DRF 过滤排序分页异常处理
DRF 过滤排序分页异常处理
过滤
涉及到查询数据的接口才需要过滤功能
DRF过滤使用种类:
- 内置过滤类
- 第三方
- 自定义
内置过滤类
导入:from rest_framework.filters import SearchFilter
前提条件:使用内置过滤类,视图类需要继承GenericAPIView才能使用
步骤:
- 视图类内filter_backends中使用SearchFilter
- 类属性search_fields指定过滤的字段
使用:链接?search=字段,且支持模糊查询
from rest_framework.generics import ListAPIView
from rest_framework.viewsets import ViewSetMixin
from rest_framework.filters import SearchFilter
from .models import Book
from .serializer import BookSerializer
# 只有查询接口才需要过滤,内置过滤类的使用需要视图类继承GenericAPIView才能使用
class BookView(ViewSetMixin, ListAPIView):
'''
内置过滤类:1、filter_backends中使用SearchFilter
2、类属性search_fields指定过滤的字段
3、链接?search=字段,且支持模糊查询
'''
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_backends = [SearchFilter,]
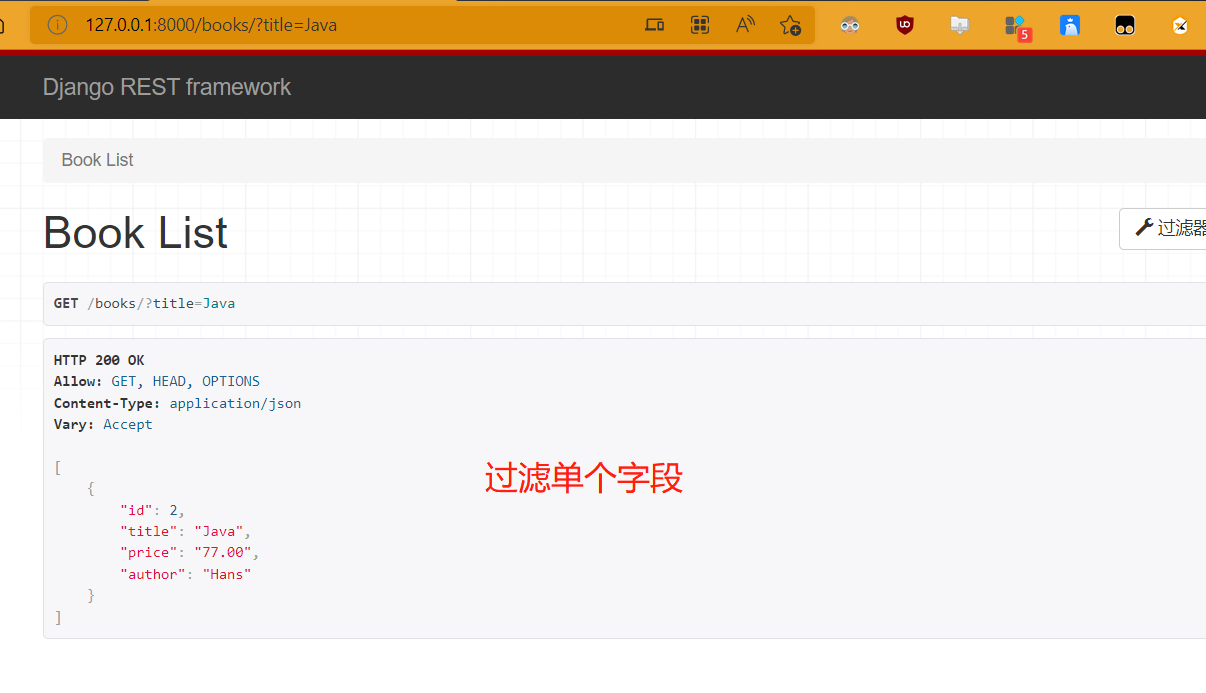
# 过滤单个字段
search_fields = ['title',]
注意:链接过滤的字段必须是search
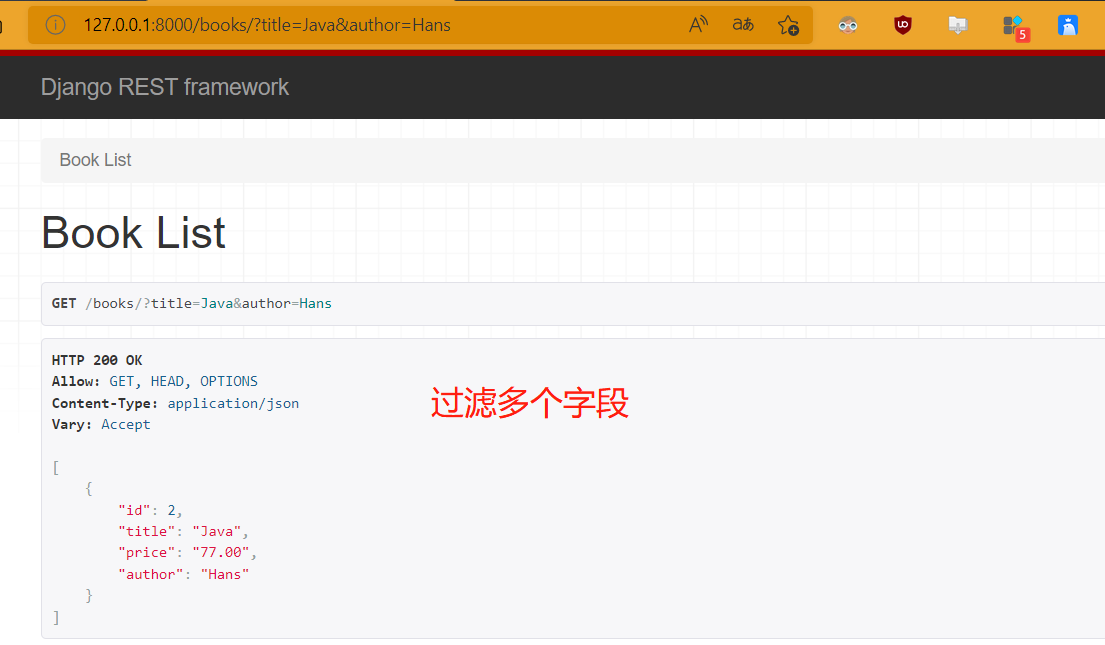
# 过滤多个字段:书名和作者名
'''
比如书名:Python 作者名:Pink,那么过滤search=P就都会过滤出来
'''
search_fields = ['title','author']
# http://127.0.0.1:8000/books/?search=H
总结:
- 内置过滤类的使用,模糊查询会将包含过滤字段的数据都过滤出来,前提是在search_fields列表内指定的字段;
- 内置过滤的特点是模糊查询
- 过滤字段参数为
search

第三方过滤
对于列表数据可能需要根据字段进行过滤,我们可以通过添加django-fitlter扩展来增强支持
安装:pip install django-filter
导入:from django_filters.rest_framework import DjangoFilterBackend
在配置文件中增加过滤后端的设置:
INSTALLED_APPS = [
...
'django_filters', # 需要注册应用,
]
在视图中添加filter_fields属性,指定可以过滤的字段
from django_filters.rest_framework import DjangoFilterBackend
