ElasticSearch 分布式及容错机制
1 ElasticSearch分布式基础
1.1 ES分布式机制
- 分布式机制:Elasticsearch是一套分布式的系统,分布式是为了应对大数据量。它的特性就是对复杂的分布式机制隐藏掉。
- 分片机制:数据存储到哪个分片,副本数据写入另外分片。
- 集群发现机制:新启动es实例,会自动加入集群。
- shard负载均衡:大量数据写入及查询,es会将数据平均分配。举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均匀分配,以保持每个节点的均衡的读写负载请求。
- shard副本:新增副本数,分片重分配。
1.2 垂直与水平扩容
垂直扩容:使用更加强大的服务器替代老服务器。但单机存储及运算能力有上线。且成本直线上升。如10台1T的服务器1万,单个10T服务器可能20万。
水平扩容:采购更多服务器,加入集群。对于ES来说,一般采用水平扩容的方式。
1.3 rebalance
当新增或减少es实例时,或者新增加数据或者删除数据时,就会导致某些服务器负载过重或者过轻。es集群就会将数据重新分配,保持一个相对均衡的状态。
1.4 master节点
(1)管理es集群的元数据
- 创建删除节点
- 创建删除索引
(2)默认情况下,es会自动选择一台机器作为master,因为任何一台机器都可能被选择为master节点,所以单点故障的情况可以忽略不计。
1.5 节点对等
- 节点对等,每个节点都能接收所有的请求
- 自动请求路由
- 响应收集
二、分片shard、副本replica机制
2.1 分片shard
在ES中,索引会被切分成n个分片,每个分片是独立的lucene索引,可以完成搜索分析存储等工作。
分片的好处:
- 如果一个索引数据量很大,会造成硬件硬盘和搜索速度的瓶颈。如果分成多个分片,分片可以分摊压力。
- 分片允许用户进行水平的扩展和拆分
- 分片允许分布式的操作,可以提高搜索以及其他操作的效率
副本的好处:
- 当一个分片失败或者下线时,备份的分片可以代替工作,提高了高可用性。
- 备份的分片也可以执行搜索操作,分摊了搜索的压力。
2.2 shard&replica机制
- 每个index包含一个或多个shard
- 每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
- 增减节点时,shard会自动在nodes中负载均衡
- primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
- replica shard是primary shard的副本,负责容错,以及承担读请求负载
- primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
- primary shard的默认数量是1,replica默认是1,默认共有2个shard,1个primary shard,1个replica shard。注意:es7以前primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
- primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
三、创建index
3.1 单node环境下
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index1
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}3.2 两个node环境下
(1)replica shard分配:3个primary shard,1node,3个replica shard,1 node
(2)primary ---> replica同步
(3)读请求:primary/replica

四、横向扩容
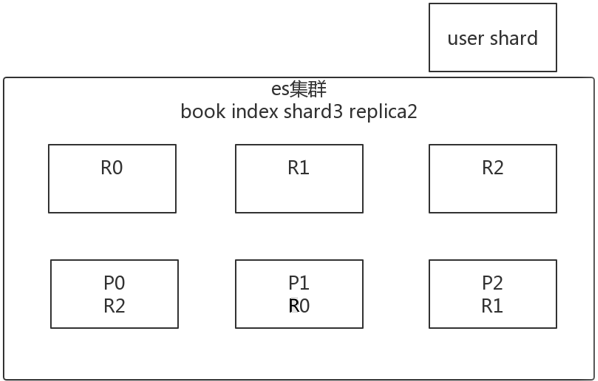
假如说存在一个book索引,shard3 replica1
- 分片自动负载均衡,分片向空闲机器转移。
- 每个节点存储更少分片,系统资源给与每个分片的资源更多,整体集群性能提高。
- 扩容极限:节点数大于整体分片数,则必有空闲机器。
- 超出扩容极限时,可以增加副本数,如设置副本数为2,总共3*3=9个分片。9台机器同时运行,存储和搜索性能更强。容错性更好。
- 容错性:只要一个索引的所有主分片在,集群就就可以运行。
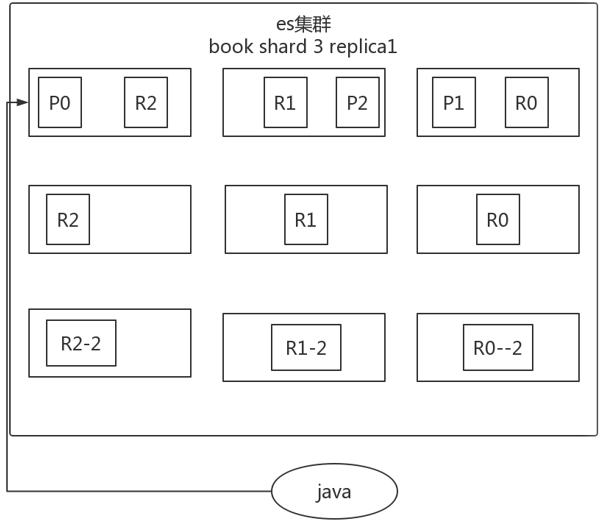
五、es容错机制
以3分片,2副本数,3节点为例介绍。
- master node宕机,自动master选举,集群为red
- replica容错:新master将replica提升为primary shard,yellow
- 重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,green
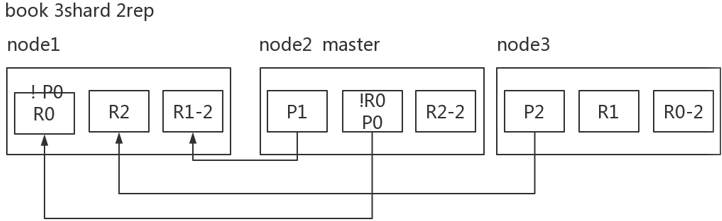
以上图为例:
在node1宕机的情况下,那么P0 shard就会消失,所有的主分片不是全active,那么集群的状态是red。
- 容错第一步,重新选举master节点。承担master相关功能。
- 容错第二步,新master将丢失的P0 shard(主分片)对应的R0 replica(副本分片)提升为主分片,现在的集群状态为yellow并且少一个副本分片,但是现在集群已经可以恢复使用了。
- 容错第三步,重启故障node,新master会感知到新节点加入,将缺失的副本分片copy一份到新的node上面,copy的是被提升为主分片的分片。现在集群已经完全恢复,状态为green。
ElasticSearch 分布式及容错机制的更多相关文章
- Elasticsearch和HDFS 容错机制 备忘
1.Elasticsearch 横向扩容以及容错机制http://www.bubuko.com/infodetail-2499254.html 2.HDFS容错机制详解https://www.cnbl ...
