【算法day4】堆结构、堆排序、比较器以及桶排
堆与堆结构(优先级队列结构)
知识点:
- 堆结构就是用数组实现的完全二叉树结构
- 完全二叉树中如果每棵子树的最大值都在顶部就是大根堆
- 完全二叉树中如果每棵子树的最小值都在顶部就是小根堆
- 堆结构的heaplnsert与heapify操作
- 堆结构的增大和减少
- 优先级队列结构,就是堆结构
一段连续的数组是可以想象成完全二叉树结构的
例如
[3,5,2,7,1,9,6]
[0,1,2,3,4,5,6]
对应到完全二叉树结构中得到
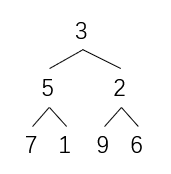
连续的一段数组可以用一个"size"描述,表示一个连续的数组到达的位置(与数组长度无关)
这个例子中的size = 7
若用数组下标表示该完全二叉树,则
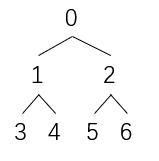
那么生成树的对应规则是:
i位置(0~6)对应的左分支为:2*i+1
例如,
0的左分支是2*0+1=1;
1的左分支是2* 1+1=1,2的左分支是2*2+1=5;
3的没有左分支,因为按照公式计算后所得超过了size,456同理
i位置(0~6)对应的右分支为:2*i+2
i位置(0~6)对应的父分支为:(i-1)/2
例如,
5位置的父分支节点是(5-1)/2=2,6位置的父分支节点是(6-1)/2=2.5,取整为2
大/小根堆
定义:在完全二叉树中,每一棵子树的最大值就是头节点的值
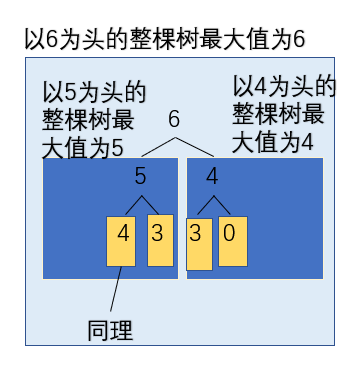
反之,则为小根堆
将连续数组表示为堆(heapinsert,将大数往上移)
假设,现在有一个数组[],设一个变量为heapsize = 0

heapsize = 0意味着数组中从0出发的连续的0个数现在构成一个堆
此时,用户给了一个数,假设是5
那么根据heapsize的指示,5被放在0位置上,heapsize+1 = 1
用户又给了一个数3,根据heapsize的指示,3被放在1位置上,heapsize+1 = 2