# 第三方过滤类
class BookView(ViewSetMixin, ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_backends = [DjangoFilterBackend,]
filter_fields = ['title','author']
http://127.0.0.1:8000/books/?title=Java # 单个字段过滤
http://127.0.0.1:8000/books/?title=Java&author=HammerZe # 多个字段过滤
总结:
- 第三方过滤类在
filter_backends字段中写,filter_fields字段指定过滤的字段 - 第三方过滤类不支持模糊查询,是精准匹配
- 第三方过滤类的使用,视图类也必须继承
GenericAPIView才能使用 - 在链接内通过
&来表示和的关系
自定义过滤类
步骤:
- 写一个类继承
BaseFilterBackend,重写filter_queryset方法,返回queryset对象,qs对象是过滤后的 - 视图类中使用,且不需要重写类属性去指定过滤的字段
- 过滤使用,支持模糊查询(自己定制过滤方式),通过
filter方法来指定过滤规则
自定义过滤类
'''filter.py'''
from django.db.models import Q
from rest_framework.filters import BaseFilterBackend
# 继承BaseFilterBackend
class MyFilter(BaseFilterBackend):
# 重写filter_queryset方法
def filter_queryset(self, request, queryset, view):
# 获取过滤参数
qs_title = request.query_params.get('title')
qs_author = request.query_params.get('author')
# title__contains:精确大小写查询,SQL中-->like BINARY
# 利用Q查询构造或关系
if qs_title:
queryset = queryset.filter(title__contains=qs_title)
elif qs_author:
queryset = queryset.filter(author__contains=qs_author)
elif qs_title or qs_author:
queryset = queryset.filter(Q(title__contains=qs_title)|Q(author__contains=qs_author))
return queryset
视图
# 自定制过滤类
from .filter import MyFilter
class BookView(ViewSetMixin, ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_backends = [MyFilter,]
# 这里不需要写类属性指定字段了,因为自定义过滤类,过滤字段了
源码分析
我们知道过滤的前提条件是视图继承了GenericAPIView才能使用,那么在GenericAPIView中的执行流程是什么?
