15. 序列化模块json和pickle、os模块
1. 序列化模块
1.1 序列化与反序列化
(1)序列化
将原本的python数据类型字典、列表、元组 转换成json格式字符串的过程就叫序列化
(2)反序列化
将json格式字符串转换成python数据类型字典、列表、元组的过程就叫反序列化
(3)为什么要序列化
计算机文件中没有字典这种数据类型,将字典中的数据转换成字符串形式的数据就称为序列化
1.2 json模块
json格式的数据在几种不同的语言中是一个通用的数据格式
(1)将python数据转换成json格式的字符串
import json
a = {'name': 'messi', 'age': 37, 'club': 'miami', 'address': 'usa'} # 将python数据转换为json字符串
b = json.dumps(a)
print(b, type(b)) # {"name": "messi", "age": 37, "club": "miami", "address": "usa"} <class 'str'> # 将json字符串转换为python数据
c = json.loads(b)
print(c, type(c)) # {'name': 'messi', 'age': 37, 'club': 'miami', 'address': 'usa'} <class 'dict'> # 将json字符串进行二进制编码,符合json格式的二进制数据也能转换为python数据
d = b.encode()
print(d, type(d)) # b'{"name": "messi", "age": 37, "club": "miami", "address": "usa"}' <class 'bytes'>
e = json.loads(d)
print(e, type(e)) # {'name': 'messi', 'age': 37, 'club': 'miami', 'address': 'usa'} <class 'dict'>
(2)json模块处理文件
import json
a = {'name': 'messi', 'age': 37, 'club': 'miami', 'address': 'usa'}
# 将python数据写入到json文件中
# 字典格式的单引号变成了双引号
with open('new.json', 'w', encoding='utf-8') as f:
json.dump(a, f, ensure_ascii=False)
# {"name": "messi", "age": 37, "club": "miami", "address": "usa"} # 将json文件的数据转换成python数据
# json格式字典双引号变成了单引号
with open('new.json', 'r', encoding='utf-8') as f2:
data = json.load(f2)
print(data, type(data)) # {'name': 'messi', 'age': 37, 'club': 'miami', 'address': 'usa'} <class 'dict'>
python中的列表存到json中还是列表,python中的元组存到json中也成了列表
(3)python数据与json数据互转
from json.encoder import JSONEncoder
from json.decoder import JSONDecodeError '''
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
'''
# 将 Python中的 字典 转换为JSON格式的字典
# 将 Python中的 元组和列表 转换为 JSON格式的列表
# 将 Python中的 字符串 转换为 JSON格式的字符串
# 将 Python中的 布尔值 True / False 转换为 JSON格式的 true / false
# 将 Python中的 None 转换为 JSON格式的 null
# 将 Python中的 整数 转换为 JSON格式的数字
(4)json参数补充
# json模块默认的编码格式是ASCII码
# 写数据的时候再在open参数中指定utf-8是不生效的
import json
a = {'name': 'messi', 'club': '迈阿密', 'num': '001'}
with open('new.json', mode='w', encoding='utf-8') as f1:
json.dump(a, f1)
