03-逻辑综合工具 - Design Compiler
逻辑综合工具DC
IC设计流程,市场-->制定spec-->RTL(同时进行sim,通过alint检查RTL有没有错误)-->systhesis(逻辑综合)-->PR(STA)-->Tape Out
- 逻辑综合将RTL转换为Gate Netlist,这些Gate时没有物理概念的,只是一些逻辑,需要摆放到具体的位置。
- 逻辑综合还需要满足timing,否则会出现亚稳态问题。
- 逻辑正确,Timing没有问题,然后进行优化。
1 什么是逻辑综合?
将前端设计工程师编写的RTL,映射到特定的工艺库(Fab提供)上,通过添加约束,对RTL代码进行逻辑优化,形成门级网表。
- 约束
- area--面积约束
- timing--时序约束
- .......
- 优化
- 删除冗余的逻辑--简化逻辑--cell变少--delay减少--timing更好
- 简化逻辑之后--面积也会减少
- .......
2 逻辑综合在ASIC设计流程的阶段
Idea-->Function description-->RTL-->RTL simulation and verification-->Gate-Level Netlist-->Physical implementation-->Tape out-->Post-silicon verfication
- Physical implementation -- 将门级逻辑转换为实际的物理电路--会使用到physical library
3 逻辑综合的转换过程
3.1 Translation
VHDL/Verilog/System verilog 通过 translation 转换为generic(GTECH) netlist,GTECH netlist 相当于一个中间过程的网表。
- 当DC将RTL代码读入之后,会自动地将代码Translate成GETCH网表。GTECH是synopsys自家开发的一种通用的,独立于工艺的标准库,里面有与门、非门、寄存器等各种基本单元。此时GTECH网表仍然保持和rtl代码的相同的层次结构。
3.2 Logic Optimization
3.3 Gate Mapping
GETCH netlist 被映射为 gate-level standard cells
Design Compiler需要的输入
- RTL description
- Timing constraints
- 工艺库
4 DC工具的流程
- Load library and design
- Apply timing constraints and design rules constraints
- design rules constraints(驱动能力的约束)
- Systhesis the design
- Analyze the rules
- 是否满足timing
- Write out the design data
5 DC综合的方式
使用DC执行逻辑综合,一般有三种方式,通常使用dc_shell配合脚本执行命令,执行综合。
- Design Vision启动GUI
- dc_shell 启动命令行
- batch_mode,将综合使用命令写到syn.tcl脚本中,并记录log
dc_shell -f syn.tcl | tee -i sys.log
6 DC参数设置
6.1 search_path
在综合过程中,设置文件读取路径,让工具去进行搜索文件。设置地文件路径通常包含verilog、library和scripts。
set_app_var search_path "$search_path ./rtl ./scripts ./libs"
6.2 target library and link library
target library是指定工艺库的名称,其中的cell对应于设计人员想要让DC推断出并且映射到的库单元。
target_library--RTL需要mapping到target_library,将lib-->编译到db类型的库,放到target_library中进行综合
link library定义其库单元只用于参考的库名称,也就是说DC不是使用link library中的单元进行推断。
为了更好的了解target library和link library需要先弄明白DC中的设计层次
DC中的设计层次
- top层,包含很多小的module(或者实例化的IP)
- 小的module(不同的.v文件,会在加载设计时和top一起被read_verilog.v加载)
- macros(就比如买一个解码器的IP,ROM,RAM etc)
- 最小的门级单元,比如OR XOR之类。
- target ibrary即目标工艺库,由Fab确定,用哪家的工艺生产芯片,就用他家的目标工艺库。门级单元,即最小的元件在此处找到,以组成门级电路。
- link library是层次3需要的,即将.v(RTL)中例化的IP解释成门级单元的样子,然后再在target library中选取正确的元件组成门级网表。link library可以看成解释设计的功能,link library应该由IP的供应商进行提供,指定搜索路径,得到IP的解释文件resolve design references.
