python os.path 模块详解
python os.path 模块详解
os.path.basename() 返回最后一项,通常是文件名
os.path.dirname() 返回的是目录,不包含文件名
os.path.split() 返回元祖包含:目录和文件名
os.path.join(path1,path2,...) 合并组合为一个完整的路径,返回字符串
os.path.splitext() 返回C:\Users\Jack\Desktop\test 和 .pdf
os.listdir() 只返回当前文件夹里面看得见的文件夹和文件,不遍历
os.walk() 返回当前文件夹里面的所有,遍历
文件夹为:C:\Users\jack\Desktop\test\
文件夹里面的文件有:case1.py, case2.py, case3.py
所以case1.py的总文件路径为:C:\Users\jack\Desktop\test\case1.py path = "C:\Users\jack\Desktop\test\"
files = os.listdir(path)
那么files 输出为[ case1.py, case2.py, case3.py ]
for file in files:
此时的 file 就是 case1.py
file_path = os.path.join(path, file) 此时的file_path 就是case1.py的总文件路径:C:\Users\jack\Desktop\test\case1.py
dir_name = os.path.dirname(file_path) 相当于 dir_name = os.path.split(file_path)[0] 输出 C:\Users\jack\Desktop\test\
base_name = os.path.basename(file_path) 相当于 dir_name = os.path.split(file_path)[1] 输出 case1.py os.path.splitext(file_path) 输出 [ 'C:\Users\jack\Desktop\test\case1', '.py' ]
1,在实际中常见的一个路径操作是,先获取路径的一个部分,再将路径组合拼接为新的路径,可以用于创建、移动、重命名文件或目录。比如我们想要找到中国环境统计年鉴(1999-2017)文件夹中,文件名含有关键字 “2014” 的所有文件,并将文件的路径保存在列表中。代码如下。
# 需要查找文件的文件夹
dir = 'D:\数据Seminar\Python中的os模块\示例资源\中国环境统计年鉴\中国环境统计年鉴(1999-2017)'
# 创建存放结果的列表
list_2014 = list() # os.listdir()函数遍历指定文件夹,返回包含文件夹中所有文件的列表(将在本期第四部分介绍)
all_files = os.listdir(dir)
# 遍历文件夹中每一个文件
for file in all_files:
# 拼接一个文件的路径,得到该文件的绝对路径
file_path = os.path.join(dir, file)
# 使用os.path.basename()函数获取文件名,判断这个文件的文件名是否含有关键字“2014”
## 该语句可以替换为 if “2014” in os.path.split(file_path)[1]:
if '2014' in os.path.basename(file_path):
list_2014.append(file_path)
# 查看最终结果列表
list_2014
os.path.join()函数常与os.path.split()等函数一起使用,通过后者解析路径中的目录或文件部分,使用前者进行动态的路径拼接,避免了手动添加文件路径中的分隔符,同时,在拼接路径名时,还可以使用相对路径或绝对路径,使得程序更加简洁明了。操作文件路径时,还有一个较常用的是os.path.abspath()函数,该函数可以将指定路径转化为绝对路径,这样的好处在于,能够确保访问的是文件的绝对路径,避免了由于相对路径与绝对路径不一致导致的错误,同时也避免了由于操作系统不同导致的路径表达方式不同。
