[转帖]MySQL 官方出品,比 mydumper 更快的多线程逻辑备份工具-MySQL Shell Dump & Load
mysqldump 和 mydumper 是我们常用的两个逻辑备份工具。
无论是 mysqldump 还是 mydumper 都是将备份数据通过 INSERT 的方式写入到备份文件中。
恢复时,myloader( mydumper 中的恢复工具 ) 是多线程导入,且一个 INSERT 语句中包含多条记录,多个 INSERT 操作批量提交。基本上,凡是我们能想到的,有助于提升导入速度的,myloader 都会使用或有选项提供。
单就恢复速度而言,可以说,myloader 就是逻辑恢复工具的天花板。
既然如此,还有办法能继续提升逻辑恢复工具的恢复速度么?毕竟,备份的恢复速度直接影响着灾难发生时数据库服务的 RTO。
答案,有!
这个就是官方在 MySQL Shell 8.0.21 中推出的 Dump & Load 工具。
与 myloader 不一样的是,MySQL Shell Load 是通过 LOAD DATA LOCAL INFILE 命令来导入数据的。
而 LOAD DATA 操作,按照官方文档的说法,比 INSERT 操作快 20 倍。
下面,我们看看 MySQL Shell Dump & Load 的具体用法和实现原理。
本文主要包括以下几部分:
- 什么是 MySQL Shell。
- MySQL Shell的安装。
- MySQL Shell Dump & Load的使用。
- util.dumpInstance的关键特性。
- util.loadDump的关键特性。
- util.dumpInstance的备份流程。
- util.dumpInstance的参数解析。
- util.loadDump的参数解析。
- 使用 MySQL Shell Dump & Load时的注意事项。
什么是 MySQL Shell
MySQL Shell 是 MySQL 的一个高级客户端和代码编辑器,是第二代 MySQL 客户端。第一代 MySQL 客户端即我们常用的 mysql。
相比于 mysql,MySQL Shell 不仅支持 SQL,还具有以下关键特性:
- 支持 Python 和 JavaScript 两种语言模式。基于此,我们可以很容易地进行一些脚本开发工作。
- 支持 AdminAPI。AdminAPI 可用来管理 InnoDB Cluster、InnoDB ClusterSet 和 InnoDB ReplicaSet。
- 支持 X DevAPI。X DevAPI 可对文档( Document )和表( Table )进行 CRUD(Create,Read,Update,Delete)操作。
除此之外,MySQL Shell 还内置了很多实用工具,包括:
- checkForServerUpgrade:检测目标实例能否升级到指定版本。
- dumpInstance:备份实例。
- dumpSchemas:备份指定库。
- dumpTables:备份指定表。
- loadDump:恢复通过上面三个工具生成的备份。
- exportTable:将指定的表导出到文本文件中。只支持单表,效果同
SELECT INTO OUTFILE一样。 - importTable:将指定文本的数据导入到表中。
在线上,如果我们有个大文件需要导入,建议使用这个工具。它会将单个文件进行拆分,然后多线程并行执行 LOAD DATA LOCAL INFILE 操作。不仅提升了导入速度,还规避了大事务的问题。 - importJson:将 JSON 格式的数据导入到 MySQL 中,譬如将 MongoDB 中通过 mongoexport 导出的数据导入到 MySQL 中。
在使用时注意:
- 通过 dumpInstance,dumpSchemas,dumpTables 生成的备份只能通过 loadDump 来恢复。
- 通过 exportTable 生成的备份只能通过 importTable 来恢复。
下面,我们重点说说 Dump & Load 相关的工具,包括 dumpInstance,dumpSchemas,dumpTables 和 loadDump。
MySQL Shell 的安装
MySQL Shell 下载地址:https://dev.mysql.com/downloads/shell/。
同 MySQL 一样,提供了多个版本的下载。这里使用 Linux 二进制版本( Linux - Generic )。
# cd /usr/local/
# wget https://dev.mysql.com/get/Downloads/MySQL-Shell/mysql-shell-8.0.29-linux-glibc2.12-x86-64bit.tar.gz
# tar xvf mysql-shell-8.0.29-linux-glibc2.12-x86-64bit.tar.gz
# ln -s mysql-shell-8.0.29-linux-glibc2.12-x86-64bit mysql-shell
# export PATH=$PATH:/usr/local/mysql-shell/bin MySQL Shell Dump & Load 的使用
util.dumpInstance(outputUrl[, options])
备份实例。
其中,outputUrl 是备份目录,其必须为空。options 是可指定的选项。
首先,看一个简单的示例。
# mysqlsh -h 10.0.20.4 -P3306 -uroot -p
mysql-js> util.dumpInstance('/data/backup/full',{compression: "none"})
Acquiring global read lock
Global read lock acquired
Initializing - done
1 out of 5 schemas will be dumped and within them 1 table, 0 views.
