强化学习-学习笔记9 | Multi-Step-TD-Target
这篇笔记依然属于TD算法的范畴。Multi-Step-TD-Target 是对 TD算法的改进。
9. Multi-Step-TD-Target
9.1 Review Sarsa & Q-Learning
- Sarsa
- 训练 动作价值函数 \(Q_\pi(s,a)\);
- TD Target 是 \(y_t = r_t + \gamma\cdot Q_\pi(s_{t+1},a_{t+1})\)
- Q-Learning
- 训练 最优动作价值函数 Q-star;
- TD Target 是 \(y_t = r_t +\gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},a)\)
- 注意,两种算法的 TD Target 的 r 部分 都只有一个奖励 \(r_t\)
- 如果用多个奖励,那么 RL 的效果会更好;Multi-Step-TD-Target就是基于这种考虑提出的。
在第一篇强化学习的基础概念篇中,就提到过,agent 会观测到以下这个轨迹:
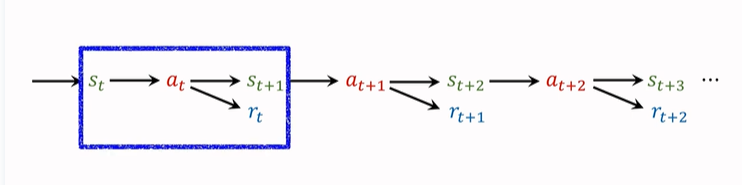
我们之前只使用一个 transition 来记录动作、奖励,并且更新 TD-Target。一个 transition 包括\((s_t,a_t,s_{t+1},r_t)\),只有一个奖励 \(r_t\)。(如上图蓝框所示)。
这样算出来的 TD Target 就是 One Step TD Target。
其实我们也可以一次使用多个 transition 中的奖励,得到的 TD Target 就是 Multi-Step-TD-Target。如下图蓝框选择了两个 transition,同理接下来可以选后两个 transition 。

9.2 多步折扣回报
Multi-Step Return.
折扣回报公式为:\(U_t=R_t+\gamma\cdot{U_{t+1}}\);
这个式子建立了 t 时刻和 t+1 时刻的 U 的关系,为了得到多步折扣回报,我们递归使用这个式子:
\(U_t=R_t+\gamma\cdot{U_{t+1}}\\=R_t+\gamma\cdot(R_{t+1}+\gamma\cdot{U_{t+2}})\\=R_t+\gamma\cdot{R_{t+1}}+\gamma^2\cdot{U_{t+2}}\)
这样,我们就可以包含两个奖励,同理我们可以有三个奖励......递归下去,包含 m个奖励为:
\(U_t=\sum_{i=0}^{m-1}\gamma^i\cdot{R_{t+i}}+\gamma^m\cdot{U_{t+m}}\)
即:回报 \(U_t\) 等于 m 个奖励的加权和,再加上 \(\gamma^m\cdot{U_{t+m}}\),后面这一项称为 多步回报。
现在我们推出了 多步的 \(U_t\) 的公式,进一步可以推出 多步 \(y_t\) 的公式,即分别对等式两侧求期望,使随机变量具体化:
Sarsa 的 m-step TD target:
\(y_t=∑_{i=0}^{m−1}\gamma^i\cdot r_{t+i}+\gamma^m\cdot{Q_\pi}(s_{t+m},a_{t+m})\)
注意:m=1 时,就是之前我们熟知的标准 TD Target。
多步的 TD Target 效果要比 单步 好。
Q-Learning 的 m-step TD target:
\(y_t = \sum_{i=0}^{m-1}\gamma^i{r_{t+i}}+\gamma^m\cdot\mathop{max}\limits_{a} Q^*({s_{t+m}},a)\)
同样,m=1时,就是之前的TD Target。
9.3 单步 与 多步 的对比
单步 TD Target 中,只使用一个奖励 \(r_t\);
如果用多步TD Target,则会使用多个奖励:\(r_t,r_{t+1},...,r_{t+m-1}\)
联想一下第二篇 价值学习 的旅途的例子,如果真实走过的路程占比越高,不考虑 “成本” 的情况下,对于旅程花费时间的估计可靠性会更高。
m 是一个超参数,需要手动调整,如果调的合适,效果会好很多。
x. 参考教程
- 视频课程:深度强化学习(全)_哔哩哔哩_bilibili
- 视频原地址:https://www.youtube.com/user/wsszju
- 课件地址:https://github.com/wangshusen/DeepLearning
强化学习-学习笔记9 | Multi-Step-TD-Target的更多相关文章
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习读书笔记 - 09 - on-policy预测的近似方法
强化学习读书笔记 - 09 - on-policy预测的近似方法 参照 Reinforcement Learning: An Introduction, Richard S. Sutton and A ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- 强化学习读书笔记 - 10 - on-policy控制的近似方法
强化学习读书笔记 - 10 - on-policy控制的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton an ...
