文本分类学习 (八)SVM 入门之线性分类器
SVM 和线性分类器是分不开的。因为SVM的核心:高维空间中,在线性可分(如果线性不可分那么就使用核函数转换为更高维从而变的线性可分)的数据集中寻找一个最优的超平面将数据集分隔开来。
所以要理解SVM首先要明白的就是线性可分和线性分类器。
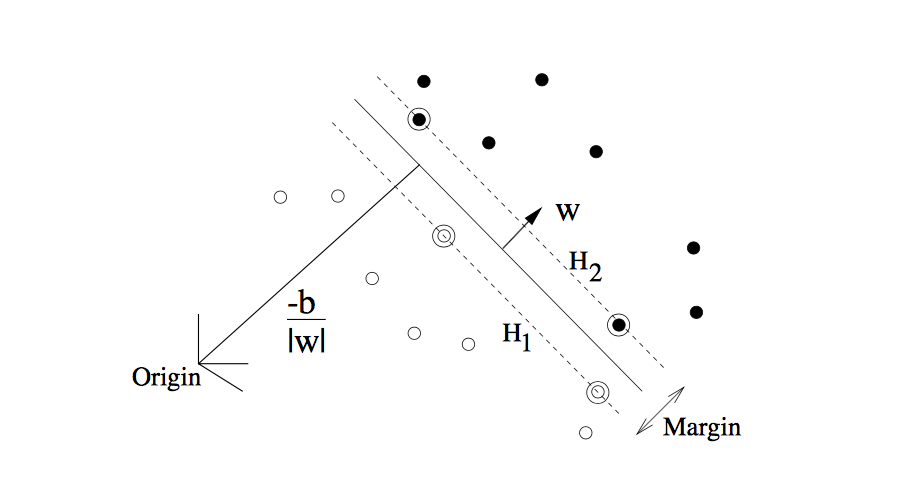
可以先解释这张图,通过这张图就可以了解线性分类器了。
这是一个在二维平面的图。其中实心点和空心点是分别属于两类的,Origin 是原点。
先看中间那条直线,中间的直线就是一条可以实心点和空心点分隔开来的直线,所以上图中的数据点是线性可分的。
这条直线其实就是线性分类器,也可以叫做分类函数,在直线上方的属于+1类,在直线下方的属于-1类。+1,-1这里只是区分类别。
所以该直线就是我们上面说的超平面,在二维空间中它是一条直线,三维空间是一个平面。。。等等,下面就统称为超平面
这个超平面上的点都满足
 (1)
(1)
这里需要解释一下:
- x 在二维平面中不是指横坐标值,而是指二维平面中点的向量,在文本分类中就是文本的向量表示。所以 x = ( xi , yi )
- w 也是一个向量 它是一个垂直于超平面的向量,如图中所示
- 该表达式不只是表示二维空间,也可以表示n维空间的超平面
- b 是一个常数
- w * x 是求两个向量的点积也就是内积,实际上应该写成w * xT w乘以x的转置向量,w是横向量,x是列向量。
所以二维平面中,该表达式也可以表示为:
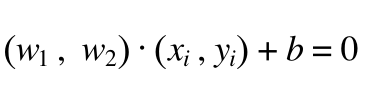 (2)
(2)
继续上图的解释,其中原点到超平面的距离为

这个可以很容易推导出来,以二维平面为例,上述表达式可以这么转换

根据点到直线的距离公式:
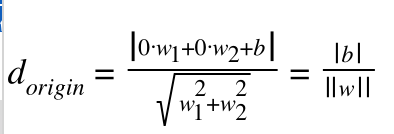 (3)
(3)
计算这个公式是为了方便我们下面计算得到几何间隔。
这里 || w || 叫做 向量 w 的 欧几里得范式,p维的向量w的范式:
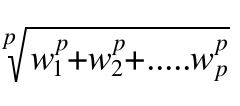
实际上是对向量长度的一种度量。
以上是在线性分类器中的一些要素:包括n维空间中的一些个点,和把这些点分开的一个超平面
下面是在SVM中对线性分类器不同的地方,在SVM中我们还要找到以下两条直线H1, H2 (上图已经是线性可分的最优分类线)
H1 和 H2 它们平行于超平面,在H1 上的点满足:
 (4)
(4)
在H2 上的点满足:
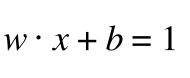 (5)
(5)
所以在图中我们可以看到空心点 都满足
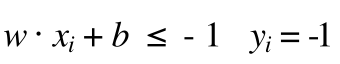 (6)
(6)
实心点都满足
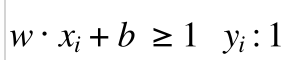 (7)
(7)
所以我们可以把上面连个式子写成一个不等式:
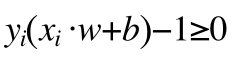 (8)
(8)
这个不等式就是图中所有数据点要满足的条件,也是最优分类函数求出来的条件。
这里还要提醒一下,xi 不是横坐标而是一个n维向量,yi 不是纵坐标而是一个分类标签,只有+1 和 -1。
上面计算过原点到超平面的距离,以此类推,H1 到原点的距离 = |-1-b| / || w || ; H2 到原点的距离 = | 1 - b | / || w ||
那么H1 到超平面的距离就是 | b| / || w || - |-1-b| / || w || = 1 / ||w|| 同理H2到超平面的距离也是 1/ ||w||
H1 和H2 之间的距离为:2 / ||w|| 。这个距离称作为几何间隔。
SVM 的工作是在n维空间中找到这两个超平面:H1 和H2 使得点都分布在H1 和H2 的两侧,并且使H1 和H2 之间的几何间隔最大,这是H1 和H2 就是支持向量
为什么呢?因为几何间隔与样本的误分次数间存在关系, 几何间隔越大误分次数的上界就越小。
这个1/||w|| 也可以通过上面的不等式(8)推导出来,把不等式(8)左边和右边同时除以 || w ||
就可以得到:
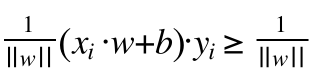 (9)
(9)
根据(6),(7)实际上yi 只是一个正负号,相当于取绝对值,因为wxi+b<=-1的时候yi就是-1,结果还是正数,所以(9)可以变成:
 (10)
(10)
不等式左边表示的就是点到超平面wx+b=0的距离,该式子表示,所有点到超平面wx+b=0的距离都大于1/||w|| 。从图中看也正是如此。

