[转载]Huffman编码压缩算法
转自http://coolshell.cn/articles/7459.html
前两天发布那个rsync算法后,想看看数据压缩的算法,知道一个经典的压缩算法Huffman算法。相信大家应该听说过 David Huffman 和他的压缩算法—— Huffman Code,一种通过字符出现频率,Priority Queue,和二叉树来进行的一种压缩算法,这种二叉树又叫Huffman二叉树 —— 一种带权重的树。从学校毕业很长时间的我忘了这个算法,但是网上查了一下,中文社区内好像没有把这个算法说得很清楚的文章,尤其是树的构造,而正好看到一篇国外的文章《A Simple Example of Huffman Code on a String》,其中的例子浅显易懂,相当不错,我就转了过来。注意,我没有对此文完全翻译。
我们直接来看示例,如果我们需要来压缩下面的字符串:
“beep boop beer!”
首先,我们先计算出每个字符出现的次数,我们得到下面这样一张表 :
| 字符 | 次数 |
| ‘b’ | 3 |
| ‘e’ | 4 |
| ‘p’ | 2 |
| ‘ ‘ | 2 |
| ‘o’ | 2 |
| ‘r’ | 1 |
| ‘!’ | 1 |
然后,我把把这些东西放到Priority Queue中(用出现的次数据当 priority),我们可以看到,Priority Queue
是以Prioirry排序一个数组,如果Priority一样,会使用出现的次序排序:下面是我们得到的Priority Queue:

接下来就是我们的算法——把这个Priority Queue
转成二叉树。我们始终从queue的头取两个元素来构造一个二叉树(第一个元素是左结点,第二个是右结点),并把这两个元素的priority相加,并放
回Priority中(再次注意,这里的Priority就是字符出现的次数),然后,我们得到下面的数据图表:
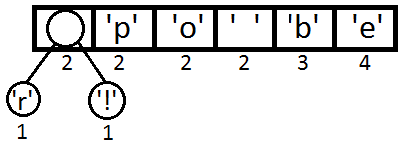
同样,我们再把前两个取出来,形成一个Priority为2+2=4的结点,然后再放回Priority Queue中 :
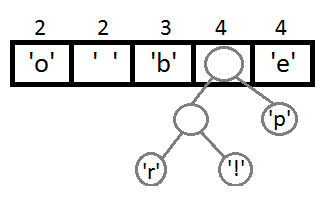
继续我们的算法(我们可以看到,这是一种自底向上的建树的过程):


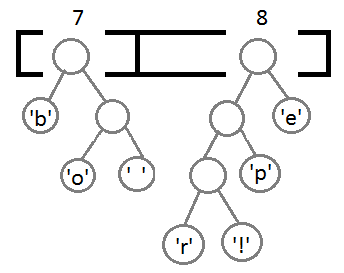
最终我们会得到下面这样一棵二叉树:
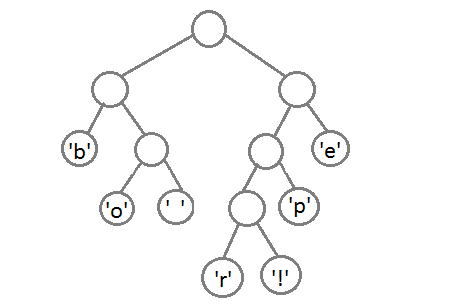
此时,我们把这个树的左支编码为0,右支编码为1,这样我们就可以遍历这棵树得到字符的编码,比如:‘b’的编码是 00,’p'的编码是101, ‘r’的编码是1000。我们可以看到出现频率越多的会越在上层,编码也越短,出现频率越少的就越在下层,编码也越长。
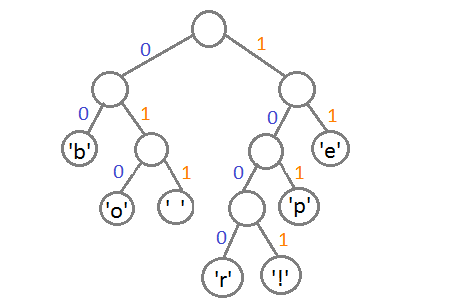
最终我们可以得到下面这张编码表:
| 字符 | 编码 |
| ‘b’ | 00 |
| ‘e’ | 11 |
| ‘p’ | 101 |
| ‘ ‘ | 011 |
| ‘o’ | 010 |
| ‘r’ | 1000 |
| ‘!’ | 1001 |
这里需要注意一点,当我们encode的时候,我们是按“bit”来encode,decode也是通过bit来完成,比如,如果我们有这样的
bitset “1011110111″ 那么其解码后就是 “pepe”。所以,我们需要通过这个二叉树建立我们Huffman编码和解码的字典表。
这里需要注意的一点是,我们的Huffman对各个字符的编码是不会冲突的,也就是说,不会存在某一个编码是另一个编码的前缀,不然的话就会大问题了。因为encode后的编码是没有分隔符的。
于是,对于我们的原始字符串 beep boop beer!