4 out of 7 users will be dumped.
Gathering information - done
All transactions have been started
Locking instance for backup
Global read lock has been released
Writing global DDL files
Writing users DDL
Running data dump using 4 threads.
NOTE: Progress information uses estimated values and may not be accurate.
Writing schema metadata - done
Writing DDL - done
Writing table metadata - done
Starting data dump
101% (650.00K rows / ~639.07K rows), 337.30K rows/s, 65.89 MB/s
Dump duration: 00:00:01s
Total duration: 00:00:01s
Schemas dumped: 1
Tables dumped: 1
Data size: 126.57 MB
Rows written: 650000
Bytes written: 126.57 MB
Average throughput: 65.30 MB/s命令中的 /data/backup/full 是备份目录,compression: "none" 指的是不压缩,这里设置为不压缩主要是为了方便查看数据文件的内容。线上使用建议开启压缩。
接下来我们看看备份目录中的内容。
# ll /data/backup/full/
total 123652
-rw-r----- 1 root root 273 May 25 21:13 @.done.json
-rw-r----- 1 root root 854 May 25 21:13 @.json
-rw-r----- 1 root root 240 May 25 21:13 @.post.sql
-rw-r----- 1 root root 288 May 25 21:13 sbtest.json
-rw-r----- 1 root root 63227502 May 25 21:13 sbtest@sbtest1@0.tsv
-rw-r----- 1 root root 488 May 25 21:13 sbtest@sbtest1@0.tsv.idx
-rw-r----- 1 root root 63339214 May 25 21:13 sbtest@sbtest1@@1.tsv
-rw-r----- 1 root root 488 May 25 21:13 sbtest@sbtest1@@1.tsv.idx
-rw-r----- 1 root root 633 May 25 21:13 sbtest@sbtest1.json
-rw-r----- 1 root root 759 May 25 21:13 sbtest@sbtest1.sql
-rw-r----- 1 root root 535 May 25 21:13 sbtest.sql
-rw-r----- 1 root root 240 May 25 21:13 @.sql
-rw-r----- 1 root root 6045 May 25 21:13 @.users.sql其中,
- @.done.json:会记录备份的结束时间,备份集的大小。备份结束时生成。
- @.json:会记录备份的一些元数据信息,包括备份时的一致性位置点信息:binlogFile,binlogPosition 和 gtidExecuted,这些信息可用来建立复制。
- @.sql,@.post.sql:这两个文件只有一些注释信息。不过在通过 util.loadDump 导入数据时,我们可以通过这两个文件自定义一些 SQL。其中,@.sql 是数据导入前执行,@.post.sql 是数据导入后执行。
- sbtest.json:记录 sbtest 中已经备份的表、视图、定时器、函数和存储过程。
- *.tsv:数据文件。我们看看数据文件的内容。TSV 格式,每一行储存一条记录,字段与字段之间用制表符(\t)分隔。
# head -2 sbtest@sbtest1@0.tsv
1 6461363 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441 22195207048-70116052123-74140395089-76317954521-98694025897
