奇异值与主成分分析(PCA)
主成分分析在上一节里面也讲了一些,这里主要谈谈如何用SVD去解PCA的问题。PCA的问题其实是一个基的变换,使得变换后的数据有着最大的方差。方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。以下面这张图为例子:
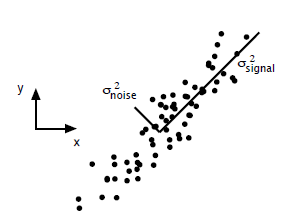
这个假设是一个摄像机采集一个物体运动得到的图片,上面的点表示物体运动的位置,假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
一般来说,方差大的方向是信号的方向,方差小的方向是噪声的方向,我们在数据挖掘中或者数字信号处理中,往往要提高信号与噪声的比例,也就是信噪比。对上图来说,如果我们只保留signal方向的数据,也可以对原数据进行不错的近似了。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
还是假设我们矩阵每一行表示一个样本,每一列表示一个feature,用矩阵的语言来表示,将一个m * n的矩阵A的进行坐标轴的变化,P就是一个变换的矩阵从一个N维的空间变换到另一个N维的空间,在空间中就会进行一些类似于旋转、拉伸的变化。
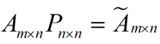
而将一个m * n的矩阵A变换成一个m * r的矩阵,这样就会使得本来有n个feature的,变成了有r个feature了(r < n),这r个其实就是对n个feature的一种提炼,我们就把这个称为feature的压缩。用数学语言表示就是:

但是这个怎么和SVD扯上关系呢?之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…我们回忆一下之前得到的SVD式子:
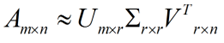
在矩阵的两边同时乘上一个矩阵V,由于V是一个正交的矩阵,所以V转置乘以V得到单位阵I,所以可以化成后面的式子
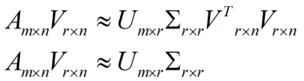
将后面的式子与A * P那个m * n的矩阵变换为m * r的矩阵的式子对照看看,在这里,其实V就是P,也就是一个变化的向量。这里是将一个m * n 的矩阵压缩到一个m * r的矩阵,也就是对列进行压缩,如果我们想对行进行压缩(在PCA的观点下,对行进行压缩可以理解为,将一些相似的sample合并在一起,或者将一些没有太大价值的sample去掉)怎么办呢?同样我们写出一个通用的行压缩例子:
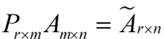
这样就从一个m行的矩阵压缩到一个r行的矩阵了,对SVD来说也是一样的,我们对SVD分解的式子两边乘以U的转置U'
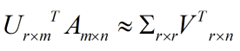
这样我们就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对A’A进行特征值的分解,只能得到一个方向的PCA。
奇异值与潜在语义索引LSI:
潜在语义索引(Latent Semantic Indexing)与PCA不太一样,至少不是实现了SVD就可以直接用的,不过LSI也是一个严重依赖于SVD的算法,之前吴军老师在矩阵计算与文本处理中的分类问题中谈到:
“三个矩阵有非常清楚的物理含义。第一个矩阵X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。最后一个矩阵Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章雷之间的相关性。因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。”
上面这段话可能不太容易理解,不过这就是LSI的精髓内容,我下面举一个例子来说明一下,下面的例子来自LSA tutorial,具体的网址我将在最后的引用中给出:
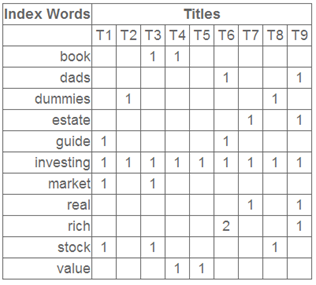
这就是一个矩阵,不过不太一样的是,这里的一行表示一个词在哪些title中出现了(一行就是之前说的一维feature),一列表示一个title中有哪些词,(这个矩阵其实是我们之前说的那种一行是一个sample的形式的一种转置,这个会使得我们的左右奇异向量的意义产生变化,但是不会影响我们计算的过程)。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:
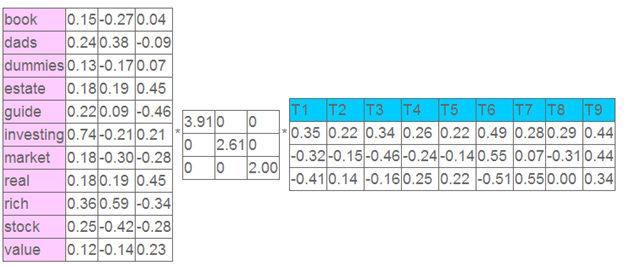
左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
继续看这个矩阵还可以发现一些有意思的东西,首先,左奇异向量的第一列表示每一个词的出现频繁程度,虽然不是线性的,但是可以认为是一个大概的描述,比如book是0.15对应文档中出现的2次,investing是0.74对应了文档中出现了9次,rich是0.36对应文档中出现了3次;
其次,右奇异向量中一的第一行表示每一篇文档中的出现词的个数的近似,比如说,T6是0.49,出现了5个词,T2是0.22,出现了2个词。
然后我们反过头来看,我们可以将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到:
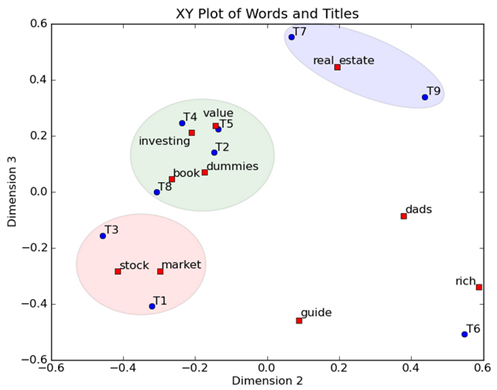
在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
不知道按这样描述,再看看吴军老师的文章,是不是对SVD更清楚了?:-D
奇异值与主成分分析(PCA)的更多相关文章
- 主成分分析PCA(转载)
主成分分析PCA 降维的必要性 1.多重共线性--预测变量之间相互关联.多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯. 2.高维空间本身具有稀疏性.一维正态分布有68%的值落于正负标准差之 ...
