golang内存对齐分析(转载)
问题
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
在开始之前,希望你计算一下 Part1 共占用的大小是多少呢?
func main() {
fmt.Printf("bool size: %d\n", unsafe.Sizeof(bool(true)))
fmt.Printf("int32 size: %d\n", unsafe.Sizeof(int32(0)))
fmt.Printf("int8 size: %d\n", unsafe.Sizeof(int8(0)))
fmt.Printf("int64 size: %d\n", unsafe.Sizeof(int64(0)))
fmt.Printf("byte size: %d\n", unsafe.Sizeof(byte(0)))
}
输出结果:
bool size: 1
int32 size: 4
int8 size: 1
int64 size: 8
byte size: 1
这么一算,Part1 这一个结构体的占用内存大小为 1+4+1+8+1 = 15 个字节。相信有的小伙伴是这么算的,看上去也没什么毛病
真实情况是怎么样的呢?我们实际调用看看,如下:
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
func main() {
part1 := Part1{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
}
输出结果:
part1 size: 32, align: 8
最终输出为占用 32 个字节。这与前面所预期的结果完全不一样。这充分地说明了先前的计算方式是错误的。为什么呢?
在这里要提到 “内存对齐” 这一概念,才能够用正确的姿势去计算,接下来我们详细的讲讲它是什么
内存对齐
有的小伙伴可能会认为内存读取,就是一个简单的字节数组摆放

上图表示一个坑一个萝卜的内存读取方式。但实际上 CPU 并不会以一个一个字节去读取和写入内存。相反 CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小。块大小我们称其为内存访问粒度。如下图:
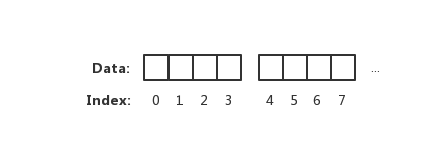
在样例中,假设访问粒度为 4。 CPU 是以每 4 个字节大小的访问粒度去读取和写入内存的。这才是正确的姿势
为什么要关心对齐
- 你正在编写的代码在性能(CPU、Memory)方面有一定的要求
- 你正在处理向量方面的指令
- 某些硬件平台(ARM)体系不支持未对齐的内存访问
另外作为一个工程师,你也很有必要学习这块知识点哦
为什么要做对齐
- 平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
- 性能原因:若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作

在上图中,假设从 Index 1 开始读取,将会出现很崩溃的问题。因为它的内存访问边界是不对齐的。因此 CPU 会做一些额外的处理工作。如下:
- CPU 首次读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0
- CPU 再次读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节
- 合并 1-4 字节的数据
- 合并后放入寄存器
从上述流程可得出,不做 “内存对齐” 是一件有点 "麻烦" 的事。因为它会增加许多耗费时间的动作
而假设做了内存对齐,从 Index 0 开始读取 4 个字节,只需要读取一次,也不需要额外的运算。这显然高效很多,是标准的空间换时间做法
默认系数
在不同平台上的编译器都有自己默认的 “对齐系数”,可通过预编译命令 #pragma pack(n) 进行变更,n 就是代指 “对齐系数”。一般来讲,我们常用的平台的系数如下:
- 32 位:4
- 64 位:8
另外要注意,不同硬件平台占用的大小和对齐值都可能是不一样的。因此本文的值不是唯一的,调试的时候需按本机的实际情况考虑
成员对齐
func main() {
fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
fmt.Printf("string align: %d\n", unsafe.Alignof("EDDYCJY"))
fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
}
输出结果:
bool align: 1
int32 align: 4
int8 align: 1
int64 align: 8
byte align: 1
string align: 8
map align: 8
在 Go 中可以调用 unsafe.Alignof 来返回相应类型的对齐系数。通过观察输出结果,可得知基本都是 2^n,最大也不会超过 8。这是因为我手提(64 位)编译器默认对齐系数是 8,因此最大值不会超过这个数
整体对齐
在上小节中,提到了结构体中的成员变量要做字节对齐。那么想当然身为最终结果的结构体,也是需要做字节对齐的
对齐规则
- 结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为编译器默认对齐长度(
#pragma pack(n))或当前成员变量类型的长度(unsafe.Sizeof),取最小值作为当前类型的对齐值。其偏移量必须为对齐值的整数倍 - 结构体本身,对齐值必须为编译器默认对齐长度(
#pragma pack(n))或结构体的所有成员变量类型中的最大长度,取最大数的最小整数倍作为对齐值 - 结合以上两点,可得知若编译器默认对齐长度(
#pragma pack(n))超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
分析流程
接下来我们一起分析一下,“它” 到底经历了些什么,影响了 “预期” 结果
| 成员变量 | 类型 | 偏移量 | 自身占用 |
|---|---|---|---|
| a | bool | 0 | 1 |
| 字节对齐 | 无 | 1 | 3 |
| b | int32 | 4 | 4 |
| c | int8 | 8 | 1 |
| 字节对齐 | 无 | 9 | 7 |
| d | int64 | 16 | 8 |
| e | byte | 24 | 1 |
| 字节对齐 | 无 | 25 | 7 |
| 总占用大小 | - | - | 32 |
成员对齐
- 第一个成员 a
- 类型为 bool
- 大小/对齐值为 1 字节
- 初始地址,偏移量为 0。占用了第 1 位
- 第二个成员 b
- 类型为 int32
- 大小/对齐值为 4 字节
- 根据规则 1,其偏移量必须为 4 的整数倍。确定偏移量为 4,因此 2-4 位为 Padding。而当前数值从第 5 位开始填充,到第 8 位。如下:axxx|bbbb
- 第三个成员 c
- 类型为 int8
- 大小/对齐值为 1 字节
- 根据规则1,其偏移量必须为 1 的整数倍。当前偏移量为 8。不需要额外对齐,填充 1 个字节到第 9 位。如下:axxx|bbbb|c...
