cJONS序列化工具解读二(数据解析)
cJSON数据解析
关于数据解析部分,其实这个解析就是个自动机,通过递归或者解析栈进行实现数据的解析
/* Utility to jump whitespace and cr/lf */
//用于跳过ascii小于32的空白字符
static const char *skip(const char *in)
{
while (in && *in && (unsigned char)*in <= )
in++;
return in;
} /* Parse an object - create a new root, and populate. */
cJSON *cJSON_ParseWithOpts(const char *value, const char **return_parse_end, int require_null_terminated)
{
const char *end = ;
cJSON *c = cJSON_New_Item();
ep = ;
if (!c)
return ; /* memory fail */ //根据前几个字符设置c类型并更新读取位置为end
end = parse_value(c, skip(value));
if (!end)
{
cJSON_Delete(c); //解析失败,数据不完整
return ;
} /* parse failure. ep is set. */ /* if we require null-terminated JSON without appended garbage, skip and then check for a null terminator */
if (require_null_terminated)///??
{
end = skip(end);
if (*end)
{
cJSON_Delete(c);
ep = end;
return ;
}
}
if (return_parse_end)
*return_parse_end = end;
return c;
}
/* Default options for cJSON_Parse */
cJSON *cJSON_Parse(const char *value) { return cJSON_ParseWithOpts(value, , ); }
①关于重点部分parse_value 对类型解读函数
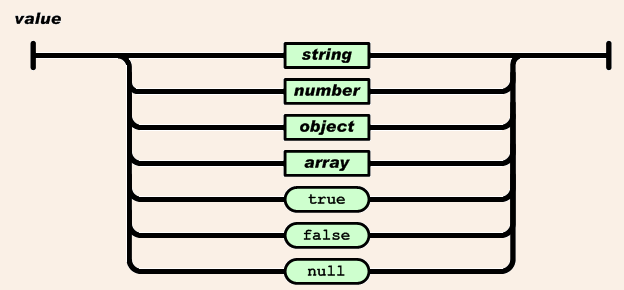
/* Parser core - when encountering text, process appropriately. */
//将输入字符串解析为具体类型cJSON结构
static const char *parse_value(cJSON *item, const char *value)
{
if (!value)
return ; /* Fail on null. */ //设置结构的具体类型并且返回下一个将要解读数据的位置
if (!strncmp(value, "null", )) { item->type = cJSON_NULL; return value + ; }
if (!strncmp(value, "false", )) { item->type = cJSON_False; return value + ; }
if (!strncmp(value, "true", )) { item->type = cJSON_True; item->valueint = ; return value + ; }
if (*value == '\"') { return parse_string(item, value); }
if (*value == '-' || (*value >= '' && *value <= '')) { return parse_number(item, value); }
if (*value == '[') { return parse_array(item, value); }
if (*value == '{') { return parse_object(item, value); } ep = value; return ; /* failure. */
}
②解析字符串部分
解析字符串时, 对于特殊字符也应该转义,比如 "n" 字符应该转换为 'n' 这个换行符。
当然,如果只有特殊字符转换的话,代码不会又这么长, 对于字符串, 还要支持非 ascii 码的字符, 即 utf8字符。
这些字符在字符串中会编码为 uXXXX 的字符串, 我们现在需要还原为 0 - 255 的一个字符。
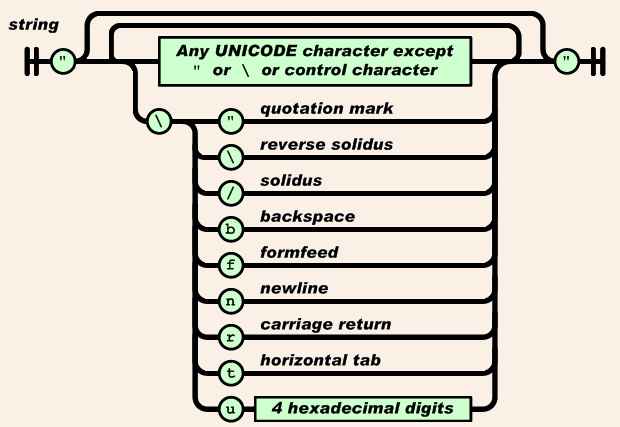
static unsigned parse_hex4(const char *str)
{
unsigned h = ;
if (*str >= '' && *str <= '')
h += (*str) - '';
else if (*str >= 'A' && *str <= 'F')
h += + (*str) - 'A';
else if (*str >= 'a' && *str <= 'f')
h += + (*str) - 'a';
else
return ; h = h << ; //*F
str++;
if (*str >= '' && *str <= '')
h += (*str) - '';
else if (*str >= 'A' && *str <= 'F')
h += + (*str) - 'A';
else if (*str >= 'a' && *str <= 'f')
h += + (*str) - 'a';
else
return ; h = h << ;
str++;
if (*str >= '' && *str <= '')
h += (*str) - '';
else if (*str >= 'A' && *str <= 'F')
h += + (*str) - 'A';
else if (*str >= 'a' && *str <= 'f')
h += + (*str) - 'a';
else return ; h = h << ;
str++;
if (*str >= '' && *str <= '')
h += (*str) - '';
else if (*str >= 'A' && *str <= 'F')
h += + (*str) - 'A';
else if (*str >= 'a' && *str <= 'f')
