解读:Hadoop Archive
hdfs并不擅长存储小文件,因为每个文件最少一个block,每个block的元数据都会在NameNode中占用150byte内存。如果存储大量的小文件,它们会吃掉NameNode节点的大量内存。MR案例:小文件处理方案
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具。它能将多个小文件打包成一个HAR文件,这样在减少NameNode内存使用的同时,仍然允许对小文件进行透明的访问,比如作为MapReduce的输入。
使用方法:
1). 归档前的目录结构
[root@ncst mapreduce]# hadoop fs -lsr /test/in
drwxr-xr-x - root supergroup -- : /test/in/har
drwxr-xr-x - root supergroup -- : /test/in/mapjoin
-rw-r--r-- root supergroup -- : /test/in/mapjoin/address.txt
-rw-r--r-- root supergroup -- : /test/in/mapjoin/company.txt
drwxr-xr-x - root supergroup -- : /test/in/small
-rw-r--r-- root supergroup -- : /test/in/small/small.
-rw-r--r-- root supergroup -- : /test/in/small/small.
-rw-r--r-- root supergroup -- : /test/in/small/small.
-rw-r--r-- root supergroup -- : /test/in/small/small_data
2). 归档命令
可以通过参数 -D har.block.size 指定HAR的大小
shell> hadoop archive -archiveName NAME -p <parent path> <src>* <dest>
/* 归档命令
* -archiveName 0825.har : 指定归档后的文件名
* -p /test/in/ : 被归档文件所在的父目录
* small mapjoin : 要被归档的目录,一至多个(small和mapjoin)
* /test/in/har : 生成的归档文件存储目录
*/
hadoop archive -archiveName 0825.har -p /test/in/ small mapjoin /test/in/har
3). 归档后的目录结构
[root@ncst ~]# hadoop fs -lsr /test/in
drwxr-xr-x - root supergroup -- : /test/in/har
drwxr-xr-x - root supergroup -- : /test/in/har/.har
-rw-r--r-- root supergroup -- : /test/in/har/.har/_SUCCESS
-rw-r--r-- root supergroup -- : /test/in/har/.har/_index
-rw-r--r-- root supergroup -- : /test/in/har/.har/_masterindex
-rw-r--r-- root supergroup -- : /test/in/har/.har/part-
drwxr-xr-x - root supergroup -- : /test/in/mapjoin
-rw-r--r-- root supergroup -- : /test/in/mapjoin/address.txt
-rw-r--r-- root supergroup -- : /test/in/mapjoin/company.txt
drwxr-xr-x - root supergroup -- : /test/in/small
-rw-r--r-- root supergroup -- : /test/in/small/small.
-rw-r--r-- root supergroup -- : /test/in/small/small.
-rw-r--r-- root supergroup -- : /test/in/small/small.
-rw-r--r-- root supergroup -- : /test/in/small/small_data
4). 查看结果文件【part-0】内容
[root@ncst ~]# hadoop fs -cat /test/in/har/.har/part-
Beijing
Guangzhou
Shenzhen
XianBeijing Red Star
Shenzhen Thunder
Guangzhou Honda
Beijing Rising
Guangzhou Development Bank
Tencent
5). 使用har uri去访问原始数据
HAR是HDFS之上的一个文件系统,因此所有 fs shell 命令对HAR文件均可用,只不过文件路径格式不一样
[root@ncst ~]# hadoop fs -lsr har:///test/in/har/0825.har
drwxr-xr-x - root supergroup 0 2015-08-22 12:02 har:///test/in/har/0825.har/mapjoin
-rw-r--r-- 1 root supergroup 39 2015-08-22 12:02 har:///test/in/har/0825.har/mapjoin/address.txt
-rw-r--r-- 1 root supergroup 129 2015-08-22 12:02 har:///test/in/har/0825.har/mapjoin/company.txt
drwxr-xr-x - root supergroup 0 2015-08-25 22:27 har:///test/in/har/0825.har/small
-rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.1
-rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.2
-rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.3
-rw-r--r-- 1 root supergroup 3 2015-08-25 22:27 har:///test/in/har/0825.har/small/small_data
6). 用har uri访问下一级目录
[root@ncst ~]# hdfs dfs -lsr har:///test/in/har/0825.har/small
-rw-r--r-- root supergroup -- : har:///test/in/har/0825.har/small/small.1
-rw-r--r-- root supergroup -- : har:///test/in/har/0825.har/small/small.2
-rw-r--r-- root supergroup -- : har:///test/in/har/0825.har/small/small.3
-rw-r--r-- root supergroup -- : har:///test/in/har/0825.har/small/small_data
). 远程访问,可以使用以下命令
//hdfs-ncst:9000 其中,ncst是NameNode所在节点的HostName