2,通常在对文件或目录进行操作前,我们需要先判断指定路径是否指向文件或目录,否则可能会出现错误。比如,我们想要获取某个文件的大小和修改时间,通过以下代码实现。
# 文件的绝对路径
path = r'D:\数据Seminar\Python中的os模块\示例资源\1997~2018县市社会经济主要指标\1997~2018县市社会经济主要指标.xlsx'
# 判断该路径是否指向文件,避免路径错误
if os.path.exists(path):
# 获取指定文件的大小
size = os.path.getsize(path)
# 获取指定文件的修改时间
mtime = os.path.getmtime(path)
print(f'文件大小为{size}字节,最后修改时间为{mtime}')
else:
print('指定路径不存在')
3,如本期引言中提到,我们在数据处理时会遇到一种场景,需要对指定文件夹中特定类型的文件进行处理,那么我们应该如何得到文件的类型呢?本节介绍os.path 模块中用于获取文件拓展名的os.path.splitext()函数。
os.path.splitext(path)函数将路径分为文件名和拓展名两部分。参数 path 是要分割的路径字符串,函数返回值为一个二元组,位置一为文件名,位置二为文件的扩展名,如果该路径末尾没有拓展名,则元组的第二个元素为空字符串。这个函数的返回结果有助于我们找到指定类型的文件,比如,我们想要找到指定文件夹下的所有 PDF 文件,并将其路径保存在列表中。代码如下。
# 文件夹的绝对路径
path = r'D:\数据Seminar\Python中的os模块\示例资源'
#用于存放结果的列表
pdf_files = list() # os.listdir()函数遍历指定文件夹,返回包含文件夹中所有文件的列表(将在本期第四部分介绍)
all_files_name = os.listdir(path)
# 遍历每一个文件
for file_name in all_files_name:
# 拼接文件的路径
file_path = os.path.join(path, file_name)
# 如果文件得到拓展名为'pdf',将其添加到列表中
if os.path.splitext(file_path)[1] == '.pdf':
pdf_files.append(file_path)
# 查看最终的结果
pdf_files
这个示例演示了一种常用于找到文件夹中特定类型文件的方法,通常先使用os.listdir()函数(下文介绍)获取目录下的所有文件,然后遍历文件列表,通过os.path.splitext()函数对文件的拓展名进行判断,找到我们需要类型的文件。
4,os.listdir()函数
os.listdir(path)函数得到一个包含指定目录下所有文件和子目录名称的列表,其中,参数 path 为遍历的目录路径(如果不指定路径,默认为当前工作目录)。在上例中,为找到示例资源文件夹中所有的PDF文件,我们使用os.listdir(path)函数遍历,并将返回的列表赋值给变量all_files_name,代码及列表内容如下。
all_files_name = os.listdir('./示例资源') 返回的all_files_name 是一个列表

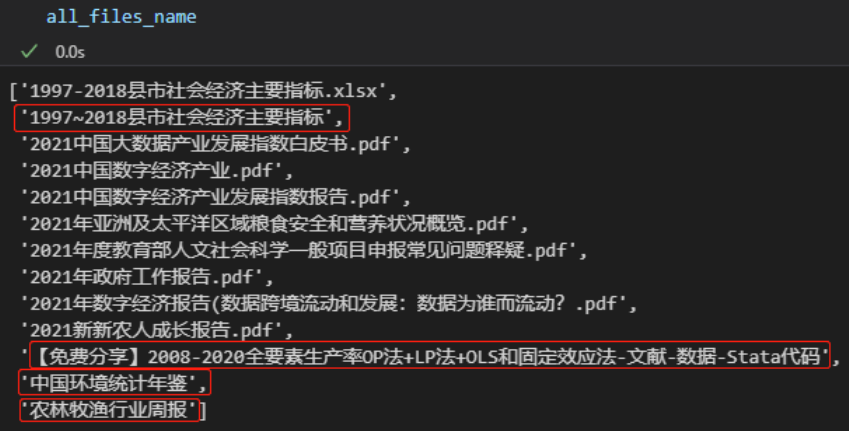
上图中红框部分为示例资源文件夹中的子目录,其余为该文件夹中的文件。在此基础上,便可以结合路径操作方法,循环遍历每一个文件。但是这个函数只能返回指定路径的同级子目录名和文件名,返回结果不包含子目录中的文件和目录,如果需要递归遍历目录下所有文件和子目录,应该使用os.walk()函数。
5,os.walk()函数
os.walk()函数是一个递归式的遍历(递归遍历是指在遍历目录结构时,对每个子目录都进行一次遍历,从而达到遍历整个目录及其子目录的目的),用于遍历指定目录及其子目录中的所有文件和目录,其语法如下。
os.walk(top, topdown=True, onerror=None, followlinks=False)
其中,参数具体含义如下。