- 强化学习-学习笔记4 | Actor-Critic
Actor-Critic 是价值学习和策略学习的结合.Actor 是策略网络,用来控制agent运动,可以看做是运动员.Critic 是价值网络,用来给动作打分,像是裁判. 4. Actor-Crit ...
- 强化学习-学习笔记8 | Q-learning
上一篇笔记认识了Sarsa,可以用来训练动作价值函数\(Q_\pi\):本篇来学习Q-Learning,这是另一种 TD 算法,用来学习 最优动作价值函数 Q-star,这就是之前价值学习中用来训练 ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
随机推荐
- 通过Nginx TCP反向代理实现Apache Doris负载均衡
概述 Nginx能够实现HTTP.HTTPS协议的负载均衡,也能够实现TCP协议的负载均衡.那么,问题来了,可不可以通过Nginx实现Apache Doris数据库的负载均衡呢?答案是:可以.接下来, ...
- MySQL进阶之表的增删改查
我的小站 修改表名 ALTER TABLE student RENAME TO stu; TO可以省略. ALTER TABLE 旧表名 RENAME 新表名; 此语句可以修改表的名称,其实一般我们在 ...
- HMS Core Discovery第14期回顾长文|纵享丝滑剪辑,释放视频创作力
HMS Core Discovery第14期直播<纵享丝滑剪辑,释放视频创作力>,已于4月21日圆满结束,本期直播我们同HMS Core视频编辑服务(Video Editor Kit)的产 ...
- 【面试普通人VS高手系列】Redis和Mysql如何保证数据一致性
今天分享一道一线互联网公司高频面试题. "Redis和Mysql如何保证数据一致性". 这个问题难倒了不少工作5年以上的程序员,难的不是问题本身,而是解决这个问题的思维模式. 下面 ...
- properties、yml配置文件映射对象
1.properties文件内容映射到类对象(属性),如Resource目录下的1.properties文件已配置前缀为com.imooc.people相关的信息,然后: pom添加依赖:spring ...
- XCTF练习题---WEB---robots
XCTF练习题---WEB---robots flag:cyberpeace{6c4b08933075fc620d16d1157ee07a7e} 解题步骤: 1.观察题目,打开场景 2.打开实验场景, ...
- XCTF练习题---MISC---掀桌子
XCTF练习题---MISC---掀桌子 flag:flag{hjzcydjzbjdcjkzkcugisdchjyjsbdfr} 解题步骤: 1.观察题目,发现没有附件,只有一串代码. 2.根据代码内 ...
- CoreWCF 1.0 正式发布,支持 .NET Core 和 .NET 5+ 的 WCF
CoreWCF 1.0 正式发布,支持 .NET Core 和 .NET 5+ 的 WCF https://devblogs.microsoft.com/dotnet/corewcf-v1-relea ...
- 请收藏,Linux 运维必备的 40 个命令总结,收好了~
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 1.删除0字节文件 find -type f -size ...
- 小程序扫码、上传图片、css时间轴
de <!-- 导航 --> <view class="navSec flexBox"> <text class="navItem {{ s ...