1、调用了GenericAPIView中的filter_queryset方法
2、filter_queryset方法源码:
def filter_queryset(self, queryset):
for backend in list(self.filter_backends):
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
'''
1.backend是通过遍历该类的filter_backends列表的得到的,也就是我们指定的过滤类列表,那么backend就是我们的过滤类
2.通过实例化得到对象来调用了类内的filter_queryset返回了过滤后的对象
'''
排序
REST framework提供了OrderingFilter过滤器来帮助我们快速指明数据按照指定字段进行排序。
导入:from rest_framework.filters import OrderingFilter
步骤:
- 视图类中配置,且视图类必须继承GenericAPIView
- 通过
ordering_fields指定要排序的字段 - 排序过滤,
-号代表倒序,且必须使用ordering指定排序字段
'''内置过滤和排序混用'''
from rest_framework.filters import OrderingFilter
from rest_framework.filters import SearchFilter
class BookView(ViewSetMixin, ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_backends = [SearchFilter,OrderingFilter]
# 先过滤后排序减少消耗
search_fields = ['title']
ordering_fields = ['id','price']
# 排序
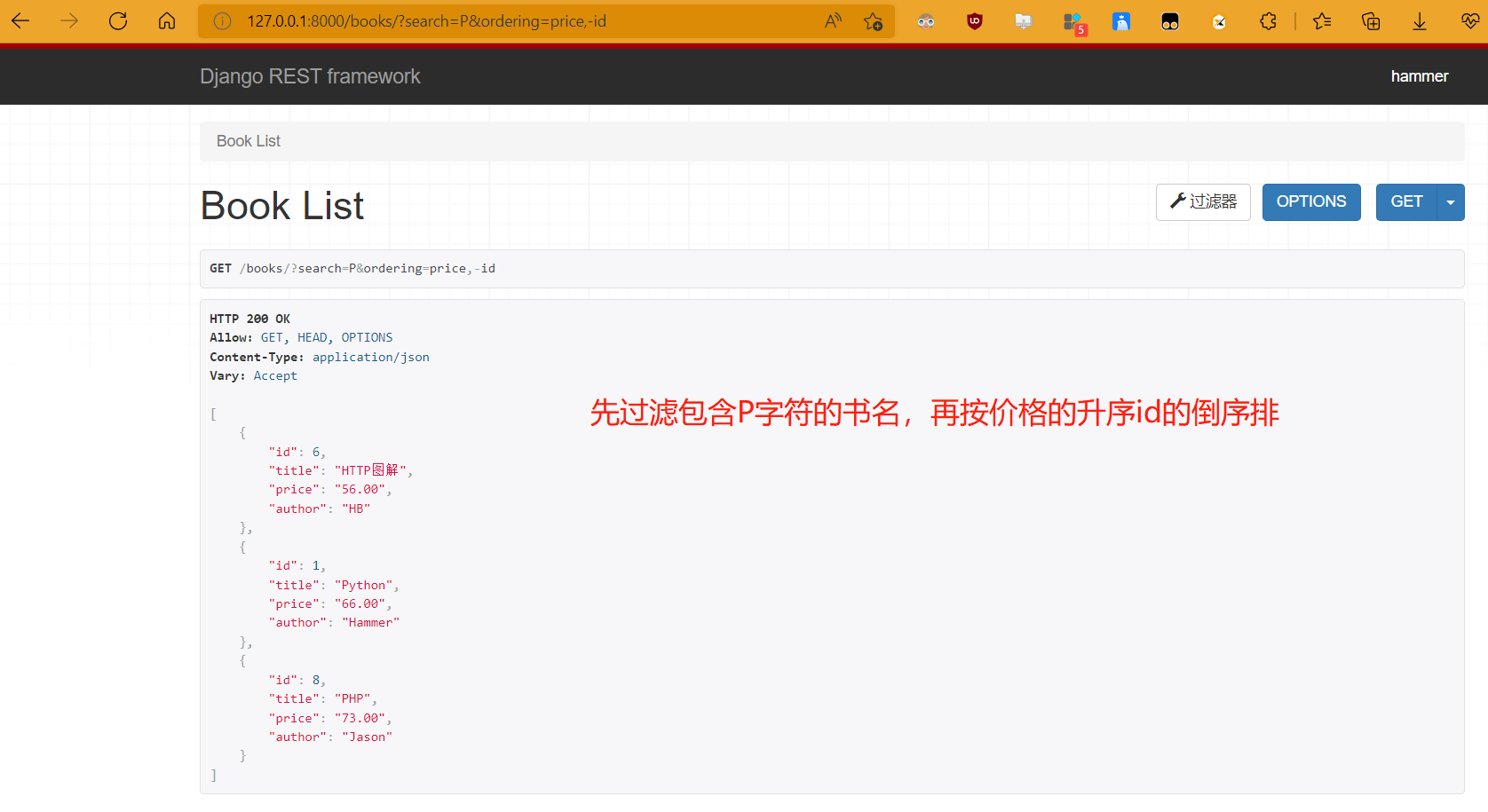
http://127.0.0.1:8000/books/?ordering=price # 价格升序
http://127.0.0.1:8000/books/?ordering=-price # 价格降序
http://127.0.0.1:8000/books/?ordering=price,id # 价格id升序
http://127.0.0.1:8000/books/?ordering=price,-id # 价格升序id降序
