tapdata问题
- 聚合节点写两个不同的聚合函数,只需要在关联目标节点的目标字段中添加上分组字段,其他字段不用做关联
- 聚合节点写两个相同的聚合函数,只需要在关联目标节点的目标字段中左右两边都添加上_id,会输出两条数据,但是其中每条数据都存在_id._tapd8_sub_name的key,value就为设置的该聚合的子处理名称。
报错处理:出现报错的话,就在任务配置中,原来的【去重写入机制】,智能去重写入,改成强制去重写入;重新运行任务,你再看下 - tapdata自有的时间戳转时间格式:https://www.yuque.com/knbase/tapdata-enterprise/data-replication_script_javascript
- tapdata使用js过滤打印日志: log.info("要打印的内容")
- 如果想要增量有效 在原表节点中就不能设置智能过滤和sql过滤是吧,直接在原表节点后面加上js过滤节点或者 row filter过滤节点是么
- 聚合后的全量同步数据量和sql分组聚合查出来的不对上
问题出现原因:
1.在聚合后的表上,如果还要分表 ,这些分表要最终关联成一张表的时候,关联字段就必须一致和分组字段相同,因为这些分表都是通过聚合节点输出的
2.分表上的数据写入模式也要和主表上的数据写入模式一样,都要弄成【更新已存在或插入新数据】,分表不能写成【仅更新时插入】
3.数据量大的话,建议复制源表结构,插入少部分数据,这样容易调试 - 增量同步都不成功,只能够全量同步,并且在原表节点中关掉了智能和sql过滤,这个应该怎么解决呢。
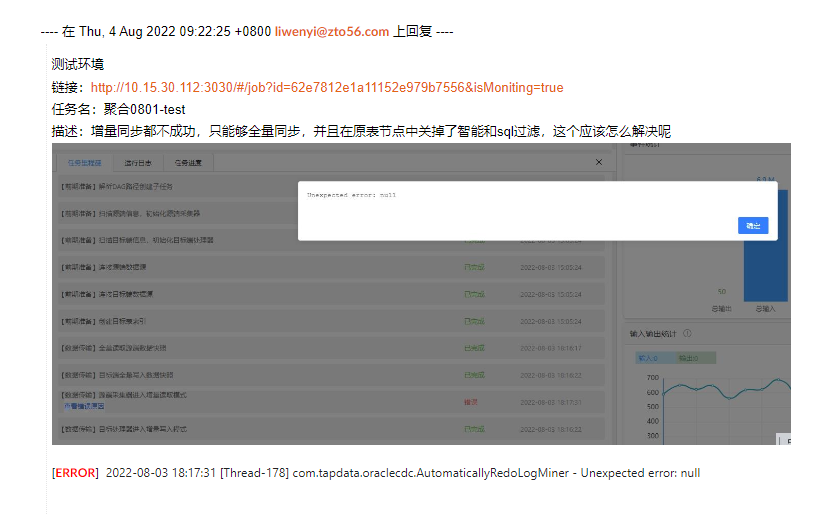
任务日志,在报错前发现有5次重试,最开始由源端Oracle logminer丢失所致,(微信是源库增量日志过期了导致)日志报警如下: [WARN] 2022-08-03 18:16:41 [Thread-178] com.tapdata.oraclecdc.AutomaticallyRedoLogMiner -
Unexpected error: ORA-01291: missing logfile ORA-06512: at "SYS.DBMS_LOGMNR", line 58 ORA-06512: at line 2 ,
retry time: 1, stacks: java.sql.SQLException: ORA-01291: missing logfile ORA-06512: at "SYS.DBMS_LOGMNR",
line 58 ORA-06512: at line 2 at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:509) at
oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:461) at oracle.jdbc.driver.T4C8Oall.processError(T4C8Oall.java:1104)
at oracle.jdbc.driver.T4CTTIfun.receive(T4CTTIfun.java:550) at oracle.jdbc.driver.T4CTTIfun.doRPC(T4CTTIfun.java:268) at oracle.jdbc.driver.
T4C8Oall.doOALL(T4C8Oall.java:655) at oracle.jdbc.driver.T4CPreparedStatement.doOall8(T4CPreparedStatement.java:270) at oracle.jdbc.driver.T4CPreparedStatement.
doOall8(T4CPreparedStatement.java:91) at oracle.jdbc.driver.T4CPreparedStatement.executeForRows(T4CPreparedStatement.java:970) at oracle.jdbc.driver.OracleStatement.
doExecuteWithTimeout(OracleStatement.java:1205) at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:3666) at oracle.jdbc.driver.
