Python 数据分析5
数据规整化
清理
转换
合并
重塑
数据库风格的DataFrame合并
- pd.merge(df1, df2)
- # 默认会将重叠列的列名当作键,最好显式的指定下,另外merge默认是使用的inner join
- pd.merge(df1, df2, on='key')
- pd.merge(df3, df4, left_on='lkey', right_on='rkey')
- # 如果两个对象的列名不同,需要分别指定,如上df3里面的是lkey,df4里面的是rkey
- pd.merge(df1, df2, how='outer')
- # how参数用来指定连接方式,总共是inner、left、right、outer四种方式
- pd.merge(df1, df2, on='key', how='left')
- pd.merge(df1, df2, how='inner')
- # 多对多合并如此简单
- pd.merge(left, right, on=['key1', 'key2'], how='outer')
- # 多个合并列的时候,列表
- pd.merge(left, right, on='key1')
- # 需要注意的是如果以key1进行连接,但是两个对象里面有其他相同列名的列存在, left会被表示成key_x,right会被表示成key_y
- pd.merge(left, right, on='key1', suffixes=('_left', '_right'))
- # 可以自定义的为左右设定后缀,这样相当于定制了列名
索引上的合并
- pd.merge(left1, right1, left_on='key', right_index=True)
- # 左边是的key,右边的是index
- pd.merge(left1, right1, left_on='key', right_index=True, how='outer')
- # 合并方式跟之前一样还是inner、outer、left、right
- pd.merge(lefth, righth, left_on=['key1', 'key2'], right_index=True)
- # 合并键是多个列用列表指明
- pd.merge(lefth, righth, left_on=['key1', 'key2'], right_index=True, how='outer')
- # 同样可以设置合并方式
- pd.merge(left2, right2, how='outer', left_index=True, right_index=True)
- # 两个合并对象都通过index连接
- left2.join(right2, how='outer')
- # dataframe里面提供了join方法,用来更方便的实现按索引合并,不过join支持的是左连接
- left1.join(right1, on='key')
- # 还支持参数dataframe的索引跟调用dataframe的列进行连接
- left2.join([right2, another])
- left2.join([right2, another], how='outer')
- # 对于简单的索引合并,你还可以向join传入一组DataFrame
轴向连接
刚刚上面讲了数据层的横向连接合并,现在是关于数据堆叠。NumPy的concatenation函数可以用NumPy数组来做:
- arr = np.arange(12).reshape((3, 4))
- np.concatenate([arr, arr], axis=1)
- # 默认axis=0,axis为1的时候就会变成横向的拼接
而在pandas里面提供了concat函数
- s1 = pd.Series([0, 1], index=['a', 'b'])
- s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
- s3 = pd.Series([5, 6], index=['f', 'g'])
- pd.concat([s1, s2, s3])
- # concat可以将值和索引粘合在一起

- pd.concat([s1, s2, s3], axis=1)
- # concat是在axis=0上工作的,最终产生一个新的Series。如果传入axis=1,则结果就会变成一个DataFrame(axis=1是列)
- pd.concat([s1, s2, s3], axis=1)
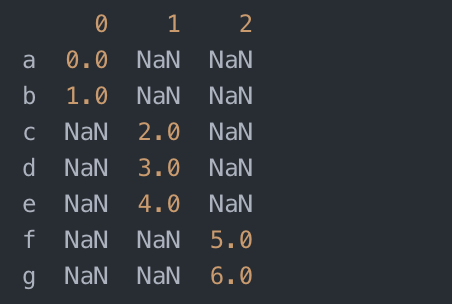
- pd.concat([s1, s4], axis=1, join='inner')
- # join='inner' 可以得到两个对象的交集
- pd.concat([s1, s4], axis=1, join_axes=[['a', 'c', 'b', 'e']])
- # 你可以通过join_axes指定要在其它轴上使用的索引
- # 会建立在另外一个索引上
- result = pd.concat([s1, s1, s3], keys=['one','two', 'three'])
- result.unstack()
- #有个问题,参与连接的片段在结果中区分不开。假设你想要在连接轴上创建一个层次化索引。使用keys参数即可达到这个目的
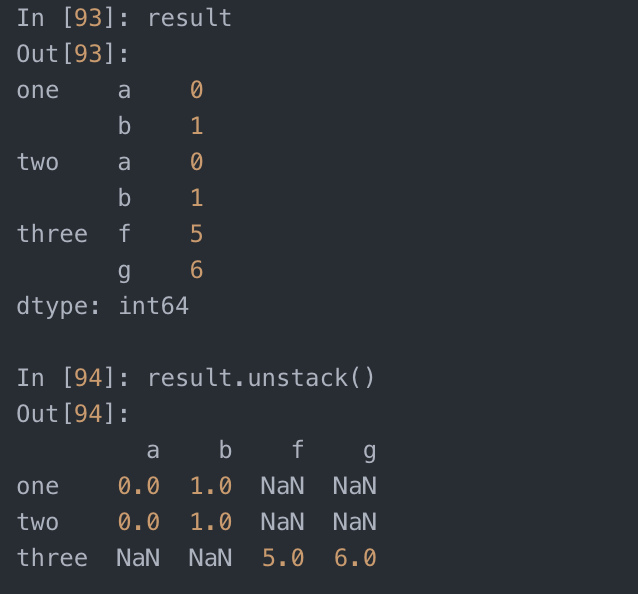
- pd.concat([s1, s2, s3], axis=1, keys=['one','two', 'three'])
- # 如果沿着axis=1对Series进行合并,则keys就会成为DataFrame的列头

- df1 = pd.DataFrame(np.arange(6).reshape(3, 2), index=['a', 'b', 'c'], columns=['one', 'two'])
- df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2), index=['a', 'c'],columns=['three', 'four'])
- pd.concat([df1, df2], axis=1, keys=['level1', 'level2'])
- # 在dataframe里面也是同理
- pd.concat({'level1': df1, 'level2': df2}, axis=1)
- # 如果传入的不是列表而是字典,则健值就变成keys
- pd.concat([df1, df2], axis=1, keys=['level1', 'level2'], names=['upper', 'lower'])
- 此外还有两个用于管理层次化索引创建方式的参数(参见表8-3)。举个例子,我们可以用names参数命名创建的轴级别
- df1 = pd.DataFrame(np.random.randn(3, 4), columns=['a', 'b', 'c', 'd'])
- df2 = pd.DataFrame(np.random.randn(2, 3), columns=['b', 'd', 'a'])
- pd.concat([df1, df2], ignore_index=True)
- # DataFrame的行索引不包含任何相关数据,在这种情况下,传入ignore_index=True即可

合并重复数据
还有一种数据组合问题不能用简单的合并(merge)或连接(concatenation)运算来处理。比如说,你可能有索引全部或部分重叠的两个数据集。举个有启发性的例子,我们使用NumPy的where函数,它表示一种等价于面向数组的if-else:
- a = pd.Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan], index=['f', 'e', 'd', 'c', 'b', 'a'])
- b = pd.Series(np.arange(len(a), dtype=np.float64), index=['f', 'e', 'd', 'c', 'b', 'a'])
- b[-1] = np.nan
- np.where(pd.isnull(a), b, a)
- # array([ 0. , 2.5, 2. , 3.5, 4.5, nan])
- where(if a then a else b)
- b[:-2].combine_first(a[2:])
- # 以b为标准,不存在的索引用a内的索引
- a NaN
- b 4.5
- c 3.0
- d 2.0
- e 1.0
- f 0.0
对于dataframe,也是同样的
- df1 = pd.DataFrame({'a': [1., np.nan, 5., np.nan], 'b': [np.nan, 2., np.nan, 6.], 'c': range(2, 18, 4)})
- df2 = pd.DataFrame({'a': [5., 4., np.nan, 3., 7.], 'b': [np.nan, 3., 4., 6., 8.]})
- df1.combine_first(df2)
重塑层次化索引
- stack:将数据的列“旋转”为行。
- unstack:将数据的行“旋转”为列。
- data = pd.DataFrame(np.arange(6).reshape((2, 3)), index=pd.Index(['Ohio','Colorado'], name='state'),columns=pd.Index(['one', 'two', 'three'],name='number'))
- result = data.stack()
- # 对该数据使用stack方法即可将列转换为行,得到一个Series
- result.unstack()
- # 对于一个层次化索引的Series,你可以用unstack将其重排为一个DataFrame
- result.unstack(0)
- result.unstack('state')
- # 默认情况下,unstack操作的是最内层(stack也是如此)。传入分层级别的编号或名称即可对其它级别进行unstack操作
- s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd'])
- s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e'])
- data2 = pd.concat([s1, s2], keys=['one', 'two'])
- data2.unstack()
- # 如果不是所有的级别值都能在各分组中找到的话,则unstack操作可能会引入缺失数据
- data2.unstack().stack()
- # stack默认会滤除缺失数据,因此该运算是可逆的
- data2.unstack().stack(dropna=False)
- # 可以通过参数来取消滤缺失数据
- df = pd.DataFrame({'left': result, 'right': result + 5}, columns=pd.Index(['left', 'right'], name='side'))
- df.unstack('state')
- # 在对DataFrame进行unstack操作时,作为旋转轴的级别将会成为结果中的最低级别
- df.unstack('state').stack('side')
- # 当调用stack,我们可以指明轴的名字
'长格式'旋转为'宽格式'
- pivoted = data.pivot('date', 'item', 'value')
- # pivot内(行索引, 列索引, 值)
- pivoted = data.pivot('date', 'item')
- #如果有两个同时需要重塑的数据列,忽略最后一个参数,得到的DataFrame就会带有层次化的列
- unstacked = ldata.set_index(['date', 'item']).unstack('item')
- # pivot其实就是用set_index创建层次化索引,再用unstack重塑
将'宽格式'旋转为'长格式'
旋转DataFrame的逆运算是pandas.melt。它不是将一列转换到多个新的DataFrame,而是合并多个列成为一个,产生一个比输入长的DataFrame
- df = pd.DataFrame({'key': ['foo', 'bar', 'baz'], 'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
- melted = pd.melt(df, ['key'])
- # key列可能是分组指标,其它的列是数据值。当使用pandas.melt,我们必须指明哪些列是分组指标。

- reshaped = melted.pivot('key', 'variable', 'value')
- # 使用pivot,可以重塑回原来的样子
- reshaped.reset_index()
- # 因为pivot的结果从列创建了一个索引,用作行标签,我们可以使用reset_index将数据移回列
- pd.melt(df, id_vars=['key'], value_vars=['A', 'B'])
- # 还可以指定列的子集,作为值的列
- pd.melt(df, value_vars=['A', 'B', 'C'])
- pd.melt(df, value_vars=['key', 'A', 'B'])
- # pandas.melt也可以不用分组指标
移除重复数据
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行(前面出现过的行)
- data = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'], 'k2': [1, 1, 2, 3, 3, 4, 4]})
- data.duplicated()
- data.drop_duplicates()
- # drop_duplicates重复的列移除掉,返回dataframe,移除的列是后出现的重复列,即上面的值为True的
这两个方法默认会判断全部列,你也可以指定部分列进行重复项判断。假设我们还有一列值,且只希望根据k1列过滤重复项
- data['v1'] = range(7)
- data.drop_duplicates(['k1'])
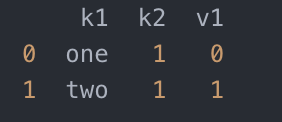
- data.drop_duplicates(['k1', 'k2'], keep='last')
- # duplicated和drop_duplicates默认保留的是第一个出现的值组合。传入keep='last'则保留最后一个
利用函数或映射进行数据转换
- data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon','Pastrami', 'corned beef', 'Bacon','pastrami', 'honey ham', 'nova lox']
- ,'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
假设你想要添加一列表示该肉类食物来源的动物类型。我们先编写一个不同肉类到动物的映射:
- meat_to_animal = {
- 'bacon': 'pig',
- 'pulled pork': 'pig',
- 'pastrami': 'cow',
- 'corned beef': 'cow',
- 'honey ham': 'pig',
- 'nova lox': 'salmon'
- }
Series的map方法可以接受一个函数或含有映射关系的字典型对象,但是这里有一个小问题,即有些肉类的首字母大写了,而另一些则没有。因此,我们还需要使用Series的str.lower方法,将各个值转换为小写
- data['animal'] = data['food'].str.lower().map(meat_to_animal)
也可以传入一个能够完成全部这些工作的函数
- data['food'].map(lambda x: meat_to_animal[x.lower()])
替换值
- data = pd.Series([1., -999., 2., -999., -1000., 3.])
- data.replace(-999, np.nan)
- # 将-999替换成NA值
- data.replace([-999, -1000], np.nan)
- # 将多个值转换成NA值
- data.replace([-999, -1000], [np.nan, 0])
- #要让每个值有不同的替换值,可以传递一个替换列表
- data.replace({-999: np.nan, -1000: 0})
- # 传入的参数也可以是字典
笔记:data.replace方法与data.str.replace不同,后者做的是字符串的元素级替换。
重命名轴索引
- data = pd.DataFrame(np.arange(12).reshape((3, 4)), index=['Ohio', 'Colorado', 'New York'], columns=['one', 'two', 'three', 'four'])
- transform = lambda x: x[:4].upper()
- data.index.map(transform)
- data.index = data.index.map(transform) # 修改index
如果想要创建数据集的转换版(而不是修改原始数据),比较实用的方法是rename
- data.rename(index=str.title, columns=str.upper)
rename可以结合字典型对象实现对部分轴标签的更新:
- data.rename(index={'OHIO': 'INDIANA'}, columns={'three': 'peekaboo'})
rename可以实现复制DataFrame并对其索引和列标签进行赋值。如果希望就地修改某个数据集,传入inplace=True即可
- data.rename(index={'OHIO': 'INDIANA'}, inplace=True)
离散化和面元划分
为了便于分析,连续数据常常被离散化或拆分为面元。
- ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
- bins = [18, 25, 35, 60, 100]
- cats = pd.cut(ages, bins)
- # 将age列表数据划分到面元,相当于归类到区间

