JVM学习笔记——垃圾回收篇
JVM学习笔记——垃圾回收篇
在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的垃圾回收部分
我们会分为以下几部分进行介绍:
- 判断垃圾回收对象
- 垃圾回收算法
- 分代垃圾回收
- 垃圾回收器
- 垃圾回收调优
判断垃圾回收对象
本小节将会介绍如何判断垃圾回收对象
引用计数法
首先我们先来介绍引用计数法的定义:
- 我们为对象附上一个当前使用量
- 当有线程使用时,我们将该值加一;当线程停止使用时,我们将该值减一
- 当当前使用量大于零时,我们创建该对象;当当前使用量减少为零时,我们将该对象当作垃圾回收对象
但该方法存在一个致命问题:
- 当两个对象互相调用对方时,就会导致当前使用量一直不为空,占用内存
可达性分析算法
同样我们先来简单介绍可达性分析算法:
- 我们首先判定一些对象为Root对象
- 我们根据这些对象来选择判定其他对象是否为垃圾回收对象
- 当该对象直接或间接被Root对象所引用时,我们不设置为垃圾回收对象;当没有被Root对象连接时,设置为垃圾回收对象
然后我们来简单介绍一下Root对象的分类(来自MAT工具统计):
- System Class:直属于Java包下的相关类,包括有Object,String,Stream,Buffer等
- Native Stack:直属于操作系统交互的类,包括有wait等
- Busy Monitor:读锁机制相关的类,当前状态下被锁定的对象是无法当作垃圾回收对象的
- Thread:互动线程,线程相关的类也无法当作垃圾回收对象
可达性分析算法就是目前Java虚拟机所使用的垃圾回收器判定方法
五种引用
下面我们将会介绍JVM中常用的五种引用方法,他们分别对应着不同的回收对象判定情况:
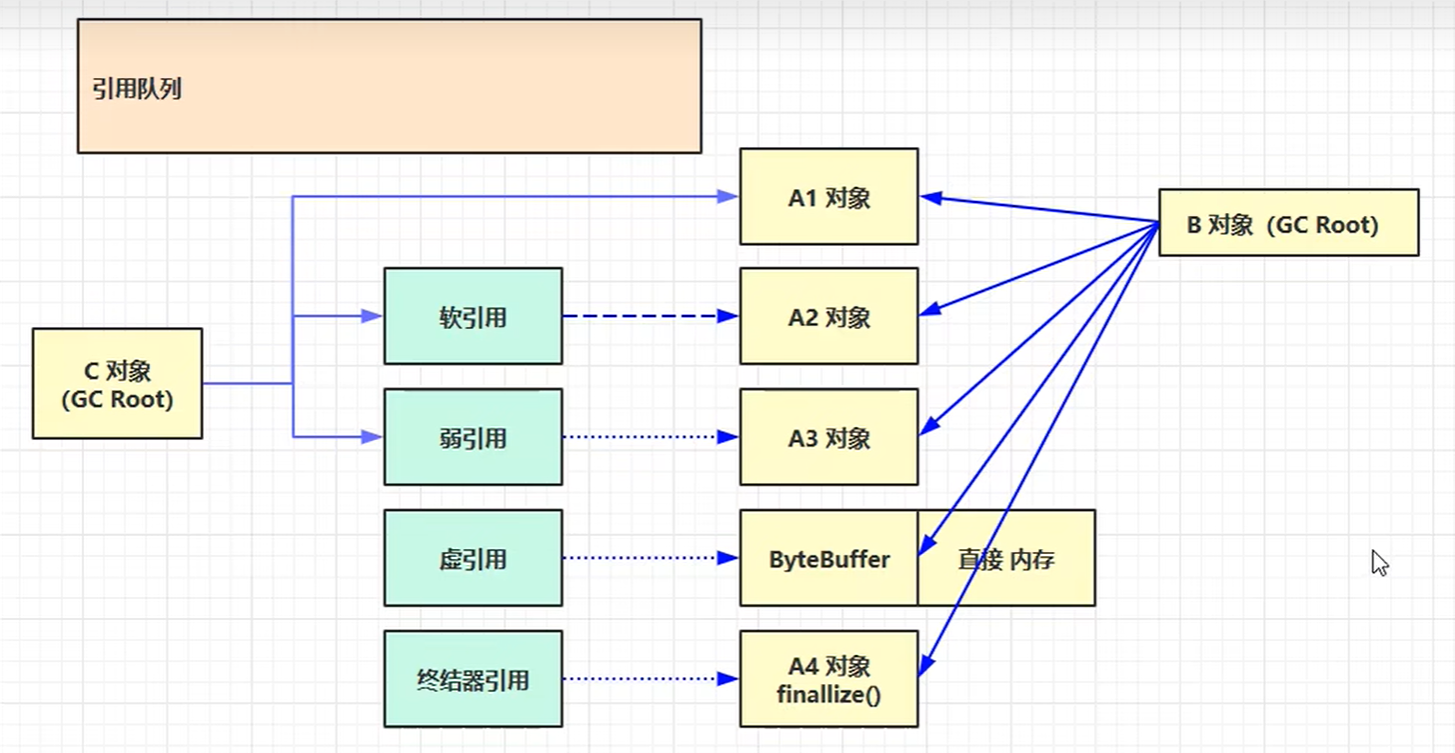
我们下面来一一介绍
强引用
上述图片中的A1对象就是强引用示例
我们下面介绍强引用的概念:
- 强引用就是由Root对象直接引用的对象
然后我们介绍强引用的回收概念:
- 只有当所有强引用连接都消失时,该对象才会被列为垃圾回收对象
- 例如上图,A1对象由B,C两个对象所强引用连接,只有当两个对象都取消引用后,A1对象才会被列入回收对象
软引用
上述图片中的A2对象就是软引用示例
我们下面介绍软引用的概念:
- 软引用不是由根Root直接引用,而是采用一个软引用对象SoftReference连接
然后我们介绍软引用的回收概念:
- 当该对象没有被强引用连接,被软引用连接时有可能会被回收
- 每次发生垃圾回收,如果垃圾回收后的内存够用,则不进行软引用对象的垃圾回收;若内存不足,则进行软引用对象的垃圾回收
此外我们的软引用对象也是会占用内存的,所以我们也需要采用其他方法将软引用对象回收:
- 我们通常将软引用对象绑定一个引用队列
- 当该软引用对象不再连接任何对象时,将其放入引用队列,引用队列会进行检测,检测到软引用对象就会对其进行垃圾回收
我们首先给出软引用对象的相关测试代码:
package cn.itcast.jvm.t2;
import java.io.IOException;
import java.lang.ref.SoftReference;
import java.util.ArrayList;
import java.util.List;
/**
* 演示软引用
* -Xmx20m -XX:+PrintGCDetails -verbose:gc
*/
public class Demo2_3 {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) throws IOException {
// 这部分是强引用对象,我们会发现所有内存都放在内部,导致内存不足
List<byte[]> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
list.add(new byte[_4MB]);
}
System.in.read();
// 调用下列方法(软引用)
soft();
}
// 软引用
public static void soft() {
// 软引用逻辑:list --> SoftReference --> byte[]
// 创建软引用
List<SoftReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
// 首先new一个SoftReference并赋值
SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB]);
System.out.println(ref.get());
// 将SoftReference加入list
list.add(ref);
System.out.println(list.size());
}
System.out.println("循环结束:" + list.size());
for (SoftReference<byte[]> ref : list) {
System.out.println(ref.get());
}
}
}
/*
调试过程:
如果我们采用强引用方法,正常情况下会在第五次循环时报错
但是如果我们采用软引用,我们会在第五次循环时发生gc清理,这时我们前四次的添加(list的前四位)就会被软引用清除
所以我们在最后循环结束后查看数组会发现:
null
null
null
null
[B@330bedb4
*/
我们再给出软引用对象回收的相关测试代码:
