Python面试题之Python中的lambda map filter reduce zip
当年龟叔想把上面列出来的这些都干掉。在 “All Things Pythonic: The fate of reduce() in Python 3000”这篇文章中,他给出了自己要移除lambda、map、filter和reduce的原因。当然,这事儿最后没成功。只有
reduce被挪到functools模块中去了。
lambda
lambda是匿名函数,也就是没有名字的函数。lambda的语法非常简单:

下面是一个lambda表达式的简单例子:
注意:我们可以把lambda表达式赋值给一个变量,然后通过这个变量来使用它。
>>> my_sum = lambda x, y: x+y
>>> my_sum(, )
下图是定义lambda表达式和定义一个普通函数的对比:

注意:
使用lambda表达式并不能提高代码的运行效率,它只能让你的代码看起来简洁一些。
map
map()接收两个参数func(函数)和seq(序列,例如list)。如下图:

map()将函数func应用于序列seq中的所有元素。在Python3之前,map()返回一个列表,列表中的每个元素都是将列表或元组“seq”中的相应元素传入函数func返回的结果。Python 3中map()返回一个迭代器。
因为map()需要一个函数作为参数,所以可以搭配lambda表达式很方便的实现各种需求:
- 例子1–将一个列表里面 的每个数字都加100:
>>> l = [, , , , ]
>>> list(map(lambda x:x+, l))
[, , , , ]
- 例子2–
使用map就相当于使用了一个for循环,我们完全可以自己定义一个my_map函数:
def my_map(func, seq):
result = []
for i in seq:
result.append(func(i))
return result
测试一下我们自己的my_map函数:
>>> def my_map(func, seq):
... result = []
... for i in seq:
... result.append(func(i))
... return result
...
>>> l = [, , , , ]
>>> list(my_map(lambda x:x+, l))
[, , , , ]
我们自定义的my_map函数的效果和内置的map函数一样。
当然在Python3中,map函数返回的是一个迭代器,所以我们也需要让我们的my_map函数返回一个迭代器:
def my_map(func, seq):
for i in seq:
yield func(i)