# {"name": "messi", "club": "\u8fc8\u963f\u5bc6", "num": "001"} # 于是就要对dump参数进行调整
with open('new.json', mode='w', encoding='utf-8') as f2:
json.dump(a, f2, ensure_ascii=False)
# ensure_ascii=True : 是否启用默认的编码格式 如果是 True 则默认使用 ASCII 码格式,如果是 False 则使用 Unicode 格式
# {"name": "messi", "club": "迈阿密", "num": "001"}
1.3 pickle模块
pickle模块和json模块都是用来序列化和反序列化python数据的
json处理不了python中的函数和类,于是有了pickle
pickle格式是一种用于序列化和反序列化Python对象的二进制格式。
(1)将python数据转换成二进制数据
import pickle
def add(x, y):
return x + y a = pickle.dumps(obj=add)
print(a, type(a))
# b'\x80\x04\x95\x14\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x03add\x94\x93\x94.' <class 'bytes'> b = pickle.loads(a)
print(b, type(b))
# 得到一个内存地址,为函数类型
# <function add at 0x000001F7ABBE3370> <class 'function'>
(2)将python数据转换成二进制数据并写入文件
import pickle
def add(x, y):
print(x + y) # 生成的aaa文件不可打开,但是可调用
with open('aaa', 'wb') as f1: # 由于pickle是将python数据序列化为二进制,因此写模式为wb
pickle.dump(add, f1) with open('aaa', 'rb') as f2:
new_add = pickle.load(f2)
print(new_add, type(new_add))
# <function add at 0x000001D099E83370> <class 'function'>
# pickle先将函数名转换成二进制写到文件中,后将文件中二进制数据转换为函数名
new_add(11, 22) # 33 转回的函数仍旧可调用
2. os模块
os模块用于与操作系统交互
2.1 os.path.*
import os
import datetime # (1)os.path.abspath 获取当前文件的绝对路径
print(os.path.abspath(__file__)) # D:\project\pythonProject\day14_部分模块\test.py # (2)os.path.dirname 获取当前文件所在文件夹的绝对路径
print(os.path.dirname(__file__)) # D:\project\pythonProject\day14_部分模块 # (3)os.path.exists 判断文件夹是否存在
a = 'D:\project\pythonProject\day14_部分模块'
print(os.path.exists(a)) # True
b = 'D:\project\pythonProject\day14_usual'
print(os.path.exists(b)) # False # (4)os.path.join 拼接文件路径
c = os.path.join('D:\project\pythonProject\day14_部分模块', 'giao')
print(c) # D:\project\pythonProject\day14_部分模块\giao
print(os.path.exists(c)) # False # (5)os.path.split 将路径分隔为最后一级和上一级并以二元元组返回
d = os.path.split('D:\project\pythonProject\day14_部分模块\\test.py') # 加一个反斜杠取消转义
print(d) # ('D:\\project\\pythonProject\\day14_部分模块', 'test.py')
e = os.path.split('D:\project\pythonProject\day14_部分模块')