- 主成分分析(PCA)原理及推导
原文:http://blog.csdn.net/zhongkejingwang/article/details/42264479 什么是PCA? 在数据挖掘或者图像处理等领域经常会用到主成分分析,这样 ...
- 机器学习之主成分分析PCA原理笔记
1. 相关背景 在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律.多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的 ...
- 深度学习入门教程UFLDL学习实验笔记三:主成分分析PCA与白化whitening
主成分分析与白化是在做深度学习训练时最常见的两种预处理的方法,主成分分析是一种我们用的很多的降维的一种手段,通过PCA降维,我们能够有效的降低数据的维度,加快运算速度.而白化就是为了使得每个特征能有同 ...
- 线性判别分析(LDA), 主成分分析(PCA)及其推导【转】
前言: 如果学习分类算法,最好从线性的入手,线性分类器最简单的就是LDA,它可以看做是简化版的SVM,如果想理解SVM这种分类器,那理解LDA就是很有必要的了. 谈到LDA,就不得不谈谈PCA,PCA ...
- 降维(一)----说说主成分分析(PCA)的源头
降维(一)----说说主成分分析(PCA)的源头 降维系列: 降维(一)----说说主成分分析(PCA)的源头 降维(二)----Laplacian Eigenmaps --------------- ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- K-L变换和 主成分分析PCA
一.K-L变换 说PCA的话,必须先介绍一下K-L变换了. K-L变换是Karhunen-Loeve变换的简称,是一种特殊的正交变换.它是建立在统计特性基础上的一种变换,有的文献也称其为霍特林(Hot ...
随机推荐
- malloc 返回值的类型是 void *
malloc 返回值的类型是 void *,所以在调用 malloc 时要显式地进行类型转换,将 void * 转换成所需要的指针类型. #include <iostream> using ...
- XAMPP phpmyadmin修改mysql密码
我手动修改了mysql的root账户的密码,然后就访问不了phpmyadmin了. 解决方法: 打开xampp目录(默认的安装目录,如果修改,请找到xampp的安装目录),打开phpmyadmin的目 ...
- 【转】C++ Incorrect Memory Usage and Corrupted Memory(模拟C++程序内存使用崩溃问题)
http://www.bogotobogo.com/cplusplus/CppCrashDebuggingMemoryLeak.php Incorrect Memory Usage and Corru ...
- python3----datetime模块分析
datetime模块用于是date和time模块的合集,datetime有两个常量,MAXYEAR和MINYEAR,分别是9999和1. datetime模块定义了5个类,分别是 1.datetime ...
- 转载 -- Cocoapod方式引入百川SDK -报错[!] Unable to find a specification for `xxx`
[cocopad集成百川sdk官网] iOS需要填写BundleID .BundleID要是当前应用的BundleID.勾选淘宝登录基础包下载SDK. 注意事项:将下载的SDK中的身份图片yw_122 ...
- 虚拟机中Lvs配置
参考:http://zh.linuxvirtualserver.org/node/272 环境,三台centos 5.2.基于ipvsadm的负载均衡,采用DR方式,负载均衡的服务是web. 内核版本 ...
- JSP页面的生命周期
JSP页面的生命周期:我们假设要访问的jsp页面是index.jsp.首先,用户发出请求index.jsp:服务器会判断是否是第一次请求:如果是的话,JSP引擎会把该JSP文件转换成为一个Servle ...
- 【BZOJ2801】[Poi2012]Minimalist Security BFS
[BZOJ2801][Poi2012]Minimalist Security Description 给出一个N个顶点.M条边的无向图,边(u,v)有权值w(u,v),顶点i也有权值p(i),并且对于 ...
- 170324、Spring 处理器和Resource
1.Spring 框架允许开发者使用两种后处理器扩展 IoC 容器,这两种后处理器扩展 IoC 容器,这两种后处理器可以后处理 IoC 容器本身,或对容器中所有的 Bean 进行后处理.IoC 容器还 ...
- 160418、ztree权限菜单
1.页面中引用ztree的css和js(大家自行下载ztree) <link rel="stylesheet" href="${ctx}/resources/js/ ...