- 第四个成员 d
- 类型为 int64
- 大小/对齐值为 8 字节
- 根据规则 1,其偏移量必须为 8 的整数倍。确定偏移量为 16,因此 9-16 位为 Padding。而当前数值从第 17 位开始写入,到第 24 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd
- 第五个成员 e
- 类型为 byte
- 大小/对齐值为 1 字节
- 根据规则 1,其偏移量必须为 1 的整数倍。当前偏移量为 24。不需要额外对齐,填充 1 个字节到第 25 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd|e...
整体对齐
在每个成员变量进行对齐后,根据规则 2,整个结构体本身也要进行字节对齐,因为可发现它可能并不是 2^n,不是偶数倍。显然不符合对齐的规则
根据规则 2,可得出对齐值为 8。现在的偏移量为 25,不是 8 的整倍数。因此确定偏移量为 32。对结构体进行对齐
结果
Part1 内存布局:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
小结
通过本节的分析,可得知先前的 “推算” 为什么错误?
是因为实际内存管理并非 “一个萝卜一个坑” 的思想。而是一块一块。通过空间换时间(效率)的思想来完成这块读取、写入。另外也需要兼顾不同平台的内存操作情况
巧妙的结构体
在上一小节,可得知根据成员变量的类型不同,其结构体的内存会产生对齐等动作。那假设字段顺序不同,会不会有什么变化呢?我们一起来试试吧
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
type Part2 struct {
e byte
c int8
a bool
b int32
d int64
}
func main() {
part1 := Part1{}
part2 := Part2{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
fmt.Printf("part2 size: %d, align: %d\n", unsafe.Sizeof(part2), unsafe.Alignof(part2))
}
输出结果:
part1 size: 32, align: 8
part2 size: 16, align: 8
通过结果可以惊喜的发现,只是 “简单” 对成员变量的字段顺序进行改变,就改变了结构体占用大小
接下来我们一起剖析一下 Part2,看看它的内部到底和上一位之间有什么区别,才导致了这样的结果?
分析流程
| 成员变量 | 类型 | 偏移量 | 自身占用 |
|---|---|---|---|
| e | byte | 0 | 1 |
| c | int8 | 1 | 1 |
| a | bool | 2 | 1 |
| 字节对齐 | 无 | 3 | 1 |
| b | int32 | 4 | 4 |
| d | int64 | 8 | 8 |
| 总占用大小 | - | - | 16 |
成员对齐
- 第一个成员 e
- 类型为 byte
- 大小/对齐值为 1 字节
- 初始地址,偏移量为 0。占用了第 1 位
- 第二个成员 c
- 类型为 int8
- 大小/对齐值为 1 字节
- 根据规则1,其偏移量必须为 1 的整数倍。当前偏移量为 2。不需要额外对齐
- 第三个成员 a
- 类型为 bool
- 大小/对齐值为 1 字节
- 根据规则1,其偏移量必须为 1 的整数倍。当前偏移量为 3。不需要额外对齐
- 第四个成员 b
- 类型为 int32
- 大小/对齐值为 4 字节
- 根据规则1,其偏移量必须为 4 的整数倍。确定偏移量为 4,因此第 3 位为 Padding。而当前数值从第 4 位开始填充,到第 8 位。如下:ecax|bbbb
- 第五个成员 d
- 类型为 int64
- 大小/对齐值为 8 字节
- 根据规则1,其偏移量必须为 8 的整数倍。当前偏移量为 8。不需要额外对齐,从 9-16 位填充 8 个字节。如下:ecax|bbbb|dddd|dddd
整体对齐
符合规则 2,不需要额外对齐
结果
Part2 内存布局:ecax|bbbb|dddd|dddd
总结
通过对比 Part1 和 Part2 的内存布局,你会发现两者有很大的不同。如下:
- Part1:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
- Part2:ecax|bbbb|dddd|dddd
仔细一看,Part1 存在许多 Padding。显然它占据了不少空间,那么 Padding 是怎么出现的呢?
