006-Hadoop Hive sql语法详解1-数据结构和Hive表建立
1.认识hive:
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL 简称Hive SQL,使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据。而mapreduce开发人员可以把己写的mapper 和reducer 作为插件来支持Hive 做更复杂的数据分析。
它与关系型数据库的SQL 略有不同,但支持了绝大多数的语句如DDL、DML 以及常见的聚合函数、连接查询、条件查询。HIVE不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。
HIVE的特点:可伸缩(在Hadoop的集群上动态的添加设备),可扩展,容错,输入格式的松散耦合。
基础数据结构
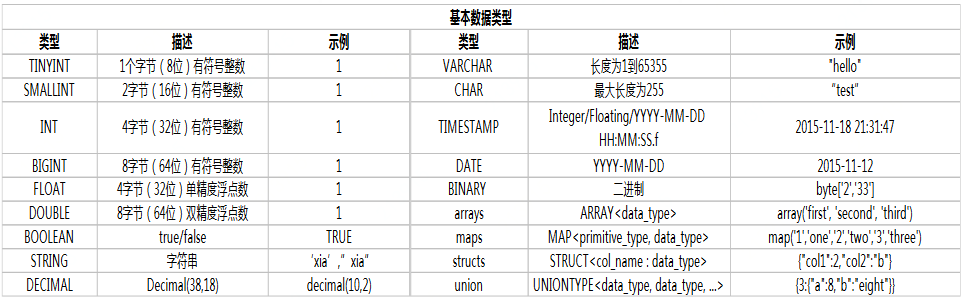
类型装换
cast(字段名or具体值 as 指定类型)
示例:select cast(1 as double) from table
2. DDL 操作
一个表可以拥有一个或多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
创建表,指定EXTERNAL就是外部表,没有指定就是内部表,内部表在drop的时候会从hdfs上删除数据,而外部表不会删除。
如果不指定数据库,hive会把表创建在default数据库下
创建简单表
hive> CREATE TABLE pokes (foo INT, bar STRING);
复杂一下如下:
创建外部表:
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '<hdfs_location>';
建分区表:
CREATE TABLE par_table(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(date STRING, pos STRING)
ROW FORMAT DELIMITED ‘\t’
FIELDS TERMINATED BY '\n'
STORED AS SEQUENCEFILE;
建Bucket表
CREATE TABLE par_table(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(date STRING, pos STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED ‘\t’
FIELDS TERMINATED BY '\n'
STORED AS SEQUENCEFILE;
创建表并创建索引字段ds
hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);
复制一个空表
CREATE TABLE empty_key_value_store
LIKE key_value_store;
例子
create table user_info (user_id int, cid string, ckid string, username string)
row format delimited
fields terminated by '\t'
lines terminated by '\n';
导入数据表的数据格式是:字段之间是tab键分割,行之间是断行。
及要我们的文件内容格式:
100636 100890 c5c86f4cddc15eb7 yyyvybtvt
100612 100865 97cc70d411c18b6f gyvcycy
100078 100087 ecd6026a15ffddf5 qa000100
显示所有表
hive> SHOW TABLES;
按正条件(正则表达式)显示表,
hive> SHOW TABLES '.*s';
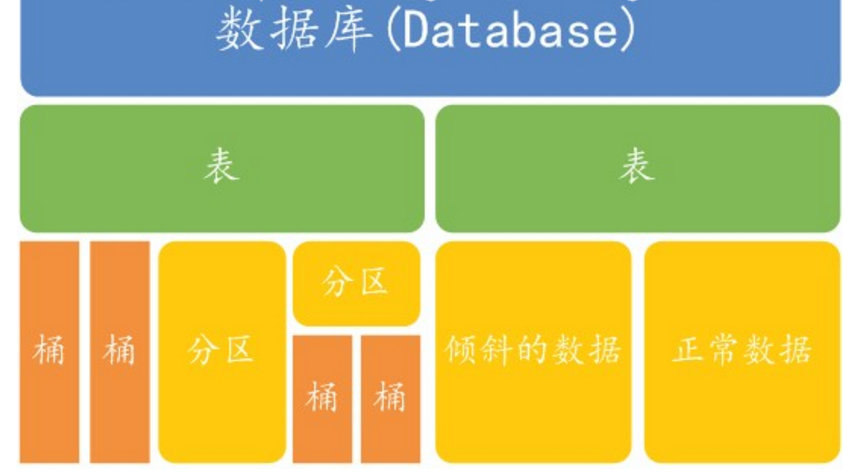
三、“外部表”、“分区表”、“Bucket表”
Bucket表和另外两个表不是同一个概念:
1、外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
2、分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse/dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
3、桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user/hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
006-Hadoop Hive sql语法详解1-数据结构和Hive表建立的更多相关文章
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- [转]Hadoop Hive sql语法详解
转自 : http://blog.csdn.net/hguisu/article/details/7256833 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式 ...