package cn.itcast.jvm.t2;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.lang.ref.SoftReference;
import java.util.ArrayList;
import java.util.List;
/**
* 演示软引用, 配合引用队列
*/
public class Demo2_4 {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) {
// 这里设置了List,里面的SoftReference是软引用对象,再在里面添加的数据就是软引用对象所引用的A2对象
List<SoftReference<byte[]>> list = new ArrayList<>();
// 引用队列(类型和引用对象的类型相同即可)
ReferenceQueue<byte[]> queue = new ReferenceQueue<>();
for (int i = 0; i < 5; i++) {
// 关联了引用队列, 当软引用所关联的 byte[]被回收时,软引用自己会加入到 queue 中去
SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB], queue);
System.out.println(ref.get());
list.add(ref);
System.out.println(list.size());
}
// 从队列中获取无用的 软引用对象,并移除
Reference<? extends byte[]> poll = queue.poll();
while( poll != null) {
list.remove(poll);
poll = queue.poll();
}
System.out.println("===========================");
for (SoftReference<byte[]> reference : list) {
System.out.println(reference.get());
}
}
}
/*
和之前那此调试相同,前四次正常运行,在第五次时进行了gc清理
但是在循环结束之后,我们将软引用对象放入到了引用队列中并进行了清理,所以这时我们的list中前四次软引用对象直接消失
我们只能看到list中只有一个对象:
[B@330bedb4
*/
弱引用
上述图片中的A3对象就是弱引用示例
我们下面介绍强弱引用的概念:
- 弱引用不是由根Root直接引用,而是采用一个弱引用对象WeakReference连接
然后我们介绍弱引用的回收概念:
- 当该对象没有被强引用连接,被弱引用连接时在进行Full gc时会被强制回收
- 每次进行老年代的Full gc(后面会讲到Full gc,这里就当作大型垃圾回收)时都会被强制回收
此外我们的弱引用对象也是会占用内存的,所以我们也需要采用相同方法将弱引用对象回收:
- 我们通常将弱引用对象绑定一个引用队列
- 当该弱引用对象不再连接任何对象时,将其放入引用队列,引用队列会进行检测,检测到弱引用对象就会对其进行垃圾回收
我们同样给出弱引用对象的垃圾回收示例代码:
package cn.itcast.jvm.t2;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.lang.ref.SoftReference;
import java.lang.ref.WeakReference;
import java.util.ArrayList;
import java.util.List;
/**
* 演示弱引用
* -Xmx20m -XX:+PrintGCDetails -verbose:gc
*/
public class Demo2_5 {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) {
// list --> WeakReference --> byte[]
List<WeakReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
WeakReference<byte[]> ref = new WeakReference<>(new byte[_4MB]);
list.add(ref);
for (WeakReference<byte[]> w : list) {
System.out.print(w.get()+" ");
}
System.out.println();
}
System.out.println("循环结束:" + list.size());
}
}
/*
这时我们的小型gc(新生代gc)是不会触发弱引用全部删除的(新生代我们后面会讲到)
只有当内存全部占满后,触发的Full gc才会导致弱引用的必定回收
例如我们在第5,7次新生代发生内存占满,这时触发了新生代的gc,但是只会删除部分WeakReference
当我们第9次新生代,老生代内存全部占满后会发生一次Full gc,这时就会引起全部弱引用数据删除,所以我们的数据会变成:
null
null
null
null
null
null
null
null
null
[B@330bedb4
*/
虚引用
上述图片中的ByteBuffer对象就是虚引用示例
我们下面介绍虚引用的概念:
- 虚引用实际上就是直接内存的引用,我们内存结构篇所学习的ByteBuffer就是例子
- 系统首先会创建一个虚引用,然后这个虚引用会创建一个ByteBuffer对象,ByteBuffer对象通过unsafe来管理直接内存
