虚拟机搭建和安装Hadoop及启动
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动
马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动
(一) 需要用到的软件
virtualbox redhat64(centos7) hadoop-2.7.3.jar jdk8 xshell ftp(我用的是FlashFXP)
所需要的软件,最好到官网上去下载,也可以到百度云盘下载:http://pan.baidu.com/s/1nvkDLbV
(二)安装配置虚拟机
将virualbox安装好后,需要新建一个linux版redhat64的虚拟机,我取名叫master;
特别需要注意的地方:
将虚拟机的网络设置为host-only,我因为忘了设置成host-only,导致新建的虚拟机和宿主机怎么都ping不通,浪费了我一些时间。
选中虚拟机-->设置-->网络,设置如下:

虚拟机网络设置
a) 在设置虚拟机网络前,先设置宿主机的VirtualBox Host-Only Network,
打开网络共享中心-->更改适配器设置,然后设置IP和子网掩码
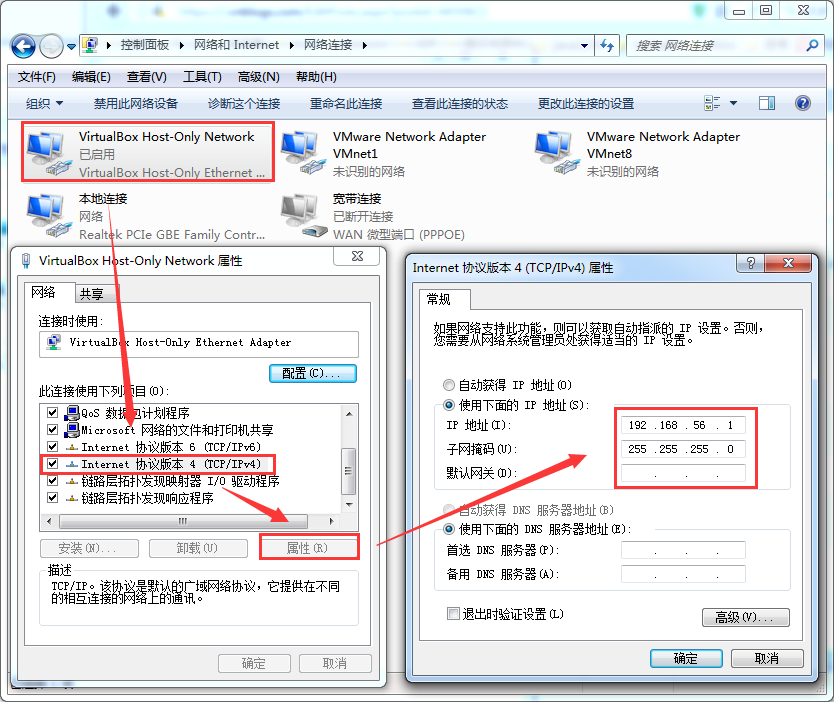
b) 设置虚拟机GATEWAY为192.168.56.1
[root@master ~]# vi /etc/sysconfig/network
#编辑内容如下
NETWORKING=yes
GATEWAY=192.168.56.1
c) 设置虚拟机IP和子网掩码
[root@master ~]# vim /etc/sysconfig/network-sripts/ifcfg-enp0s3 #编辑内容如下
TYPE=Ethernet
IPADDR=192.168.56.100
NETMASK=255.255.255.0
d) 修改master主机名
主机名千万不能有下划线【马老师一再强调】
[root@master ~]# hostnamectl set-hostname master
e) 重启master虚拟机网络
[root@master ~]# service network restart
f) 在虚拟机上ping宿主机,在宿主机上ping虚拟机master
[root@master ~]# ping 192.168.56.1
PING 192.168.56.1 (192.168.56.1) 56(84) bytes of data.
64 bytes from 192.168.56.1: icmp_seq=1 ttl=128 time=0.191 ms
64 bytes from 192.168.56.1: icmp_seq=2 ttl=128 time=0.203 ms
C:\Users\Administrator>ping 192.168.56.100 正在 Ping 192.168.56.100 具有 32 字节的数据:
来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.56.100 的回复: 字节=32 时间<1ms TTL=64
互相ping,测试成功,若不成功,注意防火墙的影响,关闭windows或虚拟机防火墙。
systemctl stop firewalld.service
systemctl disable firewalld.service
更多防火墙操作:<a href='https://www.cnblogs.com/yucongblog/p/9722414.html'>Centos7下防火墙操作</a>
(3)安装jdk
将已下载好的jdk-8u91-linux-x64.rpm和hadoop-2.7.3.tar.gz,
通过FlashFXP工具(也可以是其他的ftp工具)上传上去,
用xshell连接master虚拟机。
使用rpm进行安装jdk:

