for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
cat > /etc/docker/daemon.json <<eof< div="">
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
}
}
EOF
#使用Systemd管理的Cgroup来进行资源控制与管理,因为相对Cgroupfs而言,Systemd限制CPU、内存等资源更加简单和成熟稳定。
#日志使用json-file格式类型存储,大小为100M,保存在/var/log/containers目录下,方便ELK等日志系统收集和管理日志。
systemctl daemon-reload
systemctl restart docker.service
systemctl enable docker.service
docker info | grep "Cgroup Driver"
Cgroup Driver: systemd
所有节点安装kubeadm,kubelet和kubectl
//定义kubernetes源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
enabled=1
gpgcheck=0
repo_gpgcheck=0
EOF
yum install -y kubelet-1.20.11 kubeadm-1.20.11 kubectl-1.20.11
//开机自启kubelet
systemctl enable kubelet.service
#K8S通过kubeadm安装出来以后都是以Pod方式存在,即底层是以容器方式运行,所以kubelet必须设置开机自启
部署K8S集群
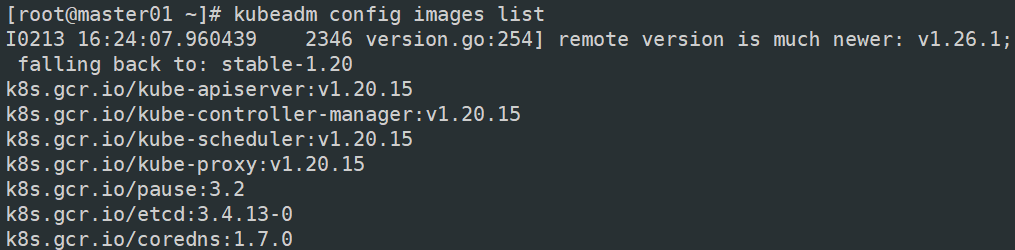
//查看初始化需要的镜像
kubeadm config images list
//在 master 节点上传 v1.20.11.zip 压缩包至 /opt 目录
unzip v1.20.11.zip -d /opt/k8s
cd /opt/k8s/v1.20.11
for i in $(ls *.tar); do docker load -i $i; done
//复制镜像和脚本到 node 节点,并在 node 节点上执行脚本加载镜像文件
scp -r /opt/k8s root@node01:/opt
cd /opt/k8s/v1.20.11
for i in $(ls *.tar); do docker load -i $i; done
scp -r /opt/k8s root@node02:/opt
cd /opt/k8s/v1.20.11
for i in $(ls *.tar); do docker load -i $i; done
//初始化kubeadm(master)
kubeadm config print init-defaults > /opt/kubeadm-config.yaml
