论文解读:ACL2021 NER | 基于模板的BART命名实体识别
摘要:本文是对ACL2021 NER 基于模板的BART命名实体识别这一论文工作进行初步解读。
本文分享自华为云社区《ACL2021 NER | 基于模板的BART命名实体识别》,作者: JuTzungKuei 。
论文:Cui Leyang, Wu Yu, Liu Jian, Yang Sen, Zhang Yue. TemplateBased Named Entity Recognition Using BART [A]. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 [C]. Online: Association for Computational Linguistics, 2021, 1835–1845.
链接:https://aclanthology.org/2021.findings-acl.161.pdf
代码:https://github.com/Nealcly/templateNER

0、摘要
- 小样本NER:源领域数据多,目标领域数据少
- 现有方法:基于相似性的度量
- 缺点:不能利用模型参数中的知识进行迁移
- 提出基于模板的方法
- NER看作一种语言模型排序问题,seq2seq框架
- 原始句子和模板分别作为源序列和模板序列,由候选实体span填充
- 推理:根据相应的模板分数对每个候选span分类
- 数据集
- CoNLL03 富资源
- MIT Movie、MIT Restaurant、ATIS 低资源
1、介绍
- NER:NLP基础任务,识别提及span,并分类
- 神经NER模型:需要大量标注数据,新闻领域很多,但其他领域很少
- 理想情况:富资源 知识迁移到 低资源
- 实际情况:不同领域实体类别不同
- 训练和测试:softmax层和crf层需要一致的标签
- 新领域:输出层必须再调整和训练
- 最近,小样本NER采用距离度量:训练相似性度量函数
- 优:降低了领域适配
- 缺:(1)启发式最近邻搜索,查找最佳超参,未更新网络参数,不能改善跨域实例的神经表示;(2)依赖源域和目标域相似的文本模式
- 提出基于模板的方法
- 利用生成PLM的小样本学习潜力,进行序列标注
- BART由标注实体填充的预定义模板微调
- 实体模板:<candidate_span> is a <entity_type> entity
- 非实体模板:<candidate_span> is not a named entity
- 方法优点:
- 可有效利用标注实例在新领域微调
- 比基于距离的方法更鲁棒,即使源域和目标域在写作风格上有很大的差距
- 可应用任意类别的NER,不改变输出层,可持续学习
- 第一个使用生成PLM解决小样本序列标注问题
- Prompt Learning(提示学习)
2、方法
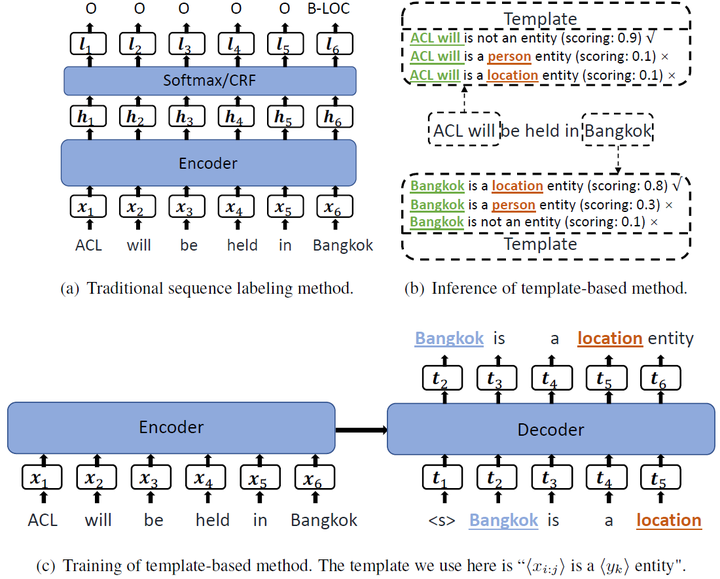
2.1、创建模板
- 将NER任务看作是seq2seq框架下的LM排序问题
- 标签集 entity_type:\mathbf{L}=\{l_1,...,l_{|L|}\}L={l1,...,l∣L∣},即{LOC, PER, ORG, …}
- 自然词:\mathbf{Y}=\{y_1,...,y_{|L|}\}Y={y1,...,y∣L∣},即{location, person, orgazation, …}
- 实体模板:\mathbf{T}^{+}_{y_k}=\text{<candidate\_span> is a location entity.}Tyk+=<candidate_span> is a location entity.