用户再给一个数6,根据heapsize的指示,6被放在2位置上,heapsize+1 = 3
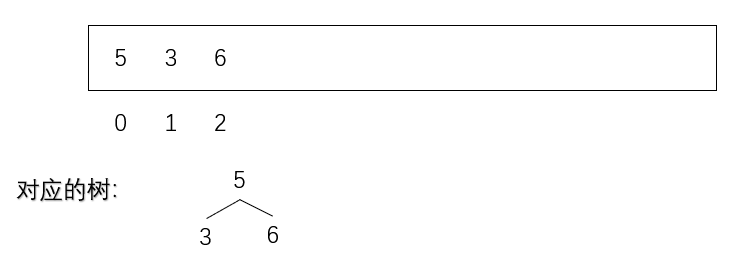
此时的树不满足“大根堆”要求,于是6就需要和自己的父去做比较
6的位置是已知的(heapsize还没变)
根据生成树的规则可以找到6的父值
父分支=(i-1)/2=(2-1)/2=0.5,取整为0
于是6需要与0位置的数(也就是5)比较大小
6比5大,于是两者交换位置,树又满足大根堆的要求了
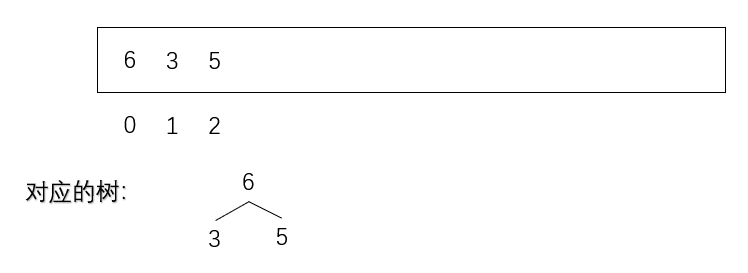
如果再进来一个更大的数也是同样的操作
规律就是,新来的数一直与自己的父值比较,若大于父值则交换,直到比较完所有的父值或者来到整棵树的头部就停止。
若小于就不动。
这样操作后可以保证用户给的每一个数到了数组里,形成的结构均为大根堆
heapify
在现有的堆中插入一个数,该数较小不符合当前位置,为了整体结构仍满足大根堆,要将其往下移,该操作称为heapify,代码实现如下

堆排序
假设有数组
[3,5,9,4,6,7,0]
[0,1,2,3,4,5,6], heapsize = 0
现在按照之前的方法从0位置到6位置让该数组排成大根堆
排完之后结果如下
数组变为由大到小的排序
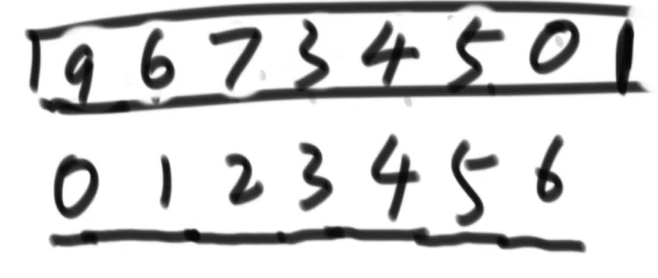
对应的树结构是,当前heapsize = 7
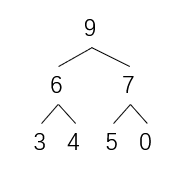
此时,将0位置的最大值与6位置的最小值交换
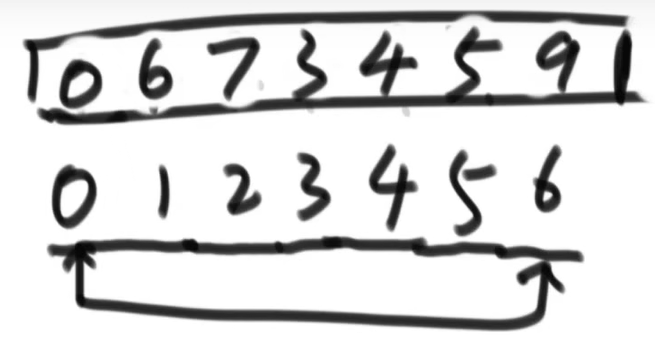
heapsize -- = 6
这样做的目的是让最大值来到堆的末尾,然后让最大值与堆断开联系(因为它是已经排好的数,堆没必要再包含它)
那么当前的树结构变为
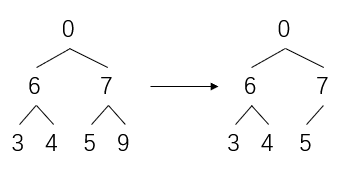
舍弃堆末尾的最大值9
