【排序】堆排序,C++实现
原创文章,转载请注明出处!
# 预备知识
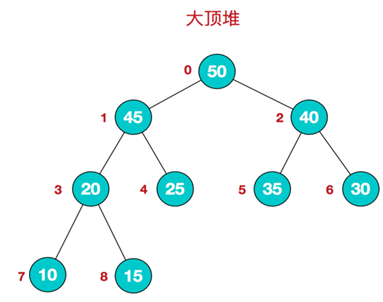
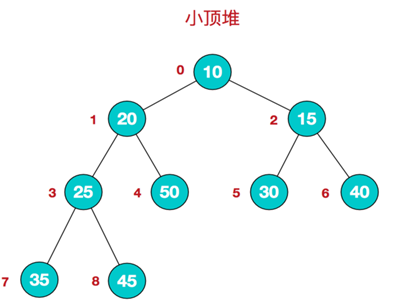
堆是一种特殊的树形数据结构,即完全二叉树。堆分为大根堆和小根堆,大根堆为根节点的值大于两个子节点的值;小根堆为根节点的值小于两个子节点的值,同时根节点的两个子树也分别是一个堆。
# 基本思路
- 步骤一:建立大根堆--将n个元素组成的无序序列构建一个大根堆,
- 步骤二:交换堆元素--交换堆尾元素和堆首元素,使堆尾元素为最大元素;
- 步骤三:重建大根堆--将前n-1个元素组成的无序序列调整为大根堆
重复执行步骤二和步骤三,直到整个序列有序。
# 图示说明
- 步骤一:建立大根堆
① 无序序列建立完全二叉树
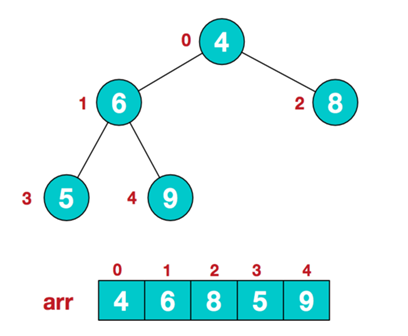
② 从最后一个叶子节点开始,从左到右,从下到上调整,将完全二叉树调整为大根堆
a.找到第1个非叶子节点6,由于6的右子节点9比6大,所以交换6和9。交换后,符合大根堆的结构。

c.找到第2个非叶子节点4,由于的4左子节点9比4大,所以交换4和9。交换后不符合大根堆的结构,继续从右到左,从下到上调整。

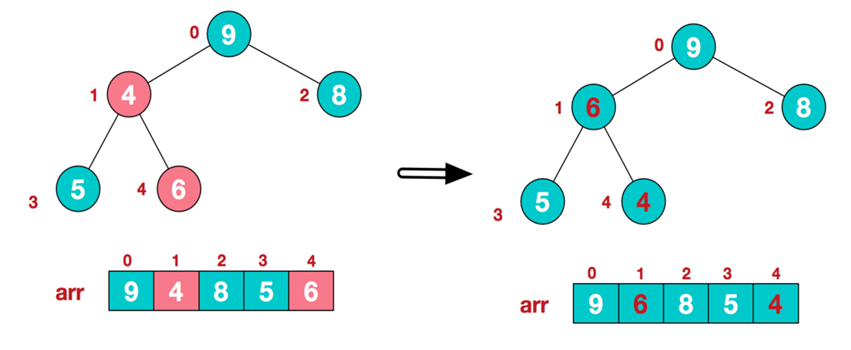
- 步骤二:交换堆元素(交换堆首和堆尾元素--获得最大元素)
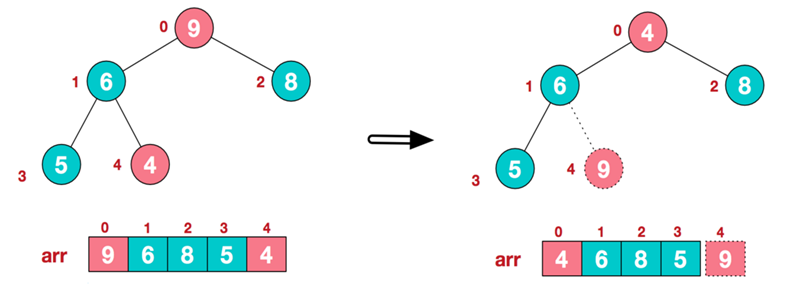
- 步骤三:重建大根堆(前n-1个元素)
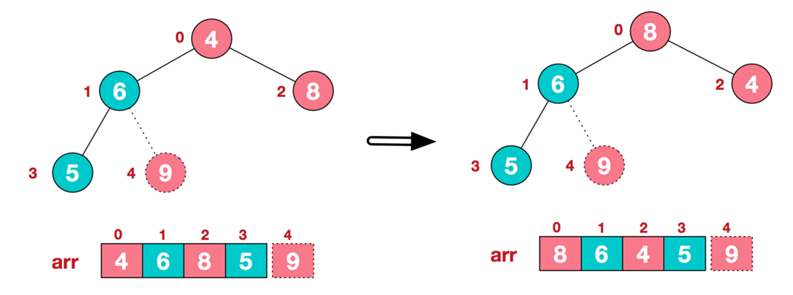
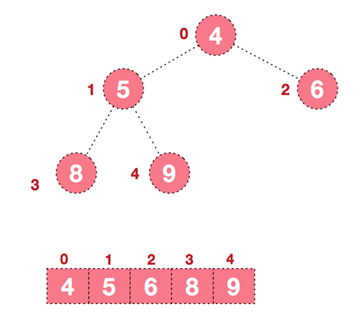
- 重复执行步骤二和步骤三,直到整个序列有序
# C++代码
#include<iostream>
#include<vector>
using namespace std; // 递归方式构建大根堆(len是arr的长度,index是第一个非叶子节点的下标)
void adjust(vector<int> &arr, int len, int index)
{
int left = 2*index + 1; // index的左子节点
int right = 2*index + 2;// index的右子节点 int maxIdx = index;
if(left<len && arr[left] > arr[maxIdx]) maxIdx = left;