- 非实体模板:\mathbf{T}^{-}=\text{<candidate\_span> is not a named entity.}T−=<candidate_span> is not a named entity.
- 模板集合:\mathbf{T}=[\mathbf{T}^{+}_{y_1},...,\mathbf{T}^{+}_{y_{|L|}},\mathbf{T}^{-}]T=[Ty1+,...,Ty∣L∣+,T−]
2.2、推理
- 枚举所有的span,限制n-grams的数量1~8,每个句子有8n个模板
- 模板打分:\mathbf{T}_{{y_k},x_{i:j}}=\{t_1,...,t_m\}Tyk,xi:j={t1,...,tm}
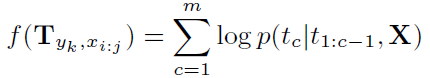
- x_{i:j}xi:j实体得分最高
- 如果存在嵌套实体,选择得分较高的一个
2.3、训练
- 金标实体用于创建模板
- 实体x_{i:j}xi:j的类型为y_kyk,其模板为:\mathbf{T}^{+}_{y_k,x_{i:j}}Tyk,xi:j+
- 非实体x_{i:j}xi:j,其模板为:\mathbf{T}^{-}_{x_{i:j}}Txi:j−
- 构建训练集:
- 正例:(\mathbf{X}, \mathbf{T}^+)(X,T+)
- 负例:(\mathbf{X}, \mathbf{T}^-)(X,T−),随机采样,数量是正例的1.5倍
- 编码:\mathbf{h}^{enc}=\text{ENCODER}(x_{1:n})henc=ENCODER(x1:n)
- 解码:\mathbf{h}_c^{dec}=\text{DECODER}(h^{enc}, t_{1:c-1})hcdec=DECODER(henc,t1:c−1)
- 词t_ctc的条件概率:p(t_c|t_{1:c-1},\mathbf{X})=\text{SOFTMAX}(\mathbf{h}_c^{dec}\mathbf{W}_{lm}+\mathbf{b}_{lm})p(tc∣t1:c−1,X)=SOFTMAX(hcdecWlm+blm)
- \mathbf{W}_{lm} \in \mathbb{R}^{d_h\times |V|}Wlm∈Rdh×∣V∣
- 交叉熵loss
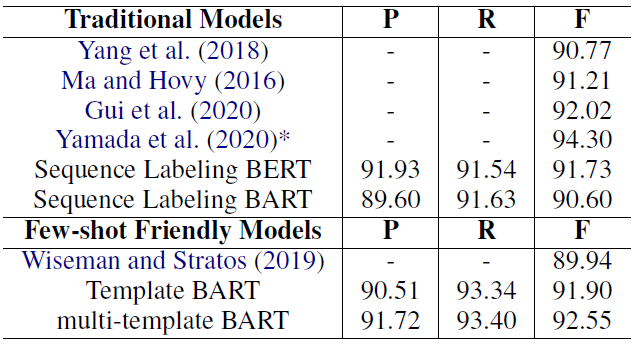
3、结果
- 不同模板类型的测试结果
- 选择前三个模板,分别训练三个模型

- 实验结果
- 最后一行是三模型融合,实体级投票
号外号外:想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习。
论文解读:ACL2021 NER | 基于模板的BART命名实体识别的更多相关文章
- DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别
三个月之前 NLP 课程结课,我们做的是命名实体识别的实验.在MSRA的简体中文NER语料(我是从这里下载的,非官方出品,可能不是SIGHAN 2006 Bakeoff-3评测所使用的原版语料)上训练 ...
- PyTorch 高级实战教程:基于 BI-LSTM CRF 实现命名实体识别和中文分词
前言:译者实测 PyTorch 代码非常简洁易懂,只需要将中文分词的数据集预处理成作者提到的格式,即可很快的就迁移了这个代码到中文分词中,相关的代码后续将会分享. 具体的数据格式,这种方式并不适合处理 ...
- 抛弃模板,一种Prompt Learning用于命名实体识别任务的新范式
原创作者 | 王翔 论文名称: Template-free Prompt Tuning for Few-shot NER 文献链接: https://arxiv.org/abs/2109.13532 ...