然后让剩下的数继续做heapify,把0再弄到堆的末尾
排完之后结果如下

树结构
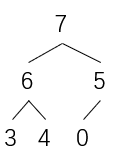
此时,又将0位置的最大值与5位置的最小值交换
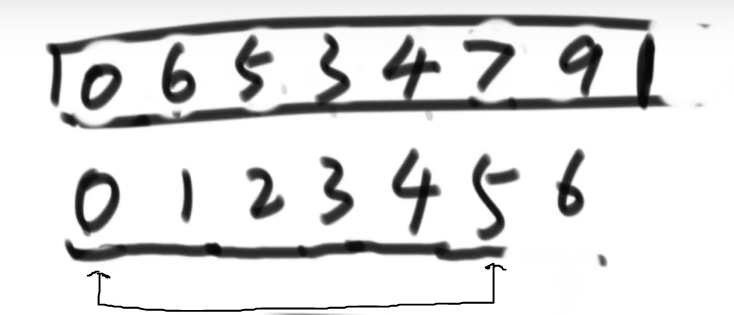
heapsize -- = 5
当前的树结构变为
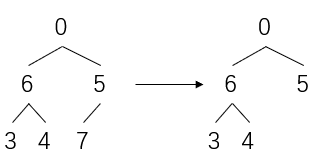
舍弃堆末尾的最大值7
然后让剩下的数继续做heapify,周而复始直到堆减为0结束
更优化的方式获取大根堆
如果我们已经知道数组中的所有数,并且只需要得到大根堆(不做别的操作)
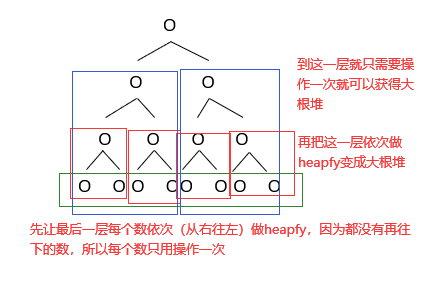
tips:
1、堆结构底层是由数组支持实现的,如果堆在不断扩大的过程中超过了数组的长度,那么数组要成倍的加长
例如,原来的数组长度是100,用完之后系统会直接给它加到200,再用完就变成400
这样,算法的空间复杂度仍然不变
2、高级语言自带的堆方法只是一个黑盒,我们可以通过add和poll与之交互,本质就是我给它一个数,它给我一个数
虽然这样在简单场景下高效,但是针对一些具体问题就不好用了
比如,我想从已经规定好的堆结构里取一个数,然后让堆仍然保持大/小根堆,自带的堆方法效率很低,只能自己手写一个
这就是为什么面试的时候经常会要求手写堆结构的原因
比较器
1)比较器的实质就是重载比较运算符
2)比较器可以很好的应用在特殊标准的排序上
3)比较器可以很好的应用在根据特殊标准排序的结构上
在C++里也叫重载运算符
简单来说,就是在比较数的时候自定义一些的规则,让比较结构变成我们想要的
例子1,
比如我调用了.sort()方法去给数组排序
排序的本质就是比较数的大小
如果上面都不加,系统可能默认从大到小排出结果
但是,我现在希望从小到大(或者指定哪些数先排等一些更复杂的排序)排,那么我就可以传一个比较器给.sort()
.sort()就可以按照比较器规定的方式进行排序(比较)
