VOC 2007测试集上mAP达到78.8%,此时每一个单体类别的AP较其它样本训练的都达到最高,而每张图测试时间仍然约为200ms。
&还存在什么问题
采用VGG-16模型,可以达到5fps,这个速度并没有完全达到实时性,还有继续提升的空间,这将在YOLO模型中得以改进。
Faster R-CNN论文详解 - CSDN博客的更多相关文章
- Fast R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Fast R-CNN &创新点 规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取: 用RoI pooling层取代最后一层max ...
- R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Rich feature hierarchies for accurate object detection and semantic segmentatio ...
- python之configparser模块详解--小白博客
configparse模块 一.ConfigParser简介 ConfigParser 是用来读取配置文件的包.配置文件的格式如下:中括号“[ ]”内包含的为section.section 下面为类似 ...
- python之socket模块详解--小白博客
主要是创建一个服务端,在创建服务端的时候,主要步骤如下:创建socket对象socket——>绑定IP地址和端口bind——>监听listen——>得到请求accept——>接 ...
- python之subprocess模块详解--小白博客
subprocess模块 subprocess是Python 2.4中新增的一个模块,它允许你生成新的进程,连接到它们的 input/output/error 管道,并获取它们的返回(状态)码.这个模 ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- Python采集CSDN博客排行榜数据
文章目录 前言 网络爬虫 搜索引擎 爬虫应用 谨防违法 爬虫实战 网页分析 编写代码 运行效果 反爬技术 前言 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知 ...
- 2016年年终CSDN博客总结
2015年12月1日,结束了4个月的尚观嵌入式培训生涯,经过了几轮重重面试,最终来到了伟易达集团.经过了长达3个月的试用期,正式成为了伟易达集团的助理工程师. 回顾一年来的学习,工作,生活.各种酸甜苦 ...
- spider csdn博客和quantstart文章
spider csdn博客和quantstart文章 功能 提取csdn博客文章 提取quantstart.com 博客文章, Micheal Hall-Moore 创办的网站 特色功能就是: 想把原 ...
随机推荐
- 原生js版ajax请求
function getXMLHttpRequest() { var xhr; if(window.ActiveXObject) { xhr= new ActiveXObject("Micr ...
- NET Core 环境搭建和命令行CLI入门[转]
NET Core 环境搭建和命令行CLI入门 时间:2016-07-06 01:48:19 阅读:258 评论:0 收藏:0 [点我收藏+] 标签: N ...
- 学习 TList 类的实现[2]
我原来以为 TList 可能是一个链表, 其实只是一个数组而已. 你知道它包含着多大一个数组吗? MaxListSize 个!MaxListSize 是 Delphi 在 Classes 单元定义的一 ...
- 实操演练!MathType几个绝妙小技巧!
在论文中编写公式时MathType绝对是很多人不二的选择,它的功能比较完善,操作比较方便,包含的符号模板很多,易学易上手,这些都是它的优点.但是在使用MathType时,还有很多绝妙的小技巧,使用起来 ...
- mysql的引擎myisam和innodb的区别
1. MYISAM和INNODB的不同?答:主要有以下几点区别: a)构造上的区别 MyISAM在磁盘上存储成三个文件,其中.frm文件存储表定义:.MYD (MYData)为数据文件:. ...
- UIScrollView的用法,属性
iOS开发学习笔记-UIScrollView的用法 转载地址:http://www.jianshu.com/p/bcaf5cdfaa7e# UIScrollView是用来在屏幕上显示那些在有限区域内放 ...
- scala函数进阶篇
1.求值策略scala里有两种求值策略Call By Value -先对函数实参求值,在函数体中用这个求出的参数值.Call By Name -先不对函数实参求值,而是函数实参每次在函数体内被用到时都 ...
- 动易CMS漏洞收集
动易SiteWeaver6.8短消息0day跨站漏洞 user用户登陆,默认账号密码 admin/admin888 短消息代码模式下编辑,预览 <img src="../Skin/bl ...
- echo\awk\sed\tee\curl的使用-shell
echo的使用:http://man.linuxde.net/echo awk的使用:http://man.linuxde.net/awk sed的使用:http://man.linuxde.net/ ...
- Path类和File类的应用
今天是我学习C#基础的第13天,可以说马上就要结束这个基础课程,感觉学习的理论性的我不能说全部掌握了,我只想说在思路上面的语法以及用法我应该基本掌握了,感觉效果不错,不得不说,要想在一种语言上面有大的 ...