- 此外,我们的虚引用必定需要绑定一个引用队列,因为我们的byteBuffer对象是无法控制直接内存的,我们需要检测虚引用来删除
然后我们介绍虚引用的回收概念:
- 首先我们会手动删除或者系统垃圾回收掉ByteBuffer对象
- 这时我们的虚引用和直接内存是不会消失的,但是我们的虚引用会被带到引用队列中
- 虚引用中携带者Cleaner对象,引用队列会一直检测是否有Cleaner对象进入,当检测到时会执行这个Cleaner方法来删除直接内存
我们需要注意的是:
- 引用队列中检测Cleaner对象的优先级较高,所以效率相关而言比较快
终结器引用
上述图片的A4对象就是终结器引用
我们下面介绍终结器引用的概念:
- 终结器引用实际上是对象自己定义的finallize方法
- 终结器对象同样也需要绑定引用队列,因为他需要靠终结器对象来清除内部对象
然后我们介绍终结器引用的回收概念:
- 如果我们希望清除终结器引用的对象,那么我们需要先将终结器引用对象导入到引用队列中
- 引用队列中同样也会一直检测是否出现终结器对象,若出现终结器对象,那么针对该终结器对象调用其内部对象的finallize方法删除
我们需要注意的是:
- 引用队列中检测终结器对象的优先级较低,所以效率相关而言比较慢
垃圾回收算法
本小节将会介绍垃圾回收的三种基本回收算法
标记清除法
我们首先给出简单图示:

我们来做简单解释:
- 首先我们找出需要进行垃圾回收的部分并进行标记
- 然后我们将该标记地址部分清除即可(注意:这里的清除仅仅是记录起始地址和终止地址,然后在其他内存占用时再次覆盖)
该算法的优缺点:
- 执行速度极快
- 但会产生内存碎片,当内存碎片逐渐增多会导致问题
标记整理法
我们首先给出简单图示:

我们来做简单解释:
- 首先我们根据Root标记出需要垃圾回收的部分
- 然后我们将垃圾回收的部分抛出之后,将后面的部分进行地址腾挪,使其紧凑
该算法的优缺点:
- 不会产生内存碎片,导致内存问题
- 速度较慢,同时整理过程中其他进程全部停止(因为会涉及内存地址重塑,进行其他进程可能会导致内存放置地址错误)
区域复制法
我们首先给出简单图示:
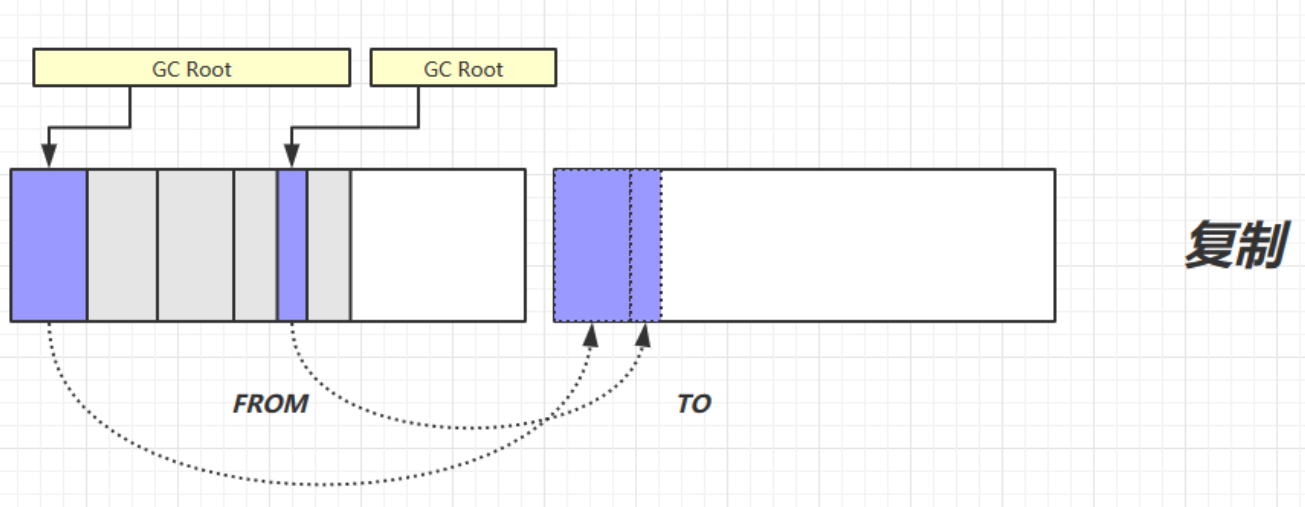
我们来做简单解释:
- 我们准备两块完全相同的区间,将他们分为From和To区间
- 我们首先在from区间存储数据,我们直接进行垃圾回收判定
- 然后将需要保存的数据直接放入To区间,垃圾回收的部分不需要管理
- 最后我们将From和To区间的定义交换,将新添加的数据放入现在的From区间(之前腾挪的To区间)
该算法的优缺点:
- 不会产生内存碎片,相对而言比较迅速
- 但需要占用两块相同的地址空间,导致占用空间较多
分代垃圾回收机制
本小节将会介绍垃圾回收的常用机制
分代垃圾回收机制介绍
我们前面已经介绍了三种垃圾回收算法,但实际上我们的垃圾回收采用的是三种方法的组合方法:
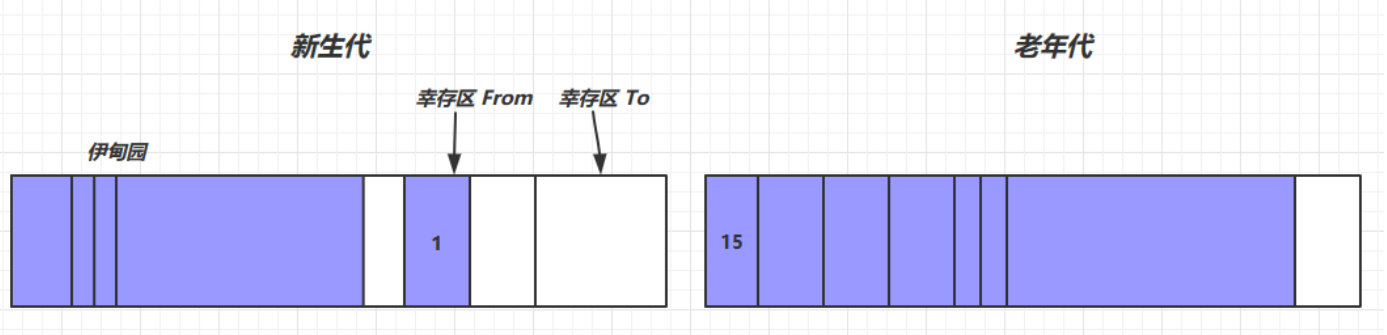
我们首先对大概念进行介绍:
- 新生代:用于存放新产生的内存数据,清除频繁
- 老生代:用于存放一直使用的内存数据,只有当内存占满时才会清理
然后我们对小概念进行介绍:
- 伊甸园:用于存放所有的新产生的内存数据
- 幸存区From:用于存放未被垃圾回收的数据
- 幸存区To:用于进行未被垃圾回收的数据的复制方法
- 幸存值:用于表示内存数据的常用程度,所有内存数据进入时默认值为0,
然后我们对整个回收机制进行介绍:
- 首先我们的新数据都会进入到新生代的伊甸园中去,默认幸存值为0
- 当伊甸园数据满后,会进行gc,这时我们进行标记清除法,将不需要的内存筛出
- 同时将幸存下来的内存数据放入到幸存区From,幸存值+1,同时进行From和To区间的对调
- 我们继续进行储存直到伊甸园再次占满,对整个新生代进行gc
- 首先将幸存区From的幸存内存放入To中并将伊甸园的幸存数据放入To,进行区间调换,幸存值+1
- 直到幸存值达到一个阈值(默认为6或者15),该内存数据就会被移动到老年代,新生代仍旧继续工作
- 直至新生代和老年代全部都占满后,这时我们就需要进行大型的垃圾回收,也就是我们之前提到的Full gc!
分代垃圾回收相关VM参数
我们下面介绍一下分代垃圾回收机制的相关参数:
| 含义 | 参数 |
|---|---|
| 堆初始大小 | -Xms |
| 堆最大大小 | -Xmx 或 -XX:MaxHeapSize=size |
| 新生代大小 | -Xmn 或 (-XX:NewSize=size + -XX:MaxNewSize=size ) |
| 幸存区比例(动态) | -XX:InitialSurvivorRatio=ratio 和 -XX:+UseAdaptiveSizePolicy |
| 幸存区比例 | -XX:SurvivorRatio=ratio |
| 晋升阈值 | -XX:MaxTenuringThreshold=threshold |
| 晋升详情 | -XX:+PrintTenuringDistribution |
| GC详情 | -XX:+PrintGCDetails -verbose:gc |
| FullGC 前 MinorGC (小gc) | -XX:+ScavengeBeforeFullGC |
分代垃圾回收案例展示
我们通过一个简单的实例来展示分代垃圾回收的实际演示:
// 相关配置信息:配置默认大小,设置回收方法,显示GC详情,开启FullGC前进行gc
// -Xms20M -Xmx20M -Xmn10M -XX:+UseSerialGC -XX:+PrintGCDetails -verbose:gc -XX:-ScavengeBeforeFullGC