例子2,
PriorityQueue是java中的优先级队列结构(也就是系统提供的堆方法)
当不指定时,默认生成的是小根堆
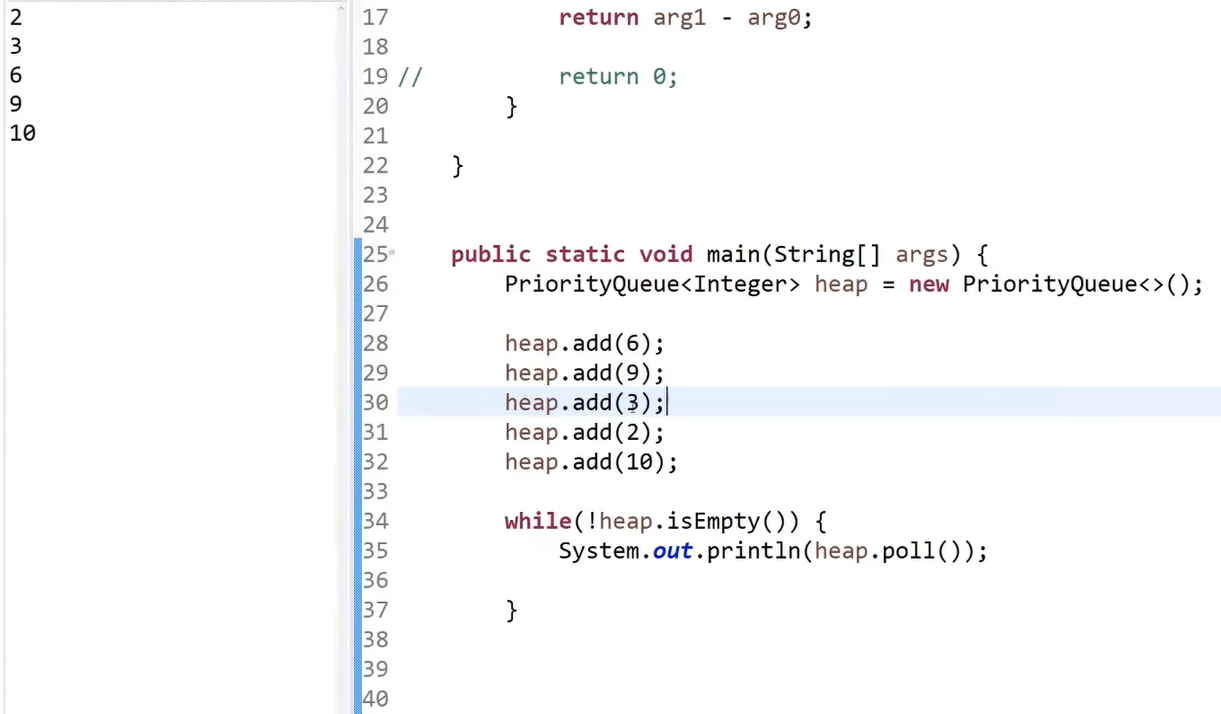
往里面添加数后poll,会按照从小到大的顺序返回值
此时,给它传一个比较器如下


这样PriorityQueue就会以大根堆的方式去构建了
比较器的应用场景
可以用于定义复杂的比较策略
例如,
我有两个数据:班级和年龄
如果想让整个数组整体按年龄来排序(小的在前),但是年龄一样的时候,班级大的排在前面
这时候可以定义比较器去实现(代码量少)
tips:
到目前为止,所有的排序算法都是基于"比较"进行的排序
也有不依靠"比较"进行的排序,但需要针对数据进行定制,往往只在特定情况下高效,使用范围较小
桶排序(基数排序)
桶排序思想下的排序
1)计数排序
2)基数排序
分析:
1)桶排序思想下的排序都是不基于比较的排序
2)时间复杂度为0(N),额外空间负载度0(M)
3)应用范围有限,需要样本的数据状况满足桶的划分
假设有以下数
[17,13,25,100,72]
里面最大的是三位数,所以其他的数要补成三位
[017,013,025,100,072]
现在设置一些“桶”用于存放数据(桶的底层一般是队列、数组或栈,这里用的是队列)
因为是十进制的数,所以理论上最多需要十个“桶”
具体到当前问题,实际上只用了0、1、2、3、5、7这几个
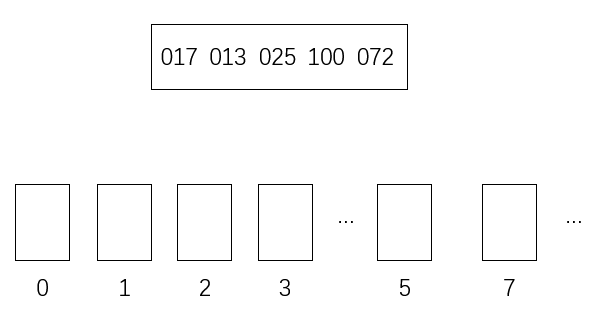
然后,从左到右按个位数将数放入桶里
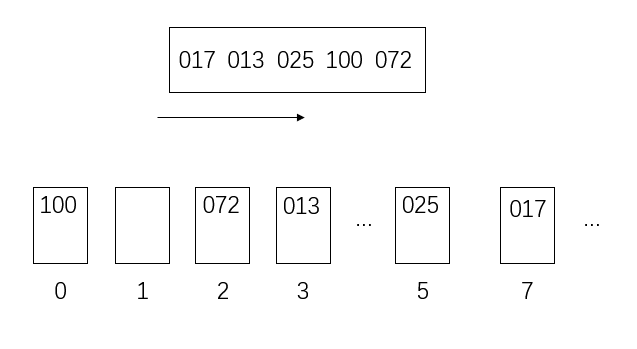
然后把桶里的数从左往右倒出来,数组更新
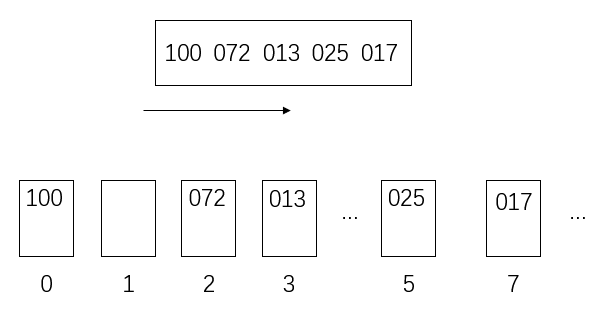
再从左到右按十位数将数放入桶里
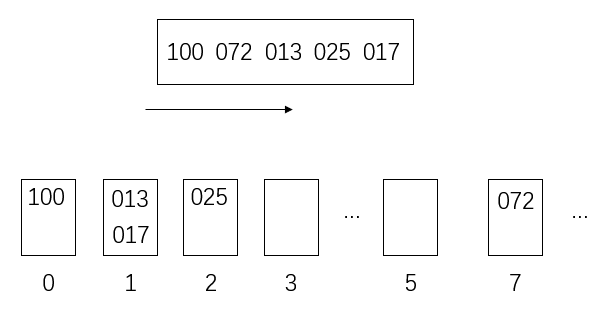
更新
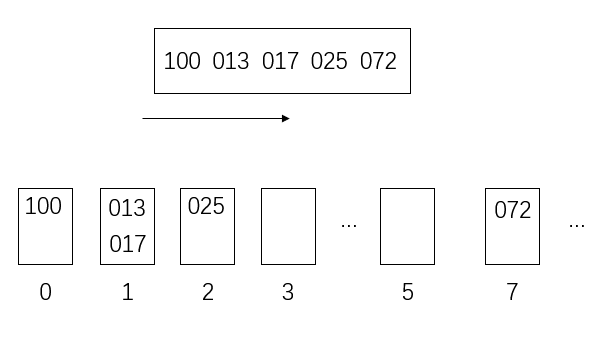