[root@ncst ~]# hadoop fs -lsr har://hdfs-ncst:9000/test/in/har/small.har
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - root supergroup -- : har://hdfs-ncst:9000/test/in/har/small.har/small
-rw-r--r-- root supergroup -- : har://hdfs-ncst:9000/test/in/har/small.har/small/small.1
-rw-r--r-- root supergroup -- : har://hdfs-ncst:9000/test/in/har/small.har/small/small.2
-rw-r--r-- root supergroup -- : har://hdfs-ncst:9000/test/in/har/small.har/small/small.3
-rw-r--r-- root supergroup -- : har://hdfs-ncst:9000/test/in/har/small.har/small/small_data
8)删除har文件必须使用rmr命令,rm是不行的
[root@ncst ~]# hadoop fs -rmr /test/in/har/.har
9). 使用HAR作为MapReduce的输入
[root@ncst ~]# hadoop jar /***/hadoop-mapreduce-examples-2.2.0.jar wordcount \
> har:///test/in/har/0825.har/mapjoin //输入路径
> /test/out/0825/05 //输出路径
存在的问题:
- 存档文件的源文件及目录都不会自动删除,需要手动删除
- 存档过程实际是一个MapReduce过程,所以需要hadoop的MapReduce支持
- 存档文件本身不支持压缩
- 存档文件一旦创建便不可修改,要想从中删除或增加文件,必须重新建立存档文件
- 创建存档文件会创建原始文件的副本,所以至少需要有与存档文件容量相同的磁盘空间
- 使用 HAR 作为MR的输入,MR可以访问其中所有的文件。但是由于InputFormat不会意识到这是个归档文件,也就不会有意识的将多个文件划分到单独的Input-Split中,所以依然是按照多个小文件来进行处理,效率依然不高
- HAR结构:二级索引
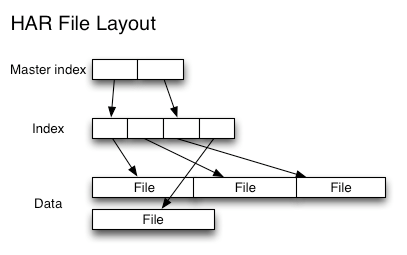
解读:Hadoop Archive的更多相关文章
- Hadoop的Archive归档命令使用指南
hadoop不适合小文件的存储,小文件本省就占用了很多的metadata,就会造成namenode越来越大.Hadoop Archives的出现视为了缓解大量小文件消耗namenode内存的问题. 采 ...
- Hadoop记录-hdfs转载
Hadoop 存档 每个文件均按块存储,每个块的元数据存储在namenode的内存中,因此hadoop存储小文件会非常低效.因为大量的小文件会耗尽namenode中的大部分内存.但注意,存储小文件所需 ...
- Hadoop的理解笔记
1.2Hadoop与云计算的关系1.什么是云计算:一种基于互联网的计算,在其中共享的资源.软件和信息以一种按需的方式提供给计算机和设备 , 就如同日常生活中的电网一样. 什么是Hadoop:Hadoo ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据技术之Hadoop(HDFS)
第1章 HDFS概述 1.1 HDFS产出背景及定义 1.2 HDFS优缺点 1.3 HDFS组成架构 1.4 HDFS文件块大小(面试重点) 第2章 HDFS的Shell操作(开发重点) 1.基本语 ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
- 转载文章——Hadoop学习
转载地址:http://www.iteye.com/blogs/subjects/zy19982004?page=2 一.Hadoop社区版和发行版 社区版:我们把Apache社区一直开发的Hadoo ...
- 从零自学Hadoop(11):Hadoop命令上
阅读目录 序 概述 Hadoop Common Commands User Commands Administration Commands File System Shell 引用 系列索引 本文版 ...
- Hadoop:部署Hadoop Single Node
一.环境准备 1.系统环境 CentOS 7 2.软件环境 OpenJDK # 查询可安装的OpenJDK软件包[root@server1] yum search java | grep jdk... ...
随机推荐
- 170417、Dubbo与Zookeeper、SpringMVC整合和使用(负载均衡、容错)
前言:互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,Dubbo是一个分布式服务框架,在这种情况下诞生的.现在核心业务抽取出来,作为独立的服 ...
- 160302、细聊分布式ID生成方法
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
- angularJs-脏检查
来自:http://www.cnblogs.com/liuyanan/p/4935652.html scope是一个指向应用model的object,也是表达式的执行上下文. scope被放置在一个类 ...
- 每日集成CruiseControl.NET + SVN + Msbuild + NAnt
CruiseControl.NET-1.8.4.0-Setup.exe 是服务器,安装时可以选择生成windows service以便开启,建议测试时不用windows se ...
- 3 differences between Savepoints and Checkpoints in Apache Flink
https://mp.weixin.qq.com/s/nQOxsZUZSiPi7Sx40mgwsA 20181104 3 differences between Savepoints and Chec ...
- Storm-源码分析-Topology Submit-Nimbus-mk-assignments
什么是"mk-assignment", 主要就是产生executor->node+port关系, 将executor分配到哪个node的哪个slot上(port代表slot, ...
- 剑指Offer——把数组排成最小的数
题目描述: 输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个.例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323. 分析: 排 ...
- HDFS基本工作机制
- MYSQL--表分区、查看分区(转)
一. mysql分区简介 数据库分区 数据库分区是一种物理数据库设计技术.虽然分区技术可以实现很多效果,但其主要目的是为了在特定的SQL操作中减少数据读写的总量以缩减sql语句的响应时间, ...
- 调试maven源代码
下载源代码,导入idea 运行MavenCli ,设置vm参数 -Dclassworlds.conf=/Users/fsq/Downloads/apache-maven-3.6.2.0/bin/m2. ...