print(e) # ('D:\\project\\pythonProject', 'day14_部分模块') # (6)os.path.basename 获取最后一级文件名/目录名
f = os.path.basename('D:\project\pythonProject\day14_部分模块\\test.py')
print(f) # test.py
g = os.path.basename('D:\project\pythonProject\day14_部分模块')
print(g) # day14_部分模块 # (7)os.path.isfile 判断当前路径是否为文件
h = os.path.isfile('D:\project\pythonProject\day14_部分模块\\test.py')
print(h) # True
i = os.path.isfile('D:\project\pythonProject\day14_部分模块')
print(i) # False # (8)os.path.isabs 判断是否为绝对路径
j = '.\\test.py'
print(os.path.isabs(j)) # False
print(os.path.isabs('D:\project\pythonProject\day14_部分模块\\test.py')) # True # (9)os.path.isdir 判断是否为目录
print(os.path.isdir('D:\project\pythonProject\day14_部分模块\\test.py'))
# False
print(os.path.isdir('D:\project\pythonProject\day14_部分模块'))
# True # (10)os.path.getatime 获取当前文件或目录的最后访问时间atime---access time
k = os.path.getatime('D:\project\pythonProject\day14_部分模块\\test.py')
print(k) # 1722512134.9196131
print(datetime.datetime.fromtimestamp(k)) # 2024-08-01 19:35:34.919613 # (11)os.path.getctime 获取当前文件或目录的创建时间ctime---create time
l = os.path.getctime('D:\project')
print(l) # 1721123236.0086133
print(datetime.datetime.fromtimestamp(l)) # 2024-07-16 17:47:16.008613 # (12)os.path.getmtime 获取当前文件或目录的修改时间mtime---modifytime
m = os.path.getmtime('D:\project\pythonProject')
print(m) # 1722504598.081404
print(datetime.datetime.fromtimestamp(m)) # 2024-08-01 17:29:58.081404 # (13)os.path.getsize 获取当前文件或目录的大小,单位为byte
print(os.path.getsize('D:\project\pythonProject\day14_部分模块\\test.py')) # 2975 # (14)os.path.sep 获取系统对应的路径分隔符 MacOs、Linux: / Windows: \
print(os.path.sep) # \
2.2 路径操作 os.*
(1)创建单级文件夹
import os CURRENT_DIR = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在的目录
print(CURRENT_DIR) # D:\project\pythonProject\day14_部分模块
# (1)创建单级文件夹
new_dir = os.path.join(CURRENT_DIR, 'giao') # 只是拼接了并没有创建
print(new_dir) # D:\project\pythonProject\day14_部分模块\giao
print(os.path.exists(new_dir)) # False os.mkdir(new_dir) # 真正生成了新的文件夹
print(os.path.exists(new_dir)) # True
(2)创建多级文件夹