h += + (*str) - 'a';
else
return ;
return h;
} /* Parse the input text into an unescaped cstring, and populate item. */
static const unsigned char firstByteMark[] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC };
static const char *parse_string(cJSON *item, const char *str)
{
const char *ptr = str + ;
char *ptr2;
char *out;
int len = ;
unsigned uc, uc2;
if (*str != '\"')
{
ep = str;
return ;
} /* not a string! */ while(*ptr != '\"' && *ptr && ++len)
if (*ptr++ == '\\') //跳过\续行符
ptr++; /* Skip escaped quotes. */ //空间申请
out = (char*)cJSON_malloc(len + ); /* This is how long we need for the string, roughly. */
if (!out)
return ; ptr = str + ;//跳过“开始
ptr2 = out;
while (*ptr != '\"' && *ptr)
{
if (*ptr != '\\')
*ptr2++ = *ptr++;
else //转义字符处理
{
ptr++;
switch (*ptr)
{
case 'b': *ptr2++ = '\b'; break;
case 'f': *ptr2++ = '\f'; break;
case 'n': *ptr2++ = '\n'; break;
case 'r': *ptr2++ = '\r'; break;
case 't': *ptr2++ = '\t'; break;
case 'u': /* transcode utf16 to utf8. */
uc = parse_hex4(ptr + );
ptr += ; /* get the unicode char. */ if ((uc >= 0xDC00 && uc <= 0xDFFF) || uc == )
break; /* check for invalid. */ if (uc >= 0xD800 && uc <= 0xDBFF) /* UTF16 surrogate pairs. */
{
if (ptr[] != '\\' || ptr[] != 'u')
break; /* missing second-half of surrogate. */
uc2 = parse_hex4(ptr + );
ptr += ;
if (uc2<0xDC00 || uc2>0xDFFF)
break; /* invalid second-half of surrogate. */
uc = 0x10000 + (((uc & 0x3FF) << ) | (uc2 & 0x3FF));
} len = ;
if (uc<0x80)
len = ;
else if (uc<0x800)
len = ;
else if (uc<0x10000)
len = ;
ptr2 += len; switch (len)
{
case :
*--ptr2 = ((uc | 0x80) & 0xBF); uc >>= ;
case :
*--ptr2 = ((uc | 0x80) & 0xBF); uc >>= ;
case :
*--ptr2 = ((uc | 0x80) & 0xBF); uc >>= ;
case :
*--ptr2 = (uc | firstByteMark[len]);
}
ptr2 += len;
break;
default:
*ptr2++ = *ptr; break;
}
ptr++;
}
}
*ptr2 = ;
if (*ptr == '\"') ptr++;
item->valuestring = out;
item->type = cJSON_String;
return ptr;
}
关于具体的字符解析中的编码相关问题,请自行阅读编码相关知识
③数字解析
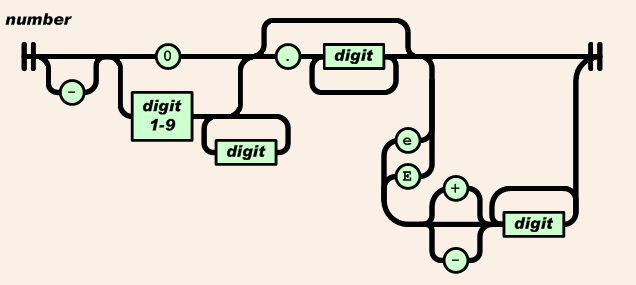
/* Parse the input text to generate a number, and populate the result into item. */
static const char *parse_number(cJSON *item, const char *num)
{
double n = , sign = , scale = ;
int subscale = ,
signsubscale = ; if (*num == '-')
sign = -, num++; /* Has sign? */
if (*num == '')
num++; /* is zero */
if (*num >= '' && *num <= '')
do
{
n = (n*10.0) + (*num++ - '');
}while (*num >= '' && *num <= ''); /* Number? */
if (*num == '.' && num[] >= '' && num[] <= '')
{
num++;
do
n = (n*10.0) + (*num++ - ''), scale--;
while (*num >= '' && *num <= '');
} /* Fractional part? */
if (*num == 'e' || *num == 'E') /* Exponent? */
{
num++;
if (*num == '+')
num++;
else if (*num == '-')
signsubscale = -, num++; /* With sign? */
while (*num >= '' && *num <= '')
subscale = (subscale * ) + (*num++ - ''); /* Number? */
} n = sign*n*pow(10.0, (scale + subscale*signsubscale)); /* number = +/- number.fraction * 10^+/- exponent */ item->valuedouble = n;