测试一下:
>>> def my_map(func, seq):
... for i in seq:
... yield func(i)
...
>>> l = [, , , , ]
>>> list(my_map(lambda x:x+, l))
[, , , , ]
与我们自己定义的my_map函数相比,由于map是内置的因此它始终可用,并且始终以相同的方式工作。它也具有一些性能优势,通常会比手动编写的for循环更快。当然内置的map还有一些高级用法:
例如,可以给map函数传入多个序列参数,它将并行的序列作为不同参数传入函数:
拿pow(arg1, arg2)函数举例,
>>> pow(, ) >>> pow(, ) >>> pow(, ) >>> list(map(pow, [, , ], [, , ]))
[, , ]
pow(arg1, arg2)函数接收两个参数arg1和arg2,map(pow, [2, 3, 4], [10, 11, 12])就会并行从[2, 3, 4]和[10, 11, 12]中取出元素,传入到pow中。
还有一个例子:
>>> from operator import add
>>> x = [, , ]
>>> y = [, , ]
>>> list(map(add, x, y))
[, , ]
调用map函数类似于列表推导式,但是列表推导式是对每个元素做表达式运算,而map对每个元素都会应用一次函数调用。也只有在map中使用内置函数时,才可能比列表推导式速度更快。
filter
filter函数和map函数一样也是接收两个参数func(函数)和seq(序列,如list),如下图:
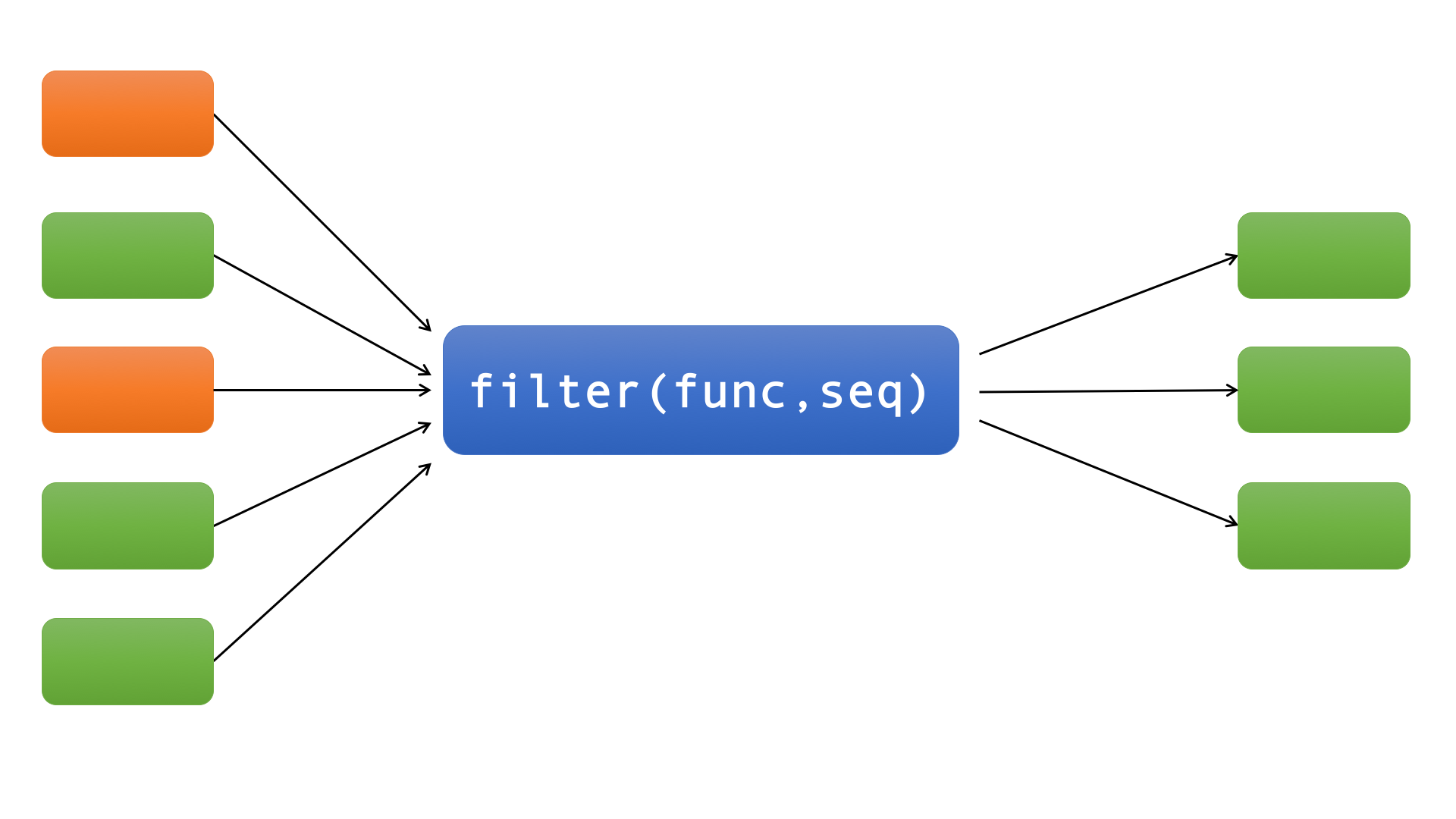
filter函数类似实现了一个过滤功能,它过滤序列中的所有元素,返回那些传入func后返回True的元素。也就是说filter函数的第一个参数func必须返回一个布尔值,即True或者False。
下面这个例子,是使用filter从一个列表中过滤出大于33的数:
>>> l = [, , , , , , ]
>>> list(filter(lambda x: x>, l))
[, ]
利用filter()还可以用来判断两个列表的交集:
>>> x = [, , , , ]
>>> y = [, , , , ]
>>> list(filter(lambda a: a in y, x))
[, , ]
reduce
注意:Python3中reduce移到了functools模块中,你可以用过from functools import reduce来使用它。
reduce同样是接收两个参数:func(函数)和seq(序列,如list),如下图:

reduce最后返回的不是一个迭代器,它返回一个值。
reduce首先将序列中的前两个元素,传入func中,再将得到的结果和第三个元素一起传入func,…,这样一直计算到最后,得到一个值,把它作为reduce的结果返回。
原理类似于下图:

看一下运行结果:
>>> from functools import reduce
>>> reduce(lambda x,y:x+y, [, , , ])
再来练习一下,使用reduce求1~100的和:
>>> from functools import reduce
>>> reduce(lambda x,y:x+y, range(, ))
三元运算
三元运算(三目运算)在Python中也叫条件表达式。三元运算的语法非常简单,主要是基于True/False的判断。如下图:

使用它就可以用简单的一行快速判断,而不再需要使用复杂的多行if语句。 大多数时候情况下使用三元运算能够让你的代码更清晰。
三元运算配合lambda表达式和reduce,求列表里面值最大的元素:
>>> from functools import reduce
>>> l = [, , , , , , ]
>>> reduce(lambda x,y: x if x > y else y, l)
再来一个,三元运算配合lambda表达式和map的例子:
将一个列表里面的奇数加100:
>>> l = [, , , , , , ]
>>> list(map(lambda x: x+ if x% else x, l))
[, , , , , , ]
zip
zip函数接收一个或多个可迭代对象作为参数,最后返回一个迭代器:
>>> x = ["a", "b", "c"]
>>> y = [, , ]
>>> a = list(zip(x, y)) # 合包
>>> a
[('a', ), ('b', ), ('c', )]
>>> b =list(zip(*a)) # 解包
>>> b
[('a', 'b', 'c'), (, , )]
zip(x, y) 会生成一个可返回元组 (m, n) 的迭代器,其中m来自x,n来自y。 一旦其中某个序列迭代结束,迭代就宣告结束。 因此迭代长度跟参数中最短的那个序列长度一致。
>>> x = [, , , , ]
>>> y = [, , , ]
>>> for m, n in zip(x, y):
... print(m, n)
...
如果上面不是你想要的效果,那么你还可以使用 itertools.zip_longest() 函数来代替这个例子中的zip。
>>> from itertools import zip_longest
>>> x = [, , , , ]
>>> y = [, , , ]
>>> for m, n in zip_longest(x, y):
... print(m, n)
... None
zip其他常见应用:
>>> keys = ["name", "age", "salary"]
>>> values = ["Andy", , ]
>>> d = dict(zip(keys, values))
>>> d
{'name': 'Andy', 'age': , 'salary': }
参考
Python面试题之Python中的lambda map filter reduce zip的更多相关文章
- python常用函数进阶(2)之map,filter,reduce,zip
Basic Python : Map, Filter, Reduce, Zip 1-Map() 1.1 Syntax # fun : a function applying to the iterab ...
- python中的内置函数lambda map filter reduce
p.p1 { margin: 0; font: 12px "Helvetica Neue" } p.p2 { margin: 0; font: 12px "Helveti ...
- lambda,map,filter,reduce
lambda 编程中提到的 lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数.返回一个函数对象. func = lambda x,y:x+y fu ...
- Python中map,filter,reduce,zip的应用
事例1: l=[('main', 'router_115.236.xx.xx', [{'abc': 1}, {'dfg': 1}]), ('main', 'router_183.61.xx.xx', ...
- 千万不要错过这几道Python面试题,Python面试题No16
第1题: python下多线程的限制以及多进程中传递参数的方式? python多线程有个全局解释器锁(global interpreter lock),简称GIL,这个GIL并不是python的特性, ...
- python 内置函数 map filter reduce lambda
map(函数名,可遍历迭代的对象) # 列组元素全加 10 # map(需要做什么的函数,遍历迭代对象)函数 map()遍历序列得到一个列表,列表的序号和个数和原来一样 l = [2,3,4,5,6, ...
- Python面试题整理-更新中
几个链接: 编程零基础应当如何开始学习 Python ? - 路人甲的回答 网易云课堂上有哪些值得推荐的 Python 教程? - 路人甲的回答 怎么用最短时间高效而踏实地学习 Python? - 路 ...
- Python面试题之Python面试题汇总
在这篇文章中: Python基础篇 1:为什么学习Python 2:通过什么途径学习Python 3:谈谈对Python和其他语言的区别 Python的优势: 4:简述解释型和编译型编程语言 5:Py ...
- python几个特别函数map filter reduce lambda
lambda函数也叫匿名函数,即,函数没有具体的名称.先来看一个最简单例子: def f(x): return x**2 print f(4) Python中使用lambda的话,写成这样 g = l ...
随机推荐
- Linux下查看nginx的安装路径
输入:nginx -V 输出:configure arguments: --prefix=/usr/local/nginx
- 记录初次使用tesseract的过程
目录 简介 安装tesseract 安装成功 python应用识别图片 简介 这个谷歌的识别项目早就听说了,使用之后发现,真的很厉害.写下初次简单使用的过程吧. 安装tesseract 谷歌的开源识别 ...
- 深入HQL学习以及HQL和SQL的区别
HQL(Hibernate Query Language) 是面向对象的查询语言, 它和 SQL 查询语言有些相似. 在 Hibernate 提供的各种检索方式中, HQL 是使用最广的一种检索方式. ...
- Python--paramiko库:连接远程服务器操作文件
import paramikofrom loggingutils.mylogger import logger as log class SSHConnection(object): def __in ...
- 解决VMware Workstation虚拟机不能联网的解决办法
在windows服务中查看,以下几个服务是否正常开启,没有就开启
- Storm-源码分析- Multimethods使用例子
1. storm通过multimethods来区分local和distributed模式 当调用launch-worker的时候, clojure会自动根据defmulti里面定义的fn来判断是调用哪 ...
- Sublime Text 中文
1.打开Sublime Text 2.Ctrl+Shift+P,输入Package Control: Install Package回车 3.输入LocalizedMenu,回车 4.点击菜单help ...
- jupter nootbok 快捷键、NumPy模块、Pandas模块初识
jupter nootbok 快捷键 插入cell:a b 删除cell:x cell模式的切换:m:Markdown模式 y:code模式 运行cell:shift+enter tab:补全 shi ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
- PAT 1041 Be Unique[简单]
1041 Be Unique (20 分) Being unique is so important to people on Mars that even their lottery is desi ...