所以我们接下来的工作就是最大化几何间隔,事实上也就是求||w||的最小值。
文本分类学习 (八)SVM 入门之线性分类器的更多相关文章
- 文本分类学习 (十)构造机器学习Libsvm 的C# wrapper(调用c/c++动态链接库)
前言: 对于SVM的了解,看前辈写的博客加上读论文对于SVM的皮毛知识总算有点了解,比如线性分类器,和求凸二次规划中用到的高等数学知识.然而SVM最核心的地方应该在于核函数和求关于α函数的极值的方法: ...
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
- 文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言: 经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的.于是开始逐一的去了解SVM的原理. SVM 是在建立在结构风险最小化和VC维理论的基础上.所以这篇只介绍关于 ...
- 文本分类学习(六) AdaBoost和SVM
直接从特征提取,跳到了BoostSVM,是因为自己一直在写程序,分析垃圾文本,和思考文本分类用于识别垃圾文本的短处.自己学习文本分类就是为了识别垃圾文本. 中间的博客待自己研究透彻后再补上吧. 因为获 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- SVM中的线性分类器
线性分类器: 首先给出一个非常非常简单的分类问题(线性可分),我们要用一条直线,将下图中黑色的点和白色的点分开,很显然,图上的这条直线就是我们要求的直线之一(可以有无数条这样的直线) 假如说, ...
- 文本分类学习 (九)SVM入门之拉格朗日和KKT条件
上一篇说到SVM需要求出一个最小的||w|| 以得到最大的几何间隔. 求一个最小的||w|| 我们通常使用 来代替||w||,我们去求解 ||w||2 的最小值.然后在这里我们还忽略了一个条件,那就是 ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- cs231n笔记:线性分类器
cs231n线性分类器学习笔记,非完全翻译,根据自己的学习情况总结出的内容: 线性分类 本节介绍线性分类器,该方法可以自然延伸到神经网络和卷积神经网络中,这类方法主要有两部分组成,一个是评分函数(sc ...
随机推荐
- 〖Linux〗Kubuntu 14.04的Eclipse 崩溃解决方法总结
1. 普通崩溃问题: eclipse/configuration/config.ini在后边添加 org.eclipse.swt.browser.DefaultType=mozilla 2. Kubu ...
- Mybatis3——使用学习(一)
目录 Mybatis Mybatis参考资源 Mybatis 使用 肯定TM要跑起来 XML映射配置文件 Mapper XML 文件 Mybatis Mybatis参考资源 Mybatis官网手册:h ...
- Effective Java 第三版——51. 仔细设计方法签名
Tips 书中的源代码地址:https://github.com/jbloch/effective-java-3e-source-code 注意,书中的有些代码里方法是基于Java 9 API中的,所 ...
- SNF快速开发平台3.0之BS页面展示和九大优点-部分页面显示效果-Asp.net+MVC4.0+WebAPI+EasyUI+Knockout
一)经过多年的实践不断优化.精心维护.运行稳定.功能完善: 能经得起不同实施策略下客户的折腾,能满足各种情况下客户的复杂需求. 二)编码实现简单易懂.符合设计模式等理念: 上手快,见效快.方便维护,能 ...
- 第一部分:开发前的准备-第一章 什么是Andorid
第1章 什么是Android Android是一个移动设备的软件栈,它包含操作系统,中间件和一些关键的应用.Android SDK提供工具和必要的API用来在Android平台上使用java程序语言来 ...
- 运行第一个Docker容器-Docker for Web Developers(1)
1. Docker介绍 Docker由dotCloud公司发起的一个内部项目,后来Docker火了,dotCloud公司改名为Docker了: Docker使用了Go语言开发,基于 Linux 内核的 ...
- python 函数的参数的几种类型
定义函数的时候,我们把参数的名字和位置确定下来,函数的接口定义就完成了.对于函数的调用者来说,只需要知道如何传递正确的参数,以及函数将返回什么样的值就够了,函数内部的复杂逻辑被封装起来,调用者无需了解 ...
- OAuth 2.0 C# 版
using System; using System.Collections.Generic; using System.Dynamic; using System.Linq; using Syste ...
- Mysql 导入导出csv 中文乱码
这篇文章介绍了Mysql 导入导出csv 中文乱码问题的解决方法,有需要的朋友可以参考一下 导入csv: load data infile '/test.csv' into table table ...
- linux 如何快速的查找日志中你所要查找的信息
在工作中我总会通过日志来查找相关问题,但有时候日志太多有不知道又不知道日志什么时候打印的,这时我们可以通过一下方法来查找: 1.把目录跳到你日志文件存放的地方 2.grep 关键字 * 例如 ...