Pytorch多GPU训练
Pytorch多GPU训练
临近放假, 服务器上的GPU好多空闲, 博主顺便研究了一下如何用多卡同时训练
原理
多卡训练的基本过程
- 首先把模型加载到一个主设备
- 把模型只读复制到多个设备
- 把大的batch数据也等分到不同的设备
- 最后将所有设备计算得到的梯度合并更新主设备上的模型参数
代码实现(以Minist为例)
#!/usr/bin/python3
# coding: utf-8
import torch
from torchvision import datasets, transforms
import torchvision
from tqdm import tqdm
device_ids = [3, 4, 6, 7]
BATCH_SIZE = 64
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])
data_train = datasets.MNIST(root = "./data/",
transform=transform,
train = True,
download = True)
data_test = datasets.MNIST(root="./data/",
transform = transform,
train = False)
data_loader_train = torch.utils.data.DataLoader(dataset=data_train,
# 这里注意batch size要对应放大倍数
batch_size = BATCH_SIZE * len(device_ids),
shuffle = True,
num_workers=2)
data_loader_test = torch.utils.data.DataLoader(dataset=data_test,
batch_size = BATCH_SIZE * len(device_ids),
shuffle = True,
num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2, kernel_size=2),
)
self.dense = torch.nn.Sequential(
torch.nn.Linear(14 * 14 * 128, 1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 10)
)
def forward(self, x):
x = self.conv1(x)
x = x.view(-1, 14 * 14 * 128)
x = self.dense(x)
return x
model = Model()
model = torch.nn.DataParallel(model, device_ids=device_ids) # 声明所有可用设备
model = model.cuda(device=device_ids[0]) # 模型放在主设备
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
n_epochs = 50
for epoch in range(n_epochs):
running_loss = 0.0
running_correct = 0
print("Epoch {}/{}".format(epoch, n_epochs))
print("-"*10)
for data in tqdm(data_loader_train):
X_train, y_train = data
# 注意数据也是放在主设备
X_train, y_train = X_train.cuda(device=device_ids[0]), y_train.cuda(device=device_ids[0])
outputs = model(X_train)
_,pred = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss = cost(outputs, y_train)
loss.backward()
optimizer.step()
running_loss += loss.data.item()
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0
for data in data_loader_test:
X_test, y_test = data
X_test, y_test = X_test.cuda(device=device_ids[0]), y_test.cuda(device=device_ids[0])
outputs = model(X_test)
_, pred = torch.max(outputs.data, 1)
testing_correct += torch.sum(pred == y_test.data)
print("Loss is:{:.4f}, Train Accuracy is:{:.4f}%, Test Accuracy is:{:.4f}".format(running_loss/len(data_train),
100*running_correct/len(data_train),
100*testing_correct/len(data_test)))
torch.save(model.state_dict(), "model_parameter.pkl")
结果分析
可以通过nvidia-smi清楚地看到3, 4, 6, 7卡在计算/usr/bin/python3进程(进程号都为34930)
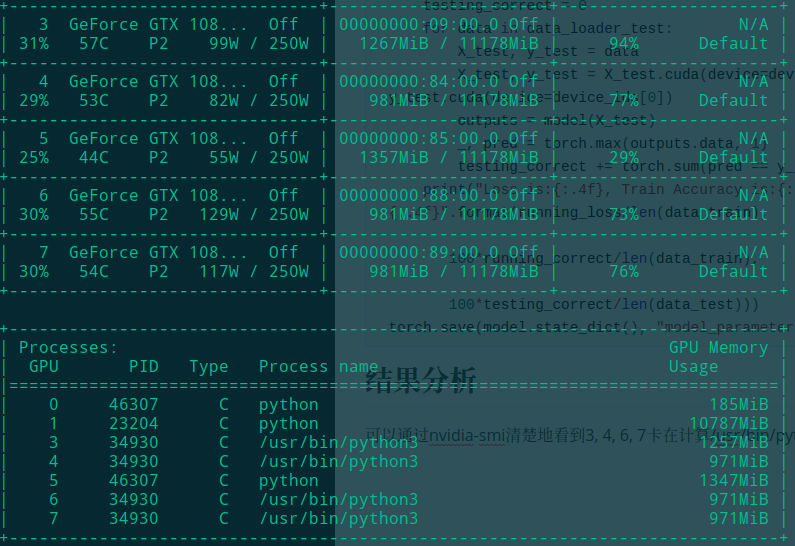
从实际加速效果来看, 由于minist是小数据集, 可能调度带来的overhead反而比计算的开销大, 因此加速不明显. 但是到大数据集上训练时, 多卡的优势就会体现出来了
Pytorch多GPU训练的更多相关文章
- pytorch 多GPU训练总结(DataParallel的使用)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/weixin_40087578/artic ...
