hive grouping sets 等聚合函数
函数说明:
grouping sets
在一个 group by 查询中,根据不同的维度组合进行聚合,等价于将不同维度的 group by 结果集进行 union all
cube
根据 group by 的维度的所有组合进行聚合
rollup
是 cube 的子集,以最左侧的维度为主,从该维度进行层级聚合。
-- grouping sets
select
order_id,
departure_date,
count(*) as cnt
from ord_test
where order_id=410341346
group by order_id,
departure_date
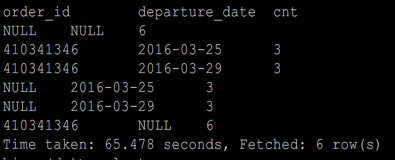
grouping sets (order_id,(order_id,departure_date))
; ---- 等价于以下
group by order_id
union all
group by order_id,departure_date -- cube
select
order_id,
departure_date,
count(*) as cnt
from ord_test
where order_id=410341346
group by order_id,
departure_date
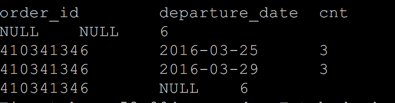
with cube
; ---- 等价于以下
select count(*) as cnt from ord_test where order_id=410341346
union all
group by order_id
union all
group by departure_date
union all
group by order_id,departure_date -- rollup
select
order_id,
departure_date,
count(*) as cnt
from ord_test
where order_id=410341346
group by order_id,
departure_date
with rollup
; ---- 等价于以下
select count(*) as cnt from ord_test where order_id=410341346
union all
group by order_id
union all
group by order_id,departure_date
结果:grouping_sets, cube, rollup

hive grouping sets 等聚合函数的更多相关文章
- hive grouping sets 实现原理
先下结论: 看了hive 1.1.0 grouping sets 实现(从源码及执行计划都可以看出与kylin实现不一样),(前提是可累加,如sum函数)他并没有像kylin一样先按照group by ...
- 9.hive聚合函数,高级聚合,采样数据
本文主要使用实例对Hive内建的一些聚合函数.分析函数以及采样函数进行比较详细的讲解. 一.基本聚合函数 数据聚合是按照特定条件将数据整合并表达出来,以总结出更多的组信息.Hive包含内建的一些基本聚 ...
- 解析数仓OLAP函数:ROLLUP、CUBE、GROUPING SETS
摘要:GaussDB(DWS) ROLLUP,CUBE,GROUPING SETS等OLAP函数的原理解析. 本文分享自华为云社区<GaussDB(DWS) OLAP函数浅析>,作者: D ...
- Hive学习之自己定义聚合函数
Hive支持用户自己定义聚合函数(UDAF),这样的类型的函数提供了更加强大的数据处理功能. Hive支持两种类型的UDAF:简单型和通用型.正如名称所暗示的,简单型UDAF的实现很easy,但因为使 ...
- SQL Server里Grouping Sets的威力
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- SQL Server里Grouping Sets的威力【转】
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- Hive高阶聚合函数 GROUPING SETS、Cube、Rollup
-- GROUPING SETS作为GROUP BY的子句,允许开发人员在GROUP BY语句后面指定多个统计选项,可以简单理解为多条group by语句通过union all把查询结果聚合起来结合起 ...
- Hive高级聚合GROUPING SETS,ROLLUP以及CUBE
scala> import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.hive.HiveContext s ...
- Hive函数:GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
参考:lxw大数据田地:http://lxw1234.com/archives/2015/04/193.htm 数据准备: CREATE EXTERNAL TABLE test_data ( mont ...
随机推荐
- Fiddler关闭自动更新
1,fiddler 启动时老弹出要更新,但不想更新,可以这样设置 Tools-Optons->General 把第一个√去掉
- js 的正则表达式 部分展示test()方法的验证功能
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- input输入框制定输入数据类型匹配
<input type="text" id="price_169" value="97" style="max-width: ...
- Code Forces 652D Nested Segments(离散化+树状数组)
Nested Segments time limit per test 2 seconds memory limit per test 256 megabytes input standard in ...
- JavaCollection Java 集合框架
Spring Injecting Collection https://www.tutorialspoint.com/spring/spring_injecting_collection.htm No ...
- sailsjs入门到精通(一)
sailsjs 官方网站http://sailsjs.com/ 中文网站: http://sailsdoc.swift.ren/ 1 全局安装sails npm install sails@bet ...
- centos 配置mysql
1.在线安装 1.首先检测一下,mysql之前有没有被安装 命令:rpm -qa | grep mysql 2.删除mysql的命令: rpm -e --nodeps `rpm -qa | grep ...
- python 面向对象· self 讲解
self就是参数 以形参形式 5.self是什么鬼? self是一个python自动会给传值的参数 那个对象执行方法,self就是谁. obj1.fetch('selec...') self=obj1 ...
- Flask系列之源码分析(一)
目录: 涉及知识点 Flask框架原理 简单示例 路由系统原理源码分析 请求流程简单源码分析 响应流程简单源码分析 session简单源码分析 涉及知识点 1.装饰器 闭包思想 def wapper( ...
- Openstack(十)部署nova服务(计算节点)
在计算节点安装 10.1安装nova计算服务 # 阿里云源详见2.3配置 # yum install openstack-nova-compute 10.2配置nova计算服务 10.2.1配置nov ...