其对就能的二进制为 : 0110 0010
0110 0101 0110 0101 0111 0000 0010 0000 0110 0010 0110 1111 0110 1111
0111 0000 0010 0000 0110 0010 0110 0101 0110 0101 0111 0010 0010 0001
我们的Huffman的编码为: 0011 1110 1011 0001 0010 1010 1100 1111 1000 1001
从上面的例子中,我们可以看到被压缩的比例还是很可观的。
作者给出了源码你可以看看( C99标准) Download the source files
[转载]Huffman编码压缩算法的更多相关文章
- Huffman 编码压缩算法
前两天发布那个rsync算法后,想看看数据压缩的算法,知道一个经典的压缩算法Huffman算法.相信大家应该听说过 David Huffman 和他的压缩算法—— Huffman Code,一种通过字 ...
- huffman编码压缩算法(转)
参考:http://blog.csdn.net/sunmenggmail/article/details/7598012 笔试时遇到的一道题.
- huffman 编码
huffman压缩是一种压缩算法,其中经典的部分就是根据字符出现的频率建立huffman树,然后根据huffman树的构建结果标示每个字符.huffman编码也称为前缀编码,就是每个字符的表示形式不是 ...
- Huffman编码实现压缩解压缩
这是我们的课程中布置的作业.找一些资料将作业完毕,顺便将其写到博客,以后看起来也方便. 原理介绍 什么是Huffman压缩 Huffman( 哈夫曼 ) 算法在上世纪五十年代初提出来了,它是一种无损压 ...
- [老文章搬家] 关于 Huffman 编码
按:去年接手一个项目,涉及到一个一个叫做Mxpeg的非主流视频编码格式,编解码器是厂商以源代码形式提供的,但是可能代码写的不算健壮,以至于我们tcp直连设备很正常,但是经过一个UDP数据分发服务器之后 ...
- Huffman编码
#define _CRT_SECURE_NO_WARNINGS #include <iostream> #include <cstdio> #include <cstri ...
- 【数据压缩】Huffman编码
1. 压缩编码概述 数据压缩在日常生活极为常见,平常所用到jpg.mp3均采用数据压缩(采用Huffman编码)以减少占用空间.编码\(C\)是指从字符空间\(A\)到码字表\(X\)的映射.数据压缩 ...
- 优先队列求解Huffman编码 c++
优先队列小析 优先队列的模板: template <class T, class Container = vector<T>,class Compare = less< ...
- Huffman编码实现电文的转码与译码
//first thing:thanks to my teacher---chenrong Dalian Maritime university /* 构造Huffman Tree思路: ( ...
随机推荐
- AJAX.basic
之前在项目中使用ajax都是通过jQuery的Ajax API来进行的,今天试了一下通过基本的JavaScript来进行ajax请求,将代码记录下来: jsp 页面 <%@ page pageE ...
- scrapy爬虫系列之三--爬取图片保存到本地
功能点:如何爬取图片,并保存到本地 爬取网站:斗鱼主播 完整代码:https://files.cnblogs.com/files/bookwed/Douyu.zip 主要代码: douyu.py im ...
- CRM - 讲师与学生
一.讲师与学生简介 1.初始化 course_record, study_record.2.学习记录3.录入成绩4.显示成绩 ajax 查询 柱状图展示成绩 highcharts 5.上传作业(os模 ...
- mysql 数据操作 单表查询 练习
查出所有员工的名字,薪资,格式为 <名字:egon>,<薪资:3000> mysql> select concat('<姓名:',name,'>') as n ...
- MySQL新加用户和开启慢查询
mysql>grant select on *.* to read@'%' identified by 'j'; //给予read用户只读全部库的权限 mysql>grant selec ...
- git-【一】概述安装
一:Git是什么? Git是目前世界上最先进的分布式版本控制系统. 二:SVN与Git的最主要的区别? SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以 ...
- Java Thread 如何处理未捕获的异常?
Java Thread是不允许异常抛出到本线程之外的,Runnable接口的public abstract void run()是不允许throws Exception的,这在编译时就通不过. 线程异 ...
- log4j2配置日志大小,个数等
1:设置log输出文件 https://www.cnblogs.com/sa-dan/p/6837225.html <?xml version="1.0" encoding= ...
- mydumper原理介绍
mydumper的安装:http://www.cnblogs.com/lizhi221/p/7010174.html mydumper介绍 MySQL自身的mysqldump工具支持单线程 ...
- Python笔记 #04# Methods
源:DataCamp datacamp 的 DAILY PRACTICE + 日常收集. Methods String Methods List Methods 缺一 Methods You can ...