1.2 Hadoop简介-hadoop-最全最完整的保姆级的java大数据学习资料
1.2 Hadoop简介
1.2.1 什么是Hadoop
Hadoop 是一个适合大数据的分布式存储和计算平台
如前所述,狭义上说Hadoop就是一个框架平台,广义上讲Hadoop代表大数据的一个技术生态 圈,包括很多其他软件框架
Hadoop生态圈技术栈
Hadoop(HDFS + MapReduce + Yarn)
Hive 数据仓库工具
HBase 海量列式非关系型数据库
Flume 数据采集工具
Sqoop ETL工具
Kafka 高吞吐消息中间件
......
1.2.2 Hadoop的起源
Hadoop 的发展历程可以用如下过程概述:
Nutch —> Google论文(GFS、MapReduce)—> Hadoop产生 —> 成为Apache顶级项目—> Cloudera公司成立(Hadoop快速发展)
- Hadoop最早起源于Nutch,Nutch 的创始人是Doug Cutting
Nutch 是一个开源 Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题 - 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。GFS,可用于处理海量网页的存储;MapReduce,可用于处理海量网页的索引计算问题
Google的三篇论文(三驾马车)
GFS:Google的分布式文件系统(Google File System)
MapReduce:Google的分布式计算框架
BigTable:大型分布式数据库
发展演变关系:
GFS —> HDFS
Google MapReduce —> Hadoop MapReduce
BigTable —> HBase
- 随后,Google公布了部分GFS和MapReduce思想的细节,Doug Cutting等人用2年的业余时间实 现了DFS和MapReduce机制,使Nutch性能飙升
- 2005年,Hadoop 作为Lucene的子项目Nutch的一部分引入Apache
- 2006年,Hadoop从Nutch剥离出来独立
- 2008年,Hadoop成为Apache的顶级项目
- Hadoop这个名字来源于Hadoop之父Doug Cutting儿子的毛绒玩具象

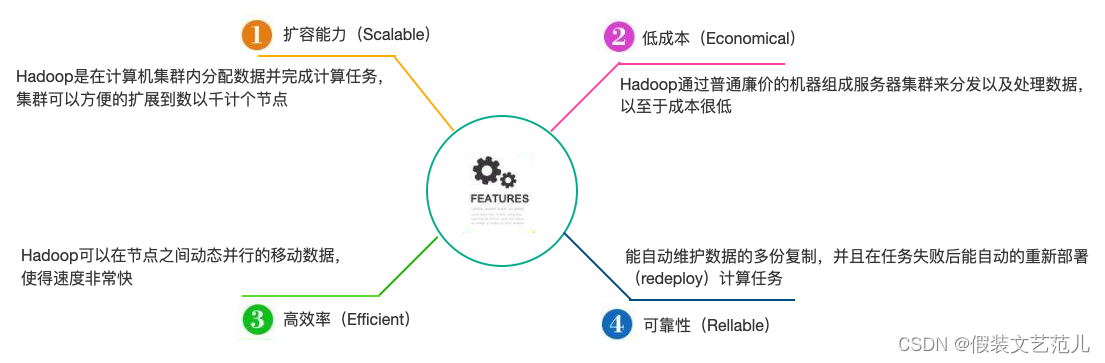
1.2.3 Hadoop的特点
1.2.4 Hadoop的发行版本
目前Hadoop发行版非常多,有Cloudera发行版(CDH)、Hortonworks发行版、华为发行版、 Intel发行版等,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,是由Apache Hadoop的开源协议决定的(任何人可以对其进行修改,并作为开源或商业产品发布/销售)
企业中主要用到的三个版本分别是:Apache Hadoop版本(最原始的,所有发行版均基于这个版本进行改进)、Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)、 Hortonworks版本(Hortonworks Data Platform,简称“HDP”)。
- Apache Hadoop 原始版本
官网地址:http://hadoop.apache.org/
优点:拥有全世界的开源贡献,代码更新版本比较快
缺点:版本的升级,版本的维护,以及版本之间的兼容性,学习非常方便
Apache所有软件的下载地址(包括各种历史版本):http://archive.apache.org/dist/ - 软件收费版本ClouderaManager CDH版本 --生产环境使用
官网地址:https://www.cloudera.com/
Cloudera主要是美国一家大数据公司在Apache开源Hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,生产环境强烈推荐使用 - 免费开源版本HortonWorks HDP版本--生产环境使用
官网地址:https://hortonworks.com/
hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks, 核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/)
1.2.5 Apache Hadoop版本更迭