····
注意
过滤可以和排序同时使用,但是先执行过滤再执行排序,提升了代码的效率(先过滤后排序),因为如果先排序,那么数据库的数量庞大的话,直接操作了整个数据库,消耗资源,过滤完成后排序只是针对一小部分数据
分页
分页只在查询所有接口中使用
导入:from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
分页有三种分页方式,如下:
PageNumberPagination,基本分页
步骤:
自定义类,继承
PageNumberPagination,重写四个类属性page_size:设置每页默认显示的条数
page_query_param:url中的查询条件,books/?page=2表示第二页
page_size_query_param:每页显示多少条的查询条件,books/?page=2&size=5,表示查询第二页,显示5条
max_page_size:设置每页最多显示条数,不管查多少条,最大显示该值限制的条数
配置在视图类中,通过
pagination_class指定,必须继承GenericAPIView才有pagination_class = PageNumberPagination
分页
from rest_framework.pagination import PageNumberPagination
class BookPagination(PageNumberPagination):
page_size = 2 # 默认每页显示2条
page_query_param = 'page' # 查询条件,eg:page=3
page_size_query_param = 'size' # 查询条件参数size=5显示五条
max_page_size = 10 # 每页最大显示条数
视图
from rest_framework.filters import OrderingFilter
from rest_framework.filters import SearchFilter
from .page import BookPagination
class BookView(ViewSetMixin, ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_backends = [SearchFilter,OrderingFilter]
search_fields = ['title','author']
ordering_fields = ['id','price']