import os CURRENT_DIR = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在的目录
new_dir = os.path.join(CURRENT_DIR, 'giu', 'giao') # 在当前文件所在目录再往下拼接两级目录
print(new_dir) # D:\project\pythonProject\day14_部分模块\giu\giao
print(os.path.exists(new_dir)) # False os.makedirs(new_dir) # 创建拼接好的两个目录
print(os.path.exists(new_dir)) # True
import os CURRENT_DIR = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在的目录
new_dir = os.path.join(CURRENT_DIR, 'giu', 'giao') # 在当前文件所在目录再往下拼接两级目录
print(new_dir) # D:\project\pythonProject\day14_部分模块\giu\giao
print(os.path.exists(new_dir)) # False os.makedirs(new_dir, exist_ok=True)
# exist_ok=True 自动判断当前文件路径是否存在,如果不存在则主动创建,如果存在则忽略
(3)删除单级文件夹
import os CURRENT_DIR = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在的目录
new_dir = os.path.join(CURRENT_DIR, 'giu', 'giao') # 在当前文件所在目录再往下拼接两级目录
os.makedirs(new_dir, exist_ok=True)
print(new_dir) # D:\project\pythonProject\day14_部分模块\giu\giao # os.rmdir 只能删除单级文件夹且单级文件夹为空
os.rmdir(new_dir) # D:\project\pythonProject\day14_部分模块\giu
print(os.path.exists(new_dir)) # False os.rmdir('D:\project\pythonProject\day13_模块与包') # OSError: [WinError 145] 目录不是空的。
(4)删除多级文件夹
import os CURRENT_DIR = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在的目录
new_dir = os.path.join(CURRENT_DIR, 'giu', 'giao') # 在当前文件所在目录再往下拼接两级目录
os.makedirs(new_dir, exist_ok=True)
print(new_dir) # D:\project\pythonProject\day14_部分模块\giu\giao # os.removedirs 若目录为空,则删除,并递归到上一级目录,若也为空,则删除,以此类推
os.removedirs(new_dir) # D:\project\pythonProject\day14_部分模块
(5)列出当前目录下的所有文件名
import os # listdir的用法
print(os.path.dirname(os.path.abspath(__file__))) # 获取当前文件所在目录
print(os.listdir(os.path.dirname(os.path.abspath(__file__)))) # ['new.json', 'task.py', 'test.py']
(6)重命名当前文件或目录
rename的用法
重命名目录
import os CURRENT_DIR = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在的目录
new_name = os.path.join(CURRENT_DIR, 'giao') # 在当前文件所在目录再拼接一个目录
os.makedirs(new_name, exist_ok=True)
print(new_name) # D:\project\pythonProject\day14_部分模块\giao new_name2 = os.path.join(CURRENT_DIR, 'giu') # 拼接一个新的名称