- 在进行逻辑综合的时候在内存中进行寻找,因为已经将小module加载到内存中了。
link
link是介于translate和compile之间地一个小步骤,主要解决设计中所有地reference。设计的instances必须有相应的定义,instance就是上面的几个设计层次中的实例。DC针对不同设计层次的instance的获取:
- 已经translate的GETEC网表可以从内存中获取
- RTL中的例化了foundary提供的stdcell,从GETECH中获取。
- macros(比如IP),将其转变为门级单元,从target library找到元件组成,也是有厂商提供的.db提供的。
- system_library,指定的库包含了工艺库中的单元的图形slow.sdb
# 指定target_library--指定具体工艺库的路径
set_appr_var target_library 90nm_typical.db
# 设定 link_library
set_app_var link_library "* 90nm_typical.db" or
set_app_var link_library "* $target_library"
# link_library 列表
set_app_var link_library [list * ${target_library} macro_library macro_library2]
- *表示从内存中获取,对应的是GETCH网表
- ${target_library}对应std
- macro_library对应macros
- $--表示使用变量
6.3 read_verilog
通过read_verilog将design读入,将RTL转化为GETCH网表,设置一个design作为current design。一般需要进行设置current design,否则系统默认读入的最后一个作为current design。将current design设置在Top上,一般针对于top进行综合。
read_verilog "Top.v A.v B.v"
6.4 current_design
设置current_design,告诉DC针对哪一个对象进行综合。
current_design Top
6.5 source timing constrain
timing constrain也是一些命令,可以将这些命令写到脚本中进行执行。
- Apply timing constrain on current design
- Clock constrain:modeling clock trees
# clock period
create_clock -period 2 [get_ports Clk]
# clock skew
set_clock_uncertainty -setup 0.3 [get_clocks Clk]
# clock transition
set_clock_transition -max 0.15 [get_clock Clk]
# clock latency
set_clock_latency -max 0.7 [get_clock Clk]
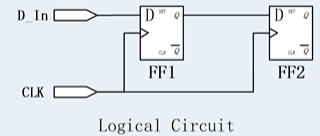
- create_clock,做约束的时候或者是检查约束的时候,模型是组合逻辑--寄存器--组合逻辑,组合逻辑就会造成delay,在FF1上升沿,将D端数据抓到Q端,进行数据传输,在FF2上升沿将输入抓入。在FF2上升沿之前,需要保证数据稳定下来,保证抓取数据正确,如果数据不稳定,在FF2上升沿之前数据没有传递到,就会造成FF2抓取数据错误。所以需要满足一个setup time,定义一个时钟,在一个时钟之内,FF1 D端数据要传到FF2 D端,并且保持数据的稳定。
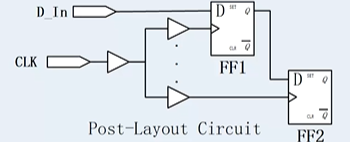
- set_clock_uncertainty,约束margin skew,clock是有抖动的,要留有预量。在前端设计来所,任务Clk到FF1和到FF2的时间是一致的,在后端而言,是同过金属走线连接的,有些cell距离port比较近,有的cell离port比较远,可以通过在近端插入buffer,在远端金属走线上加RC延迟,保证FF1和FF2的timing一致。从clock的port到不同的register的时间会有偏差,叫做skew。
在前端考虑timing的时候,对于可能存在的skew也需要考虑进来。后面比较容易满足。 - set_clock_transition,理想的信号翻转是不需要时间的,但是实际的情况信号完成从0到1,或者从1到0进行跳变总是需要时间的。
- set_clock_latency,从Clk到达D_in消耗的时间。如果一个design中只有一个Clk,可以将latency忽略掉,因为检查的时候检查FF1和FF2之间相对的时间就可以。当design有不同的Clk,clk1和clk2到达的时间不同,如果要检查一个clk驱动的register到另一个clk驱动的register的时候,不仅要考虑两个register之间的相对时间还要考虑clk到register的时间。(clk1->FF1与clk2->FF2)。clk决定了什么时间去lanch。