pagination_class = BookPagination
# http://127.0.0.1:8000/books/?page=2&size=5
注意:pagination_class指定分页类不需要使用列表

LimitOffsetPagination,偏移分页
步骤:
- 自定义类,继承LimitOffsetPagination,重写四个类属性
- default_limit:默认每页获取的条数
- limit_query_param:每页显示多少条的查询条件,比如?limit=3,表示获取三条,如果不写默认使用default_limit设置的条数
- offset_query_param:表示偏移量参数,比如?offset=3表示从第三条开始往后获取默认的条数
- max_limit:设置最大显示条数
- 视图类内配置,pagination_class参数指定,必须继承GenericAPIView才有
分页
class MyLimitOffsetPagination(LimitOffsetPagination):
default_limit = 2 # 默认每页显示2条
limit_query_param = 'limit' # ?limit=3,查询出3条
offset_query_param = 'offset' # 偏移量,?offset=1,从第一条后开始
max_limit = 5 # 最大显示5条
视图
from rest_framework.filters import OrderingFilter
from rest_framework.filters import SearchFilter
from .page import MyLimitOffsetPagination
class BookView(ViewSetMixin, ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_backends = [SearchFilter,OrderingFilter]
# 先过滤后排序减少消耗
search_fields = ['title','author']
ordering_fields = ['id','price']
pagination_class = MyLimitOffsetPagination
# http://127.0.0.1:8000/books/?limit=2&offset=4
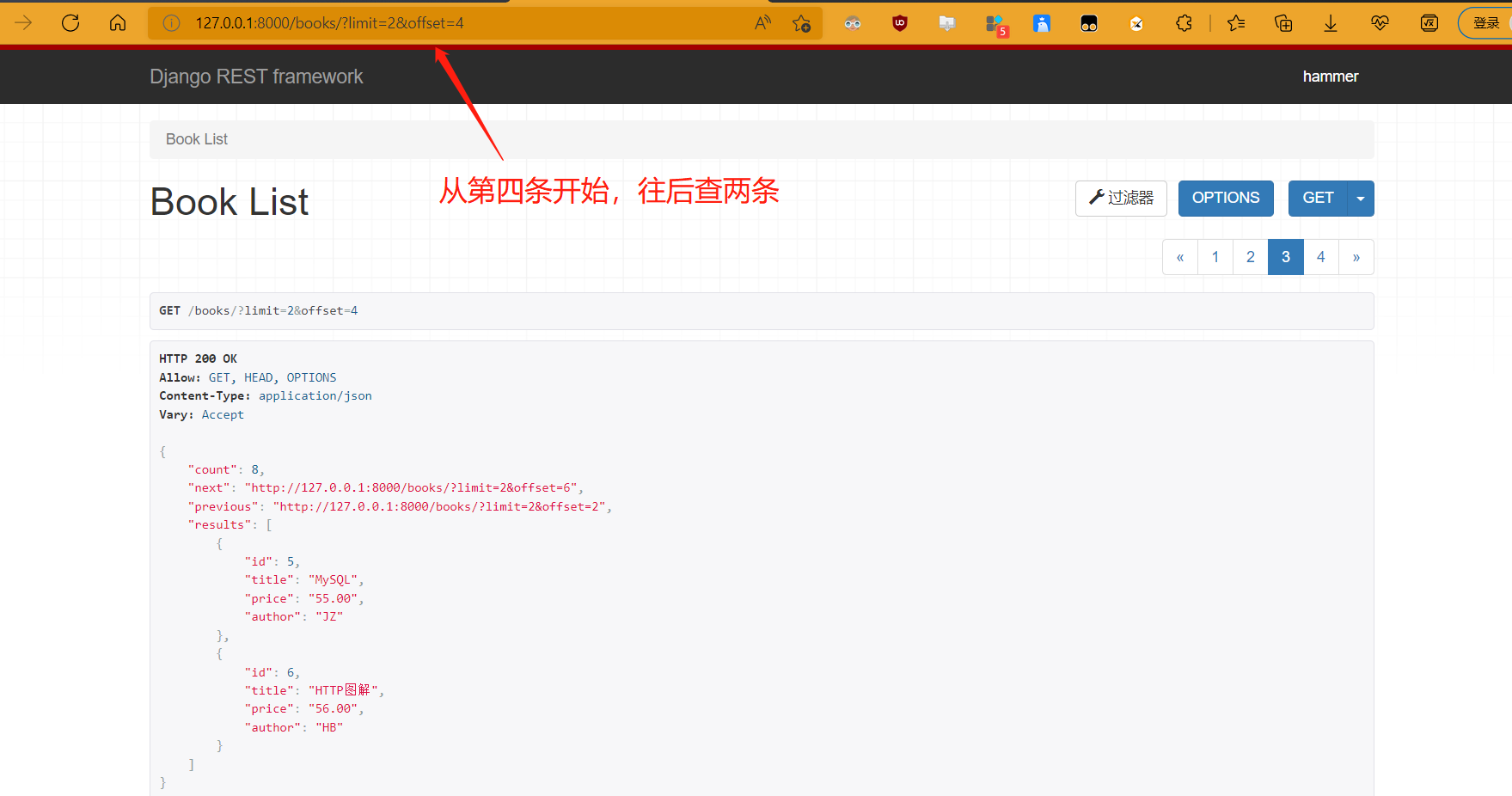
