吴裕雄 python 机器学习——聚类
import numpy as np
import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7):
'''
生成用于聚类的数据集 :param centers: 聚类的中心点组成的数组。如果中心点是二维的,则产生的每个样本都是二维的。
:param num: 样本数
:param std: 每个簇中样本的标准差
:return: 用于聚类的数据集。是一个元组,第一个元素为样本集,第二个元素为样本集的真实簇分类标记
'''
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5)
# X,labels_true = create_data(centers,num=100,std=0.7)
# print(X,labels_true)
print(len(X))
print(len(labels_true))
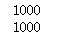
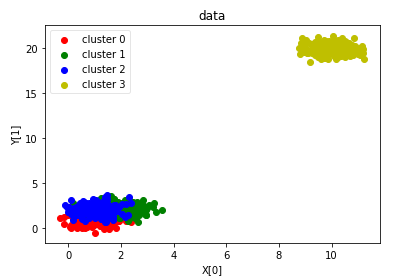
def plot_data(*data):
'''
绘制用于聚类的数据集
'''
X,labels_true=data
labels=np.unique(labels_true)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
# 每个簇的样本标记不同的颜色
colors='rgbyckm'
for i,label in enumerate(labels):
position=labels_true==label
ax.scatter(X[position,0],X[position,1],label="cluster %d"%label,color=colors[i%len(colors)])
ax.legend(loc="best",framealpha=0.5)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[1]")
ax.set_title("data")
plt.show() plot_data(X,labels_true) # 绘制用于聚类的数据集
吴裕雄 python 机器学习——聚类的更多相关文章
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- 吴裕雄 python 机器学习——层次聚类AgglomerativeClustering模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——线性判断分析LinearDiscriminantAnalysis
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——ElasticNet回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
随机推荐
- chrome crx插件存档
https://github.com/mdamien/chrome-extensions-archive
- centos 命令行和图形桌面模式的切换
1.安装系统时建议安装图形界面,毕竟图形桌面下安装程序,比较方便 2.系统部署完成后可以切换到命令行界面:打开一个SHELL窗口运行 init 3 即可进入命令行界面.恢复图形用init 5 3.进入 ...
- 一个新手后端需要了解的前端核心知识点之position(一)
以下内容是基于观看慕课网视频教程总结的知识点,边打代码边总结,符合自己的思维习惯.不是针对新手入门 我做程序的初衷是想做一个网站出来.HTML语言当然重要啊,缺什么就百度什么,很浪费时间,还是好好的打 ...
- Hibernate环境搭建
Hibernate的环境搭建,主要步骤分为一下四步: 首先创建一个工程,在工程里创建一个实体类User,在这个实体类中必须包含无参的构造器,和这个类对属性的存取方法(getter and setter ...
- C++ generic tools -- from C++ Standard Library
今晚学了一下C++标准程序库, 来简单回顾和总结一下. 1.pair 结构体 // defined in <utility> , in the std namespace namespac ...
- 编写高质量代码改善C#程序的157个建议——建议155:随生产代码一起提交单元测试代码
建议155:随生产代码一起提交单元测试代码 首先提出一个问题:我们害怕修改代码吗?是否曾经无数次面对乱糟糟的代码,下决心进行重构,然后在一个月后的某个周一,却收到来自测试版的报告:新的版本,没有之前的 ...
- [LeetCode 题解]: Maximum Depth of Binary Tree
Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the long ...
- 【RabbitMQ学习记录】- 消息队列存储机制源码分析
本文来自 网易云社区 . RabbitMQ在金融系统,OpenStack内部组件通信和通信领域应用广泛,它部署简单,管理界面内容丰富使用十分方便.笔者最近在研究RabbitMQ部署运维和代码架构,本篇 ...
- [转载] Linux 下产生和调试core文件
原地址:http://blog.csdn.net/shaovey/article/details/2744487 linux下如何产生core,调试core 在程序不寻常退出时,内核会在当前工作目录下 ...
- 【《Effective C#》提炼总结】提高Unity中C#代码质量的22条准则
引言 原则1尽可能地使用属性而不是可直接访问的数据成员 原则2偏向于使用运行时常量而不是编译时常量 原则3 推荐使用is 或as操作符而不是强制类型转换 原则4 推荐使用条件属性而不是if条件编译 原 ...