2 1112248 13241531885-45658403807-79170748828-69419634012-13605813761-77983377181-01582588137-21344716829-87370944992-02457486289 28733802923-10548894641-11867531929-71265603657-36546888392- sbtest@sbtest1.json:记录了表相关的一些元数据信息,如列名,字段之间的分隔符(fieldsTerminatedBy)等。
- sbtest@sbtest1.sql:sbtest.sbtest1 的建表语句。
- sbtest.sql:建库语句。如果这个库中存在存储过程、函数、定时器,也是写到这个文件中。
- @.users.sql:创建账号及授权语句。默认不会备份 mysql.session,mysql.session,mysql.sys 这三个内部账号。
util.dumpSchemas(schemas, outputUrl[, options])
备份指定库的数据。
用法同 util.dumpInstance 类似。其中,第一个参数必须为数组,即使只需备份一个库,如,
util.dumpSchemas(['sbtest'],'/data/backup/schema')
支持的配置大部分与 util.dumpInstance 相同。
从 MySQL Shell 8.0.28 开始,可直接使用 util.dumpInstance 中的 includeSchemas 选项进行指定库的备份。
util.dumpTables(schema, tables, outputUrl[, options])
备份指定表的数据。
用法同 util.dumpInstance 类似。其中,第二个参数必须为数组,如,
util.dumpTables('sbtest',['sbtest1'],'/data/backup/table')
支持的配置大部分与 util.dumpInstance 相同。
从 MySQL Shell 8.0.28 开始,可直接使用 util.dumpInstance 中的 includeTables 选项进行指定表的备份。
util.loadDump(url[, options])
导入通过 dump 命令生成的备份集。如,
# mysqlsh -S /data/mysql/3307/data/mysql.sock
mysql-js> util.loadDump("/data/backup/full",{loadUsers: true})
Loading DDL, Data and Users from '/data/backup/full' using 4 threads.
Opening dump...
Target is MySQL 8.0.27. Dump was produced from MySQL 8.0.27
Scanning metadata - done
Checking for pre-existing objects...
Executing common preamble SQL
Executing DDL - done
Executing view DDL - done
Starting data load
2 thds loading - 100% (126.57 MB / 126.57 MB), 11.43 MB/s, 0 / 1 tables done
Recreating indexes - done
Executing user accounts SQL...
NOTE: Skipping CREATE/ALTER USER statements for user 'root'@'localhost'
NOTE: Skipping GRANT statements for user 'root'@'localhost'
Executing common postamble SQL
2 chunks (650.00K rows, 126.57 MB) for 1 tables in 1 schemas were loaded in 10 sec (avg throughput 13.96 MB/s)
0 warnings were reported during the load.
命令中的 /data/backup/full 是备份目录,loadUsers: true 是导入账号,默认不会导入。
util.dumpInstance 的关键特性
util.dumpInstance 的关键特性如下:
- 多线程备份。并发线程数由 threads 决定,默认是 4。
- 支持单表 chunk 级别的并行备份,前提是表上存在主键或唯一索引。