CursorPagination,游标分页
步骤:
- 自定义类,继承CursorPagination,重写三个类属性
- page_size:每页显示的条数
- cursor_query_param:查询条件
- ordering:排序规则,指定排序字段
- 视图类内配置,pagination_class参数指定,必须继承GenericAPIView才有
分页
class MyCursorPagination(CursorPagination):
cursor_query_param = 'cursor'
page_size = 2
ordering = 'id'
视图
from rest_framework.filters import SearchFilter
from .page import MyCursorPagination
class BookView(ViewSetMixin, ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_backends = [SearchFilter]
search_fields = ['title','author']
pagination_class = MyCursorPagination
'''
注意:因为分页内指定了排序规则,那么视图内如果再指定了排序规则就会报错
'''
总结
- 分页类内指定了排序,视图内不要写排序规则,不然报错
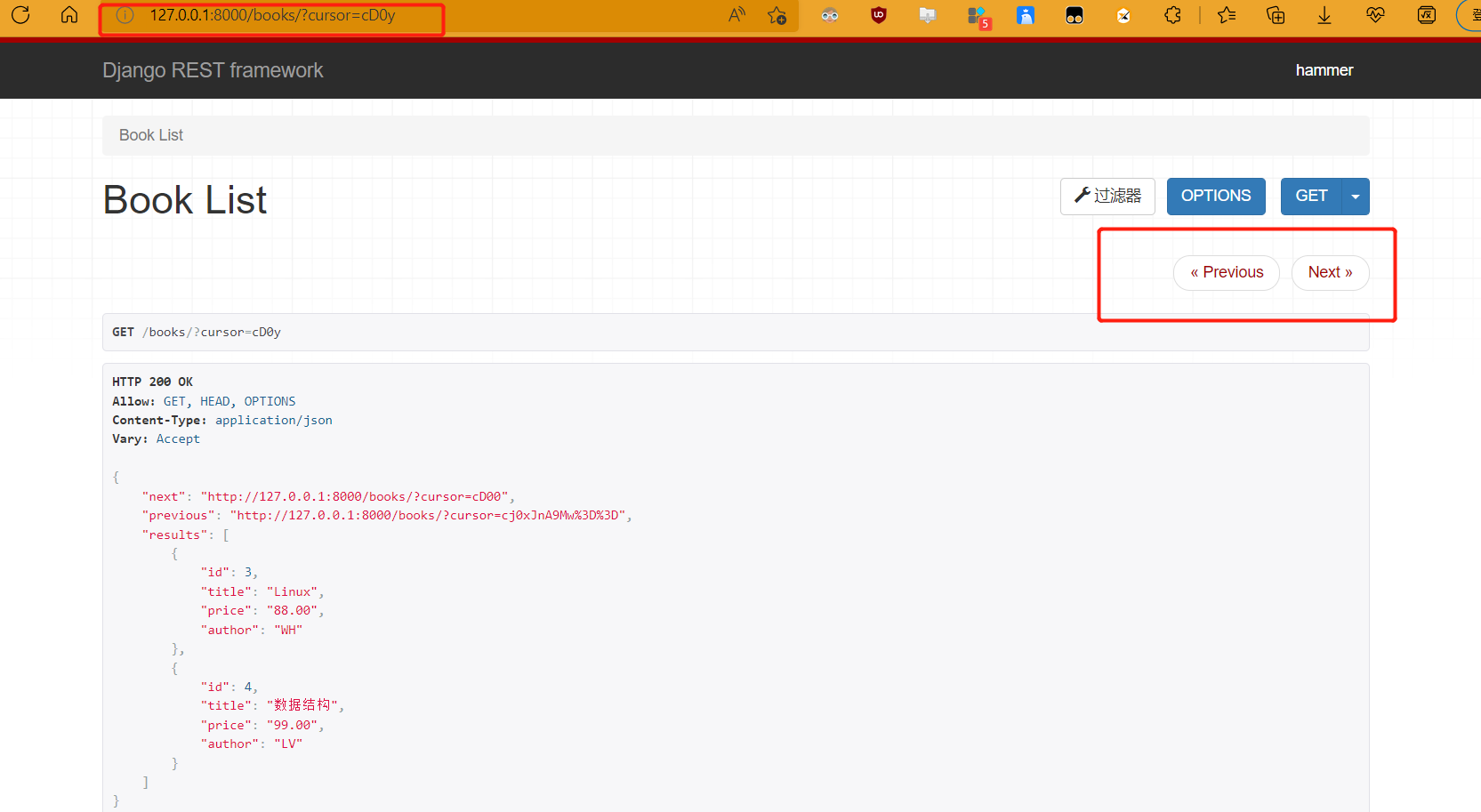
分页总结
- 前两种分页都可以从中间位置获取一页,而最后一个分页类只能上一页或下一页
- 前两种在获取某一页的时候,都需要从开始过滤到要取的页面数的数据,本质是SQL中的limit··,查询出要跳过的页数显示要查的数据,相比第三种慢一点
- 第三种方式,本质是先排序,内部维护了一个游标,游标只能选择往前或者往后,在获取到一页的数据时,不需要过滤之前的数据,相比前两种速度较快,适合大数据量的分页
异常
REST framework提供了异常处理,我们可以自定义异常处理函数,不论正常还是异常,通过定制,我们可以返回我们想要返回的样子
步骤
- 自定义函数
- 在配置文件中配置函数
注意
如果没有配置自己处理异常的规则,会执行默认的,如下:
from rest_framework import settings
from rest_framework.views import exception_handler
默认配置流程怎么走?