item->valueint = (int)n;
item->type = cJSON_Number;
return num;
}
④解析数组
解析数组, 需要先遇到 '[' 这个符号, 然后挨个的读取节点内容, 节点使用 ',' 分隔, ',' 前后还可能有空格, 最后以 ']' 结尾。
我们要编写的也是这样。
先创建一个数组对象, 判断是否有儿子, 有的话读取第一个儿子, 然后判断是不是有 逗号, 有的话循环读取后面的儿子。
最后读取 ']' 即可。
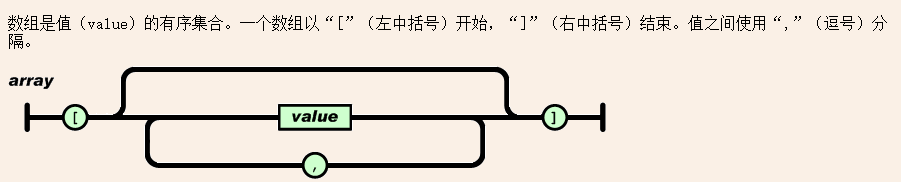
/* Build an array from input text. */
static const char *parse_array(cJSON *item, const char *value)
{
cJSON *child;
if (*value != '[')
{
ep = value;
return ;
} /* not an array! */ item->type = cJSON_Array;
value = skip(value + );
if (*value == ']')
return value + ; /* empty array. */ item->child = child = cJSON_New_Item();
if (!item->child)
return ; /* memory fail */
//解析数组内结构
value = skip(parse_value(child, skip(value))); /* skip any spacing, get the value. */
if (!value) return ; while (*value == ',')
{
cJSON *new_item;
if (!(new_item = cJSON_New_Item())) return ; /* memory fail */ child->next = new_item;
new_item->prev = child;
child = new_item;
value = skip(parse_value(child, skip(value + )));
if (!value)
return ; /* memory fail */
} if (*value == ']')
return value + ; /* end of array */
ep = value;
return ; /* malformed. */
}
⑤解析对象
解析对象和解析数组类似, 只不过对象的一个儿子是个 key - value, key 是字符串, value 可能是任何值, key 和 value 用 ":" 分隔。

/* Render an object to text. */
static char *print_object(cJSON *item, int depth, int fmt, printbuffer *p)
{
char **entries = , **names = ;
char *out = , *ptr, *ret, *str; int len = , i = , j;
cJSON *child = item->child;
int numentries = , fail = ;
size_t tmplen = ;
/* Count the number of entries. */
while (child) numentries++, child = child->next;
/* Explicitly handle empty object case */
if (!numentries)
{
if (p) out = ensure(p, fmt ? depth + : );
else out = (char*)cJSON_malloc(fmt ? depth + : );
if (!out) return ;
ptr = out; *ptr++ = '{';
if (fmt) { *ptr++ = '\n'; for (i = ; i<depth - ; i++) *ptr++ = '\t'; }
*ptr++ = '}'; *ptr++ = ;
return out;
}
if (p)
{
/* Compose the output: */
i = p->offset;
len = fmt ? : ; ptr = ensure(p, len + ); if (!ptr) return ;
*ptr++ = '{'; if (fmt) *ptr++ = '\n'; *ptr = ; p->offset += len;
child = item->child; depth++;
while (child)
{
if (fmt)
{
ptr = ensure(p, depth); if (!ptr) return ;
for (j = ; j<depth; j++) *ptr++ = '\t';
p->offset += depth;
}
print_string_ptr(child->string, p);
p->offset = update(p); len = fmt ? : ;
ptr = ensure(p, len); if (!ptr) return ;
*ptr++ = ':'; if (fmt) *ptr++ = '\t';
p->offset += len; print_value(child, depth, fmt, p);
p->offset = update(p); len = (fmt ? : ) + (child->next ? : );
ptr = ensure(p, len + ); if (!ptr) return ;
if (child->next) *ptr++ = ',';
if (fmt) *ptr++ = '\n'; *ptr = ;
p->offset += len;
child = child->next;
}
ptr = ensure(p, fmt ? (depth + ) : ); if (!ptr) return ;
if (fmt) for (i = ; i<depth - ; i++) *ptr++ = '\t';
*ptr++ = '}'; *ptr = ;
out = (p->buffer) + i;
}
else
{
/* Allocate space for the names and the objects */
entries = (char**)cJSON_malloc(numentries * sizeof(char*));