12 advertiseAddress: 192.168.63.100 #指定master节点的IP地址
34 kubernetesVersion: v1.20.11 #指定kubernetes版本号
36 dnsDomain: cluster.local
37 podSubnet: "10.244.0.0/16" #指定pod网段,10.244.0.0/16用于匹配flannel默认网段
38 serviceSubnet: 10.96.0.0/16 #指定service网段
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs #把默认的kube-proxy调度方式改为ipvs模式
kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log
#--experimental-upload-certs 参数可以在后续执行加入节点时自动分发证书文件,K8S V1.16版本开始替换为 --upload-certs
#tee kubeadm-init.log 用以输出日志
方法二: kubeadm init --apiserver-advertise-address=192.168.63.100 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.20.11 --service-cidr=10.96.0.0/16 --pod-network-cidr=10.244.0.0/16 --token-ttl=0
初始化集群需使用kubeadm init命令,可以指定具体参数初始化,也可以指定配置文件初始化。 可选参数: --apiserver-advertise-address:apiserver通告给其他组件的IP地址,一般应该为Master节点的用于集群内部通信的IP地址,0.0.0.0表示节点上所有可用地址 --apiserver-bind-port:apiserver的监听端口,默认是6443 --cert-dir:通讯的ssl证书文件,默认/etc/kubernetes/pki --control-plane-endpoint:控制台平面的共享终端,可以是负载均衡的ip地址或者dns域名,高可用集群时需要添加 --image-repository:拉取镜像的镜像仓库,默认是k8s.gcr.io --kubernetes-version:指定kubernetes版本 --pod-network-cidr:pod资源的网段,需与pod网络插件的值设置一致。Flannel网络插件的默认为10.244.0.0/16,Calico插件的默认值为192.168.0.0/16; --service-cidr:service资源的网段 --service-dns-domain:service全域名的后缀,默认是cluster.local --token-ttl:默认token的有效期为24小时,如果不想过期,可以加上 --token-ttl=0 这个参数
方法二初始化后需要修改 kube-proxy 的 configmap,开启 ipvs