6.6 timing constrain(II)
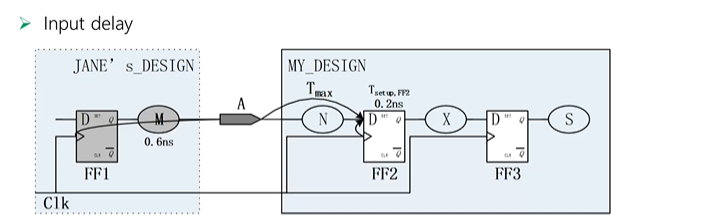
对于My_design内部的约束,可以通过set_cloclk的方式进行约束。一个时钟周期之内,信号可以稳定传输,这是reg to reg path 的约束。
对于IO path来说,信号什么时候来是不知道的,可以假设信号经过前一个reg输出后,经过port进入第一级reg。所以从FF1到FF2总体的时间就是一个时钟周期,知道My_design外部的时间消耗,就知道了My_Design的第一级reg的时间。就可以选择合适的cell来代替组合My_design中第一级reg之前的组合逻辑。如何告诉组合逻辑外部消耗的时间,就通过set_input_delay进行设置,告诉DC工具,外部消耗了0.6,里面用时钟周期减掉外部消耗。
# Latest Data Arrival Time at Port A,after Jane's launching clock edge = 0.6ns
set_input_delay -max 0.6 -clock Clk [get_ports A]
- get_ports A--指定从A port到前一级reg消耗的时间
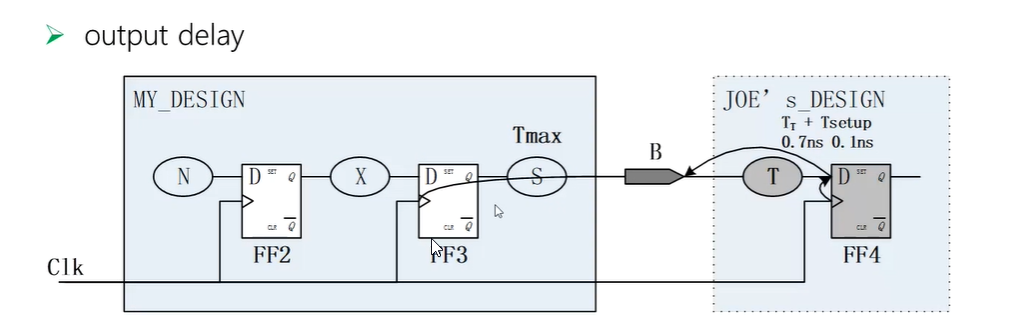
对于正常来说,计算reg to reg,对于My_design的output port,也不是一个完整周期,假设外部还有一个register,知道外部的到下一个register的时间,就知道了当前My_design中reg到output port的时间。
# Latest Data Arrival Time at Port B,before Joe's capturing clock=0.8ns
set_input_delay -max 0.8 -clock Clk [get_ports B]
- -clock Clk--指定哪一个clock
- get_ports B --指定B port到下一级reg的消耗时间
- delay和clock是有关系的,内部使用clock是Clk,外部使用的也是Clk,可以使用同一个时钟周期去减,如果用的不是一个clock,情况会复杂。
6.7 environment constrainu
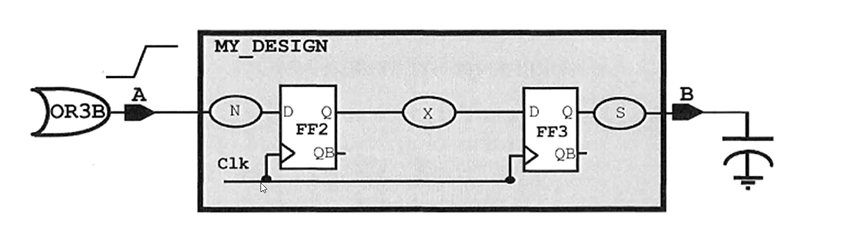
除了input delay和output delay,Desgin中的每一个cell都会计算delay,比如在My_design中插入了一个buffer,这个buffer的delay是从library中查出的。在library中定义了各种各样的cell,每个cell都有一个delay table,delay table是一个二维的cha表,一个是load compatitence,另一个是input transition。
也就是说对于一个cell来说,它的delay取决于input transition和输出的负载,输出的负载越达,delay越大。对于FF2来说,它的input transition是由前一级传递过来的,对于它的output load是由后一级给它的。
对于My_design中第一级来说,前面一级时port,没有input transition,分析起来比较乐观,为了让条件更加严格,可以通过set_input_transition给它一个input transition。如果对于input transition不是很了解,也可以给一个driving cell。
set_input_transition 0.12 [get_ports A]
对于output来说,它的input transition是从前面一级一级传递过来的,最后传递到一个cell上,但是对于它来说,output load又是缺失的,通过set_load进行指定它后面的load是什么样的情况。
set_load [expr {30.0/1000}] [get_ports B]
6.8 compile/compile_ultra
compile=Logic Optimization + Gate Mapping
- Performs three level of optimization--三个层次的优化
- Architectural level synthesis
在design中有结构进行调整的,工具进行优化。 - Logic level or GETCH optimization
在纯逻辑和算法的层面进行优化。 - Gate-level or mapping optimization
- Minimize area while meeting timing constraints
compile执行的命令
compile
compile_ultra
- To compile a design, use the compile command if you are using DC Expert,or the compile_ultra command if you are using DC Ultra or DC Graphical. Command options allow you to customize and control optimization.