- 默认是压缩备份。
- 支持备份限速。可通过 maxRate 限制单个线程的数据读取速率。
util.loadDump 的关键特性
util.loadDump 的关键特性如下:
- 多线程恢复。并发线程数由 threads 决定,默认是 4。
- 支持断点续传功能。
在导入的过程中,会在备份目录生成一个进度文件,用于记录导入过程中的进度信息。
文件名由 progressFile 指定,默认是 load-progress.<server_uuid>.progress。
导入时,如果备份目录中存在 progressFile,默认会从上次完成的地方继续执行。如果要从头开始执行,需将 resetProgress 设置为 true。 - 支持延迟创建二级索引。
- 支持边备份,边导入。
- 通过 LOAD DATA LOCAL INFILE 命令来导入数据。
- 如果单个文件过大,util.loadDump 在导入时会自动进行切割,以避免产生大事务。
util.dumpInstance 的备份流程
util.dumpInstance 的备份流程如下图所示。
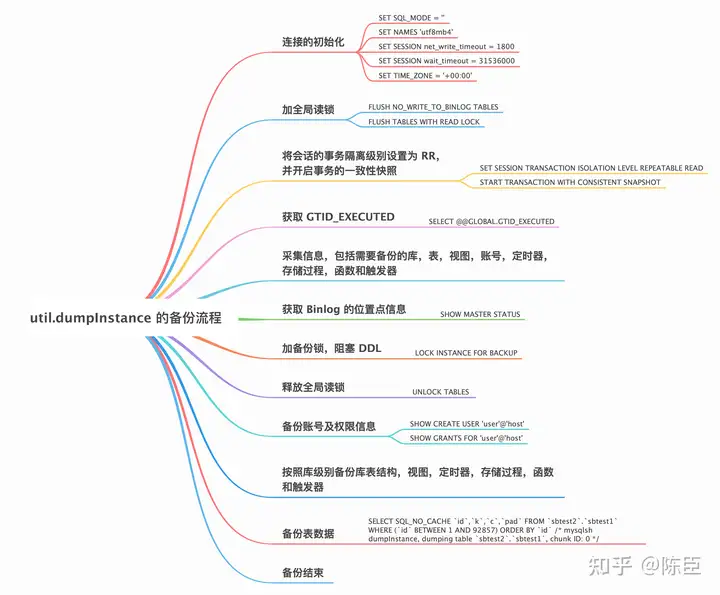
不难看出,util.dumpInstance 的备份流程与 mysqldump 大致相同,不同的地方主要体现在以下两点:
- util.dumpInstance 会加备份锁。备份锁可用来阻塞备份过程中的 DDL。
- util.dumpInstance 是并行备份,相对于 mysqldump 的单线程备份,备份效率更高。
util.dumpInstance 的参数解析
util.dumpInstance 的参数可分为如下几类:
过滤相关
以下是过滤相关的选项。
- excludeSchemas:忽略某些库的备份,多个库之间用逗号隔开,如,
excludeSchemas: ["db1", "db2"] - includeSchemas:指定某些库的备份。
- excludeTables:忽略某些表的备份,表必须是 schema.table 的格式,多个表之间用逗号隔开,如,
excludeTables: ["sbtest.sbtest1", "sbtest.sbtest2"] - includeTables:指定某些表的备份。
- events:是否备份定时器,默认为 true。
- excludeEvents:忽略某些定时器的备份。
- includeEvents:指定某些定时器的备份。
- routines:是否备份函数和存储过程,默认为 true。
- excludeRoutines:忽略某些函数和存储过程的备份。
- includeRoutines:指定某些函数和存储过程的备份。
- users:是否备份账号信息,默认为 true。
- excludeUsers:忽略某些账号的备份,可指定多个账号。
- includeUsers:指定某些账号的备份,可指定多个账号。
- triggers:是否备份触发器,默认为 true。
- excludeTriggers:忽略某些触发器的备份。
- includeTriggers:指定某些触发器的备份。
- ddlOnly:是否只备份表结构,默认为 false。
- dataOnly:是否只备份数据,默认为 false。
并行备份相关
- chunking:是否开启 chunk 级别的并行备份功能,默认为 true。
- bytesPerChunk:每个 chunk 文件的大小,默认 64M。
- threads:并发线程数,默认为 4。
OCI(甲骨文云)相关
- ocimds:是否检查备份集与 MySQL Database Service(甲骨文云的 MySQL 云服务,简称 MDS )的兼容性,默认为 false,不检查。如果设置为 true,会输出所有的不兼容项及解决方法。不兼容项可通过下面的 compatibility 来解决。
- compatibility:如果要将备份数据导入到 MDS 中,为了保证与后者的兼容性,可在导出的过程中进行相应地调整。具体来说:
- create_invisible_pks:对于没有主键的表,会创建一个隐藏主键:my_row_id BIGINT UNSIGNED AUTO_INCREMENT INVISIBLE PRIMARY KEY。隐藏列是 MySQL 8.0.23 引入的。
- force_innodb:将表的引擎强制设置为 InnoDB。
- ignore_missing_pks:忽略主键缺失导致的错误,与 create_invisible_pks 互斥,不能同时指定。
- skip_invalid_accounts:忽略没有密码,或者使用了 MDS 不支持的认证插件的账号。