输入:
kubectl edit cm kube-proxy -n=kube-system
并且修改mode: ipvs
提示:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.63.100:6443 --token wfjo7j.baa0aheyw39w3m7h
--discovery-token-ca-cert-hash sha256:77100ff66b20100cbd9f1c289788e43aee69c5b4e24cc2c74c2e5d634a074fdc
把显示出来的
分别复制到node01和node02
//设定kubectl
kubectl需经由API server认证及授权后方能执行相应的管理操作,kubeadm 部署的集群为其生成了一个具有管理员权限的认证配置文件 /etc/kubernetes/admin.conf,它可由 kubectl 通过默认的 “$HOME/.kube/config” 的路径进行加载。
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
//如果 kubectl get cs 发现集群不健康,更改以下两个文件(master)
vim /etc/kubernetes/manifests/kube-scheduler.yaml
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
修改如下内容
把--bind-address=127.0.0.1变成--bind-address=192.168.63.100 #修改成k8s的控制节点master01的ip
把httpGet:字段下的hosts由127.0.0.1变成192.168.63.100(有两处)
#- --port=0 # 搜索port=0,把这一行注释掉
systemctl restart kubelet
//所有节点部署网络插件flannel
方法一:
//所有节点上传flannel镜像 flannel.tar 到 /opt 目录,master节点上传 kube-flannel.yml 文件
cd /opt
docker load < flannel.tar
//在 master 节点创建 flannel 资源
kubectl apply -f kube-flannel.yml
如果出现这些问题
是cni(插件)有问题
kubectl describe pod -n kube-system
node1:
cd /opt
mv cni{,.cni.bak}
把cni-plugins-linux-amd64-v0.8.6.tgz放到/opt
mkdir cni/bin -p
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin/
到master
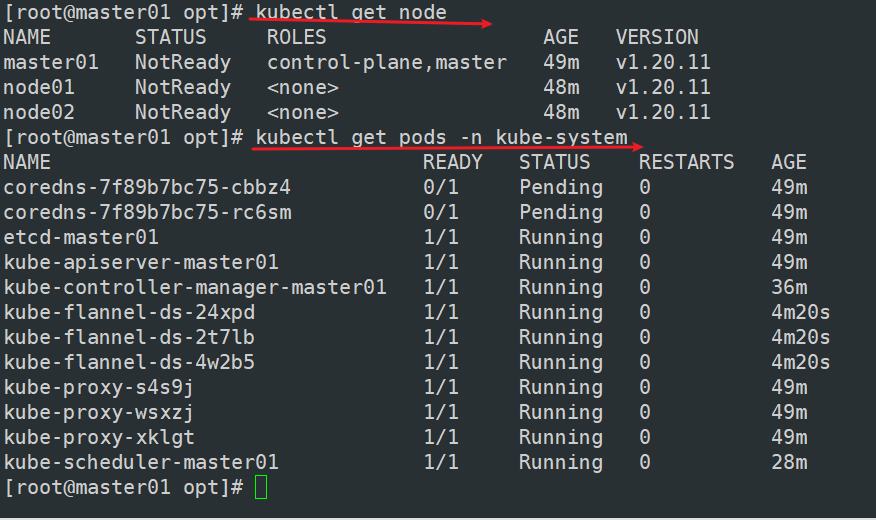
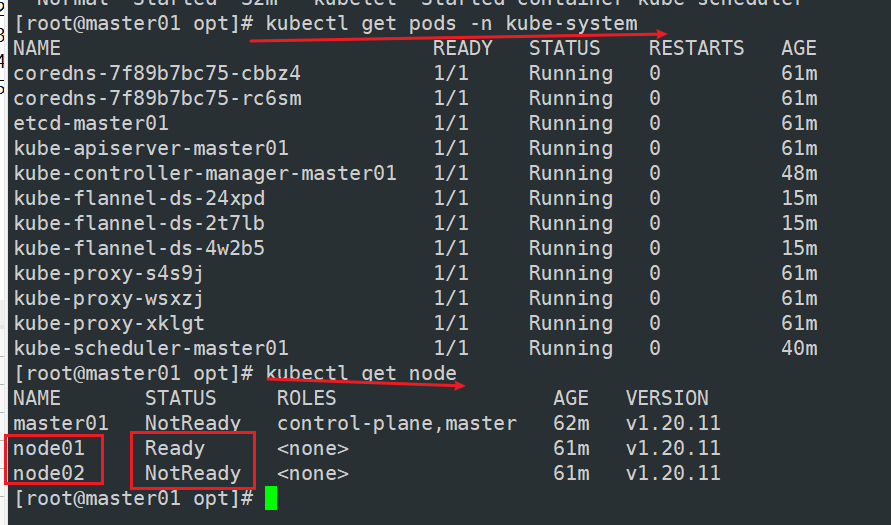