- Elasticsearch由浅入深(二)ES基础分布式架构、横向扩容、容错机制
Elasticsearch的基础分布式架构 Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式系统,分布式是为了应对大数据量. Elasticsearch ...
- Elasticsearch学习笔记(四)ElasticSearch分布式机制
一.Elasticsearch对复杂分布式机制透明的隐藏特性 1.分片机制: (1)index包含多个shard,每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处 ...
- Elasticsearch分布式机制和document分析
1. Elasticsearch对复杂分布式机制的透明隐藏特性 1.1)分片机制 1.2)集群发现机制 1.3)shard负载均衡 1.4)shard副本,请求路由,集群扩容,shard重分配 2. ...
- Elasticsearch 横向扩容以及容错机制
写在前面的话:读书破万卷,编码如有神-------------------------------------------------------------------- 参考内容: <Ela ...
- elasticsearch从入门到出门-08-Elasticsearch容错机制:master选举,replica容错,数据恢复
假如: 9 shard,3 node Elasticsearch容错机制:master选举,replica容错,数据恢复 最佳分配情况: 这样分配之后,不管其中哪个node 宕机这个es 依然可以提供 ...
- [源码解析] 并行分布式框架 Celery 之 容错机制
[源码解析] 并行分布式框架 Celery 之 容错机制 目录 [源码解析] 并行分布式框架 Celery 之 容错机制 0x00 摘要 0x01 概述 1.1 错误种类 1.2 失败维度 1.3 应 ...
- ElasticSearch教程——分片、扩容以及容错机制(转学习使用)
一.Primary shard和replica shard机制 1.index包含多个shard; 2.每个shard都是一个最小的工作单元,承载部分的数据,Lucene实例,完整的简历索引和处理请求 ...
- Flink资料(2)-- 数据流容错机制
数据流容错机制 该文档翻译自Data Streaming Fault Tolerance,文档描述flink在流式数据流图上的容错机制. ------------------------------- ...
随机推荐
- ARC084F - XorShift
有两种解法,这里都放一下. 解法一 首先易知异或运算可以视作是 \(\mathbb{F}_2\) 意义下的每一位独立的加法. 因此我们可以考虑对于每个二进制数 \(s\) 构造一个多项式 \(F(x) ...
- Java基础复习(三)
1. &和&&的区别. &和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则 ...
- Ubuntu18 用新用户登录后退格键/方向键/制表键 乱码
Ubuntu18新建用户后,用新用户登录,此时 退格键Backspace 变成了 ^H,且方向键.制表键.Del键等均失效 这样会造成很多的麻烦,解决方式有两种: 方式1:Ctrl + Backspa ...
- Java执行cmd命令、bat脚本、linux命令,shell脚本等
1.Windows下执行cmd命令 如复制 D:\tmp\my.txt 到D:\tmp\my_by_only_cmd.txt 现文件如图示: 执行代码: private static void run ...
- mysql data local的使用导入与导出数据到.txt
一.先创建表 CREATE TABLE stu(id INT UNSIGNED AUTO_INCREMENT,NAME VARCHAR(15) UNIQUE, /* 唯一约束 , 可以不填写,如果填写 ...
- 利用shell脚本[带注释的]部署单节点多实例es集群(docker版)
文章目录 目录结构 install_docker_es.sh elasticsearch.yml.template 没事写写shell[我自己都不信,如果不是因为工作需要,我才不要写shell],努力 ...
- win10+redhat8双系统安装(非虚拟机)
win10+redhat8双系统安装(非虚拟机) 记录这次在原有的win10系统基础上,安装了redhat 8操作系统,过程中也出现了一些状况,百度了许久,许多文章并没有效果,摸爬滚打,有了这一次的记 ...
- 使用Sinopia部署私有npm仓库
使用Sinopia部署私有npm仓库 [root@localhost ~]# hostnamectl set-hostname --static npm-server [root@npm-server ...
- Linux-CPU优化之平均负载率
一.平均负载率定义 平均负载是指单位时间内,系统处于可运行状态 和不可中断状态 的平均进程数,也就是平均活跃进程数,它和CPU 使用率并没有直接关系. 可运行状态的进程:是指正在使用 CPU 或者正在 ...
- 如何封装安全的go
如何封装安全的go 在业务代码开发过程中,我们会有很大概率使用go语言的goroutine来开启一个新的goroutine执行另外一段业务,或者开启多个goroutine来并行执行多个业务逻辑.所以我 ...