- strip_definers:去掉视图、存储过程、函数、定时器、触发器中的 DEFINER=account 子句。
- strip_restricted_grants:去掉 MDS 中不允许 GRANT 的权限。
- strip_tablespaces:去掉建表语句中的 TABLESPACE=xxx 子句。
- osBucketName,osNamespace,ociConfigFile,ociProfile,ociParManifest,ociParExpireTime:OCI 对象存储相关。
其它选项
- tzUtc:是否设置 TIME_ZONE = '+00:00',默认为 true。
- consistent:是否开启一致性备份,默认为 true。若设置为 false,则不会加全局读锁,也不会开启事务的一致性快照。
- dryRun:试运行。此时只会打印备份信息,不会执行备份操作。
- maxRate:限制单个线程的数据读取速率,单位 byte,默认为 0,不限制。
- showProgress:是否打印进度信息,如果是 TTY 设备(命令行终端),则为 true,反之,则为 false。
- defaultCharacterSet:字符集,默认为 utf8mb4。
- compression:备份文件的压缩算法,默认为 zstd。也可设置为 gzip 或 none(不压缩)。
util.loadDump 的参数解析
util.loadDump 的参数可分为如下几类:
过滤相关
- excludeEvents:忽略某些定时器的导入。
- excludeRoutines:忽略某些函数和存储过程的导入。
- excludeSchemas:忽略某些库的导入。
- excludeTables:忽略某些表的导入。
- excludeTriggers:忽略某些触发器的导入。
- excludeUsers:忽略某些账号的导入。
- includeEvents:导入指定定时器。
- includeRoutines:导入指定函数和存储过程。
- includeSchemas:导入指定库。
- includeTables:导入指定表。
- includeTriggers:导入指定触发器。
- includeUsers:导入指定账号。
- loadData:是否导入数据,默认为 true。
- loadDdl:是否导入 DDL 语句,默认为 true。
- loadUsers:是否导入账号,默认为 false。注意,即使将 loadUsers 设置为 true,也不会导入当前正在执行导入操作的用户。
- ignoreExistingObjects:是否忽略已经存在的对象,默认为 off。
并行导入相关
- backgroundThreads:获取元数据和 DDL 文件内容的线程数。备份集如果存储在本地,backgroundThreads 默认和 threads 一致。
- threads:并发线程数,默认为 4。
- maxBytesPerTransaction:指定单个 LOAD DATA 操作可加载的最大字节数。默认与 bytesPerChunk 一致。这个参数可用来规避大事务。
断点续传相关
- progressFile:在导入的过程中,会在备份目录生成一个 progressFile,用于记录加载过程中的进度信息,这个进度信息可用来实现断点续传功能。默认为 load-progress.<server_uuid>.progress。
- resetProgress:如果备份目录中存在 progressFile,默认会从上次完成的地方继续执行。如果要从头开始执行,需将 resetProgress 设置为 true。该参数默认为 off。
OCI 相关
osBucketName,osNamespace,ociConfigFile,ociProfile。
二级索引相关
- deferTableIndexes:是否延迟(数据加载完毕后)创建二级索引。可设置:off(不延迟),fulltext(只延迟创建全文索引,默认值),all(延迟创建所有索引)。
- loadIndexes:与 deferTableIndexes 一起使用,用来决定数据加载完毕后,最后的二级索引是否创建,默认为 true。
其它选项
- analyzeTables:表加载完毕后,是否执行 ANALYZE TABLE 操作。默认是 off(不执行),也可设置为 on 或 histogram(只对有直方图信息的表执行)。
- characterSet:字符集,无需显式设置,默认会从备份集中获取。
- createInvisiblePKs:是否创建隐式主键,默认从备份集中获取。这个与备份时是否指定了 create_invisible_pks 有关,若指定了则为 true,反之为 false。
- dryRun:试运行。
