Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面
摘要:介绍了使用Scrapy处理JSON API和AJAX页面的方法
有时候,你会发现你要爬取的页面并不存在HTML源码,譬如,在浏览器打开http://localhost:9312/static/,然后右击空白处,选择“查看网页源代码”,如下所示:
就会发现一片空白

留意到红线处指定了一个名为api.json的文件,于是打开浏览器的调试器中的Network面板,找到名为api.json的标签
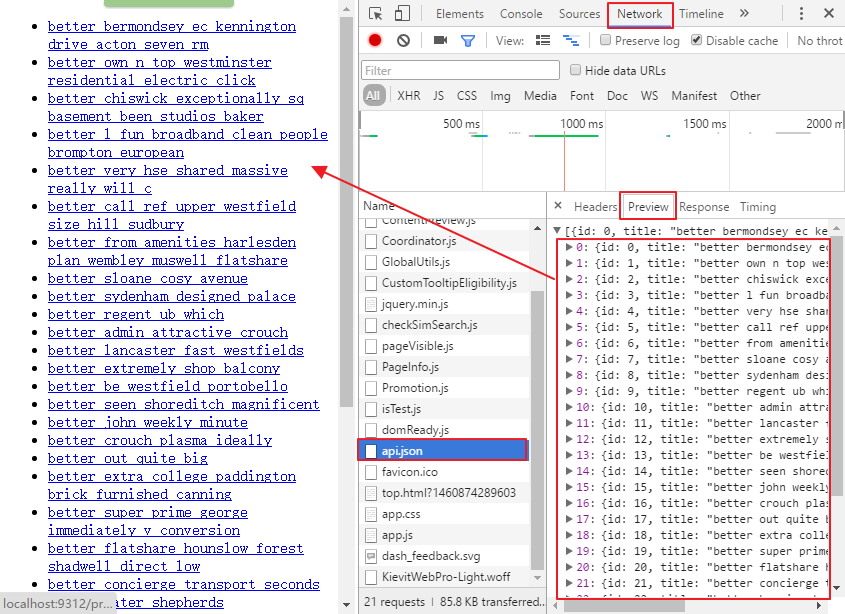
在上图的红色框里就找到了原网页中的内容,这是一个简单的JSON API,有些复杂的API会要求你先登录,发送POST请求,或者返回一些更加有趣的数据结构。Python提供了一个用于解析JSON的库,可以通过语句json.loads(response.body)将JSON数据转变成Python对象
api.py文件的源代码地址:
https://github.com/Kylinlin/scrapybook/blob/master/ch05%2Fproperties%2Fproperties%2Fspiders%2Fapi.py
复制manual.py文件,重命名为api.py,做以下改动:
将spider名修改为api
将start_urls修改为JSON API的URL,如下
start_urls = (
'http://web:9312/properties/api.json',
)
如果在获取这个json的api之前,需要登录,就使用start_request()函数(参考《Learning Scrapy笔记(五)- Scrapy登录网站》)
- 修改parse函数
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_%06d.html" % id # 构建一个每个条目的完整url
yield Request(url, callback=self.parse_item)
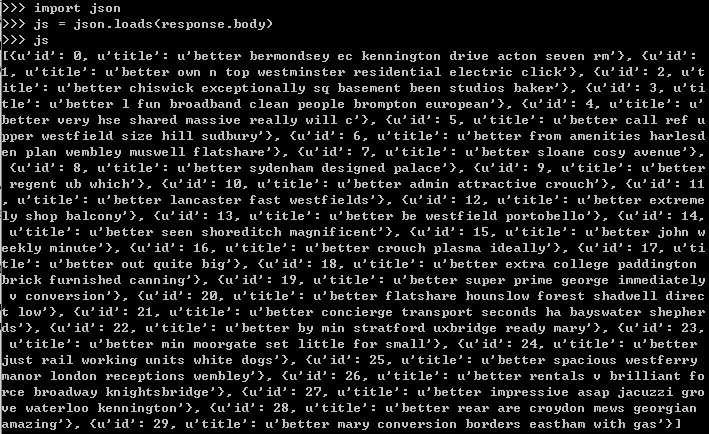
上面的js变量是一个列表,每个元素都代表了一个条目,可以使用scrapy shell工具来验证:
scrapy shell http://web:9312/properties/api.json
运行该spider:scrapy crawl api
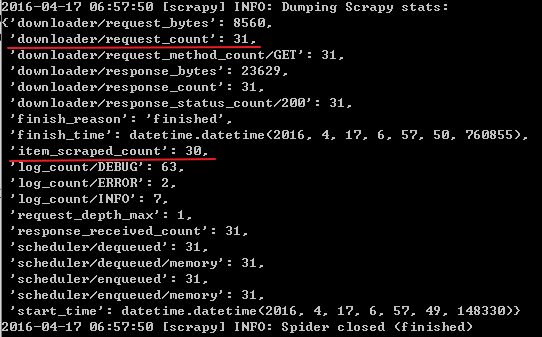
可以看到总共发送了31个request,获取了30个item
再观察上图中使用scrapy shell工具检查js变量的图,其实除了id字段外,还可以获取title字段,所以可以在parse函数中同时获取title字段,并将该字段的值传送到parse_item函数中填充到item里(省去了在parse_item函数中使用xpath来提取title的步骤),修改parse函数如下:
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item) #meta变量是一个字典,用于向回调函数传递数据
在parse_item函数中,可以在response中提取这个字段
l.add_value('title', response.meta['title'],
MapCompose(unicode.strip, unicode.title))
Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面的更多相关文章
- Gin-Go学习笔记六:Gin-Web框架 Api的编写
Api编写 1> Gin框架的Api返回的数据格式有json,xml,yaml这三种格式.其中yaml这种格式是一种特殊的数据格式.(本人暂时没有实现获取节点值得操作) 2> ...