- 【NER】对命名实体识别(槽位填充)的一些认识
命名实体识别 1. 问题定义 广义的命名实体识别是指识别出待处理文本中三大类(实体类.时间类和数字类).七小类(人名.机构名.地名.日期.货币和百分比)命名实体.但实际应用中不只是识别上述所说的实体类 ...
- 神经网络结构在命名实体识别(NER)中的应用
神经网络结构在命名实体识别(NER)中的应用 近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展.作为NLP领域的基础任务-命名实体识别(Named Entity Recognit ...
- 2. 知识图谱-命名实体识别(NER)详解
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识 ...
- 基于bert的命名实体识别,pytorch实现,支持中文/英文【源学计划】
声明:为了帮助初学者快速入门和上手,开始源学计划,即通过源代码进行学习.该计划收取少量费用,提供有质量保证的源码,以及详细的使用说明. 第一个项目是基于bert的命名实体识别(name entity ...
- 基于keras实现的中文实体识别
1.简介 NER(Named Entity Recognition,命名实体识别)又称作专名识别,是自然语言处理中常见的一项任务,使用的范围非常广.命名实体通常指的是文本中具有特别意义或者指代性非常强 ...
- 【神经网络】神经网络结构在命名实体识别(NER)中的应用
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型,如下图.它是NLP领域中一些复杂任务(例如关系抽取,信息检索等)的 ...
- 命名实体识别(NER)
一.任务 Named Entity Recognition,简称NER.主要用于提取时间.地点.人物.组织机构名. 二.应用 知识图谱.情感分析.机器翻译.对话问答系统都有应用.比如,需要利用命名实体 ...
随机推荐
- Facade 外观模式简介与 C# 示例【结构型5】【设计模式来了_10】
〇.简介 1.什么是外观模式? 一句话解释: 将一系列需要一起进行的操作,封装到一个类中,通过对某一个方法的调用,自动完成一系列操作. 外观模式是一种简单而又实用的设计模式,它的目的是提供一个统一 ...
- SQL基础应用
SQL基础应用 更多详细内容请查阅:https://www.jianshu.com/p/08c4b78402ff 1.SQL介绍 结构化查询语言 5.7 以后符合SQL92严格模式 通过sql_mod ...
- MongoDB 中的锁分析
MongoDB 中的锁 前言 MongoDB 中锁的类型 锁的让渡释放 常见操作使用的锁类型 如果定位 MongoDB 中锁操作 1.查询运行超过20S 的请求 2.批量删除请求大于 20s 的请求 ...
- Chromium VIZ工作流
在 Chromium 中 viz 的核心逻辑运行在 GPU 进程中,负责接收其他进程产生的 viz::CompositorFrame(简称 CF),然后把这些 CF 进行合成,并将合成的结果最终渲染在 ...
- sed 原地替换文件时遇到的趣事
哈喽大家好,我是咸鱼 在文章<三剑客之 sed>中咸鱼向大家介绍了文本三剑客中的 sed sed 全名叫 stream editor,流编辑器,用程序的方式来编辑文本 那么今天咸鱼打算讲一 ...
- ST-Link v2 刷写 GNUK,年轻人的第一个 OpenPGP 智能卡!
前言 看到了这篇文章 想搞 PGP 智能卡玩,但是 yubikey 死贵 还涉及到某些傻逼政治问题 于是就想找找有无开源实现什么的. 然后就看见了 smartcard 的制作教程,可惜能找到的便宜 j ...
- c#中代理模式详解
基本介绍: "代理"顾名思义指以他人的名义,在授权范围内进行处理事情的意思. 在编程语言中的则解释为:为其他对象提供一种代理以控制对这个对象的访问. 从释义上不难解读, ...
- Webpack相关知识点
webpack的优点 webpack从配置的入口出发,可以打包所有前端资源,同时可以配置多种loader来处理不同类型文件的转换,并且可以配置plugin来扩展模块打包流程,满足更多构建中特殊的需求, ...
- Stable Diffusion扩散模型
人像生成模型 1.模型理论基础 扩散模型(Diffusion Model): 1.1 Diffusion Model 原理 首先,Denoise Model 需要一个起始的噪声图像作为输入.这个噪声图 ...
- 有什么BI工具可以实现中国式报表?
BI(Business Intelligence)工具是指用于帮助企业收集.分析.处理和展示数据的软件工具,以支持企业决策制定和业务运营优化的技术系统. 中国式报表在BI工具中的实现主要涉及到对中国商 ...