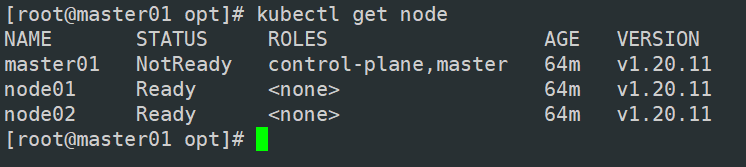
kubectl get pods -n kube-system
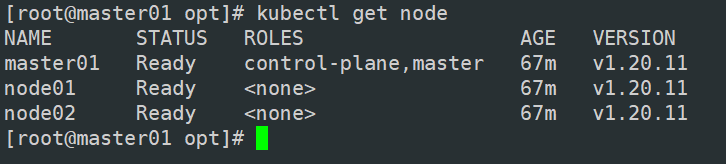
kubectl get node
可以看到node02没有ready,因此还得到node02做
node02:
cd /opt
mv cni{,.cni.bak}
到node01:
cd /opt
scp -r cni root@node02:/opt/
然后master01也要做这个动作
mater01:
cd /opt
mv cni{,.cni.bak}
到node01:
cd /opt
scp -r cni root@node02:/opt/
//在 node 节点上执行 kubeadm join 命令加入群集
kubeadm join 192.168.10.19:6443 --token rc0kfs.a1sfe3gl4dvopck5
--discovery-token-ca-cert-hash sha256:864fe553c812df2af262b406b707db68b0fd450dc08b34efb73dd5a4771d37a2
kubectl get pods -n kube-system ##为什么有3个flannel,因为3台机器
NAME READY STATUS RESTARTS AGE
coredns-bccdc95cf-c9w6l 1/1 Running 0 71m
coredns-bccdc95cf-nql5j 1/1 Running 0 71m
etcd-master 1/1 Running 0 71m
kube-apiserver-master 1/1 Running 0 70m
kube-controller-manager-master 1/1 Running 0 70m
kube-flannel-ds-amd64-kfhwf 1/1 Running 0 2m53s
kube-flannel-ds-amd64-qkdfh 1/1 Running 0 46m
kube-flannel-ds-amd64-vffxv 1/1 Running 0 2m56s
kube-proxy-558p8 1/1 Running 0 2m53s
kube-proxy-nwd7g 1/1 Running 0 2m56s
kube-proxy-qpz8t 1/1 Running 0 71m
kube-scheduler-master 1/1 Running 0 70m
//测试 pod 资源创建
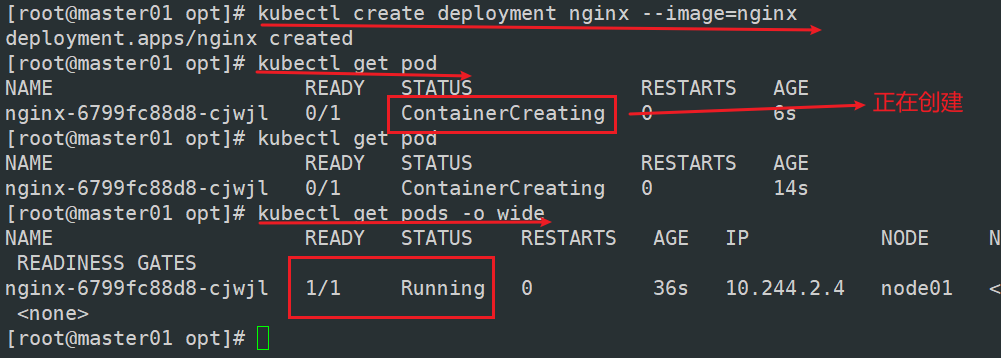
kubectl create deployment nginx --image=nginx
kubectl get pods -o wide
//暴露端口提供服务
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 3h57m