T4CPreparedStatement.executeInternal(T4CPreparedStatement.java:1426) at oracle.jdbc.driver.OraclePreparedStatement.execute(OraclePreparedStatement.java:3778) at oracle.
jdbc.driver.OraclePreparedStatementWrapper.execute(OraclePreparedStatementWrapper.java:1081) at com.tapdata.oraclecdc.AbstractRedoLogMiner.getLogContentsResultSet(Abstra
ctRedoLogMiner.java:1212) at com.tapdata.oraclecdc.AutomaticallyRedoLogMiner.startMine(AutomaticallyRedoLogMiner.java:177) at com.tapdata.oraclecdc.OracleConnector.lambd
a$startConnect$1(OracleConnector.java:440) at java.lang.Thread.run(Thread.java:748) Caused by: Error : 1291, Position : 0, Sql = BEGIN SYS.DBMS_LOGMNR.START_LOGMNR( START
SCN => :1 , OPTIONS => SYS.DBMS_LOGMNR.DDL_DICT_TRACKING + SYS.DBMS_LOGMNR.DICT_FROM_REDO_LOGS + SYS.DBMS_LOGMNR.CONTINUOUS_MINE + SYS.DBMS_LOGMNR.NO_SQL_DELIMITER ); END;
, OriginalSql = BEGIN SYS.DBMS_LOGMNR.START_LOGMNR( STARTSCN => ?, OPTIONS => SYS.DBMS_LOGMNR.DDL_DICT_TRACKING + SYS.DBMS_LOGMNR.DICT_FROM_REDO_LOGS + SYS.DBMS_LOGMNR.CON
TINUOUS_MINE + SYS.DBMS_LOGMNR.NO_SQL_DELIMITER ); END;, Error Msg = ORA-01291: missing logfile ORA-06512: at "SYS.DBMS_LOGMNR", line 58 ORA-06512: at line 2 at oracle.jdbc
.driver.T4CTTIoer11.processError(T4CTTIoer11.java:513) ... 17 more 平台系统设置中关闭了共享挖掘;
共享挖掘任务也停止;
所以任务在增量阶段,直接挖取Oracle库的日志; 解决方式,
1. 了解Oracle源库redo log日志保留的时长;
2. 任务重置重新启动运行;
3. 或者采用共享日志挖掘的方式;
tapdata问题的更多相关文章
- Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布
https://www.bilibili.com/video/BV1tT411g7PA/?aid=470724972&cid=766317673&page=1 点击上方链接,一分钟快速 ...
- Tapdata Cloud 2.1.5来啦:新增支持Amazon RDS数据库,错误日志查询更便捷,Agent部署细节再优化
需求持续更新,优化一刻不停--Tapdata Cloud 2.1.5 来啦! 最新发布的版本中,数据连接再上新,同时新增任务报错相关信息快速查询入口,开始支持 JVM 参数自定义设置. 更 ...
- Tapdata x 轻流,为用户打造实时接入轻流的数据高速通道
在全行业加速布局数字化的当口,如何善用工具,也是为转型升级添薪助力的关键一步. 那么当轻量的异构数据实时同步工具,遇上轻量的数字化管理工具,将会收获什么样的新体验?此番 Tapdata 与轻流 ...
- 活动报名:以「数」制「疫」,解密 Tapdata 在张家港市卫健委数字化防疫场景下的最佳实践
疫情两年有余,全国抗疫攻防战步履不停.在"动态清零"总方针的指导下,国内疫情防控工作渐趋规范化.常态化.健康码.行程卡.疫情地图.电子哨兵.核酸码.场所码--各类精准防疫手 ...
- Tapdata Cloud 2.1.4 来啦:数据连接又上新,PolarDB MySQL、轻流开始接入,可自动标记不支持的字段类型
需求持续更新,优化一刻不停--Tapdata Cloud 2.1.4 来啦! 最新发布的版本中,在新增数据连接之余,默认标记不支持同步的字段类型,避免因此影响任务的正常运行. 更新速览 ① 数 ...