最后按百位数将数放入桶里
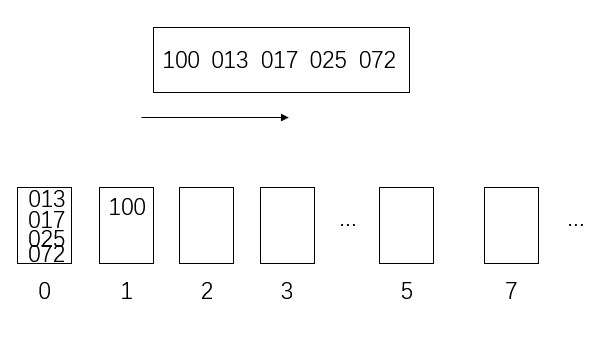
更新

排序结束
因为高位数是晚排序的,所以它优先级就会高,因此就会跑到最右边去
同理可区分十位和个位
代码实现讲解(2:11:25):https://www.bilibili.com/video/BV13g41157hK?p=5&spm_id_from=333.880.my_history.page.click
【算法day4】堆结构、堆排序、比较器以及桶排的更多相关文章
- python下实现二叉堆以及堆排序
python下实现二叉堆以及堆排序 堆是一种特殊的树形结构, 堆中的数据存储满足一定的堆序.堆排序是一种选择排序, 其算法复杂度, 时间复杂度相对于其他的排序算法都有很大的优势. 堆分为大头堆和小头堆 ...
- PHP面试:说下什么是堆和堆排序?
堆是什么? 堆是基于树抽象数据类型的一种特殊的数据结构,用于许多算法和数据结构中.一个常见的例子就是优先队列,还有排序算法之一的堆排序.这篇文章我们将讨论堆的属性.不同类型的堆以及堆的常见操作.另外我 ...
- Java实现的二叉堆以及堆排序详解
一.前言 二叉堆是一个特殊的堆,其本质是一棵完全二叉树,可用数组来存储数据,如果根节点在数组的下标位置为1,那么当前节点n的左子节点为2n,有子节点在数组中的下标位置为2n+1.二叉堆类型分为最大堆( ...
- 使用加强堆结构解决topK问题
作者:Grey 原文地址: 使用加强堆结构解决topK问题 题目描述 LintCode 550 · Top K Frequent Words II 思路 由于要统计每个字符串的次数,以及字典序,所以, ...
- 堆结构的优秀实现类----PriorityQueue优先队列
之前的文章中,我们有介绍过动态数组ArrayList,双向队列LinkedList,键值对集合HashMap,树集TreeMap.他们都各自有各自的优点,ArrayList动态扩容,数组实现查询非常快 ...