myapp-ky20 NodePort 10.96.180.95 80:30585/TCP 3s ##30585是对外的 CLUSTER-IP中的10.96.180.95是server
//测试访问
//扩展3个副本
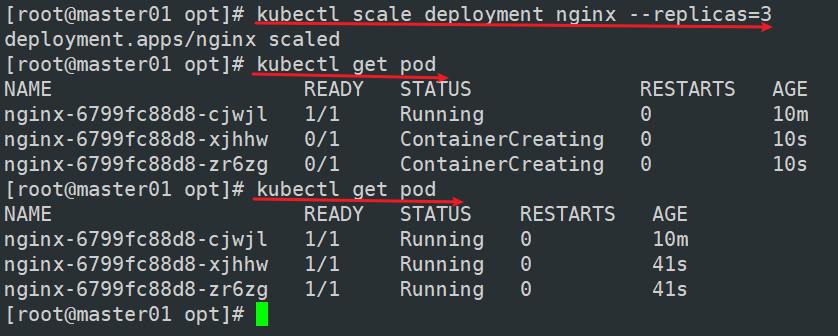
kubectl scale deployment nginx --replicas=3
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-554b9c67f9-9kh4s 1/1 Running 0 66s 10.244.1.3 node01
nginx-554b9c67f9-rv77q 1/1 Running 0 66s 10.244.2.2 node02
nginx-554b9c67f9-zr2xs 1/1 Running 0 17m 10.244.1.2 node01
部署 Dashboard
//在 master01 节点上操作
#上传 recommended.yaml 文件到 /opt/k8s 目录中
cd /opt/k8s
vim recommended.yaml
#默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 30001 #添加
type: NodePort #添加
selector:
k8s-app: kubernetes-dashboard
kubectl apply -f recommended.yaml
#创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
复制token
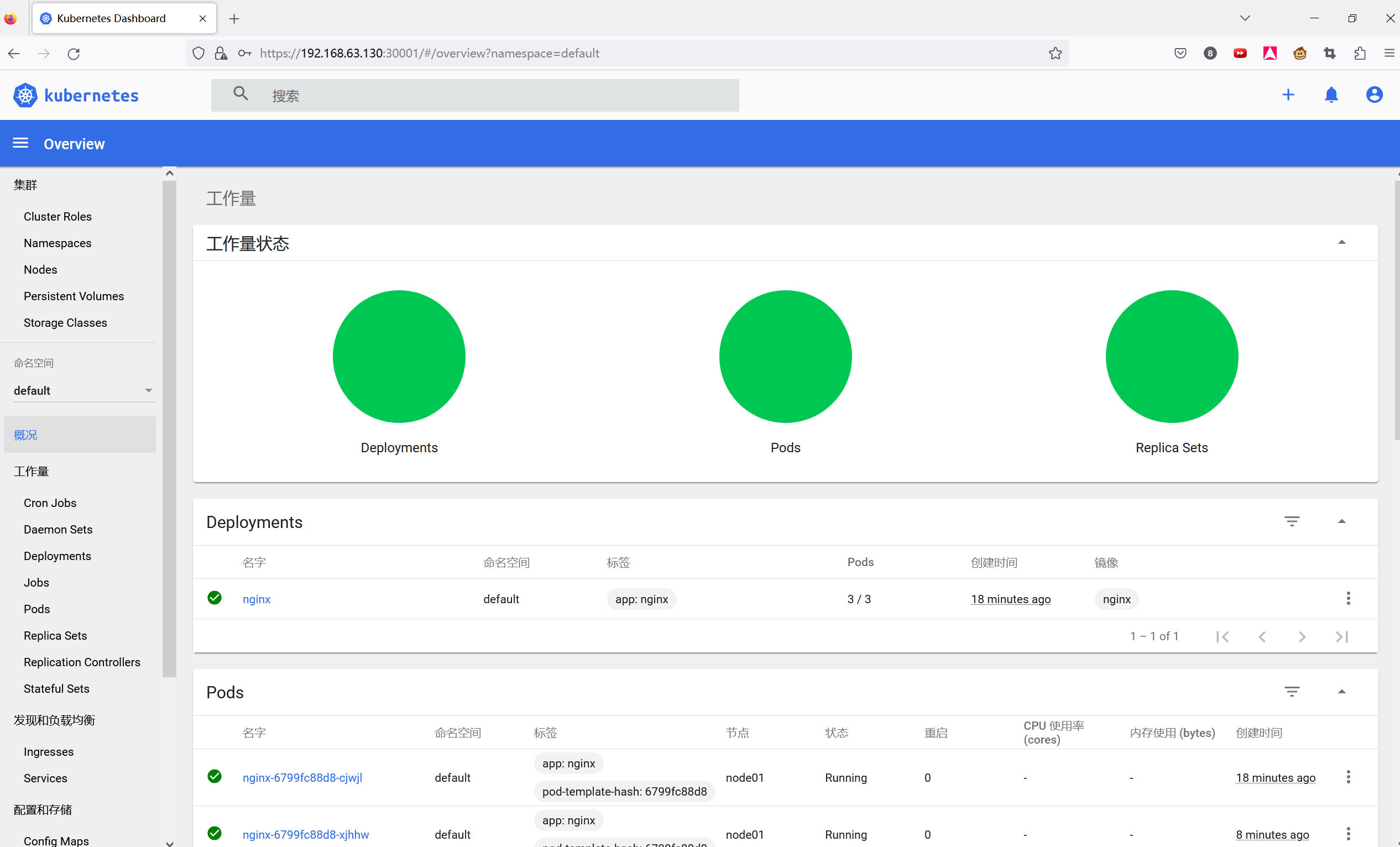
#使用输出的token登录Dashboard
安装Harbor私有仓库
//修改主机名
hostnamectl set-hostname hub.kgc.com
//所有节点加上主机名映射
echo '192.168.63.160 hub.kgc.com' >> /etc/hosts
//安装 docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum install -y docker-ce docker-ce-cli containerd.io
mkdir /etc/docker
cat > /etc/docker/daemon.json <<eof< div="">
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
}
EOF
systemctl start docker
systemctl enable docker
//所有 node 节点都修改 docker 配置文件,加上私有仓库配置
cat > /etc/docker/daemon.json <<eof< div="">
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
}
EOF
systemctl daemon-reload
systemctl restart docker