- 活动报名 | 如何基于开源项目 Tapdata PDK,快速完成数据源和目标的开发?
近日,Tapdata 启动 PDK 插件生态共建计划,宣布开源插件开发框架 Tapdata PDK,将自身的数据接口能力开放出来,帮助开发者根据实际需求,自助接入数据源和目标,快速开启「Data ...
- Tapdata 与阿里云 PolarDB 开源数据库社区联合共建开放数据技术生态
近日,阿里云 PolarDB 开源数据库社区宣布将与 Tapdata 联合共建开放数据技术生态.在此之际,一直专注实时数据服务平台的 Tapdata ,也宣布开源其数据源开发框架--PDK(Plu ...
- Tapdata PDK 生态共建计划启动!Doris、OceanBase、PolarDB、SequoiaDB 等十余家厂商首批加入
2022年4月7日,Tapdata 正式启动 PDK 插件生态共建计划,致力于全面连接数据孤岛,加速构建更加开放的数据生态,以期让各行各业的使用者都能释放数据的价值,随时获取新鲜的数据.截至目前, ...
- Whats On Tap | Tapdata Cloud 如何助力大型家居连锁商城推进数字化经营?
Tapdata Cloud 的操作有多便捷,上手试一下就能充分了解了.--Tapdata Cloud 用户 | 报表实施 @某大型家居服务平台 一边是监管政策趋严,推动房地产回归本源,存量竞争时代开启 ...
- Tapdata Cloud 2.1.2 来啦:大波细节已就绪!字段类型可批量修改、支持微信扫码登录、新增支持 Vika 为目标
Tapdata Cloud cloud.tapdata.net 让数据实时可用 Tapdata Cloud 是国内首家异构数据库实时同步云平台,目前支持 Oracle.MySQL.PG.SQL Ser ...
随机推荐
- VMware Workstation Pro 16、docker和Mysql相关
VMware Workstation Pro 16安装参考 docker容器的使用参考 Docker 容器使用 Docker Hub资源 Docker Hub Mysql数据库安装参考 Mysql数据 ...
- FMC DA子卡设计原理图:FMCJ465-2路 16bit 12.6GSPS FMC DA子卡
FMCJ465-2路 16bit 12.6GSPS FMC DA子卡 一.板卡概述: FMCJ465是一款转换速率最高为12.6GSPS 的 DAC 回放板,DAC位数16bit; 板卡基于 ...
- 你到底懂不懂JavaScript?来做做这12道面试题试试!
携手创作,共同成长!这是我参与「掘金日新计划 · 8 月更文挑战」的第 21 天,点击查看活动详情 JavaScript 是每一个前端开发者都应该掌握的基础技术,但是很多时候,你可能并不完全懂 Jav ...
- python获取某一年的所有节假日
注:chinese_calander库需要每年手动更新一次 import datetime import chinese_calendar def get_holidays(year=None, in ...
- Spring的IOC源码分析
Spring IOC 容器源码分析 Spring 最重要的概念是 IOC 和 AOP,本篇文章其实就是要带领大家来分析下 Spring 的 IOC 容器.既然大家平时都要用到 Spring,怎么可以不 ...
- redis底层数据结构之简单动态字符串(SDS)
简单动态字符串(simple dynamic string,SDS) redis使用C语言编写的,但是redis的字符串却不是C语言中的字符串(以空字符'\0'结尾的字符数组),redis定义了一种简 ...
- Tiup离线安装TIDB集群4.0.16版本
环境:centos7.6 中控机:8.213.8.25(内网) 可用服务器8.213.8.25-8.213.8.29 一.准备 TiUP 离线组件包 方法1:外网下载离线安装包拷贝进内网服务器 在Ti ...
- 使用yum快速安装mysql-5.7(用于测试)
1)CentOS 7 下安装 MySQL 5.7 下载并安装MySQL官方的 Yum Repository [wget -i -c http://dev.mysql.com/get/mysql57-c ...
- Python与CSharp之间内存共享互传信息
C#写入字符串到共享内存 try { long t = 1 << 10 << 10; var mmf = MemoryMappedFile.CreateOrOpen(" ...
- Windows10 WSL开启SSH登录
1.wsl 安装ssh服务(使用的是ubuntu)sudo apt install openssh-server 2.修改配置文件sudo vim /etc/ssh/sshd_config关键的几处修 ...