/*
首先我们展示不添加内存的状况
*/
package cn.itcast.jvm.t2;
import java.util.ArrayList;
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
/*
其中def new generation,eden space是新生代,tenured generation是老年代,from,to幸存区
Heap
def new generation total 9216K, used 4510K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 55% used [0x00000000fec00000, 0x00000000ff067aa0, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
tenured generation total 10240K, used 0K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 0% used [0x00000000ff600000, 0x00000000ff600000, 0x00000000ff600200, 0x0000000100000000)
Metaspace used 4362K, capacity 4714K, committed 4992K, reserved 1056768K
class space used 480K, capacity 533K, committed 640K, reserved 1048576K
*/
/*
然后我们展示添加1mb的情况
*/
package cn.itcast.jvm.t2;
import java.util.ArrayList;
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
list.add(new byte[_1MB]);
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
/*
我们可以发现新生代数据增加,老年代未发生变化
Heap
def new generation total 9216K, used 5534K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 67% used [0x00000000fec00000, 0x00000000ff167a40, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
tenured generation total 10240K, used 0K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 0% used [0x00000000ff600000, 0x00000000ff600000, 0x00000000ff600200, 0x0000000100000000)
Metaspace used 4354K, capacity 4714K, committed 4992K, reserved 1056768K
class space used 480K, capacity 533K, committed 640K, reserved 1048576
*/
/*
最后需要补充讲解一点:当我们的新生代不足以装载数据内存时,我们会直接将其装入老年代(老年代能够装载情况下)
*/
package cn.itcast.jvm.t2;
import java.util.ArrayList;
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
list.add(new byte[_8MB]);
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
/*
我们会发现eden的值未发生变化,但是tenured generation里面装载了8192K
Heap
def new generation total 9216K, used 4510K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 55% used [0x00000000fec00000, 0x00000000ff067a30, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
tenured generation total 10240K, used 8192K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 80% used [0x00000000ff600000, 0x00000000ffe00010, 0x00000000ffe00200, 0x0000000100000000)
Metaspace used 4360K, capacity 4714K, committed 4992K, reserved 1056768K
class space used 480K, capacity 533K, committed 640K, reserved 1048576K
*/
/*
当然,当我们的新生代和老年代都不足以装载时,系统报错~
*/
package cn.itcast.jvm.t2;
import java.util.ArrayList;