//安装 Harbor
//上传 harbor-offline-installer-v1.2.2.tgz 和 docker-compose 文件到 /opt 目录(harbor)
cd /opt
cp docker-compose /usr/local/bin/
chmod +x /usr/local/bin/docker-compose
tar zxvf harbor-offline-installer-v1.2.2.tgz
cd harbor/
vim harbor.cfg
5 hostname = hub.kgc.com
9 ui_url_protocol = https
24 ssl_cert = /data/cert/server.crt
25 ssl_cert_key = /data/cert/server.key
59 harbor_admin_password = Harbor12345
//生成证书
mkdir -p /data/cert
cd /data/cert
#生成私钥
openssl genrsa -des3 -out server.key 2048
输入两遍密码:123456
#生成证书签名请求文件
openssl req -new -key server.key -out server.csr
输入私钥密码:123456
输入国家名:CN
输入省名:BJ
输入市名:BJ
输入组织名:KGC
输入机构名:KGC
输入域名:hub.kgc.com
输入管理员邮箱:admin@kgc.com
其它全部直接回车
#备份私钥
cp server.key server.key.org
#清除私钥密码
openssl rsa -in server.key.org -out server.key
输入私钥密码:123456
#签名证书
openssl x509 -req -days 1000 -in server.csr -signkey server.key -out server.crt
chmod +x /data/cert/*
cd /opt/harbor/
./install.sh
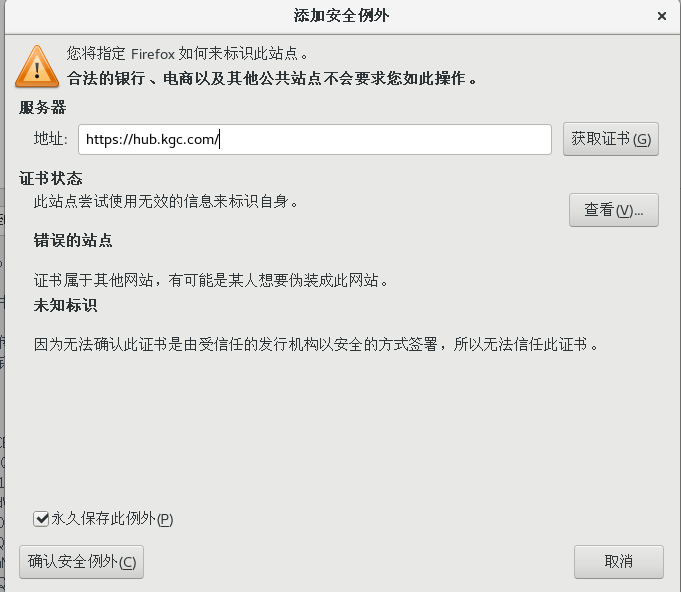
添加例外 -> 确认安全例外
用户名:admin
密码:Harbor12345
//在一个node节点上登录harbor
//上传镜像
docker tag nginx:latest hub.kgc.com/library/nginx:v1
docker push hub.kgc.com/library/nginx:v1
//在master节点上删除之前创建的nginx资源
kubectl delete deployment nginx
kubectl create deployment nginx-deployment --image=hub.kgc.com/library/nginx:v1 --port=80 --replicas=3
kubectl expose deployment nginx-deployment --port=30000 --target-port=80 ##暴露端口