- Scrapy基础(六)————Scrapy爬取伯乐在线一通过css和xpath解析文章字段
上次我们介绍了scrapy的安装和加入debug的main文件,这次重要介绍创建的爬虫的基本爬取有用信息 通过命令(这篇博文)创建了jobbole这个爬虫,并且生成了jobbole.py这个文件,又写 ...
- 钉钉开发笔记(六)使用Google浏览器做真机页面调试
注: 参考文献:https://developers.google.com/web/ 部分字段为翻译文献,水平有限,如有错误敬请指正 步骤1: 从Windows,Mac或Linux计算机远程调试And ...
- Learning Scrapy笔记(零) - 前言
我已经使用了scrapy有半年之多,但是却一直都感觉没有入门,网上关于scrapy的文章简直少得可怜,而官网上的文档(http://doc.scrapy.org/en/1.0/index.html)对 ...
- Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分 Scrapy的爬取流程 Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示 URL:Scrapy的运行就从那个你想要 ...
- scrapy笔记集合
细读http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 目录 Scrapy介绍 安装 基本命令 项目结构以及爬虫应用介绍 简单使用示例 选 ...
- Scrapy 笔记(二)
一个scrapy爬虫知乎项目的笔记 1.通过命令创建项目 scrapy startproject zhihucd zhihuscrapy genspider zhihu www.zhihu.com(临 ...
- 转 Scrapy笔记(5)- Item详解
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API,并且可以很方便的声明字段,很多Scra ...
- Scrapy笔记(1)- 入门篇
Scrapy笔记01- 入门篇 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说, ...
随机推荐
- fw: firefox plugin
http://blog.csdn.net/fancycow/article/details/7261191 firefox的插件分两种类型,一种extension,叫扩展,一种是plugin,我们叫插 ...
- 内网安装ubuntu包
到http://packages.ubuntu.com搜索包下载下来, 再安装.
- SQL server 2016 安装步骤
1.进入安装中心:可以参考硬件和软件要求.可以看到一些说明文档 2.选择全新安装模式继续安装 3.输入产品秘钥:这里使用演示秘钥进行 4.在协议中,点击同意,并点击下一步按钮,继续安装 5.进入全局规 ...
- DAY13 Matlab实现图像错切源代码
Matlab实现图像错切源代码 %错切im=(imread('robot.jpg'));im1=rgb2gray(im);figure,imshow(im1);[row,col]=size(im1); ...
- MySQL 密码修改
方法1: 用SET PASSWORD命令 首先登录MySQL. 格式:mysql> set password for 用户名@localhost = password('新密码'); 例子:my ...
- ceph--磁盘和rbd、rados性能测试工具和方法
我在物理机上创建了5台虚拟机,搭建了一个ceph集群,结构如图: 具体的安装步骤参考文档:http://docs.ceph.org.cn/start/ http://www.centoscn.com/ ...
- MySQL(二)
一.外键 外键是设置当前表中的某一列与别一数据表中的主键列关联.主要目的是控制与外键表中的数据,保持数据一致性,完整性,也就是说:当前表中这一列的数据必须是关联外键列中的某一数据,而且相关联的两个数据 ...
- BFPRT(线性查找算法)
BFPRT算法解决的问题十分经典,即从某n个元素的序列中选出第k大(第k小)的元素,通过巧妙的分 析,BFPRT可以保证在最坏情况下仍为线性时间复杂度.该算法的思想与快速排序思想相似,当然,为使得算法 ...
- (转)Java基础——嵌套类、内部类、匿名类
本文内容分转自博客:http://www.cnblogs.com/mengdd/archive/2013/02/08/2909307.html 将相关的类组织在一起,从而降低了命名空间的混乱. 一个内 ...
- phonegap ios默认启动页
phonegap创建的项目默认的启动界面是phonegap的图标,想去掉这个图标,有两个方法,第一就是将resourece下面的splash文件下面的图片改成自己想要的启动页面,名字要相同,替换掉它默 ...