print(new_name2) # D:\project\pythonProject\day14_部分模块\giu
os.rename(new_name, new_name2) # 用最新的替换原来的
重命名文件名
import os CURRENT_FILE = os.path.abspath(__file__) # 获取当前文件绝对路径
print(CURRENT_FILE) # D:\project\pythonProject\day14_部分模块\task.py CURRENT_DIR = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在的目录
new_filename = os.path.join(CURRENT_DIR, 'workon.py') # 拼接一个新的文件名称
print(new_filename) # D:\project\pythonProject\day14_部分模块\workon.py
os.rename(CURRENT_FILE, new_filename) # 用新的名称替换原来的
(7)删除指定文件
os.remove的用法

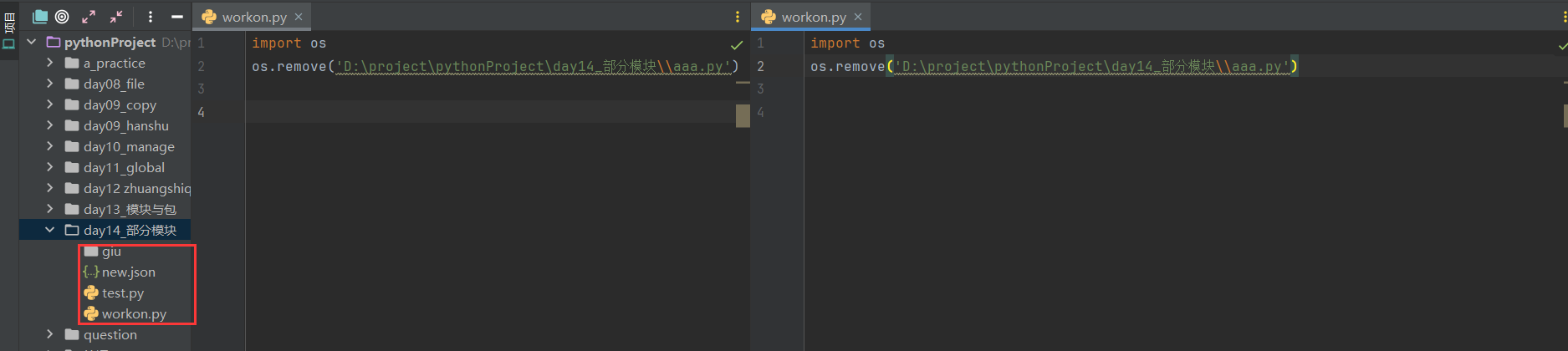
(8)列出当前文件的元信息
import os print(os.stat(os.path.abspath(__file__)))
# st_mode: inode 保护模式
# st_ino: inode 节点号。
# st_dev: inode 驻留的设备。
# st_nlink: inode 的链接数。
# st_uid: 所有者的用户ID。
# st_gid: 所有者的组ID。
# st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
# st_atime: 上次访问的时间。
# st_mtime: 最后一次修改的时间。
# st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间
(9)获取当前所在的工作目录
import os print(os.getcwd()) # D:\project\pythonProject\day14_部分模块
(10)切换工作目录
import os print(os.getcwd()) # 当前路径 D:\project\pythonProject\day14_部分模块
os.chdir('D:\project\pythonProject\day13_模块与包') # 切换路径
print(os.getcwd()) # D:\project\pythonProject\day13_模块与包
(11)执行shell命令
操作系统不同则命令名称也不同
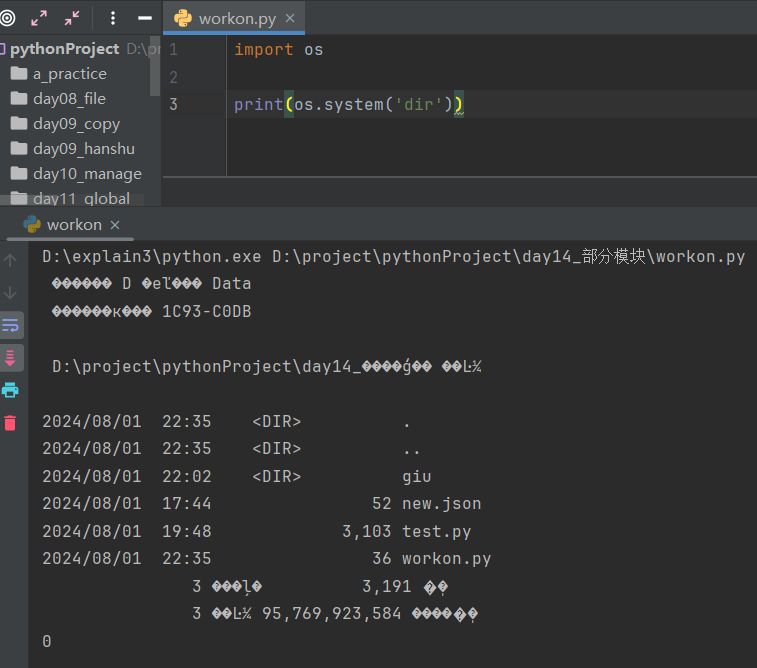
(12)执行命令获取结果
import os
res = os.system('dir')
print(res)
2.3 os模块操作补充
# (1)获取操作系统的路径分隔符
import os print(os.sep) # \
print(os.path.sep) # \
# (2)获取操作系统的行终止符
import os print(os.linesep) # \r\n
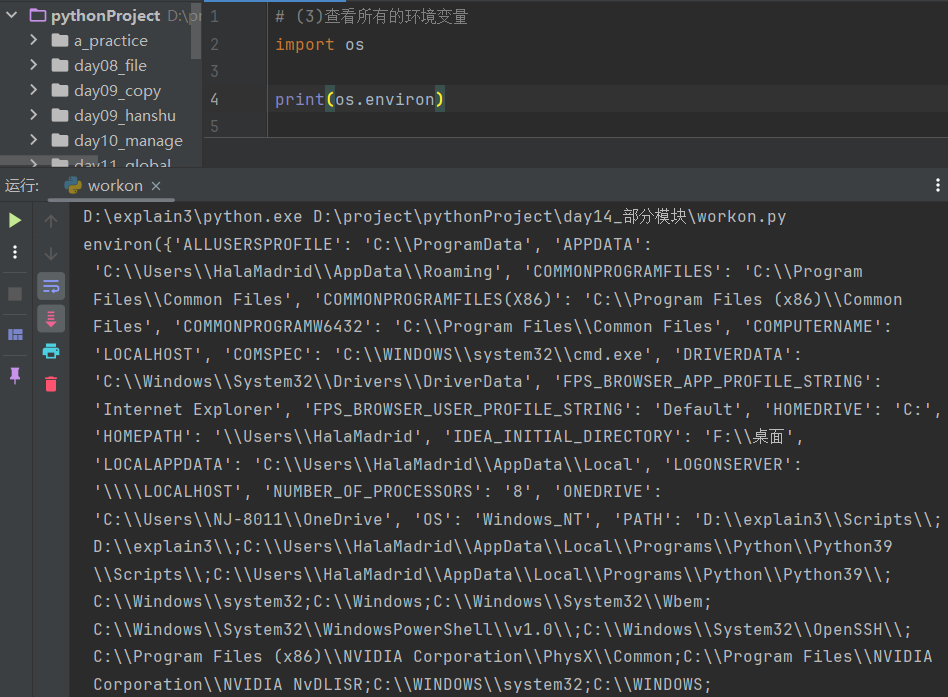
# (4)查看操作系统的标识
import os print(os.name) # nt
15. 序列化模块json和pickle、os模块的更多相关文章
- collections queue、os、datetime,序列化(json和pickle)模块
目录 Collections 模块 1.nametuple 2.deque(双端队列) 3.双端队列(deque): 4.Odereddict(有序字典): 5.Defaultdict(默认字典,首字 ...
- json、pickle\shelve模块(超级好用~!)讲解
json.pickle模块讲解 见我前面的文章:http://www.cnblogs.com/itfat/p/7456054.html shelve模块讲解(超级好用~!) json和pickle的模 ...
- 【转】Python之数据序列化(json、pickle、shelve)
[转]Python之数据序列化(json.pickle.shelve) 本节内容 前言 json模块 pickle模块 shelve模块 总结 一.前言 1. 现实需求 每种编程语言都有各自的数据类型 ...