# 1、 APIView源码
# dispatch方法源码
except Exception as exc:
response = self.handle_exception(exc)
# handle_exception方法源码
response = exception_handler(exc, context)
# 2、views种的exception_handler方法
def exception_handler(exc, context):
···
# 3、 默认配置文件
'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler',
自定义异常
源码exception_handler方法有两种情况,if判断第一种情况是处理了APIException对象的异常返回Reponse对象,第二种情况是处理了其他异常返回了None,这里我们针对这两种情况的异常进行定制处理
- exc:错误原因
- context:字典,包含了当前请求对象和视图类对象
自定义异常处理方法
from rest_framework.views import exception_handler
from rest_framework.response import Response
def myexception_handler(exc, context):
# 先执行原来的exception_handler帮助我们处理
res = exception_handler(exc, context)
if res:
# res有值代表处理过了APIException对象的异常了,返回的数据再定制
res = Response(data={'code': 998, 'msg': res.data.get('detail', '服务器异常,请联系系统管理员')})
# res = Response(data={'code': 998, 'msg': '服务器异常,请联系系统管理员'})
# res.data.get从响应中获取原来的处理详细信息
else:
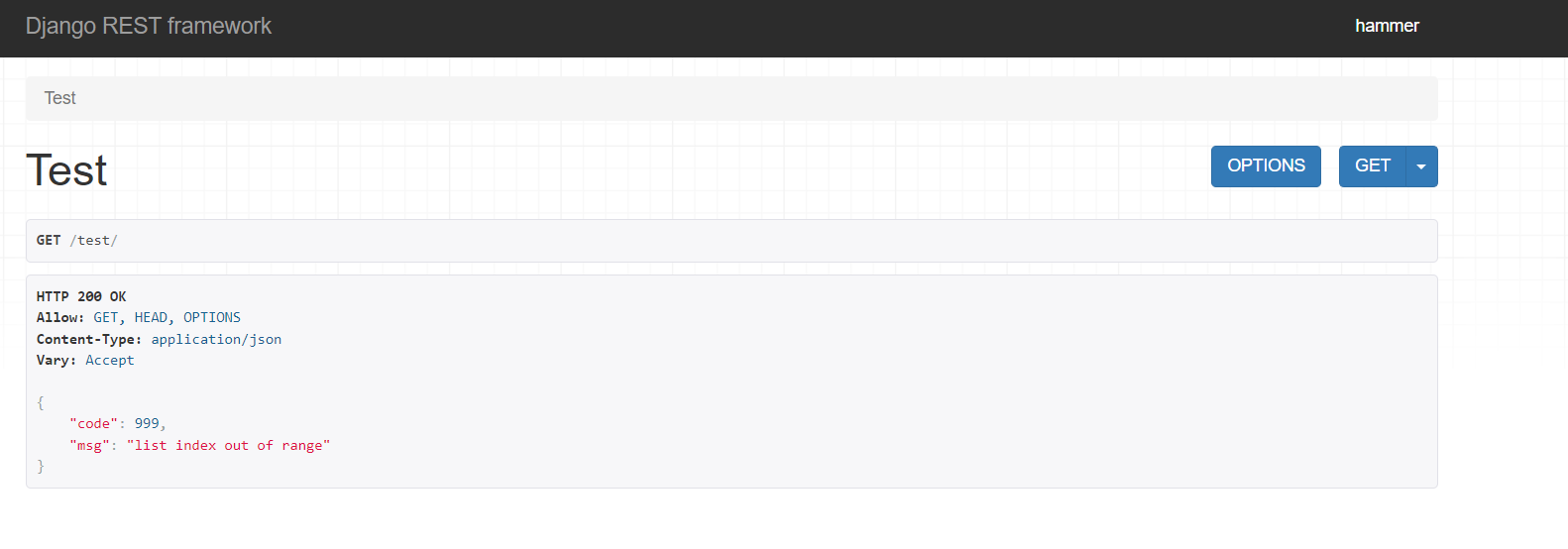
res = Response(data={'code': 999, 'msg': str(exc)})
print(exc) # list index out of range
'''模拟日志处理'''
request = context.get('request') # 当次请求的request对象
view = context.get('view') # 当次执行的视图类对象
print('错误原因:%s,错误视图类:%s,请求地址:%s,请求方式:%s' % (str(exc), str(view), request.path, request.method))
'''结果:
错误原因:list index out of range,错误视图类:<app01.views.TestView object at 0x000001C3B1C7CA58>,请求地址:/test/,请求方式:GET
'''
return res
视图
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.exceptions import APIException
# 测试异常视图
class TestView(APIView):
def get(self,request):
# 1、 其他报错
l = [1,2,3]
print(l[100])
# 2、APIException异常
# raise APIException('APIException errors!')
return Response('successfuly!')
配置文件
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'app01.exception.myexception_handler' # 再出异常,会执行自己定义的函数
}
REST framework定义的异常
- APIException 所有异常的父类
- ParseError 解析错误
- AuthenticationFailed 认证失败
- NotAuthenticated 尚未认证
- PermissionDenied 权限决绝
- NotFound 未找到
- MethodNotAllowed 请求方式不支持
- NotAcceptable 要获取的数据格式不支持
- Throttled 超过限流次数
- ValidationError 校验失败
DRF 过滤排序分页异常处理的更多相关文章
- 三 drf 认证,权限,限流,过滤,排序,分页,异常处理,接口文档,集xadmin的使用
因为接下来的功能中需要使用到登陆功能,所以我们使用django内置admin站点并创建一个管理员. python manage.py createsuperuser 创建管理员以后,访问admin站点 ...