- compile_ultra的优化功能更多一些。在优化的时候优先满足timing和DRC,area优先级是最低的。
6.9 report_qor
通过report_qor报告结果
report quality of result(qor) for a synthesis summary
- 报告信息
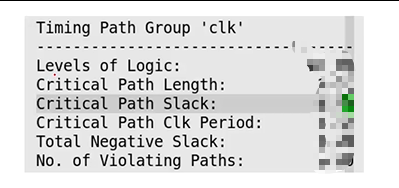
- levels of logic是逻辑级联数,相当于一个信号经由几个LUT串联而来,data path delay就是走线延时了,和逻辑规模、布局、扇出数有关。
2.Timing - clock period
- WNS:Worst negtive slack
- TNS:total negtive slack
3.cell count--cell数量 - Leaf cell count
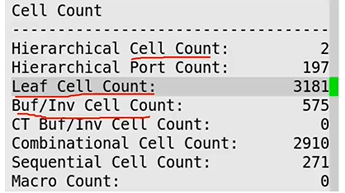
3.Area - Cell area

6.10 report_timing
report_timing
- The report_timing invokes DC's Static Timing Analyzer
- Break the design down into individual timing paths
- Analyzes each timing path for max-delay timing
- DC中是不会优化hold的,优化setup通过优化组合逻辑进行。setup来说是delay太大了,减小需要进行优化组合逻辑。对于hold来说,是delay太快了,需要进行延缓,可以插入buffer进行优化hold。
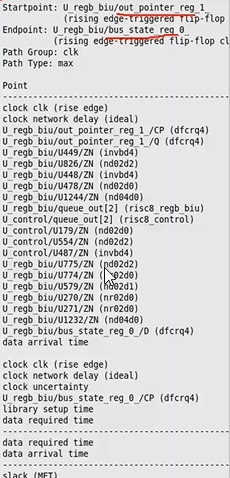
- header部分
- startpoint--timing path开始;并说明startpoint是由哪个时钟进行capture和launch的
- endpoint--timing path结束;并说明endpoint是由哪个时钟进行capture和launch的
- path group--dc中path group根据capture clock进行分的,同一个capture clock的timing path分到同一个path group
- path type--max 表示setup,min表示hold
- 对于这条path经过的所有cell
reg1--->reg0
- data arrival time
- clock
6.11 output
write_sdc my_design.sdc
write -f ddc -hier -output my_ddc.ddc
write -f verilog -heir -outout my_design.gv
03-逻辑综合工具 - Design Compiler的更多相关文章
- Tcl与Design Compiler (八)——DC的逻辑综合与优化
本文属于原创手打(有参考文献),如果有错,欢迎留言更正:此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner 对进行时序路径.工作环 ...
- Tcl与Design Compiler (七)——环境、设计规则和面积约束
本文属于原创手打(有参考文献),如果有错,欢迎留言更正:此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner 本文的主要内容是讲解( ...
- Tcl与Design Compiler (十二)——综合后处理
本文如果有错,欢迎留言更正:此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner 概述 前面也讲了一些综合后的需要进行的一些工作,这 ...
- Design Compiler 综合
综合(synthesis) = 转换(translation) + 优化(logic optimization) + 映射(gate mapping): 转换阶段将HDL语言描述的电路用门级逻辑实现. ...