- 常用模块一(os模块、序列化模块(json和pickle))
一.os模块 os模块是与操作系统交互的一个接口. import os # 和文件和文件夹的操作有关 os.makedirs('dirname1/dirname2') # 可生成多层递归目录 os.r ...
- 2019-7-18 collections,time,random,os,sys,序列化模块(json和pickle)应用
一.collections模块 1.具名元组:namedtuple(生成可以使用名字来访问元素的tuple) 表示坐标点x为1 y为2的坐标 注意:第二个参数可以传可迭代对象,也可以传字符串,但是字 ...
- Python 入门基础14 --time、os、random、json、pickle 常用模块1
今日内容: 一.常用模块 2019.04.10 更新 1.time:时间 2.calendar:日历 3.datetime:可以运算的时间 4.sys:系统 5.os:操作系统 6.os.path:系 ...
- python序列化模块json和pickle
序列化相关 1. json 应用场景: json模块主要用于处理json格式的数据,可以将json格式的数据转化为python的字典,便于python处理,同时也可以将python的字典或列表等对象转 ...
- python中序列化模块json和pickle
json模块:json是第三方包,不是系统内置模块,以字符串序列 常用操作有: json.dumps() # 将变量序列化,即将功能性字符转化为字符串 例: >>> import j ...
- python常见模块之序列化(json与pickle以及shelve)
什么是序列化? 我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flatte ...
- 序列化的两个模块(json和pickle)
到底什么是序列化(picking)呢? 我们把变量从内存中变成可存储或传输的过程称之为序列化 序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上. 反过来,把变量内容从序列化的对 ...
随机推荐
- 【干货】流量录制回放工具:jvm-sandbox-repeater
在软件开发和测试过程中,我们经常会遇到需要对网络请求进行录制和回放的需求,以便进行调试.测试和分析.为了模拟真实的用户请求,我们通常会使用各种流量录制回放工具来记录并重放网络请求. 其中,jvm-sa ...
- P9058 [Ynoi2004] rpmtdq 与 P9678 [ICPC2022 Jinan R] Tree Distance
思路: 注意到点对数量有 \(N^2\) 个,考虑丢掉一些无用的点对. 对于点对 \((x_1,y_1),(x_2,y_2)\),满足 \(x_1 \le x_2 < y_2 \le y_1\) ...
- 我用Awesome-Graphs看论文:解读PowerGraph
PowerGraph论文:<PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs> 上次通过文章< ...
- OpenCV计算机视觉学习(16)——仿射变换学习笔记
如果需要其他图像处理的文章及代码,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractic ...
- PVE linux_VM 扩容分区
页面 调整磁盘大小 手动分区 fdisk -l fdisk /dev/sda 对该磁盘进行分区, 输入n并回车,n是"new"新建分区 [root@localhost ~]# fd ...
- Java RMI技术详解与案例分析
Java RMI(Remote Method Invocation)是一种允许Java虚拟机之间进行通信和交互的技术.它使得远程Java对象能够像本地对象一样被访问和操作,从而简化了分布式应用程序的开 ...
- 使用 Apache DolphinScheduler 进行 EMR 任务调度
By AWS Team 前言 随着企业规模的扩大,业务数据的激增,我们会使用 Hadoop/Spark 框架来处理大量数据的 ETL/聚合分析作业,⽽这些作业将需要由统一的作业调度平台去定时调度. 在 ...
- Maven经验分享(八)maven去除jar报依赖
又是项目总结的时候了,说一下maven使用中遇到的问题以及解决方案. 在新项目的开发中,使用maven进行持续构建,在搭建框架的过程中经常遇到jar冲突的问题,现在来介绍下如何去除jar传递依赖. 1 ...
- C语言中的短路现象
短路现象1 比如有以下表达式 a && b && c 只有a为真(非0)才需要判断b的值: 只有a和b都为真,才需要判断c的值. 举例 求最终a.b.c.d的值. ma ...
- liunx下安装Nginx
Linux下nginx的安装以及环境配置 https://blog.csdn.net/qq_42815754/article/details/82980326 第一步:下载nginx压缩包 在这里可以 ...