if (!entries) return ;
names = (char**)cJSON_malloc(numentries * sizeof(char*));
if (!names) { cJSON_free(entries); return ; }
memset(entries, , sizeof(char*)*numentries);
memset(names, , sizeof(char*)*numentries); /* Collect all the results into our arrays: */
child = item->child; depth++; if (fmt) len += depth;
while (child)
{
names[i] = str = print_string_ptr(child->string, );
entries[i++] = ret = print_value(child, depth, fmt, );
if (str && ret) len += strlen(ret) + strlen(str) + + (fmt ? + depth : ); else fail = ;
child = child->next;
} /* Try to allocate the output string */
if (!fail) out = (char*)cJSON_malloc(len);
if (!out) fail = ; /* Handle failure */
if (fail)
{
for (i = ; i<numentries; i++) { if (names[i]) cJSON_free(names[i]); if (entries[i]) cJSON_free(entries[i]); }
cJSON_free(names); cJSON_free(entries);
return ;
} /* Compose the output: */
*out = '{'; ptr = out + ; if (fmt)*ptr++ = '\n'; *ptr = ;
for (i = ; i<numentries; i++)
{
if (fmt) for (j = ; j<depth; j++) *ptr++ = '\t';
tmplen = strlen(names[i]); memcpy(ptr, names[i], tmplen); ptr += tmplen;
*ptr++ = ':'; if (fmt) *ptr++ = '\t';
strcpy(ptr, entries[i]); ptr += strlen(entries[i]);
if (i != numentries - ) *ptr++ = ',';
if (fmt) *ptr++ = '\n'; *ptr = ;
cJSON_free(names[i]); cJSON_free(entries[i]);
} cJSON_free(names); cJSON_free(entries);
if (fmt) for (i = ; i<depth - ; i++) *ptr++ = '\t';
*ptr++ = '}'; *ptr++ = ;
}
return out;
}
这样都实现后, 字符串解析为 json 对象就实现了。
⑥序列化
序列化也就是格式化输出了。
序列化又分为格式化输出,压缩输出
/* Render a cJSON item/entity/structure to text. */
char *cJSON_Print(cJSON *item)
{
return print_value(item, , , );
}
char *cJSON_PrintUnformatted(cJSON *item)
{
return print_value(item, , , );
} char *cJSON_PrintBuffered(cJSON *item, int prebuffer, int fmt)
{
printbuffer p;
p.buffer = (char*)cJSON_malloc(prebuffer);
p.length = prebuffer;
p.offset = ;
return print_value(item, , fmt, &p);
return p.buffer;
} /* Render a value to text. */
static char *print_value(cJSON *item, int depth, int fmt, printbuffer *p)
{
char *out = ;
if (!item) return ;
if (p)
{
switch ((item->type) & )
{
case cJSON_NULL: {out = ensure(p, ); if (out) strcpy(out, "null"); break; }
case cJSON_False: {out = ensure(p, ); if (out) strcpy(out, "false"); break; }
case cJSON_True: {out = ensure(p, ); if (out) strcpy(out, "true"); break; }
case cJSON_Number: out = print_number(item, p); break;
case cJSON_String: out = print_string(item, p); break;
case cJSON_Array: out = print_array(item, depth, fmt, p); break;
case cJSON_Object: out = print_object(item, depth, fmt, p); break;
}
}
else
{
switch ((item->type) & )
{
case cJSON_NULL: out = cJSON_strdup("null"); break;
case cJSON_False: out = cJSON_strdup("false"); break;
case cJSON_True: out = cJSON_strdup("true"); break;
case cJSON_Number: out = print_number(item, ); break;
case cJSON_String: out = print_string(item, ); break;