- 『Python CoolBook:heapq』数据结构和算法_heapq堆队列算法&容器排序
一.heapq堆队列算法模块 本模块实现了堆队列算法,也叫作优先级队列算法.堆队列是一棵二叉树,并且拥有这样特点,它的父节点的值小于等于任何它的子节点的值. 本模块实际上实现了一系列操作容器的方法,使 ...
- 排序算法<No.5>【堆排序】
算法,是系统软件开发,甚至是搞软件的技术人士的核心竞争力,这一点,我坚信不疑.践行算法实践,已经有一段时间没有practise了,今天来一个相对麻烦点的,堆排序. 1. 什么是堆(Heap) 这里说的 ...
- 堆与堆排序/Heap&Heap sort
最近在自学算法导论,看到堆排序这一章,来做一下笔记.堆排序是一种时间复杂度为O(lgn)的原址排序算法.它使用了一种叫做堆的数据结构.堆排序具有空间原址性,即指任何时候都需要常数个额外的元素空间存储临 ...
- java实现堆结构
一.前言 之前用java实现堆结构,一直用的优先队列,但是在实际的面试中,可能会要求用数组实现,所以还是用java老老实实的实现一遍堆结构吧. 二.概念 堆,有两种形式,一种是大根堆,另一种是小根堆. ...
- Libheap:一款用于分析Glibc堆结构的GDB调试工具
Libheap是一个用于在Linux平台上分析glibc堆结构的GDB调试脚本,使用Python语言编写. 安装 Glibc安装 尽管Libheap不要求glibc使用GDB调试支持和 ...
随机推荐
- [转帖]Python连接Oracle数据库进行数据处理操作
https://www.dgrt.cn/a/2259443.html?action=onClick 解决以下问题: Python连接Oracle数据库,并查询.提取Oracle数据库中数据? 通过Py ...
- AI五子棋 C++ 借助图形库raylib和raygui 设计模式思考过程和实现思路总结
转载请注明 原文链接 :https://www.cnblogs.com/Multya/p/17988499 repo: https://github.com/Satar07/AI_GoBang_Pub ...
- React中生命周期的讲解
什么是生命周期? 从出生到成长,最后到死亡,这个过程的时间可以理解为生命周期. React中的组件也是这么一个过程. React的生命周期分为三个阶段:挂载期(也叫实例化期).更新期(也叫存在期).卸 ...
- 【1】Anaconda安装超简洁教程,配置环境、创建虚拟环境、添加镜像源
相关文章: [1]Anaconda安装超简洁教程,瞬间学会! [2]Anaconda下:ipython文件的打开方式,Jupyter Notebook中运行.py文件,快速打开ipython文件的方法 ...
- 生活小技巧:Excel中PMT函数的使用
关于PMT函数,从百科中就可以搜到基本解释: PMT函数即年金函数,基于固定利率及等额分期付款方式,返回贷款的每期付款额. PMT(Rate, Nper, Pv, Fv, Type). 语法参数 ●R ...
- Linux-数据集 TPC-H、TPC-DS的导入和使用(MySQL)
一. TPC-H 数据集 1.数据集下载 TPC-H数据集: https://github.com/gregrahn/tpch-kit 可采用gcc下载或者直接下载zip包,然后解压即可. 具体使用方 ...
- NC24727 [USACO 2010 Feb G]Slowing down
题目链接 题目 题目描述 Every day each of Farmer John's N (1 <= N <= 100,000) cows conveniently numbered ...
- 轻松玩转makefile | 函数的使用
前言 在上一篇文章中,尽管使用了变量和模式,但还是有不够好的地方,在Makefile中要指明每一个源文件,我们接下来利用函数对其进行优化,并介绍其他常用的一些函数. 依旧是以fun.c ,main.c ...
- 快速傅里叶变换(FFT)和小波分析在信号处理上的应用
1前言 1.1傅里叶变换 函数f(t)为一元连续函数,其傅里叶变换定义为: F(w)的傅里叶逆变换定义为: 其中,i为虚数单位.由欧拉公式: 任意绝对可积的连续函数f(t),都可以用三角函数表示,由于 ...
- 【framework】应用进程启动流程
1 前言 Activity启动流程 中介绍了从点击桌面上应用快捷方式到 Activity 的 onCreate() 方法调用流程,本将介绍应用进程的启动流程.由于应用进程启动流程复杂,本文按进程将其拆 ...