- Hadoop Hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询 ...
- 【hive】——Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQ ...
- 009-Hadoop Hive sql语法详解4-DQL 操作:数据查询SQL-select、join、union、udtf
一.基本的Select 操作 语法SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE whe ...
- 010-Hadoop Hive sql语法详解5-HiveQL与SQL区别
1.Hive不支持等值连接 •SQL中对两表内联可以写成:•select * from dual a,dual b where a.key = b.key;•Hive中应为•select * from ...
- 008-Hadoop Hive sql语法详解3-DML 操作:元数据存储
一.概述 hive不支持用insert语句一条一条的进行插入操作,也不支持update操作.数据是以load的方式加载到建立好的表中.数据一旦导入就不可以修改. DML包括:INSERT插入.UPDA ...
随机推荐
- 关于VS2013编辑器的问题
如果输出报错 This function or variable may be unsafe. 解决方法 1.用VS2013打开出现错误的代码文件 2.在工程文件名处右击鼠标打开快捷菜单,找到“属性” ...
- 什么是Spring Cloud
Spring Cloud是一系列框架的有序集合.它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册.配置中心.消息总线.负载均衡.断路器.数据监控等,都可以用 ...
- 【UVa】Headmaster's Headache(状压dp)
http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&p ...
- SSH学习三 SESSION
一.session方法 Session:由同一个IE窗体向同一个WEBAPP发的全部请求的总称,一个会话 同一个会话的多个额请求能够从前到后多个请求.??祖给孙.孙不给祖 浏览器:搜集sessionI ...
- Oracle Data Provider for .NET的使用(三)-ORACLE与.NET类型对应关系
想来这个是最重要的事情了,因为多数情况下,我们使用dbhelper来调用数据库的时候,是因为如下三个地方导致错误: 1.错误的sql语句:末尾多了分号,少了部分关键字 2.sql中的参数与parame ...
- 多线程编程(三)--创建线程之Thread VS Runnable
前面写过一篇基础的创建多线程的博文: 那么本篇博文主要来对照一下这两种创建线程的差别. 继承Thread类: 还拿上篇博客的样例来说: 四个线程各自卖各自的票,说明四个线程之间没有共享,是独立的线程. ...
- CSS代码重构与优化
CSS代码重构的基本方法 前面说到了CSS代码重构的目的,现在我们来说说一些如何达到这些目的的一些基本方法,这些方法都是易于理解,容易实施的一些手段,大家平时可能也不知不觉地在使用它. 提高CSS性能 ...
- Python tushare 初步了解
一.安装 1.Python 2.numpy 3.pandas 4.lxml 5.............. n.tushare 二.初步测试
- Tomcat服务器的安装与配置
安装 输入网址进入Tomcat的官网 在左边导航栏选择对应下载的版本 下载安装包形式 下载并解压到我们欲放入的目录中 配置 ...
- 《C#高级编程》学习笔记----c#内存管理--栈VS堆
本文转载自Netprawn,原文英文版地址 尽管在.net framework中我们不太需要关注内存管理和垃圾回收这方面的问题,但是出于提高我们应用程序性能的目的,在我们的脑子里还是需要有这方面的意识 ...