kubectl get svc,pods
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 443/TCP 10m
service/nginx-deployment ClusterIP 10.96.219.157 30000/TCP 3m15s
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-77bcbfbfdc-bv5bz 1/1 Running 0 16s
pod/nginx-deployment-77bcbfbfdc-fq8wr 1/1 Running 0 16s
pod/nginx-deployment-77bcbfbfdc-xrg45 1/1 Running 0 3m39s
master:
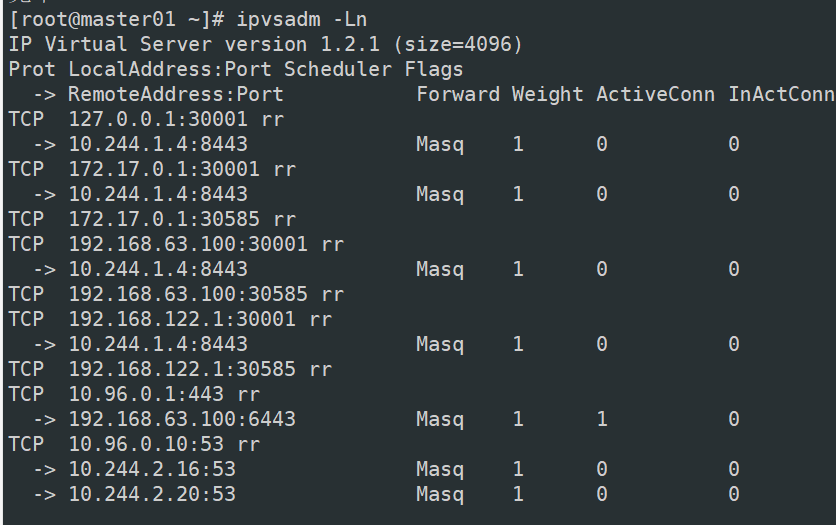
yum install ipvsadm -y
ipvsadm -Ln
//如果没东西,需要修改 kube-proxy 的 configmap,开启 ipvs
kubectl edit cm kube-proxy -n=kube-system
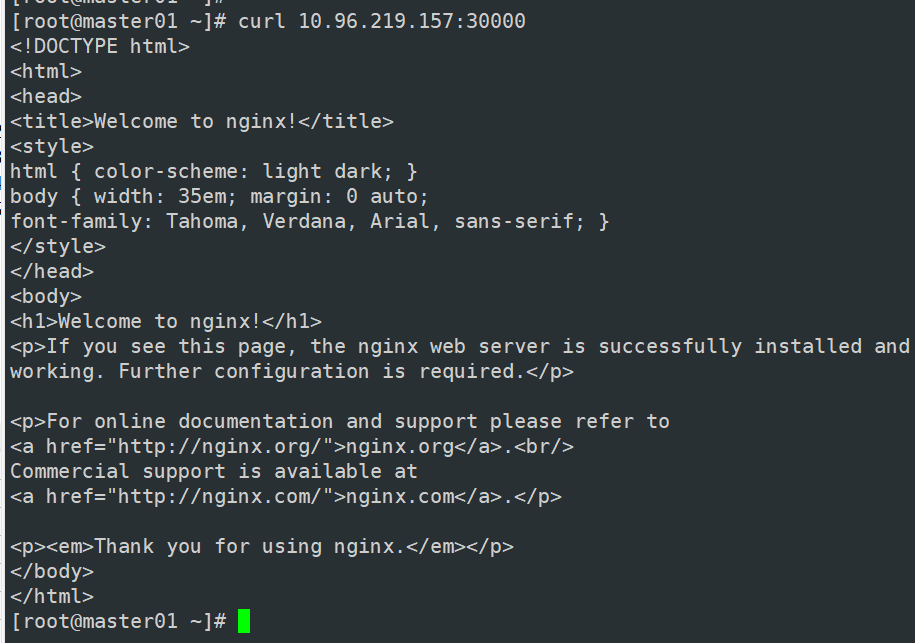
curl 10.96.219.157:30000
kubectl edit svc nginx-deployment
25 type: NodePort #把调度策略改成NodePort
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 443/TCP 29m
service/nginx-deployment NodePort 10.96.222.161 30000:30173/TCP 22m
浏览器访问:
192.168.63.100:30173
192.168.63.130:30173
192.168.63.150:30173
#将cluster-admin角色权限授予用户system:anonymous
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
内核参数优化方案
cat > /etc/sysctl.d/kubernetes.conf <<eof< div="">
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 #禁止使用 swap 空间,只有当系统内存不足(OOM)时才允许使用它
vm.overcommit_memory=1 #不检查物理内存是否够用
vm.panic_on_oom=0 #开启 OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963 #指定最大文件句柄数
fs.nr_open=52706963 #仅4.4以上版本支持
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF