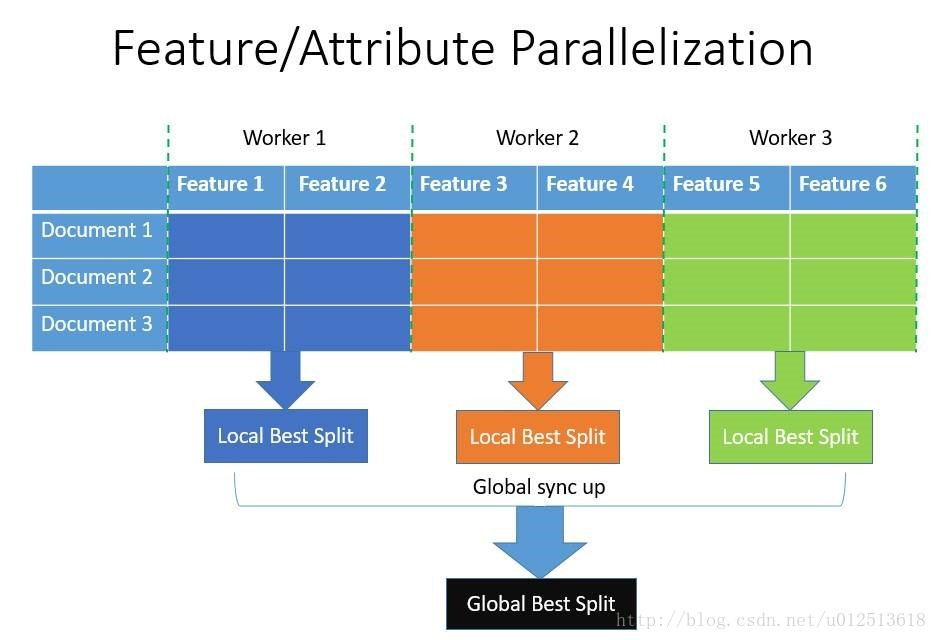
LightGBM总结
一、LightGBM介绍
LightGBM是一个梯度Boosting框架,使用基于决策树的学习算法。它可以说是分布式的,高效的,有以下优势:
1)更快的训练效率
2)低内存使用
3)更高的准确率
4)支持并行化学习
5)可以处理大规模数据
与常见的机器学习算法对比,速度是非常快的
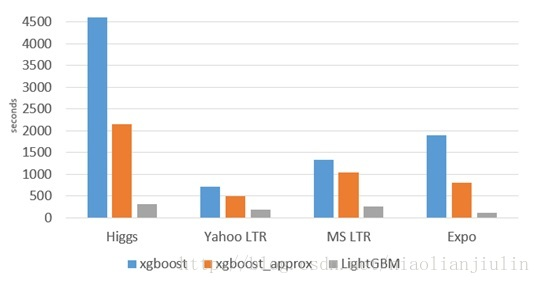
二、XGboost缺点
在讨论LightGBM时,不可避免的会提到XGboost,关于XGboost可以参考此博文
关于XGboost的不足之处主要有:
1)每次迭代训练时需要读取整个数据集,耗时耗内存;
2)使用Basic Exact Greedy Algorithm计算最佳分裂节点时需要预先将特征的取值进行排序,排序之后为了保存排序的结果,费时又费内存;
3)计算分裂节点时需要遍历每一个候选节点,然后计算分裂之后的信息增益,费时;
4)生成决策树是level-wise级别的,也就是预先设置好树的深度之后,每一颗树都需要生长到设置的那个深度,这样有些树在某一次分裂之后效果甚至没有提升但仍然会继续划分树枝,然后再次划分....之后就是无用功了,耗时。
三、LightGBM原理
为了避免上述XGB的缺陷,并且能够在不损害准确率的条件下加快GBDT模型的训练速度,lightGBM在传统的GBDT算法上加了两个技术:
- 单边梯度采样 Gradient-based One-Side Sampling (GOSS);
- 互斥稀疏特征绑定 Exclusive Feature Bundling (EFB)
使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGB遍历所有特征值节省了不少开销;使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。
1. Gradient-based One-Side Sampling
GOSS是一个样本实例的采样算法,目的是丢弃一些对计算信息增益没有帮助的实例,留下有帮助的。可以看到具有较大梯度的数据对计算信息增益的贡献比较大(参考论文Greedy Function Approximation: A Gradient Boosting Machine的证明),因此GOSS在进行数据采样的时候只保留了梯度较大的数据,但是如果直接将所有梯度较小的数据都丢弃掉势必会影响数据的总体分布,因此GOSS首先将要进行分裂的特征的所有取值按照绝对值大小降序排序(XGB一样也进行了排序,但是lgb不用保存排序后的结果),选取绝对值最大的a*100%个数据,然后在剩下的较小梯度数据中随机选择b*100%个数据,并且将这b%个数据乘以一个常数 %,最后使用这(a+b)%个数据来计算信息增益。下图是GOSS的具体算法:

从算法上看,在d次迭代中lightGBM只使用了useSet个实例进行训练,每一轮迭代都学习了一个弱学习器,并且在进行下一轮学习时,前面的每一轮所学习的弱学习器都将影响该轮的学习。
2. Exclusive Feature Bundling
高维度的数据通常是非常稀疏的,这样的特性为特征的相互之间结合提供了便利。通过将一些特征进行融合绑定在一起,可以使特征数量大大减少,这样在进行histogram building时时间复杂度从O(#data * #feature)变为O(#data * #bundle),这里#bundle远小于#feature。
那么将哪些特征绑定在一起呢?又要怎么绑定呢?
对于第一个问题,将相互独立的特征进行bunding是一个NP难问题,lightGBM将这个问题转化为图着色的问题来求解,将所有特征视为图G的一个顶点,将不是相互独立的特征用一条边连接起来,边的权重就是两个相连接的特征的总冲突值,这样需要绑定的特征就是在图着色问题中要涂上同一种颜色的那些点(特征)。
对于第二个问题,绑定几个特征在同一个bundle里需要保证绑定前的原始特征的值可以在bundle中识别,考虑到 histogram-based算法将连续的值保存为离散的bins,我们可以使得不同特征的值分到bundle中的不同bins中,这可以通过在特征值中加一个偏置常量来解决,比如,我们在bundle中绑定了两个特征A和B,A特征的原始取值为区间[0,10),B特征的原始取值为区间[0,20),我们可以在B特征的取值上加一个偏置常量10,将其取值范围变为[10,30),这样就可以放心的融合特征A和B了,因为在树模型中对于每一个特征都会计算分裂节点的,也就是通过将他们的取值范围限定在不同的bins中,在分裂时可以将不同特征很好的分裂到树的不同分支中去。

3.直方图算法(Histogram-based Algorithm)
Histogram-based 算法不是lightGBM所特有的,其他GBDT算法也采用了这样的算法,XGB也有,但是它和lightGBM有所不同,这里介绍一下lgb的Histogram-based 算法。

Histogram-based 算法将连续的特征映射到离散的buckets中,组成一个个的bins,然后使用这些bins建立直方图。简而言之就是将连续变量离散化。
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。在Xgboost中需要遍历所有离散化的值,而在这里只要遍历k个直方图的值。

使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值。
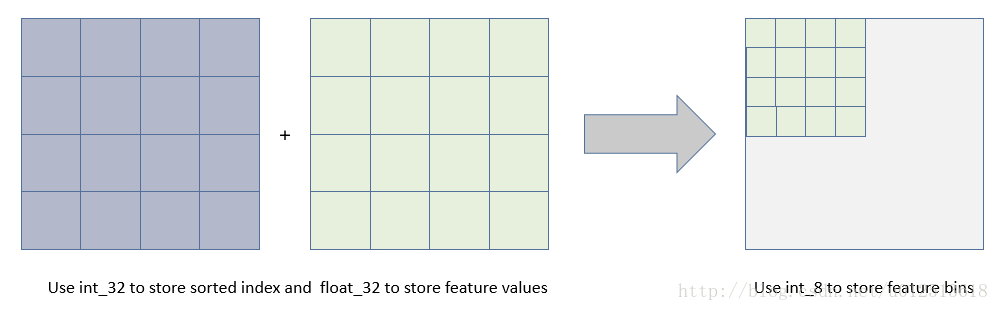
然后在计算上的代价也大幅降低,XGBoost预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data * #feature) 优化到O(k* #features)。
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
LightGBM的直方图做差加速
一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后(父节点在上一轮就已经计算出来了),可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

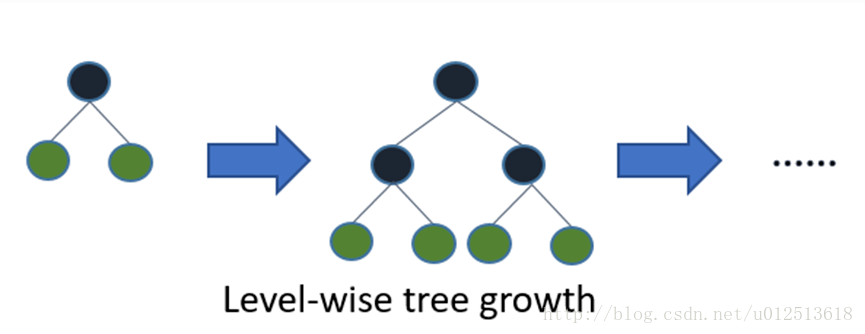
4.带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
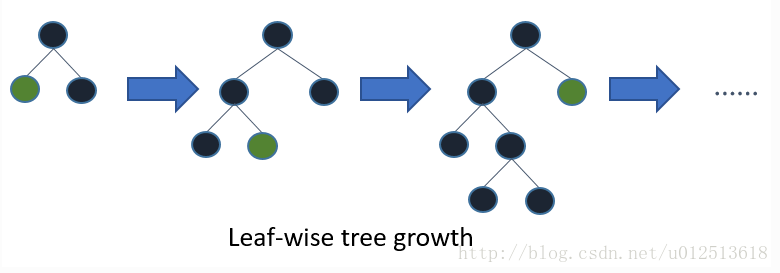
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。【lgb在生成树的过程中不需要达到设置的树的深度只要树的叶子数量达到了设置的个数之后就终止当前树的生长,这样就不会为了达到深度而去生长一些对任务贡献不大的树叶。这也是lightGBM训练速度快的一个原因。】因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
5.直接支持类别特征(即不需要做one-hot编码)
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的one-hot编码特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的one-hot编码展开。并在决策树算法上增加了类别特征的决策规则。在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。
6.直接支持高效并行
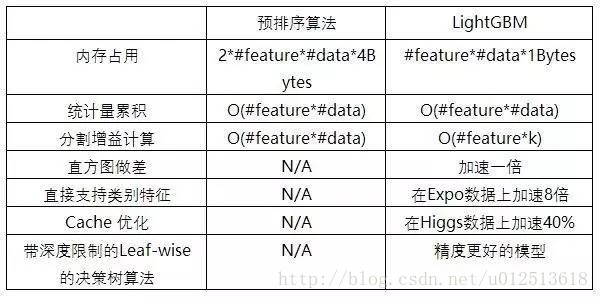
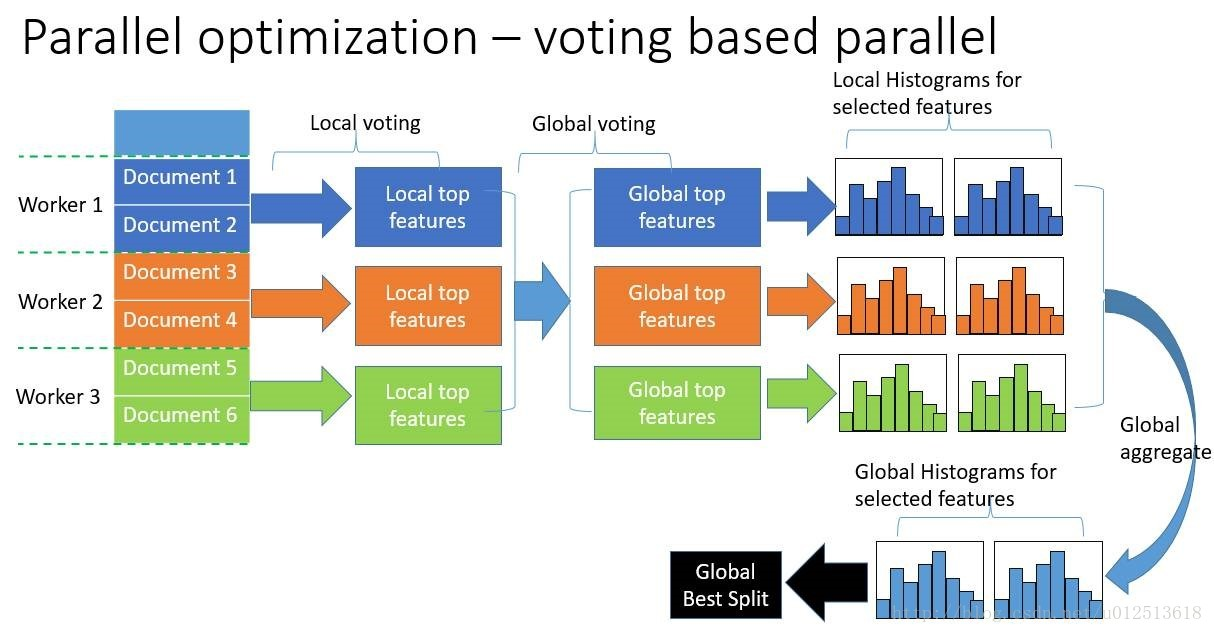
LightGBM还具有支持高效并行的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。
1)特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
2)数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
LightGBM针对这两种并行方法都做了优化,在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;在数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。
四、LightGBM参数调优
下面几张表为重要参数的含义和如何应用
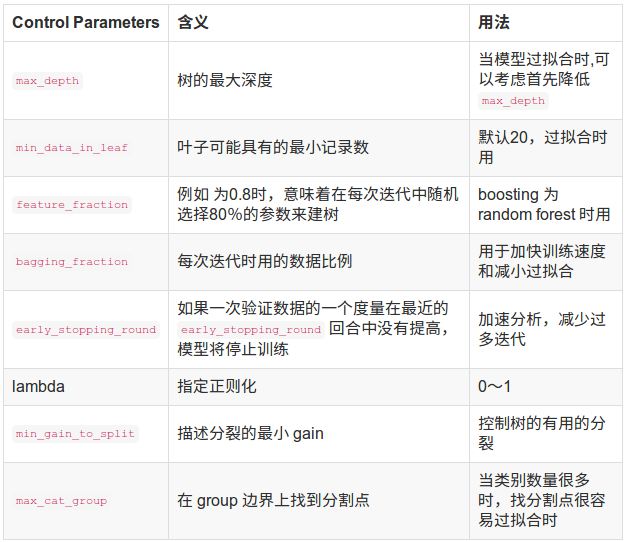


接下来是调参
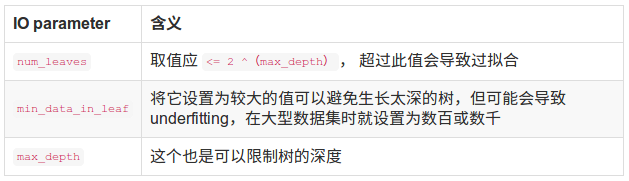
下表对应了Faster Spread,better accuracy,over-fitting三种目的时,可以调整的参数

参考文献:
LightGBM总结的更多相关文章
- LightGBM中GBDT的实现
现在LightGBM开源了,这里将之前的一个文档发布出来供大家参考,帮助更快理解LightGBM的实现,整体思路应该是类似的. LightGBM优雅,快速,效果好,希望LightGBM越来越好:) L ...
- XGBoost、LightGBM的详细对比介绍
sklearn集成方法 集成方法的目的是结合一些基于某些算法训练得到的基学习器来改进其泛化能力和鲁棒性(相对单个的基学习器而言)主流的两种做法分别是: bagging 基本思想 独立的训练一些基学习器 ...
- 安装 LightGBM 包的过程
conda install cmake conda install gcc git clone --recursive https://github.com/Microsoft/LightGBM ; ...
- 工业级GBDT算法︱微软开源 的LightGBM(R包正在开发....)
看完一篇介绍文章后,第一个直觉就是这算法已经配得上工业级属性.日前看到微软已经公开了这一算法,而且已经发开python版本,本人觉得等hadoop+Spark这些平台配齐之后,就可以大规模宣传啦~如果 ...
- LightGBM大战XGBoost,谁将夺得桂冠?
引 言 如果你是一个机器学习社区的活跃成员,你一定知道 提升机器(Boosting Machine)以及它们的能力.提升机器从AdaBoost发展到目前最流行的XGBoost.XGBoost实际上已经 ...
- Stacking:Catboost、Xgboost、LightGBM、Adaboost、RF etc
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- LightGBM算法(转载)
原文:https://blog.csdn.net/niaolianjiulin/article/details/76584785 前者的含义是轻量级,GBM:梯度上升机. 相较于xgboost: 更快 ...
- 自动调参库hyperopt+lightgbm 调参demo
在此之前,调参要么网格调参,要么随机调参,要么肉眼调参.虽然调参到一定程度,进步有限,但仍然很耗精力. 自动调参库hyperopt可用tpe算法自动调参,实测强于随机调参. hyperopt 需要自己 ...
- Lightgbm 随笔
lightGBM LightGBM 是一个梯度 boosting 框架,使用基于学习算法的决策树.它可以说是分布式的,高效的,有以下优势: 更快的训练效率 低内存使用 更高的准确率 支持并行化学习 可 ...
随机推荐
- [转]国家税务总局:个税专项附加扣除APP正式启用!(附操作指南)
https://wallstreetcn.com/articles/3462504 12月31日国家税务总局官网消息,个人所得税专项附加扣除政策将于2019年1月1日起实施.2018年12月31日,由 ...
- Go的sort接口实现
package main import ( "fmt" "sort" "time" ) type Track struct { Title ...
- Scala模式匹配| 隐式转换
1. 模式匹配 Scala中的模式匹配类似于Java中的switch语法,但是更加强大.模式匹配语法中,采用match关键字声明,每个分支采用case关键字进行声明,当需要匹配时,会从第一个case分 ...
- Oracle做insert或者update时未提交事务导致表锁定解决办法
//查看被锁定表有几个 select object_name,machine,s.sid,s.serial# from v$locked_object l,dba_objects o ,v$sessi ...
- 程序猿最浪漫的表白,肯定会得到你的她——Jason niu 原文来自GitHub,本人已部分修改
程序猿最浪漫的表白,肯定会得到你的她——Jason niu 原文来自GitHub,主页本人已部分修改,感谢程序猿大神wuxia2001和hackerzhou的开源,感谢这两位大神! 视频结果展示 ...
- Java 中的内部类
前言 在第一次把Java 编程思想中的内部类这一章撸完后,有点印象.大概知道了什么时内部类,局部内部类,匿名内部类,嵌套内部类.随着时间的推移,自己慢慢的就忘记了,总感觉自己思考的东西不多,于是 看了 ...
- pandas 必背函数操作
1.五个常用属性 index,columns,shape,values,dtypes2.常用函数:set_index,reset_index,del df['column_name'],pd.read ...
- C#からネイティブDLLを呼び出す場合のVSからのデバッグのジレンマを解決する
「C#を使う最大のメリットって.やっぱり.Visual Studioですよね!」って自信を持って言いたいですね. という心境ではあるんですが.私の仕事はどっちかというとC++よりなので.どうしても.D ...
- mysql 使用教程 入门
转载 http://www.cnblogs.com/mr-wid/archive/2013/05/09/3068229.html MySQL有三大类数据类型, 分别为数字.日期\时间.字符串, 这三大 ...
- mysql 连接超慢
cd /etc/mysql/mysql.conf.dsudo vi mysqld.cnf加上最后一句skip-name-resolve, 如下:[mysqld]## * Basic Settings# ...