case cJSON_Array: out = print_array(item, depth, fmt, ); break;
case cJSON_Object: out = print_object(item, depth, fmt, ); break;
}
}
return out;
}
假设我们要使用格式化输出, 也就是美化输出。
cjson 的做法不是边分析 json 边输出, 而是预先将要输的内容全部按字符串存在内存中, 最后输出整个字符串。
这对于比较大的 json 来说, 内存就是个问题了。
另外,格式化输出依靠的是节点的深度, 这个也可以优化, 一般宽度超过80 时, 就需要从新的一行算起的。
/* Render an object to text. */
static char *print_object(cJSON *item, int depth, int fmt, printbuffer *p)
{
char **entries = , **names = ;
char *out = , *ptr, *ret, *str; int len = , i = , j;
cJSON *child = item->child;
int numentries = , fail = ;
size_t tmplen = ;
/* Count the number of entries. */
while (child) numentries++, child = child->next;
/* Explicitly handle empty object case */
if (!numentries)
{
if (p) out = ensure(p, fmt ? depth + : );
else out = (char*)cJSON_malloc(fmt ? depth + : );
if (!out) return ;
ptr = out; *ptr++ = '{';
if (fmt) { *ptr++ = '\n'; for (i = ; i<depth - ; i++) *ptr++ = '\t'; }
*ptr++ = '}'; *ptr++ = ;
return out;
}
if (p)
{
/* Compose the output: */
i = p->offset;
len = fmt ? : ; ptr = ensure(p, len + ); if (!ptr) return ;
*ptr++ = '{'; if (fmt) *ptr++ = '\n'; *ptr = ; p->offset += len;
child = item->child; depth++;
while (child)
{
if (fmt)
{
ptr = ensure(p, depth); if (!ptr) return ;
for (j = ; j<depth; j++) *ptr++ = '\t';
p->offset += depth;
}
print_string_ptr(child->string, p);
p->offset = update(p); len = fmt ? : ;
ptr = ensure(p, len); if (!ptr) return ;
*ptr++ = ':'; if (fmt) *ptr++ = '\t';
p->offset += len; print_value(child, depth, fmt, p);
p->offset = update(p); len = (fmt ? : ) + (child->next ? : );
ptr = ensure(p, len + ); if (!ptr) return ;
if (child->next) *ptr++ = ',';
if (fmt) *ptr++ = '\n'; *ptr = ;
p->offset += len;
child = child->next;
}
ptr = ensure(p, fmt ? (depth + ) : ); if (!ptr) return ;
if (fmt) for (i = ; i<depth - ; i++) *ptr++ = '\t';
*ptr++ = '}'; *ptr = ;
out = (p->buffer) + i;
}
else
{
/* Allocate space for the names and the objects */
entries = (char**)cJSON_malloc(numentries * sizeof(char*));
if (!entries) return ;
names = (char**)cJSON_malloc(numentries * sizeof(char*));
if (!names) { cJSON_free(entries); return ; }
memset(entries, , sizeof(char*)*numentries);
memset(names, , sizeof(char*)*numentries); /* Collect all the results into our arrays: */
child = item->child; depth++; if (fmt) len += depth;
while (child)
{
names[i] = str = print_string_ptr(child->string, );
entries[i++] = ret = print_value(child, depth, fmt, );
if (str && ret) len += strlen(ret) + strlen(str) + + (fmt ? + depth : ); else fail = ;
child = child->next;
} /* Try to allocate the output string */
if (!fail) out = (char*)cJSON_malloc(len);
if (!out) fail = ; /* Handle failure */
if (fail)
{
for (i = ; i<numentries; i++) { if (names[i]) cJSON_free(names[i]); if (entries[i]) cJSON_free(entries[i]); }
cJSON_free(names); cJSON_free(entries);
return ;
} /* Compose the output: */
*out = '{'; ptr = out + ; if (fmt)*ptr++ = '\n'; *ptr = ;