if(right<len && arr[right] > arr[maxIdx]) maxIdx = right; if(maxIdx != index)
{
swap(arr[maxIdx], arr[index]);
adjust(arr, len, maxIdx);
} } // 堆排序
void heapSort(vector<int> &arr, int size)
{
// 构建大根堆(从最后一个非叶子节点向上)
for(int i=size/2 - 1; i >= 0; i--)
{
adjust(arr, size, i);
} // 调整大根堆
for(int i = size - 1; i >= 1; i--)
{
swap(arr[0], arr[i]); // 将当前最大的放置到数组末尾
adjust(arr, i, 0); // 将未完成排序的部分继续进行堆排序
}
} int main()
{
vector<int> arr = {8, 1, 14, 3, 21, 5, 7, 10};
heapSort(arr, arr.size());
for(int i=0;i<arr.size();i++)
{
cout<<arr[i]<<endl;
}
return 0;
}
# 参考文献:
文中配图参考地址
【排序】堆排序,C++实现的更多相关文章
- 排序 选择排序&&堆排序
选择排序&&堆排序 1.选择排序: 介绍:选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理如下.首先在未排序序列中找到最小(大)元素,存放到排序序列的起始 ...
- C# 插入排序 冒泡排序 选择排序 高速排序 堆排序 归并排序 基数排序 希尔排序
C# 插入排序 冒泡排序 选择排序 高速排序 堆排序 归并排序 基数排序 希尔排序 以下列出了数据结构与算法的八种基本排序:插入排序 冒泡排序 选择排序 高速排序 堆排序 归并排序 基数排序 希尔排序 ...
- 选择排序---堆排序算法(Javascript版)
堆排序分为两个过程: 1.建堆. 堆实质上是完全二叉树,必须满足:树中任一非叶子结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字. 堆分为:大根堆和小根堆,升序排序采用大根堆,降序排序 ...
- 八大排序算法之四选择排序—堆排序(Heap Sort)
堆排序是一种树形选择排序,是对直接选择排序的有效改进. 基本思想: 堆的定义如下:具有n个元素的序列(k1,k2,...,kn),当且仅当满足 时称之为堆.由堆的定义可以看出,堆顶元素(即第一个元素) ...