- cats.codes
- # array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)
- cats.categories
- # IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]], closed='right', dtype='interval[int64]')
- pd.value_counts(cats)

跟“区间”的数学符号一样,圆括号表示开端,而方括号则表示闭端(包括)。哪边是闭端可以通过right=False进行修改
- cats = pd.cut(ages, bins, right=False)

你可 以通过传递一个列表或数组到labels,设置自己的面元名称:
- group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
- pd.cut(ages, bins, labels=group_names)
如果向cut传入的是面元的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元。下面这个例子中,我们将一些均匀分布的数据分成四组:
- data = np.random.rand(20)
- pd.cut(data, 4, precision=2)
- # 选项precision=2,限定小数只有两位。
qcut是一个非常类似于cut的函数,它可以根据样本分位数对数据进行面元划分。根据数据的分布情况,cut可能无法使各个面元中含有相同数量的数据点。而qcut由于使用的是样本分位数,因此可以得到大小基本相等的面元:
- data = np.random.randn(1000)
- cats = pd.qcut(data, 4)
- pd.value_counts(cats)
- # 可以发现四个区间是一样大的都是250个元素
与cut类似,你也可以传递自定义的分位数(0到1之间的数值,包含端点):
- pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
Python 数据分析5的更多相关文章
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- 【搬砖】【Python数据分析】Pycharm中plot绘图不能显示出来
最近在看<Python数据分析>这本书,而自己写代码一直用的是Pycharm,在练习的时候就碰到了plot()绘图不能显示出来的问题.网上翻了一下找到知乎上一篇回答,试了一下好像不行,而且 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据分析(二): Numpy技巧 (1/4)
In [1]: import numpy numpy.__version__ Out[1]: '1.13.1' In [2]: import numpy as np
- Python数据分析(二): Numpy技巧 (2/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- Python数据分析(二): Numpy技巧 (3/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- Python数据分析(二): Numpy技巧 (4/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 第一部分: ht ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
随机推荐
- day 21 垃圾回收机制、标记删除及分代回收
垃圾回收机制 # 不能被程序访问到的数据,就称之为垃圾 引用计数 # 引用计数是用来记录值的内存地址被记录的次数的# 每一次对值地址的引用都可以使该值的引用计数 +1# 每一次对值地址的释放都可以使 ...
- vue 前端将时间戳格式化
转自西风XF : https://blog.csdn.net/qq_36242361/article/details/79143050 后端传过来的时间数据是时间戳的形式,前端需要进行格式化 1. 新 ...
- VisualStudio 快捷键
ctrl + o : 打开当前文件所在文件目录 ctrl + 鼠标左键 : 转到方法或者字段定义
- JS学习笔记:(一)浏览器页面渲染机制
浏览器的内核主要分为渲染引擎和JS引擎.目前市面上常见的浏览器内核可以分为这四种:Trident(IE).Gecko(火狐).Blink(Chrome.Opera).Webkit(Safari).这里 ...
- 【MySQL 读书笔记】SQL 刷脏页可能造成数据库抖动
开始今天读书笔记之前我觉得需要回顾一下当我们在更新一条数据的时候做了什么. 因为 WAL 技术的存在,所以当我们执行一条更新语句的时候是先写日志,后写磁盘的.当我们在内存中写入了 redolog 之后 ...
- 获取SQL数据库中的数据库名、所有表名、所有字段名、列描述
1.获取所有数据库名: (1).Select Name FROM Master.dbo.SysDatabases orDER BY Name 2.获取所有表名: (1).Select Na ...
- iOS presentViewController 方法引起的问题
有个需求,在项目中随时使用 presentViewController来显示一个界面,比如弹窗提示或者人脸解锁,都是在任何情况都可能出现的. 在presentViewController 调用前,已经 ...
- Python 学习笔记 - 不断更新!
Python 学习笔记 太久不写python,已经忘记以前学习的时候遇到了那些坑坑洼洼的地方了,开个帖子来记录一下,以供日后查阅. 摘要:一些报错:为啥Python没有自增 ++ 和自减 --: 0x ...
- cas-5.3.x接入REST登录认证,移动端登录解决方案
一.部署cas-server及cas-sample-java-webapp 1.克隆cas-overlay-template项目并切换到5.3分支 git clone git@github.com:a ...
- Codeforces Round #549 (Div. 1)
今天试图用typora写题解 真开心 参考 你会发现有很多都是参考的..zblzbl Codeforces Round #549 (Div. 1) 最近脑子不行啦 需要cf来缓解一下 A. The B ...