- ignoreVersion:忽略 MySQL 的版本检测。默认情况下,要求备份实例和导入实例的大版本一致。
- schema:将表导入到指定 schema 中,适用于通过 util.dumpTables 创建的备份。
- showMetadata:导入时是否打印一致性备份时的位置点信息。
- showProgress:是否打印进度信息。
- skipBinlog:是否设置 sql_log_bin=0 ,默认 false。这一点与 mysqldump、mydumper 不同,后面这两个工具默认会禁用 Binlog。
- updateGtidSet:更新 GTID_PURGED。可设置:off(不更新,默认值), replace(替代目标实例的 GTID_PURGED), append(追加)。
- waitDumpTimeout:util.loadDump 可导入当前正在备份的备份集。处理完所有文件后,如果备份还没有结束(具体来说,是备份集中没有生成 @.done.json),util.loadDump 会报错退出,可指定 waitDumpTimeout 等待一段时间,单位秒。
MySQL Shell Dump & Load 的注意事项
1. 表上存在主键或唯一索引才能进行 chunk 级别的并行备份。字段的数据类型不限。不像 mydumper,分片键只能是整数类型。
2. 对于不能进行并行备份的表,目前会备份到一个文件中。如果该文件过大,不用担心大事务的问题,util.loadDump 在导入时会自动进行切割。
3. util.dumpInstance 只能保证 InnoDB 表的备份一致性。
4. 默认不会备份 information_schema,mysql,ndbinfo,performance_schema,sys。
5. 备份实例支持 MySQL 5.6 及以上版本,导入实例支持 MySQL 5.7 及以上版本。
6. 备份的过程中,会将 BLOB 等非文本安全的列转换为 Base64,由此会导致转换后的数据大小超过原数据。导入时,注意 max_allowed_packet 的限制。
7. 导入之前,需将目标实例的 local_infile 设置为 ON。
参考
[1] Instance Dump Utility, Schema Dump Utility, and Table Dump Utility
[2] MySQL Shell Dump & Load part 1: Demo!
[3] MySQL Shell Dump & Load part 2: Benchmarks
[4] MySQL Shell Dump & Load part 3: Load Dump
[转帖]MySQL 官方出品,比 mydumper 更快的多线程逻辑备份工具-MySQL Shell Dump & Load的更多相关文章
- 官方出品,比 mydumper 更快的逻辑备份工具
mysqldump 和 mydumper 是我们常用的两个逻辑备份工具. 无论是 mysqldump 还是 mydumper 都是将备份数据通过 INSERT 的方式写入到备份文件中. 恢复时,myl ...
- MySQL 逻辑备份工具
简介: Mydumper.Myloader 是一个第三方的.开源的 MySQL 逻辑备份工具. 支持多线程,比起 mysqldump 要快很多,也能解决 innobackupex 备份工具对 MyIS ...
- MySQL数据备份之逻辑备份工具mysqldump
#前言:我们知道对数据进行备份很重要,出现非正常操作可以进行对数据进行恢复,下面我们就来使用一下mysql数据库自带的一个逻辑备份工具mysqldump 1.简单概述 #mysqldump:mysql ...
- MySQL中基于mysqldump和二进制日志log-bin进行逻辑备份以及基于时间点的还原
本文出处:http://www.cnblogs.com/wy123/p/6956464.html 本文仅模拟使用mysqldump和log-bin二进制日志进行简单测试,仅作为个人学习笔记,可能离实际 ...
- mysqlpump:更加合理的mysql数据库逻辑备份工具
端看参见就知道了! E:\mysql-8.0.12-winx64>mysqlpump --helpmysqlpump Ver 8.0.12 for Win64 on x86_64 (MySQL ...
- mysql备份工具 :mysqldump mydumper Xtrabackup 原理
备份是数据安全的最后一道防线,对于任何数据丢失的场景,备份虽然不一定能恢复百分之百的数据(取决于备份周期),但至少能将损失降到最低.衡量备份恢复有两个重要的指标:恢复点目标(RPO)和恢复时间目标(R ...