- 选择排序—堆排序(Heap Sort) 没看明白,不解释
堆排序是一种树形选择排序,是对直接选择排序的有效改进. 基本思想: 堆的定义如下:具有n个元素的序列(k1,k2,...,kn),当且仅当满足 时称之为堆.由堆的定义可以看出,堆顶元素(即第一个元素) ...
- 内部排序->选择排序->堆排序
文字描述 堆排序中,待排序数据同样可以用完全二叉树表示, 完全二叉树的所有非终端结点的值均不大于(或小于)其左.右孩子结点的值.由此,若序列{k1, k2, …, kn}是堆,则堆顶元素(或完全二叉树 ...
- 选择排序:直接选择排序&堆排序
上一篇中, 介绍了交换排序中的冒泡排序和快速排序, 那么这一篇就来介绍一下 选择排序和堆排序, 以及他们与快速排序的比较. 一.直接选择排序 1. 思想 在描述直接选择排序思想之前, 先来一个假设吧. ...
- 直接选择排序&堆排序
1.什么是直接选择排序? 直接选择排序(Straight Select Sort)是一种简单的排序方法,它的基本思想是:通过n-i次关键字之间的比较,从n-i+1个记录中选出关键字最小的记录,并和第i ...
- python 排序 堆排序
算法思想 : 堆排序利用堆数据结构设计的一种排序算法,堆是一种近似完全二叉树的结构,同时满足堆积的性质,即对于任意的i均有ki>=k(2i+1),ki>=k(2i+2) 步骤: 将数组转化 ...
- 九度OJ 1202 排序 -- 堆排序
题目地址:http://ac.jobdu.com/problem.php?pid=1202 题目描述: 对输入的n个数进行排序并输出. 输入: 输入的第一行包括一个整数n(1<=n<=10 ...
随机推荐
- Redis中RedisTemplate和Redisson管道的使用
当对Redis进行高频次的命令发送时,由于网络IO的原因,会耗去大量的时间.所以Redis提供了管道技术,就是将命令一次性批量的发送给Redis,从而减少IO. 一.Jedis对redis的管道进行操 ...
- pt-table-checksum校验mysql主从数据一致性
主从数据的一致性校验是个头疼的问题,偶尔被业务投诉主从数据不一致,或者几个从库之间的数据不一致,这会令人沮丧.通常我们仅有一种办法,热备主库,然后替换掉所有的从库.这不仅代价非常大,而且类似治标不治本 ...
- 虚拟机 Ubuntu18.04 tensorflow cpu 版本
虚拟机 Ubuntu18.04 tensorflow cpu 版本 虚拟机VMware 配置: 20G容量,可扩充 2G内存,可扩充 网络采用NAT模式 平台:win10下的Ubuntu18.04 出 ...
- C4 文件和目录:APUE 笔记
C4: 文件和目录 本章主要讨论stat函数及其返回信息,通过修改stat结构字段,了解文件属性. struct stat结构定义如下: struct stat { __dev_t st_dev; / ...
- 【转发】Linux中设置服务自启动的三种方式
有时候我们需要Linux系统在开机的时候自动加载某些脚本或系统服务 主要用三种方式进行这一操作: ln -s 在/etc/rc.d/rc*.d目录中建立/e ...
- [mybatis]Record与Example的用法
一.Record 一个Record是一个Dao对象(继承Mapper接口),tkmybatis会将record自动映射成sql语句,record中所有非null的属性都作为sql语句,如: 映射的sq ...
- Java连接MySQL数据库——代码
工具:eclipse MySQL5.7.17 MySQL连接驱动:mysql-connector-java-5.1.43.jar 加载驱动:我是用MAVEN进行管理 数据库连接信息: 数据库名称:wu ...
- HDU 4815 概率dp,背包
Little Tiger vs. Deep Monkey Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65535/65535 K ( ...
- EASYUI 1.4版 combobox firefox 下不支持中文检索的问题
easyui 的combobox 在IE下面输入中文,可以自动实现筛选和检索的功能,但是在firefox下面不可以. 于是查了一些资料,发现原来是浏览器对于中文输入法的处理问题,对于chrome 和 ...
- HDU 4734 F(x) ★(数位DP)
题意 一个整数 (AnAn-1An-2 ... A2A1), 定义 F(x) = An * 2n-1 + An-1 * 2n-2 + ... + A2 * 2 + A1 * 1,求[0..B]内有多少 ...