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
list.add(new byte[_8MB]);
list.add(new byte[_8MB]);
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
/*
我们首先会看到他在Full gc之前做了一次小gc,然后做了一次Full gc,可是这并无法解决问题
[GC (Allocation Failure) [DefNew: 4345K->999K(9216K), 0.0016573 secs][Tenured: 8192K->9189K(10240K), 0.0022899 secs] 12537K->9189K(19456K), [Metaspace: 4352K->4352K(1056768K)], 0.0039931 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [Tenured: 9189K->9124K(10240K), 0.0018331 secs] 9189K->9124K(19456K), [Metaspace: 4352K->4352K(1056768K)], 0.0018528 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
然后系统进行报错
Exception in thread "Thread-0" java.lang.OutOfMemoryError: Java heap space
at cn.itcast.jvm.t2.Demo2_1.lambda$main$0(Demo2_1.java:20)
at cn.itcast.jvm.t2.Demo2_1$$Lambda$1/1023892928.run(Unknown Source)
at java.lang.Thread.run(Thread.java:750)
最后我们可以看到老年代占用了89%,第一个数据仍旧保存,但第二个数据无法保存导致报错
Heap
def new generation total 9216K, used 366K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 4% used [0x00000000fec00000, 0x00000000fec5baa8, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
tenured generation total 10240K, used 9124K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 89% used [0x00000000ff600000, 0x00000000ffee93c0, 0x00000000ffee9400, 0x0000000100000000)
Metaspace used 4379K, capacity 4704K, committed 4992K, reserved 1056768K
class space used 480K, capacity 528K, committed 640K, reserved 1048576K
我们还需要注意的是:即使内存不足发生报错,但该程序不会结束;系统只会释放自己当前项目的进程而不会影响其他进程
*/
垃圾回收器
前面我们已经介绍了垃圾回收机制,现在我们来介绍常用的垃圾回收器
STW概念
我们在正式讲解垃圾回收器之前,我们先来回顾一个概念STW:
- STW即Stop The World,意思是暂停所有进程处理
- 因为我们在进行垃圾处理时,会涉及到地址空间的整合(标记整理法),这时所有CPU都需要停止操作
串行垃圾回收器
我们首先来介绍串行垃圾回收器的特点:
- 单线程
- 适用于堆内存较小,适合单人电脑
我们给出串行垃圾回收器的展示图:

我们所需配置:
// 设置 新生代回收方法复制 老年代回收方法为标记整理法
-XX:+UseSerialGC = Serial + SerialOld
我们来简单解释一下:
- 串行操作属于单核CPU处理
- 我们在处理该CPU的垃圾回收时,只有该线程的CPU进行操作
- 但同时老年代采用标记整理法会涉及到内存地址重新规划,所以其他CPU也需要暂停操作,即STW
吞吐量优先垃圾回收器
我们首先来介绍吞吐量优先垃圾回收器的特点:
- 多线程
- 适用于堆内存较大,需要多核CPU
- 让单位时间内,STW时间最短,例如每次STW0.2秒,但执行两次,共用0.4s(总时间最短)
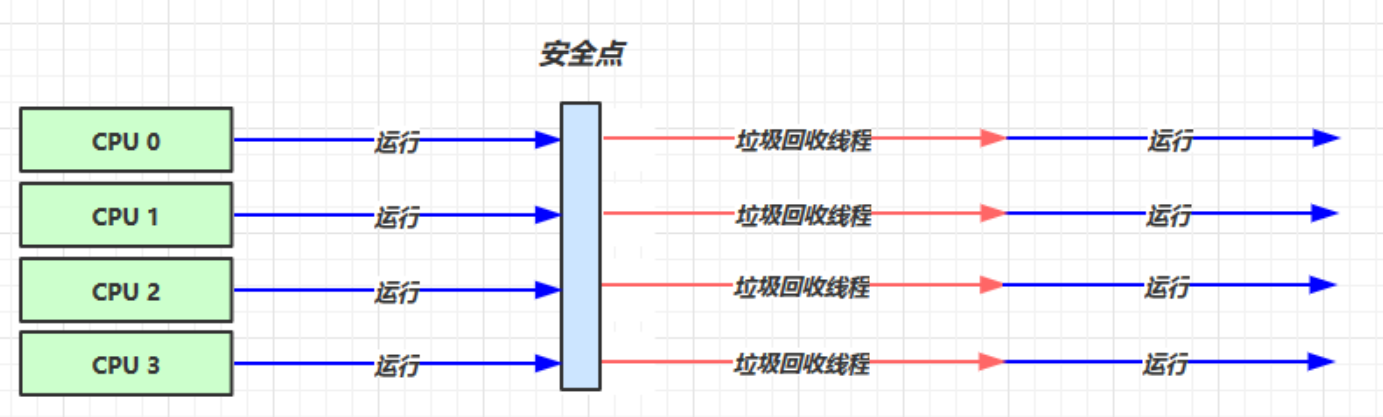
我们给出吞吐量优先垃圾回收器的展示图:
我们所需配置:
// 设置垃圾回收器方法
XX:+UseParallelGC ~ -XX:+UseParallelOldGC
// 自适应新生代晋升老年代的阈值处理
-XX:+UseAdaptiveSizePolicy
// 设置垃圾回收时间占总时间的比例(与-XX:MaxGCPauseMillis=ms冲突)
-XX:GCTimeRatio=ratio
// 设置最大STW时间(与-XX:GCTimeRatio=ratio冲突)
-XX:MaxGCPauseMillis=ms
// 设置最大同时进行CPU个数
-XX:ParallelGCThreads=n
我们来简单解释一下:
- 吞吐量优先垃圾回收器是多核CPU处理回收器
- 当一个进程发生垃圾回收时,我们会将所有CPU都用于垃圾回收,这时CPU利用率为100%