通过本文的介绍,可得知是由于不同类型导致需要进行字节对齐,以此保证内存的访问边界
那么也不难理解,为什么调整结构体内成员变量的字段顺序就能达到缩小结构体占用大小的疑问了,是因为巧妙地减少了 Padding 的存在。让它们更 “紧凑” 了。这一点对于加深 Go 的内存布局印象和大对象的优化非常有帮
转载于https://segmentfault.com/a/1190000017527311
golang内存对齐分析(转载)的更多相关文章
- 什么是内存对齐,go中内存对齐分析
内存对齐 什么是内存对齐 为什么需要内存对齐 减少次数 保障原子性 对齐系数 对齐规则 总结 参考 内存对齐 什么是内存对齐 弄明白什么是内存对齐的时候,先来看一个demo type s struct ...
- 【转载】【内存对齐(二)】__declspec( align(#) )的用法和大小计算
转自:http://www.cppblog.com/deercoder/archive/2011/03/13/141747.html 感谢作者! 在上面讲到了关于pack的内存对齐和计算方法,这里继续 ...
- Nginx学习笔记(五) 源码分析&内存模块&内存对齐
Nginx源码分析&内存模块 今天总结了下C语言的内存分配问题,那么就看看Nginx的内存分配相关模型的具体实现.还有内存对齐的内容~~不懂的可以看看~~ src/os/unix/Ngx_al ...
- Unity3D–Texture图片空间和内存占用分析(转载)
原地址:http://www.unity蛮牛.com/home.php?mod=space&uid=1801&do=blog&id=756 Texture图片空间和内存占用分析 ...
- 查看w3wp进程占用的内存及.NET内存泄露,死锁分析--转载
一 基础知识 在分析之前,先上一张图: 从上面可以看到,这个w3wp进程占用了376M内存,启动了54个线程. 在使用windbg查看之前,看到的进程含有 *32 字样,意思是在64位机器上已32位方 ...
- Golang 是否有必要内存对齐?
原文:https://ms2008.github.io/2019/08/01/golang-memory-alignment/ 内存模型 Posted by ms2008 on August 1, 2 ...
- C语言内存对齐详解
一.字节对齐基本概念 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型 ...
- nginx 内存池分析
最近nginx的源码刚好研究到内存池,这儿就看下nginx内存池的相关的东西. 一,为什么要使用内存池 大多数的解释不外乎提升程序的处理性能及减小内存中的碎片,对于性能优化这点主要体现在: (1)系统 ...
- C/C++中的内存对齐问题和pragma pack命令详解
这个内存对齐问题,居然影响到了sizeof(struct)的结果值.突然想到了之前写的一个API库里,有个API是向后台服务程序发送socket请求.其中的socket数据包是一个结构体.在发送soc ...
随机推荐
- 开源三轴云台EVVGC(simple BGC)分析
一. 主程序分析 主程序结构清晰,流程如图所示,下面将对每个部分做详细分析 二. 系统初始化 系统初始化部分的流程如上图所示,下面对每部分做具体分析 1. 时钟初始化 该部分主要是使能DWT,用DWT ...
- Java并发编程虚假唤醒问题(生产者和消费者关系)
何为虚假唤醒: 当一个条件满足时,很多线程都被唤醒了,但是只有其中部分是有用的唤醒,其它的唤醒都是无用功:比如买货:如果商品本来没有货物,突然进了一件商品,这是所有的线程都被唤醒了,但是只能一个人买, ...
- C++设计模式 - 总结
一个目标:管理变化,提高复用 掌握设计模式一个核心目标:管理变化,提高复用.在使用设计模式中发现并没有实现复用,这就和设计初衷相违背了,说明代买写的不好. 两种手段:分解VS.抽象 在代码设计中,该开 ...
- JavaScript 里的 'this' 的一般解释
本文旨在帮助自己和大家理解 JS 里的 this, 翻译.整理并改写自本人关注的一个博主 Dmitri Pavlutin,原文链接如下: https://dmitripavlutin.com/gent ...
- mac phpstorm返回文件顶部或者底部
在Mac下,请按FN+Command+→|←,就这么简单~
- Oracle 关于v$之类的视图使用说明
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/19/cncpt/data-dictionary-and-dynamic ...
- Bootstrap Javascript组件,模态框级联open解决方案
<script type="text/javascript"> top.global={zIndex:null}; $("body>div[data-m ...
- 用maven建立一个工程4
在命令行里面输入cd C:\Users\admin\Documents\hello 然后按回车 再输入这行代码 mvn archetype:generate -DgroupId=com.liyongz ...
- 学习MFS(六)
一.文件系统选型 在一般的生产环境中,NFS共享存储算是比较常用的,简单.方便,但随着业务的不断扩展,数据量也是承爆发式的增长,因而对存储这些数据的文件系统要求也越来越高了,分存式.可扩展.大容量,这 ...
- linux命令手册
常⻅系统服务命令 常用命令 作用 chkconfig --list 列出系统服务 service <服务名> status 查看某个服务 service <服务名> start ...