for (i = ; i<numentries; i++)
{
if (fmt) for (j = ; j<depth; j++) *ptr++ = '\t';
tmplen = strlen(names[i]); memcpy(ptr, names[i], tmplen); ptr += tmplen;
*ptr++ = ':'; if (fmt) *ptr++ = '\t';
strcpy(ptr, entries[i]); ptr += strlen(entries[i]);
if (i != numentries - ) *ptr++ = ',';
if (fmt) *ptr++ = '\n'; *ptr = ;
cJSON_free(names[i]); cJSON_free(entries[i]);
} cJSON_free(names); cJSON_free(entries);
if (fmt) for (i = ; i<depth - ; i++) *ptr++ = '\t';
*ptr++ = '}'; *ptr++ = ;
}
return out;
}
static char *print_array(cJSON *item, int depth, int fmt, printbuffer *p)
{
char **entries;
char *out = , *ptr, *ret; int len = ;
cJSON *child = item->child;
int numentries = , i = , fail = ;
size_t tmplen = ; /* How many entries in the array? */
while (child) numentries++, child = child->next;
/* Explicitly handle numentries==0 */
if (!numentries)
{
if (p) out = ensure(p, );
else out = (char*)cJSON_malloc();
if (out) strcpy(out, "[]");
return out;
} if (p)
{
/* Compose the output array. */
i = p->offset;
ptr = ensure(p, ); if (!ptr) return ; *ptr = '['; p->offset++;
child = item->child;
while (child && !fail)
{
print_value(child, depth + , fmt, p);
p->offset = update(p);
if (child->next) { len = fmt ? : ; ptr = ensure(p, len + ); if (!ptr) return ; *ptr++ = ','; if (fmt)*ptr++ = ' '; *ptr = ; p->offset += len; }
child = child->next;
}
ptr = ensure(p, ); if (!ptr) return ; *ptr++ = ']'; *ptr = ;
out = (p->buffer) + i;
}
else
{
/* Allocate an array to hold the values for each */
entries = (char**)cJSON_malloc(numentries * sizeof(char*));
if (!entries) return ;
memset(entries, , numentries * sizeof(char*));
/* Retrieve all the results: */
child = item->child;
while (child && !fail)
{
ret = print_value(child, depth + , fmt, );
entries[i++] = ret;
if (ret) len += strlen(ret) + + (fmt ? : ); else fail = ;
child = child->next;
} /* If we didn't fail, try to malloc the output string */
if (!fail) out = (char*)cJSON_malloc(len);
/* If that fails, we fail. */
if (!out) fail = ; /* Handle failure. */
if (fail)
{
for (i = ; i<numentries; i++) if (entries[i]) cJSON_free(entries[i]);
cJSON_free(entries);
return ;
} /* Compose the output array. */
*out = '[';
ptr = out + ; *ptr = ;
for (i = ; i<numentries; i++)
{
tmplen = strlen(entries[i]); memcpy(ptr, entries[i], tmplen); ptr += tmplen;
if (i != numentries - ) { *ptr++ = ','; if (fmt)*ptr++ = ' '; *ptr = ; }
cJSON_free(entries[i]);
}
cJSON_free(entries);
*ptr++ = ']'; *ptr++ = ;
}
return out;
}
cJONS序列化工具解读二(数据解析)的更多相关文章
- cJONS序列化工具解读三(使用案例)
cJSON使用案例 由了解了cJSON的数据结构,接口以及实现之后,那么我们来举例说明其使用. 本例子是一个简单的学生信息表格管理,我们通过键值对的方式向json中增加元素信息. 然后可以格式化输出结 ...
- cJSON序列化工具解读一(结构剖析)
cJSON简介 JSON基本信息 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式.易于人阅读和编写.同时易于机器解析和生成.是一种很好地数据交换语言. 官方 ...
- Python网络爬虫实战(二)数据解析
上一篇说完了如何爬取一个网页,以及爬取中可能遇到的几个问题.那么接下来我们就需要对已经爬取下来的网页进行解析,从中提取出我们想要的数据. 根据爬取下来的数据,我们需要写不同的解析方式,最常见的一般都是 ...