响应时间优先垃圾回收器
我们首先来介绍响应时间优先垃圾回收器的特点:
多线程
适用于堆内存较大,需要多核CPU
让单次STW时间最短,例如每次STW0.1秒,但执行五次,共用0.5s(单次时间最短)
我们给出响应时间优先垃圾回收器的展示图:
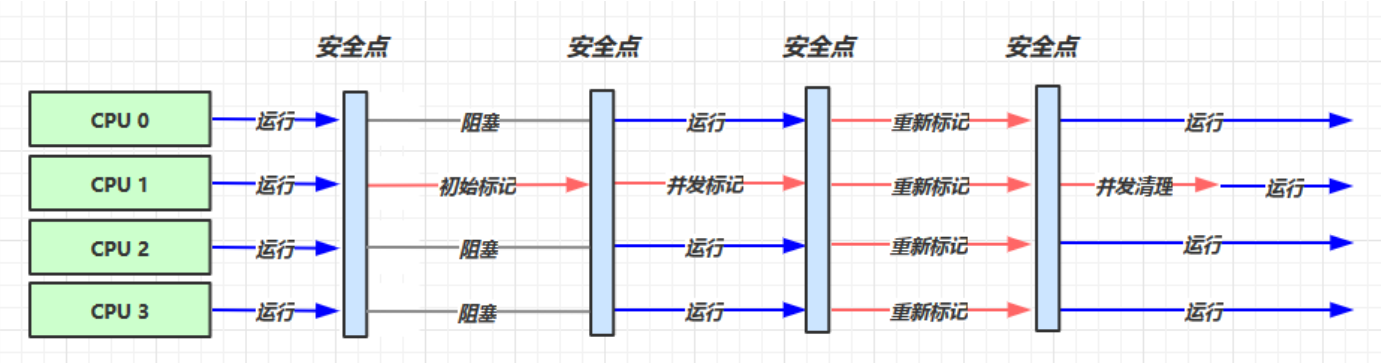
我们所需配置:
// +UseConcMarkSweepGC:设置并发标记清除算法,允许用户进程单独进行,但部分时间还需要阻塞
// -XX:+UseParNewGC:设置新生代算法,
// SerialOld:当老年代并发失败,采用单线程方法
-XX:+UseConcMarkSweepGC ~ -XX:+UseParNewGC ~ SerialOld
// -XX:ParallelGCThreads=n:并行数设置为n
// -XX:ConcGCThreads=threads:并发线程最好设置为CPU的1/4个数,相当于只有1/4个CPU在处理垃圾回收
-XX:ParallelGCThreads=n ~ -XX:ConcGCThreads=threads
// 预留空间(因为并发清理时其他进程可能会产生一些垃圾,这些垃圾目前无法处理,我们需要预留一定空间进行储存)
-XX:CMSInitiatingOccupancyFraction=percent
// 我们在重新标记阶段前,先对新生代进行垃圾回收,节省其标记量
-XX:+CMSScavengeBeforeRemark
我们来简单解释一下:
- 响应时间优先垃圾回收器是多核CPU处理回收器
- 首先我们的CPU1进行初始标记,其他进程阻塞,仅标记一些Root对象(时间短)
- 然后我们CPU1进行并发标记,其他进程继续运行,这时用来标记所有的垃圾回收对象(时间长)
- 然后由于我们的并发标记可能会导致一些内存混乱,所以我们将所有CPU需要进行重新标记(时间短)
- 最后只需要对CPU1进行并发清理即可,其他进程继续运行
G1垃圾回收器
下面我们将会针对jdk1.9默认垃圾回收器做一个详细的介绍
G1垃圾回收器简介
首先我们先来简单介绍一下G1垃圾回收器:
- G1回收器:Garbage First
- 在2017成为JDK9的默认垃圾回收器
下面我们来介绍G1垃圾回收器的特点:
- 同时注重吞吐量和低延迟,默认的暂停目标是200ms
- 超大堆内存,将堆划分为多个大小相等的Region
- 整体上是标记整理法,但两个区域之间是复制算法
相关JVM参数:
- -XX:+UseG1GC 使用G1垃圾回收器(JDK9之前都不是默认回收器)
- -XX:G1HeapRegionSize=size 设置Region的大小
- -XX:MaxGCPauseMillis=time 设置最大的G1垃圾回收时间
G1垃圾回收器阶段简介
我们通过一张图来简单介绍G1垃圾回收器的过程:
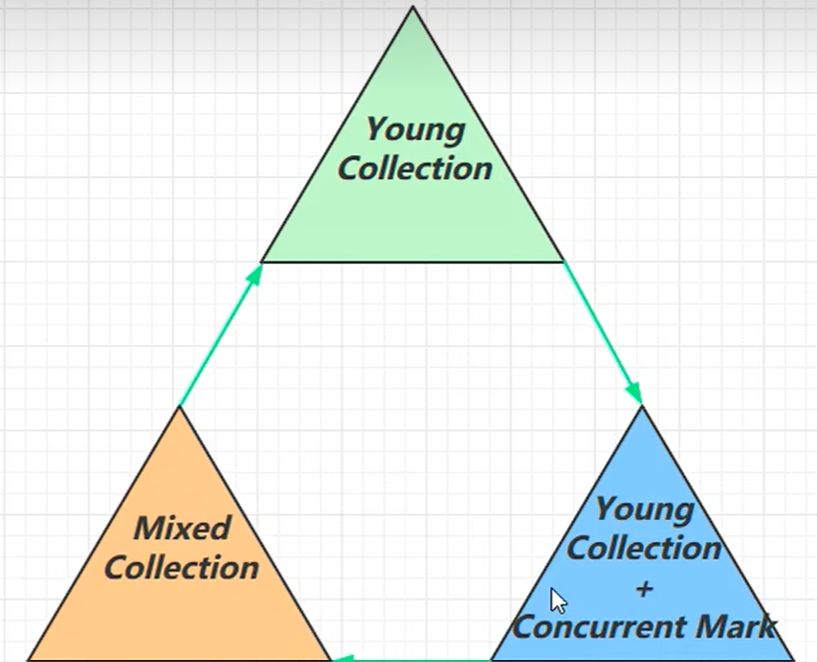
我们可以看到整个流程分为三个阶段:
- YoungCollection:新生代阶段
- YoungCollection+ConcurrentMark:新生代阶段+并发标记阶段
- MixedCollection:混合收集阶段
Young Collection
我们首先给出该阶段的展示图:
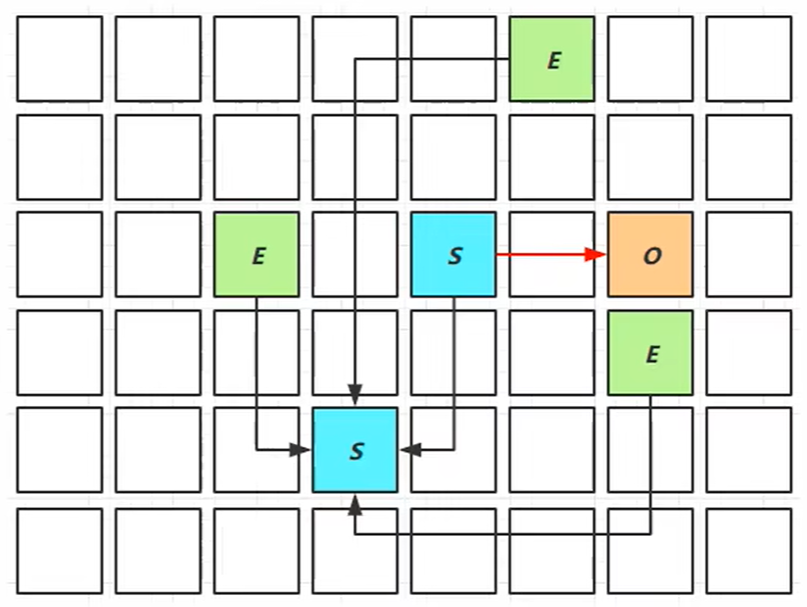
我们对其进行解释:
- E就是伊甸园,S就是幸存区,O就是老年代
- 其产生的正常流程就和分代垃圾回收机制一样,但这阶段不会产生GC
Young Collection + CM
我们首先给出该阶段的展示图:
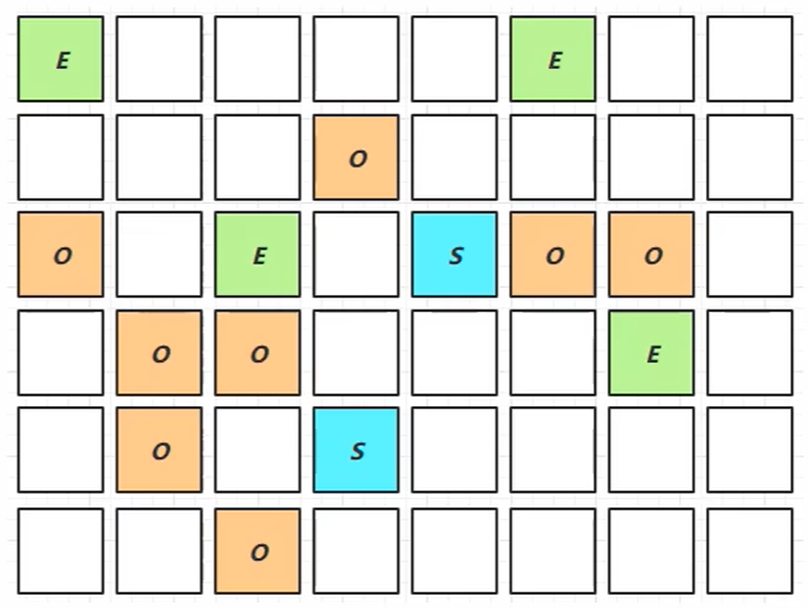
我们对其进行解释:
- 其字符含义完全相同
- 当新生代内存占满后进行Young GC时会同时进行GC Root的初始标记
- 老年代占用堆空间比例达到阈值时,进行并发标记(不会产生STW),阈值可以控制
我们给出并发标记阈值控制语句:
// 阈值控制
-XX:InitiatingHeapOccupancyPercent=percent (默认45%)
Mixed Collection
我们首先给出该阶段的展示图:
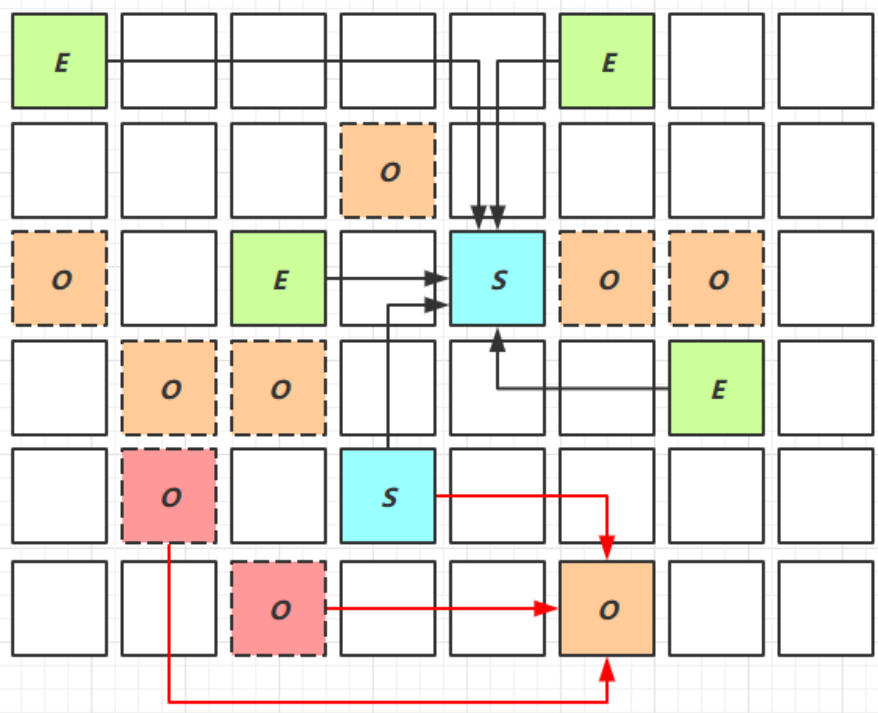
我们对其进行解释:
- 其字符含义完全相同
- 但该阶段会对E,S,O进行全面垃圾回收
- 其中最终标记(Remark)和拷贝存活(Evacation)都会STW(我们均会在后面解释)
我们需要注意一点:
- Mixed Collection可能并不会将所有老年代的数据都删除
- 它会根据你设置的最大暂停时间来进行抉择,如果时间不足以删除所有老年代数据,就会挑选部分较大的内存数据进行回收
Full GC
我们需要重新总结一下Full GC操作:
- SerialGC(串行垃圾回收)
- 新生代内存不足时发生的垃圾收集 - minor gc
- 老年代内存不足时发生的垃圾收集 - full gc
- ParalllelGC(吞吐量优先垃圾回收)
- 新生代内存不足时发生的垃圾收集 - minor gc
- 老年代内存不足时发生的垃圾收集 - full gc
- CMS(响应时间优先垃圾回收)
- 新生代内存不足时发生的垃圾收集 - minor gc
- 老年代内存不足时优先进行标记操作同步垃圾回收,当内存完全占满后才采用full gc
- G1(Garbage First)
- 新生代内存不足时发生的垃圾收集 - minor gc
- 老年代内存不足时优先进行MixedCollection同步垃圾回收,当内存完全占满后才采用full gc
G1知识点补充
我们在前面已经提到了我们将堆划分为多个Region
但其实这个Region并不仅仅只分为了E,S,O三个空间,此外还包括以下空间:
- RSet(Remember Set :记忆集合)
/*
每一个Region都会划出一部分内存用来储存记录其他Region对当前持有Rset Region中Card的引用
针对G1的垃圾回收时间设置较短,在进行标记过程中可能会导致时间过长,所以我们设置了RSet来储存部分信息
我们可以直接通过扫描每块Region里面的RSet来分析垃圾比例最高的Region区,放入CSet中,进行回收。
*/
- CSet(Collection Set 回收集合)
/*
收集集合代表每次GC暂停时回收的一系列目标分区。
在任意一次收集暂停中,CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。
年轻代收集CSet只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到CSet中。
*/
新生代跨代引用
由于我们的初次标记时会去寻找Root部分
但其实大部分的Root都放入了老年代,但老年底数据较多难以查找,所以G1提供了一种方法:
- 将老年代O再次划分为多个区间,名为卡
- 如果该卡中存储了Root部分,那么就将该卡标记为脏卡,同时放于RSet中存储起来便于查找
我们给出简单图示:
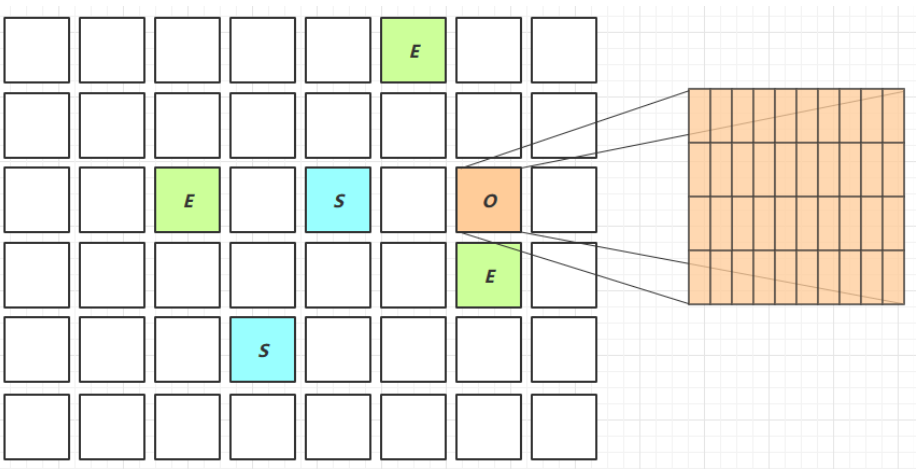
同时如果该Root地址发生变化,G1给出了另外的方法进行更换:
- 在引用变更时通过post-write barrier + dirty card queue
- concurrent refinement threads 更新 Remembered Set
Remark重新标记
我们在进行标记时通常采用三色标记法:
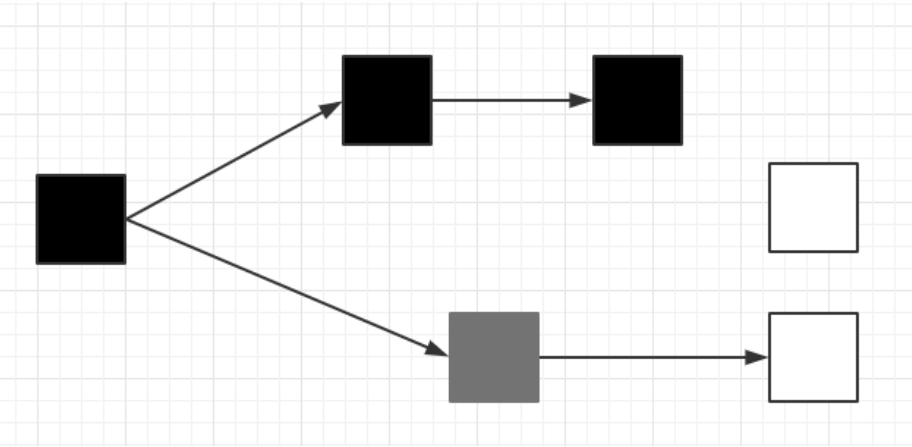
我们做简单介绍:
- 黑色是已经标记结束的内存
- 灰色是正在标记的内存
- 白色是未标记的内存
我们针对上述进行分析:
- 最左侧是根,黑色,已经被标记
- 上方为根的直接/间接引用对象,黑色,已经被标记
- 下方为根的直接/间接引用对象,灰色,正在标记,白色,还未被标记当后面会被标记
- 最右侧孤零零的白色方块,没有被引用,不会被标记,最后会被当作垃圾回收对象处理掉
这时我们就会发现一个问题:
- 如果最右侧的方块在针对自身的CPU的并发标记结束后,又被其他进程所调用了(并发标记其他CPU正常运行)
- 但是此时它是白色的,最终会被这次的垃圾回收操作清除掉,就会导致影响其他进程操作
所以我们设计了Remark重新标记操作:
- 如果在该方块针对自身的并发标记结束后又被其他进程调用,这时将他拖入一个队列中,并将其变为灰色
- 在并发标记结束后进入重新标记阶段,就会检查该队列,若发现灰色对象,在队列中将它变为黑色对象并排出队列
G1垃圾回收器重要更新
下面我们将会针对G1垃圾回收器在各个版本的重要更新做个介绍
JDK 8u20 字符串去重
我们首先要明白字符串在底层是采用char数组形成的:
String s1 = new String("hello"); // char[]{'h','e','l','l','o'}
String s2 = new String("hello"); // char[]{'h','e','l','l','o'}
如果重复的字符串都存放在内存中肯定会导致内存多余占用,所以提供了解决方案:
- 将所有新分配的字符串放入一个队列
- 当新生代回收时,G1并发检查是否有字符串重复
- 如果它们值一样,让它们引用同一个 char[]
- 注意与 String.intern() 不一样:一个底层针对String类型,一个底层针对char[]类型
其优缺点:
- 优点:节省大量内存
- 缺点:略微增多了CPU时间,新生代回收时间略微增多
JDK 8u40 并发标记类卸载
当所有的类都经过并发标记后,就会直到哪些类不再被使用
这时如果一个类加载器的所有类都不再使用时,我们就可以卸载它所加载的所有类
JDK 8u60 回收巨型对象
首先我们介绍一下巨型对象的定义:
一个对象大于 region 的一半时,称之为巨型对象
然后我们再来介绍G1对巨型对象的处理方法:
回收时被优先考虑
G1 不会对巨型对象进行拷贝
G1 会跟踪老年代所有 incoming 引用,这样老年代 incoming 引用为0 的巨型对象就可以在新生代垃圾回收时处理掉
垃圾回收调优
本小节将会介绍垃圾回收的调优机制
基本调优概念
我们进行调优需要掌握的基本知识:
- 掌握相关工具使用
- 掌握基本的空间调整
- 掌握GC相关的VM参数
- 明白调优并非固定公式,而是需要结合应用,环境
我们调优的领域并非只有垃圾回收,但是这个部分的调优确实会给项目带来很大的速率优化,此外还有其他方法的调优:
- IO调优
- 锁竞争调优
- CPU占用调优
此外我们需要确定调优的目标:
- 是为了保证低延迟还是为了保证高吞吐量
最快的GC是不发生GC
首先我们需要明白GC是花费时间的,如果我们能够控制好内存保证不发生GC,那么才是最快的
如果我们频繁发生GC操作,那么我们就需要先进行自我反思:
- 存放的数据是否过多?
/*
例如我们是否设置了相同元素筛选?错误账号禁止缓存?
*/
- 数据表示是否臃肿?
/*
例如我们调取数据时是否只调取了我们所需数据还是全盘托出?
例如我们选择数据类型时是否是以最低标准为要求,数据库能采用tiny不要使用int
*/
- 是否存在内存泄露?
/*
例如我们是否设置缓存数据时采用了Static形式的Map并不断存储数据?
*/
新生代调优
首先我们先来回顾一下新生代的优点:
- 所有的new操作的内存分配十分廉价:直接new出来存放在伊甸区即可
- 死亡对象的回收代价为零:我们直接采用复制将幸存内存复制出来即可,其他垃圾回收部分不用过问
- 大部分对象都是垃圾:我们实际上幸存下来的内存数据是小部分数据,所以大部分都是垃圾
- 垃圾回收时间相对短:Minor GC的时间远低于Full GC
那么我们该怎么进行调优呢:
- 最简单的方法就是适当扩大新生代空间即可
- 新生代不易太小:如果新生代过小就会导致不断发生minor GC浪费时间,且幸存区过小导致无用数据都存入老年代
- 新生代不易太大:如果新生代过大相对老年代空间变小,容易发生Full GC,Full GC的运行时间过长
那么官方认可的新生代大小为多少:
- 新生代能容纳所有[并发量*(请求-响应)]的数据
新生代幸存区调优
首先我们需要直到新生代幸存区存放的数据主要分为两部分:
- 当前活跃对象:并不应该晋级到老年代,只是目前阶段需要使用的内存数据
- 需要晋升对象:我们一直使用的内存数据,需要传递到老年代
首先我们需要保证具有一定的幸存区大小:
- 如果幸存区过小,就会导致幸存区数据提前进入到老年代
- 但如果是当前活跃对象进入到老年代,既不能发挥作用,并且也难以排出老年代
其次我们需要控制晋升标准:
- 设置一定规格的晋升标准,防止部分当前活跃对象进入到老年代,理由同上
老年代调优
最后我们介绍一下老年代调优,我们这里以CMS为例:
- 首先CMS老年代内存越大越好
- 其次在不做调优的情况下,如果没有发生Full GC就不需要调优了,否则优先调优新生代
- 如果经常发生Full GC,我们就需要将老年代空间增大了,官方推荐增大目前老年代空间大小的1/4~1/3即可
调优案例展示
最后我们介绍三个调优方法的案例:
- Full GC和Minor GC频繁
/*
主要是因为新生代空间不足
因为新生代空间不足,经常发生minor GC,同时幸存区空间不足导致大量数据直接进入到老年代,最后导致老年代也产生Full GC
*/
- 请求高峰期发生 Full GC,单次暂停时间特别长 (CMS)
/*
首先我们已经直到是CMS的垃圾回收方法
我们在之前的学习中得知Full GC主要分为三个阶段:初始标记,并发标记,重新标记
在请求高峰期期间,数据较多,我们的重新标记由于需要重新扫描所有数据空间,所以会导致单次暂停时间长
我们只需要保证在进行重新扫描前先进行一次Minor GC消除掉无用数据就可以加快暂停速度:-XX:+CMSScavengeBeforeRemark
*/
- 老年代充裕情况下,发生 Full GC (CMS jdk1.7)
/*
首先我们需要注意是jdk1.7版本
在1.7版本是由永久代负责管理方法区以及常量池,如果永久代内存满了也会产生Full GC
所以我们只需要增加永久代的内存大小即可
*/
结束语
到这里我们JVM的垃圾回收篇就结束了,希望能为你带来帮助~
附录
该文章属于学习内容,具体参考B站黑马程序员满老师的JVM完整教程
这里附上视频链接:01_垃圾回收概述_哔哩哔哩_bilibili
JVM学习笔记——垃圾回收篇的更多相关文章
- JVM学习笔记——内存模型篇
JVM学习笔记--内存模型篇 在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的内存模型部分 我们会分为以下几部分进行介绍: 内存模型 乐观锁与悲观锁 synchronized优化 内 ...
- Java进阶 JVM 内存与垃圾回收篇(一)
JVM 1. 引言 1.1 什么是JVM? 定义 Java Vritual Machine - java 程序的运行环境(Java二进制字节码的运行环境) 好处 一次编译 ,到处运行 自动内存管理,垃 ...
- JVM学习--(四)垃圾回收算法
我们都知道java语言与C语言最大的区别就是内存自动回收,那么JVM是怎么控制内存回收的,这篇文章将介绍JVM垃圾回收的几种算法,从而了解内存回收的基本原理. stop the world 在介绍垃圾 ...
- JVM学习记录-垃圾回收算法
简述 因为各个平台的虚拟机的垃圾收集器的实现各有不同,所以只介绍几个常见的垃圾收集算法. JVM中常见的垃圾收集算法有以下四种: 标记-清除算法(Mark-Sweep). 复制算法(Copying). ...
- JVM学习笔记(四)------内存调优【转】
转自:http://blog.csdn.net/cutesource/article/details/5907418 版权声明:本文为博主原创文章,未经博主允许不得转载. 首先需要注意的是在对JVM内 ...
- JVM学习笔记(四)------内存调优
首先需要注意的是在对JVM内存调优的时候不能只看操作系统级别Java进程所占用的内存,这个数值不能准确的反应堆内存的真实占用情况,因为GC过后这个值是不会变化的,因此内存调优的时候要更多地使用JDK提 ...
- jvm内存JVM学习笔记-引用(Reference)机制
在写这篇文章之前,xxx已经写过了几篇关于改jvm内存主题的文章,想要了解的朋友可以去翻一下之前的文章 如果你还不了解JVM的基本概念和内存划分,请阅读JVM学习笔记-基础知识和JVM学习笔记-内存处 ...
- 【转载】Java性能优化之JVM GC(垃圾回收机制)
文章来源:https://zhuanlan.zhihu.com/p/25539690 Java的性能优化,整理出一篇文章,供以后温故知新. JVM GC(垃圾回收机制) 在学习Java GC 之前,我 ...
- Java性能优化之JVM GC(垃圾回收机制)
Java的性能优化,整理出一篇文章,供以后温故知新. JVM GC(垃圾回收机制) 在学习Java GC 之前,我们需要记住一个单词:stop-the-world .它会在任何一种GC算法中发生.st ...
随机推荐
- i40e网卡驱动遇到的一个问题
最近在排查一个crash文件的时候,遇到一个堆栈,即软中断收包的时候,skb的关联的dev是null,导致oops, 然后去crash分析的时候,发现skb的dev去不是null. 从oops到cra ...
- 内网渗透之vlunstack靶场
前言:vlunstack靶场是由三台虚拟机构成,一台是有外网ip的windows7系统(nat模式),另外两台是纯内网机器(外网ping不通),分别是域控win2008和内网主机win2003,这里就 ...
- 「CCO 2017」专业网络
Kevin 正在一个社区中开发他的专业网络.不幸的是,他是个外地人,还不认识社区中的任何人.但是他可以与 N 个人建立朋友关系 . 然而,社区里没几个人想与一个外地人交朋友.Kevin 想交朋友的 N ...
- Windows批量修改文件
如图我是建立了壁纸文件夹 Windows自带的排序方式 如何不用自带的呢? 在这个文件夹里面建一个.txt文件 如下 ok第二步骤 将UTF-8格式改为ANSI格式 点击文件-另存为ANSI格式-替换 ...
- OpenDrop 这样的应用程序以及与当今流行的替代品的比较
由安全移动网络实验室 OpenDrop 创建的用 Python 编写的开放 Apple AirDrop 实现是一个命令行工具,允许直接通过 Wi-Fi 在设备之间共享文件.它的独特之处在于它与 App ...
- Shell第四章《正则表达式》
一.前言 1.1.名词解释 正则表达式(regular expression, RE)是一种字符模式,用于在查找过程中匹配指定的字符.在大多数程序里,正则表达式都被置于两个正斜杠之间:例如/l[oO] ...
- fastadmin后台分页设置显示方法
1.参照日志列表的分页(后台代码都有) 2.修改默认分页配置,在初始化里面加上: pageList: [5,10,'all'], 3.显示列表: [$where, $sort, $order, $ ...
- Java开发学习(三十五)----SpringBoot快速入门及起步依赖解析
一.SpringBoot简介 SpringBoot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化 Spring 应用的初始搭建以及开发过程. 使用了 Spring 框架后已经简化了我 ...
- 发布日志- kratos v2.1.4 发布!
v2.1.4 release https://github.com/go-kratos/kratos/releases/tag/v2.1.4 New Features feat(registry/co ...
- CentOS7下的lvm(逻辑卷)在线扩容
扩展前该lvm分区为14GB 关闭系统,给sdb硬盘扩展6GB,然后重新进入CentOS.(或者是原有磁盘还有剩余未使用的空间) 对sdb进行分区: [root@converter ~]# fdisk ...