- MySQL逻辑备份利器-mydumper
关于mydumper的简介和下载请访问:https://launchpad.net/mydumper 简言之,mydumper是多线程逻辑备份,对于表和数据量很大的情况下,建议使用mydumper提高 ...
- MySQL 逻辑备份mysqldump&mysqlpump&mydumper原理解析
目录 准备 mysqldump备份 mysqlpump备份 mydumper备份 想弄清除逻辑备份的原理,最好的办法是开启general_log,一探究竟 准备 创建用户 CREATE USER IF ...
- MySQL 5.7 mysqlpump 备份工具说明
背景: MySQL5.7之后多了一个备份工具:mysqlpump.它是mysqldump的一个衍生,mysqldump就不多说明了,现在看看mysqlpump到底有了哪些提升,可以查看官方文档,这里针 ...
- (4.14)mysql备份还原——mysql物理热备工具之ibbackup
关键词:mysql热备工具,ibbackup,mysql物理备份工具 1. 准备 ibbackup 是 InnoDB 提供的收费工具,它支持在线热备 InnoDB 数据,主要有以下特性: * Onli ...
随机推荐
- cp {,bak}用法(转载)
cp filename{,bak} cp filename{,.bak} 这个命令是用来把filename备份成filename.bak的 等同于命令 cp filename filename.bak ...
- 4.elasticsearch中聚合查询
elasticsearch聚合查询 什么是聚合,就是目的不是查询具体的文档,而是查询文档的相关性,此外还可以对聚合的文档在按照其他维度再聚合. 包含以下四种聚合 Bucket Aggregation ...
- 9 个让你的 Python 代码更快的小技巧
哈喽大家好,我是咸鱼 我们经常听到 "Python 太慢了","Python 性能不行"这样的观点.但是,只要掌握一些编程技巧,就能大幅提升 Python 的运 ...
- CodeForces 1141F2 贪心 离散化
CodeForces 1141F2 贪心 离散化 题意 给定一个序列,要求我们找出最多数量的不相交区间,每个区间和都相等. 思路 一开始没有头绪,不过看到 \(n \le 1500\) 后想到可以把所 ...
- 案例解析关于ArkUI框架中ForEach的潜在陷阱与性能优化
本文分享自华为云社区<深入解析ForEach的潜在陷阱与性能优化:错误用法与性能下降的案例分析>,作者:柠檬味拥抱 . 在ArkUI框架中,ForEach接口是基于数组类型数据进行循环渲染 ...
- 云图说|云数据库GaussDB如何做到卓越性能
摘要:对于数据库来说,性能一直被视为最关键的部分.GaussDB作为华为自主创新研发的分布式关系型数据库,那么华为云数据库GaussDB在提升数据库性能方面都有哪些黑科技呢? 本文分享自华为云社区&l ...
- KubeEdge和Kuiper“双剑合并”,轻松解决边缘流式数据处理
摘要:KubeEdge 是一个开源的边缘计算平台,它在Kubernetes原生的容器编排和调度能力之上,扩展实现了 云边协同.计算下沉.海量边缘设备管理.边缘自治等能力.KubeEdge还将通过插件的 ...
- 实践案例丨CenterNet-Hourglass论文复现
摘要:本案例是CenterNet-Hourglass论文复现的体验案例,此模型是对Objects as Points 中提出的CenterNet进行结果复现. 本文分享自华为云社区<Center ...
- 统一元数据,数据湖Catalog让大数据存算分离不再是问题
摘要:为了解决现阶段大数据存算分离痛点问题,华为云大数据推出重量级数据湖Catalog服务. 1 背景 随着5G.IoT等技术的发展,企业积累了越来越多的数据,需要激发更多的数据价值变现.传统大数据平 ...
- 带你了解数据库的“吸尘器”:VACUUM
摘要:在GaussDB(DWS)中,VACUUM的本质就是一个"吸尘器",用于吸收"尘埃". 下面将从VACUUM的作用.用法.原理等方面进行介绍. 在Gaus ...