0.x 系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x 版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x 版本系列:架构产生重大变化,引入了yarn平台等许多新特性
3.x 版本系列:EC技术、YARN的时间轴服务等新特性
1.2.6 第六节 Hadoop的优缺点
Hadoop的优点
- Hadoop具有存储和处理数据能力的高可靠性。
- Hadoop通过可用的计算机集群分配数据,完成存储和计算任务,这些集群可以方便地扩展到数以千计的节点中,具有高扩展性。
- Hadoop能够在节点之间进行动态地移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性。
- Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配,具有高容错性。
Hadoop的缺点
- Hadoop不适用于低延迟数据访问。
- Hadoop不能高效存储大量小文件。
- Hadoop不支持多用户写入并任意修改文件。
1.2 Hadoop简介-hadoop-最全最完整的保姆级的java大数据学习资料的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记1-大数据处理架构Hadoop
Hadoop:一个开源的.可运行于大规模集群上的分布式计算平台.实现了MapReduce计算模型和分布式文件系统HDFS等功能,方便用户轻松编写分布式并行程序. Hadoop生态系统: HDFS:Ha ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- java大数据最全课程学习笔记(2)--Hadoop完全分布式运行模式
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 Hadoop完全分布式运行模式 步骤分析: 编写集群分发脚本xsync 集群配置 集群部署规划 配置集群 集群单 ...
随机推荐
- JS 模块化 - 03 AMD 规范与 Require JS
1 AMD 规范介绍 AMD 规范,全称 Asynchronous Module Definition,异步模块定义,模块之间的依赖可以被异步加载. AMD 规范由 Common JS 规范演进而来, ...
- Beats:在Docker里运行Filebeat
- EFK-4::ElasticSearch集群TLS加密通讯
转载自:https://mp.weixin.qq.com/s?__biz=MzUyNzk0NTI4MQ==&mid=2247483822&idx=1&sn=6813b22eb5 ...
- 如何从Django项目中删除或隐藏应用
1.项目的settings.py文件 INSTALLED_APPS中删除或者注释掉,这是针对数据库这一块儿的 2.项目的urls.py文件 删除或这注释掉应用的路径导入 urlpatterns中删除或 ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
- Redis从入门到高级笔记【涵盖重点面试题】
NoSQL数据库 DBEngines网站中会统计目前数据库在全世界的排名 1.1 什么是NoSQL 最常见的解释是"non-relational",很多人说它是"Not ...
- 使用 Loki 搭建个人日志平台
文章转载自:https://blog.kelu.org/tech/2020/01/31/grafana-loki-for-logging-aggregation.html 背景 Loki的第一个稳定版 ...
- 14. Fluentd输出插件:out_forward用法详解
out_forward是一个带缓存的输出插件,用于向其他节点转发日志事件,并支持转发节点之间的负载均衡和自动故障切换. out_forward支持至多一次和至少一次传输模式,默认为至多一次. out_ ...
- Java程序设计(三)作业
题目1:用户输入学号,如果是以ccutsoft开头,并且后边是4位数字,前两位大于06小于等于当前年份.判断用户输入是否合法.ccutsoft_0801. 1 //题目1:用户输入学号,如果是以abc ...
- Springboot 之 Filter 实现 Gzip 压缩超大 json 对象
简介 在项目中,存在传递超大 json 数据的场景.直接传输超大 json 数据的话,有以下两个弊端 占用网络带宽,而有些云产品就是按照带宽来计费的,间接浪费了钱 传输数据大导致网络传输耗时较长 为了 ...