- top 为要遍历的目录路径。返回的是一个三元组(dirpath,dirnames,filenames),dirpath 为当前遍历的目录树的目录路径,dirnames 为当前目录下所有子目录列表,filenames为当前目录下所有文件列表。
- topdown 为可选参数,为 True 时(默认)表示优先遍历 top目录,即 walk 会遍历 top 文件夹与其每一个子目录。否则会优先遍历 top 的子目录。
- onerror 为可选的错误处理函数。
- followlinks为可选参数,为 True 时表示会遍历目录下的快捷方式实际所指的目录,为 False 时(默认)表示优先遍历 top 的子目录。
当我们使用os.walk()函数时,它会从根目录开始遍历整个目录树,并且对于每个目录,都会返回一个三元组。下面我们通过示例了解 os.walk() 函数如何进行递归遍历。
现在我们有一个递归遍历示例文件夹(为方便演示,根目录下只有一级子目录),其文件结构为
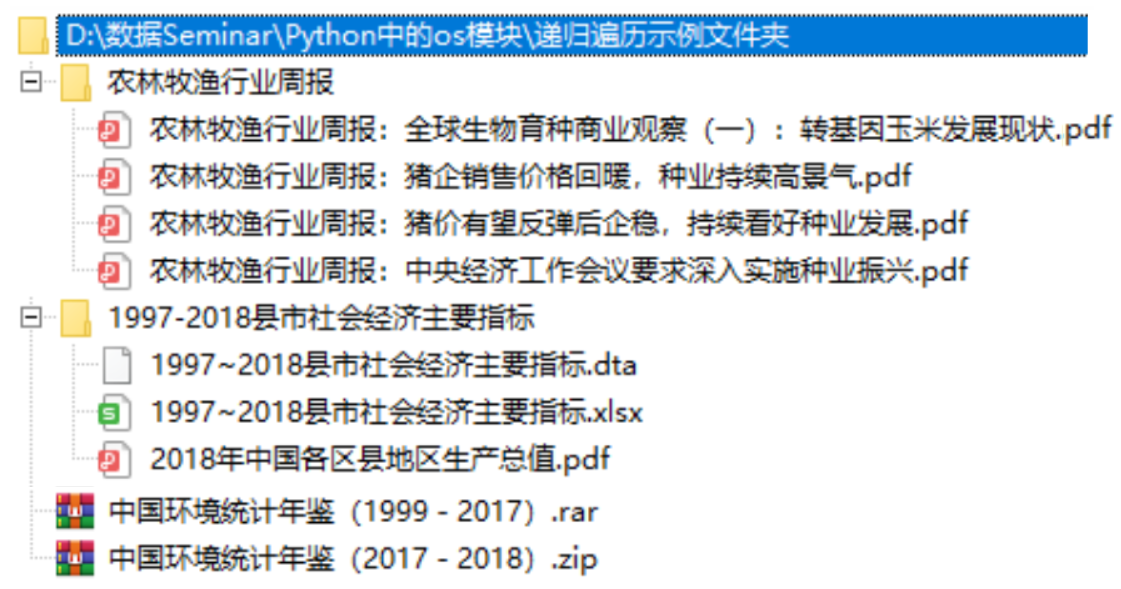
可以看到,根目录d:\数据Seminar\Python中的os模块\递归遍历示例文件夹中有两个文件,以及两个子目录,再将其子目录展开,得到如下目录树。

下面使用os.walk()函数遍历目录d:\数据Seminar\Python中的os模块\递归遍历示例文件夹。
os.walk(path) 返回的是一个三元组(dirpath,dirnames,filenames),dirpath 为当前遍历的目录树的目录路径,dirnames 为当前目录下所有子目录列表,filenames为当前目录下所有文件列表。
# 递归遍历该目录
walk_tree = os.walk('D:\数据Seminar\Python中的os模块\递归遍历示例文件夹') # 从根目录开始遍历整个目录树,每一个目录都会返回一个三元组,使用for循环依次查看结果
for dirpath, dirnames, filenames in walk_tree:
print('----------当前遍历的目录树的目录路径----------')
print(dirpath) print('----------当前目录下的所有子目录列表----------')
# 遍历当前目录下所有的子目录----------------------这个功能很少使用------------------这个功能很少使用---------------
for dirname in dirnames:
# 拼接路径,得到子目录的路径
dir_name = os.path.join(dirpath, dirname)
print(dir_name) print('----------当前目录下所有文件列表----------')
# 遍历当前目录下所有的文件
for filename in filenames:
# 拼接路径,得到文件路径
file_name = os.path.join(dirpath,filename)
print(file_name)
得到结果如下图所示,第一次循环遍历目录树,结果为红框所示,在当前遍历的根目录下,有两个子目录分别为1997-2018县市社会经济主要指标和农林牧渔行业周报,以及两个文件。第二次循环遍历目录树,当前根目录变为d:\数据Seminar\Python中的os模块\递归遍历示例文件夹\1997-2018县市社会经济主要指标(即目录树的根目录下的第一个子目录),得到该目录下所有的文件,且该目录下没有子目录,故为空。同理,得到第三次循环遍历目录树的结果。

通过os.walk()函数,我们可以轻松遍历整个目录树,查找指定路径中我们需要的所有文件或目录,在处理大量数据时更方便。如果只需要查找指定路径的文件,使用os.listdir()函数即可。
python os.path 模块详解的更多相关文章
- 转载的:Python os 和 os.path模块详解
os.getcwd()获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录:相当于shell下cd os.curdi ...