- pytorch 指定GPU训练
# 1: torch.cuda.set_device(1) # 2: device = torch.device("cuda:1") # 3:(官方推荐)import os os. ...
- pytorch 多GPU训练过程中出现ap=0情况
原因可能是pytorch 自带的BN bug:安装nvidia apex 可以解决: $ git clone https://github.com/NVIDIA/apex $ cd apex $ pi ...
- Pytorch中多GPU训练指北
前言 在数据越来越多的时代,随着模型规模参数的增多,以及数据量的不断提升,使用多GPU去训练是不可避免的事情.Pytorch在0.4.0及以后的版本中已经提供了多GPU训练的方式,本文简单讲解下使用P ...
- PyTorch Tutorials 4 训练一个分类器
%matplotlib inline 训练一个分类器 上一讲中已经看到如何去定义一个神经网络,计算损失值和更新网络的权重. 你现在可能在想下一步. 关于数据? 一般情况下处理图像.文本.音频和视频数据 ...
- Pytorch使用分布式训练,单机多卡
pytorch的并行分为模型并行.数据并行 左侧模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练. 右侧数据并行:多个显卡同时采用数据训练网络的副本. 一.模型并行 二.数据并行 数 ...
- MinkowskiEngine多GPU训练
MinkowskiEngine多GPU训练 目前,MinkowskiEngine通过数据并行化支持Multi-GPU训练.在数据并行化中,有一组微型批处理,这些微型批处理将被送到到网络的一组副本中. ...
- 使用Deeplearning4j进行GPU训练时,出错的解决方法
一.问题 使用deeplearning4j进行GPU训练时,可能会出现java.lang.UnsatisfiedLinkError: no jnicudnn in java.library.path错 ...
- tensorflow使用多个gpu训练
关于多gpu训练,tf并没有给太多的学习资料,比较官方的只有:tensorflow-models/tutorials/image/cifar10/cifar10_multi_gpu_train.py ...
随机推荐
- spring kafka生产、消费消息
参考网址: https://blog.csdn.net/lansetiankong12/article/details/54946641 1.新建Maven项目-KafkaMaven ->点击n ...
- 非常好用的sersync同步工具
作者:邓聪聪 常用同步工具sync的进阶软件 服务端的配置: uid = rsync gid = rsync port = use chroot = on max connections = time ...
- COGS2187 [HZOI 2015] 帕秋莉的超级多项式
什么都别说了,咱心态已经炸了... question 题目戳这里的说... 其实就是叫你求下面这个式子的导函数: noteskey 其实是道板子题呢~ 刚好给我们弄个多项式合集的说... 各种板子粘贴 ...
- C++入门篇十
静态成员变量:可以共享数据,类内声明,类外初始化(实现) // 静态成员变量.cpp : 此文件包含 "main" 函数.程序执行将在此处开始并结束. // #include &q ...
- eclipse导入maven时,html页面引入js的路径出现红色波浪线
用eclipse导入一个springboot项目时,html页面引入js以及css时出现如下图所示情况,html页面用了 thymeleaf模板引擎.另外js文件与css文件路径也是正确无误的. 原来 ...
- JAVA第二次实训作业
1.一维数组的创建和遍历. 声明并创建存放4个人考试成绩的一维数组,并使用for循环遍历数组并打印分数. 要求: 首先按“顺序”遍历,即打印顺序为:从第一个人到第四个人: 然后按“逆序”遍历,即打印顺 ...
- datatable 给某一列添加title属性
简单描述:采用datatable拼接的表格,没有title属性,嗯就是这个情况,直接上代码 代码: //js代码$("#toAdd").click("click" ...
- ueditor内容带格式回显(html字符串回显)
简单描述:项目里有个地方用到啦ueditor,用来输入XX描述就用电影film代替,保存后,获取到ueditor里的内容(html字符串),保存到数据库. 吐槽:回显的时候,无论怎么处置,就是死活不好 ...
- elemet-ui图标—特殊字符的unicode编码表
https://blog.csdn.net/lurr88/article/details/79754811
- echarts 自定义配置带单位的 tooltip 提示框方法 和 圆环数据 tooltip 过长超出屏幕
-------tip1-------- 在 tooltip 里边配置:拼接字符串: tooltip : { trigger: 'axis', formatter:function(params) { ...