- day74:drf:drf其他功能:认证/权限/限流/过滤/排序/分页/异常处理&自动生成接口文档
目录 1.django-admin 2.认证:Authentication 3.权限:Permissions 4.限流:Throttling 5.过滤:Filtering 6.排序:OrderingF ...
- DRF之过滤排序分页异常处理
一.过滤 对于列表数据要通过字段来进行过滤,就需要添加 django-filter 模块 使用方法: # 1.注册,在app中注册 settings.py INSTALLED_APPS = [ 'dj ...
- drf07 过滤 排序 分页 异常处理 自动生成接口文档
4. 过滤Filtering 对于列表数据可能需要根据字段进行过滤,我们可以通过添加django-fitlter扩展来增强支持. pip install django-filter 在配置文件sett ...
- DRF之权限认证,过滤分页,异常处理
1. 认证Authentication 在配置文件中配置全局默认的认证方案 REST_FRAMEWORK = { 'DEFAULT_AUTHENTICATION_CLASSES': ( 'rest_f ...
- drf_jwt手动签发与校验-drf小组件:过滤-筛选-排序-分页
签发token 源码的入口:完成token签发的view类里面封装的方法. 源码中在请求token的时候只有post请求方法,主要分析一下源码中的post方法的实现. settings源码: 总结: ...
- drf框架 - 过滤组件 | 分页组件 | 过滤器插件
drf框架 接口过滤条件 群查接口各种筛选组件数据准备 models.py class Car(models.Model): name = models.CharField(max_length=16 ...
- Contoso 大学 - 3 - 排序、过滤及分页
原文 Contoso 大学 - 3 - 排序.过滤及分页 目录 Contoso 大学 - 使用 EF Code First 创建 MVC 应用 原文地址:http://www.asp.net/mvc/ ...
- Ecside基于数据库的过滤、分页、排序
首先ecside展现列表.排序.过滤(该三种操作以下简称为 RSF )的实现原理完全和原版EC一样, 如果您对原版EC的retrieveRowsCallback.sortRowsCallback.fi ...
随机推荐
- vue中使用js-cookie插件
js-cookie是一个用于处理 cookie 的简单.轻量级 JavaScript API,官方文档:https://www.npmjs.com/package/js-cookie. 一.安装 np ...
- LGP5437题解
呃怎么感觉很裸啊( 题意是让求生成树边权之和的期望,那么我们只需要算出所有生成树的边权之和除以生成树边数即可. 由于是求和,我们只需要计算出每条边对答案的贡献即可. 我们知道一个完全图有 \(n^{n ...
- Java 开发工具之Myeclipse快捷键
- @Autowired @Qualifier @Resource
@Autowired 用于对Bean的属性变量,属性的setter()方法及构造方法进行标注,配合对应的注解处理器完成Bean的自动装配工作.默认按照Bean的类型进行装配. @Resource 其作 ...
- Ubuntu系统中防火墙的使用和开放端口
目录 Ubuntu系统 防火墙的使用和开放端口 1.安装防火墙 2.查看防火墙状态 3.开启.重启.关闭防火墙 4.Ubuntu添加开放.关闭端口 5.开放规定协议的端口 6.关闭指定协议端口 7.开 ...
- 5分钟了解Redis的内部实现跳跃表(skiplist)
跳跃表简介 跳跃表(skiplist)是一个有序的数据结构,它通过在每个节点维护不同层次指向后续节点的指针,以达到快速访问指定节点的目的.跳跃表在查找指定节点时,平均时间复杂度为,最坏时间复杂度为O( ...
- [SPDK/NVMe存储技术分析]012 - 用户态ibv_post_send()源码分析
OFA定义了一组标准的Verbs,并提供了一个标准库libibvers.在用户态实现NVMe over RDMA的Host(i.e. Initiator)和Target, 少不了要跟OFA定义的Ver ...
- Spring Security实现统一登录与权限控制
1 项目介绍 最开始是一个单体应用,所有功能模块都写在一个项目里,后来觉得项目越来越大,于是决定把一些功能拆分出去,形成一个一个独立的微服务,于是就有个问题了,登录.退出.权限控制这些东西怎么办呢? ...
- 【Vulnhub】LazySysAdmin
下载链接 https://download.vulnhub.com/lazysysadmin/Lazysysadmin.zip 运行环境 Virtualbox Vnware Workstation p ...
- DWR是什么?有什么作用?
DWR(Direct Web Remoting)是一个用于改善web页面与Java类交互的远程服务器端Ajax开源框架,可以帮助开发人员开发包含AJAX技术的网站. 它可以允许在浏览器里的代码使用运行 ...