- python标准库介绍——2 os.path模块详解
== os.path 模块 == ``os.path`` 模块包含了各种处理长文件名(路径名)的函数. 先导入 (import) ``os`` 模块, 然后就可以以 ``os.path`` 访问该模块 ...
- (转)python之os,sys模块详解
python之sys模块详解 原文:http://www.cnblogs.com/cherishry/p/5725184.html sys模块功能多,我们这里介绍一些比较实用的功能,相信你会喜欢的,和 ...
- python之sys模块详解
python之sys模块详解 sys模块功能多,我们这里介绍一些比较实用的功能,相信你会喜欢的,和我一起走进python的模块吧! sys模块的常见函数列表 sys.argv: 实现从程序外部向程序传 ...
- python中threading模块详解(一)
python中threading模块详解(一) 来源 http://blog.chinaunix.net/uid-27571599-id-3484048.html threading提供了一个比thr ...
- Python中time模块详解
Python中time模块详解 在平常的代码中,我们常常需要与时间打交道.在Python中,与时间处理有关的模块就包括:time,datetime以及calendar.这篇文章,主要讲解time模块. ...
- Node入门教程(8)第六章:path 模块详解
path 模块详解 path 模块提供了一些工具函数,用于处理文件与目录的路径.由于windows和其他系统之间路径不统一,path模块还专门做了相关处理,屏蔽了彼此之间的差异. 可移植操作系统接口( ...
- 【308】Python os.path 模块常用方法
参考:Python os.path 模块 参考:python3中,os.path模块下常用的用法总结 01 abspath 返回一个目录的绝对路径. 02 basename 返回一个目录的基名 ...
- Python的logging模块详解
Python的logging模块详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.日志级别 日志级别指的是产生的日志的事件的严重程度. 设置一个级别后,严重程度 ...
- python os.path模块常用方法详解
os.path模块主要用于文件的属性获取,在编程中经常用到,以下是该模块的几种常用方法.更多的方法可以去查看官方文档:http://docs.python.org/library/os.path.ht ...
随机推荐
- 使用Docker安装Odoo 17(非Docker Compose)
使用Docker安装Odoo 17(非Docker Compose) 前言 最近在学习Odoo,先是windows 安装企业版,多年不用windows的服务器操作系统,一看windows的ECS那么贵 ...
- 绑定style
² 对象语法 <div:style="{color: redColor, fontSize: '20px'}">对象写法</div> data: { red ...
- git基础命令 gitHub
git 和 gitHub git : 本地项目版本管理工具 gitHub : 相当于一个有很多功能的百度云盘,存储本地项目版本,管 ...
- ETL工具-nifi干货系列 第六讲 处理器JoltTransformJSON
1.处理器作用 使用Jolt转换JSON数据为其他结构的JSON,成功的路由到'success',失败的'failure'.处理JSON的实用程序不是基于流的,因此大型JSON文档转换可能会消耗大量内 ...
- xxlJob端口号及故障转移设置,解决负载均衡调度任务执行
xxlJob端口号及故障转移设置,解决负载均衡调度任务执行 my.xxljob.executorPort = 1162 my.xxljob.executorAppName = myService-jo ...
- 关于 "= default" 和 "= delete" 函数
在 C++ 11 中,"= default" 和 "= delete" 函数使我们能够显示指定成员函数是否自动生成. 其中,"= delete&quo ...
- DHorse v1.5.1 发布,基于 k8s 的发布平台
版本说明 新增特性 支持k8s的v1.30.x版本: 优化特性 优化回滚功能: 修复注册来源的回滚问题: 新增和修改应用时校验应用名: 升级kubernetes-client至v6.13.0: 调整部 ...
- 关于Collection和Map的笔记
此二者在日常编程中,用得太频繁,所以多少有必要记录下,便于需要的时候翻翻. 但鉴于它们的后代太多,逐一牢记有有点难度,所以学习上应该把握以下几点即可: 含义 重要区别 常用的实现类和工具 关注要点:有 ...
- Linux 获取 指定目录 下的 最大子目录深度
命令 function getDirMaxDepth() { folder_name="$1" if [ ! -d "$folder_name" ];then ...
- ComfyUI进阶篇:ComfyUI核心节点(一)
ComfyUI进阶篇:ComfyUI核心节点(一) 前言: 学习ComfyUI是一场持久战.当你掌握了ComfyUI的安装和运行之后,会发现大量五花八门的节点.面对各种各样的工作流和复杂的节点种类,可 ...