- 数据序列化工具——flatbuffer
flatbuffer是一款类似于protobuf的数据序列化工具.所有数据序列化,简单来说,就是将某程数据结构按照一定的格式进行编码与解码,以方便在不同的进程间传递后,能够正确的还原成之前的数据结构. ...
- Gprinter热敏打印机光栅位图点阵数据解析工具
最近参与的项目有一个需求,解析佳博热敏打印机的光栅位图点阵数据并保存为图片文件.数据是通过Bus Hound抓取的,如下图所示. 其中1b 40为初始化打印机的指令,对应的ASCII码为ESC @,1 ...
- Request模块—数据解析工具
一.爬虫基本步骤 指定URL信息 发起请求 获取响应数据 对响应数据进行数据解析 持久化存储 二.数据解析 1. 正则表达式 (1) 基本语法 1. 单字符: . : 除换行以外所有字符 [] :[a ...
- 二、Android XML数据解析
XML,可扩展标记语言.可以用来存储数据,可以看做是一个小型的数据库,SharedPreference就是使用XML文件存储数据的,SQLite底层也是一个XML文件,而在网络应用方面,通常作为信息的 ...
- 多叉树结构:JSON数据解析(二)
多叉树结构:JSON数据解析(二) 在上篇文章中提到了JSON数据解析的基本方法,但是方法效率太低,这里接着上篇文章写写如何利用多叉树结构,定义对象,实现JSON数据字段快速随机访问. JSON数据通 ...
- DRF框架(二)——解析模块(parsers)、异常模块(exception_handler)、响应模块(Response)、三大序列化组件介绍、Serializer组件(序列化与反序列化使用)
解析模块 为什么要配置解析模块 1)drf给我们提供了多种解析数据包方式的解析类 form-data/urlencoded/json 2)我们可以通过配置来控制前台提交的哪些格式的数据后台在解析,哪些 ...
随机推荐
- jsonp解决跨域问题
日常开发网页中,时常遇到跨域问题,通常解决办法:后端提供的接口支持jsonp格式,前端采用dataType:jsonp. 一:Jquery封装的AJAX,dataType:jsonp格式的方法: $. ...
- WebStorm keyboard shortcuts
ctrl + D 向下复制 下面是Webstorm的一些常用快捷键: shift + enter: 另起一行 ctrl + alt + L: 格式化代码 control + E: 光标跳到行尾 it ...
- 软工网络15团队作业1——团队组队&展示
一.团队展示 1.队名:想不出队名 2.队员学号(标记组长) 201521123064 郭炜埕 201521123066 郑晓丽 201521123067 廖怡洁 201521123068 包梦榕 2 ...
- [HZNUOJ] 博
Description 定义一个数字序列为“非下降序列”: 此处我们约定用$n\;表示数字序列的长度,下面定义在n \in [1, \infty]时有效$ $if \;\; n = 1:$ $\;\; ...
- Divide by Zero 2017 and Codeforces Round #399 (Div. 1 + Div. 2, combined) C - Jon Snow and his Favourite Number
地址:http://codeforces.com/contest/768/problem/C 题目: C. Jon Snow and his Favourite Number time limit p ...
- javascript 理解对象--- 定义多个属性和读取属性的特性
一 定义多个属性 ECMAScript5 定义了一个Object.defineProperties()方法,用于定义多个属性.此方法接受两个对象参数: 第一个对象:要添加或修改其属性的对象 第二个对象 ...
- C++ char float int string 之间的转换
string str = "123"; string 转 int int i = atoi( str.c_str() ); string 转 float float f = ato ...
- linux系统上使用unzip命令
最近在本地使用maven打包工程后,将工程部署到linux服务器的tomcat上,使用unzip解压工程报--->未找到命令.即该命名文件未安装,需要安装一下.安装命令如下: yum insta ...
- RedisTemplate访问Redis数据结构
https://www.jianshu.com/p/7bf5dc61ca06 Redis 数据结构简介 Redis 可以存储键与5种不同数据结构类型之间的映射,这5种数据结构类型分别为String(字 ...
- HCNP学习笔记之HCNP学习的几种境界
前言: 做任何事情都应该遵循一个循序渐进的过程,而这个过程可能是较为枯乏无味的,在我接触的人中主要分为踏实肯学满腹才华和半途而废不思进取两类.故而希望大家成为前者,勿做后者. 第一境界:散漫无序 简单 ...