- Tcl与Design Compiler (二)——DC综合与Tcl语法结构概述
1.逻辑综合的概述 synthesis = translation + logic optimization + gate mapping . DC工作流程主要分为这三步 Translation : ...
- Tcl与Design Compiler (五)——综合库(时序库)和DC的设计对象
本文如果有错,欢迎留言更正:此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner 前面一直说到综合库/工艺库这些东西,现在就来讲讲讲 ...
- Tcl与Design Compiler (十一)——其他的时序约束选项(二)
本文如果有错,欢迎留言更正:此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner 前面介绍的设计都不算很复杂,都是使用时钟的默认行为 ...
- Tcl与Design Compiler (十三)——Design Compliler中常用到的命令(示例)总结
本文如果有错,欢迎留言更正:此外,转载请标明出处 http://www.cnblogs.com/IClearner/ ,作者:IC_learner 本文将描述在Design Compliler中常用 ...
- Link带参数的Verilog模块(Design Compiler)
在Design Compiler中,Verilog文件可以用read_verilog命令读入,用link命令连接.以下是连接两个文件RegisterFile.v和Test.v的脚本: # Read d ...
- Tcl与Design Compiler (一)——前言
已经学习DC的使用有一段时间了,在学习期间,参考了一些书,写了一些总结.我也不把总结藏着掖着了,记录在博客园里面,一方面是记录自己的学习记录,另一方面是分享给大家,希望大家能够得到帮助.参考的书籍有很 ...
随机推荐
- JSP中request对象的简单实用,实现简单的注册以及个人信息的展示
JSP中Request对象的使用 概述:request对象主要用于接收客户端发送来的请求信息,客户端的请求信息被封装在request对象中,通过它可以了解到客户的需求,然后做出响应.主要封装了用户提交 ...
- Vue学习之--------脚手架的分析、Ref属性、Props配置(2022/7/28)
欢迎大家加入我的社区:http://t.csdn.cn/Q52km 社区中不定时发红包 文章目录 1.脚手架的分析 2.ref属性 2.1 基础知识 2.2 代码实现 2.3 测试效果 3.Props ...
- 创建Vue工程常用的命令
创建一个vue项目的步骤 1.创建一个名称为myapp的工程 vue init webpack myapp 2.进入工程目录 cd myapp 3.安装 vue-router npm install ...
- Python爬虫urllib库的使用
urllib 在Python2中,有urllib和urllib2两个库实现请求发送,在Python3中,统一为urllib,是Python内置的HTTP请求库 request:最基本的HTTP请求模块 ...
- Java安全之反序列化(1)
序列化与反序列化 概述 Java序列化是指把Java对象转换为字节序列的过程:这串字符可能被储存/发送到任何需要的位置,在适当的时候,再将它转回原本的 Java 对象,而Java反序列化是指把字节序列 ...
- java学习之JSON
0X00前言 JSON可以说是javascript的一种数据类型,我们学习JSON是为了在客户端的数据给读取出来,官方的解释是:概述:JSON(JavaScript Object Notation, ...
- Kubernetes_从云原生到kubernetes
一.前言 二.kubernetes和云原生 Cloud Native 直接翻译为云原生,云原生官网:https://www.cncf.io/ CNCF,表示 Cloud Native Computin ...
- 小米mini路由器刷breed不死鸟和潘多拉固件
前言 开启小米路由器ssh, 这一步浪费我很长时间,因为目前的开发版都对ssh升级进行了md5校验,导致官方升级方法总是失败,所以换成老版本的 路由器固件就行了. 步骤 下载 0.4.36 mini路 ...
- php+nginx环境搭建
PHP安装教程参考:https://www.cnblogs.com/kyuang/p/6801942.html 1.安装基础环境: yum -y install gcc bison bison-dev ...
- 数据结构高阶--AVL(平衡二叉树)(图解+实现)
AVL树(平衡二叉树) 概念 二叉搜索树虽可以缩短查找的效率,但如果数据有序或接近有序二叉搜索树将退化为单支树,查找元素相当于在顺序表中搜索元素,效率低下.因此为了解决这个问题,两位俄罗斯的数学家发明 ...