默认安装在 /usr/java下面,执行java看到如下输入,即表示java安装成功:

(4)安装hadoop
tar -xvf hadoop-2.7.3.tar.gz
并将解压后的文件hadoop-2.7.3修改成hadoop,执行mv hadoop-2.7.3 hadoop
(5) 配置hadoop的JAVA_HOME
vim /usr/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/default
(6) 配置hadoop的环境变量
vim /etc/profile
在profile文件尾部添加内容如下:
export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin
要想使profile文件生效,还要执行指令
[root@master ~]# source /etc/profile
(7)修改master的/usr/local/hadoop/etc/hadoop/core-site.xml,指明namenode的信息
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
这里需要指明一下,core-site.xml里面的配置需要复制到slave虚拟机上,由于采用的是步骤(9)虚拟机复制,这个信息也已经复制过去了。
(8) 测试hadoop命令是否可以直接执行
任意目录下敲 hadoop,打印如下,表示hadoop的环境变量配置成功

(9) 复制3台虚拟机
关闭master,选中master-->右键-->复制,分别复制出取名为slave1,slave2,slave3的3台虚拟机。

使用无界面启动方式启动4台虚拟机
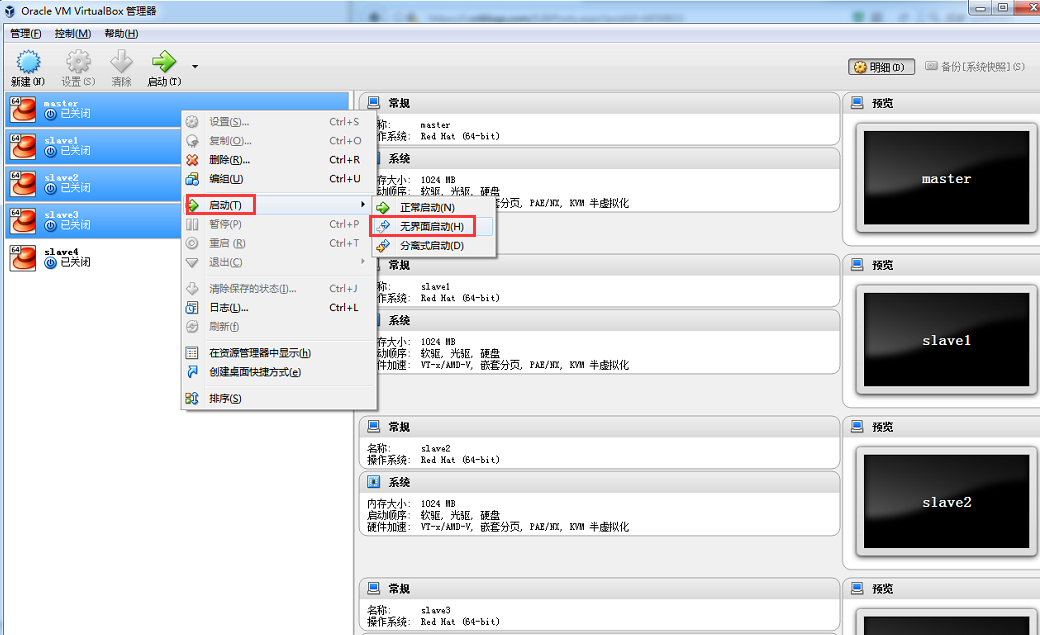
然后,使用以上步骤(2)中的虚拟机网络配置(b)(c)(d)(e)(f)操作slave1,slave2,slave3,
slave1 设置为IP:192.168.56.101,hostname:slave1
slave1 设置为IP:192.168.56.102,hostname:slave2
slave1 设置为IP:192.168.56.103,hostname:slave3
使用xshell依次登陆上maser,slave1,slave2,slave3四台虚拟机。
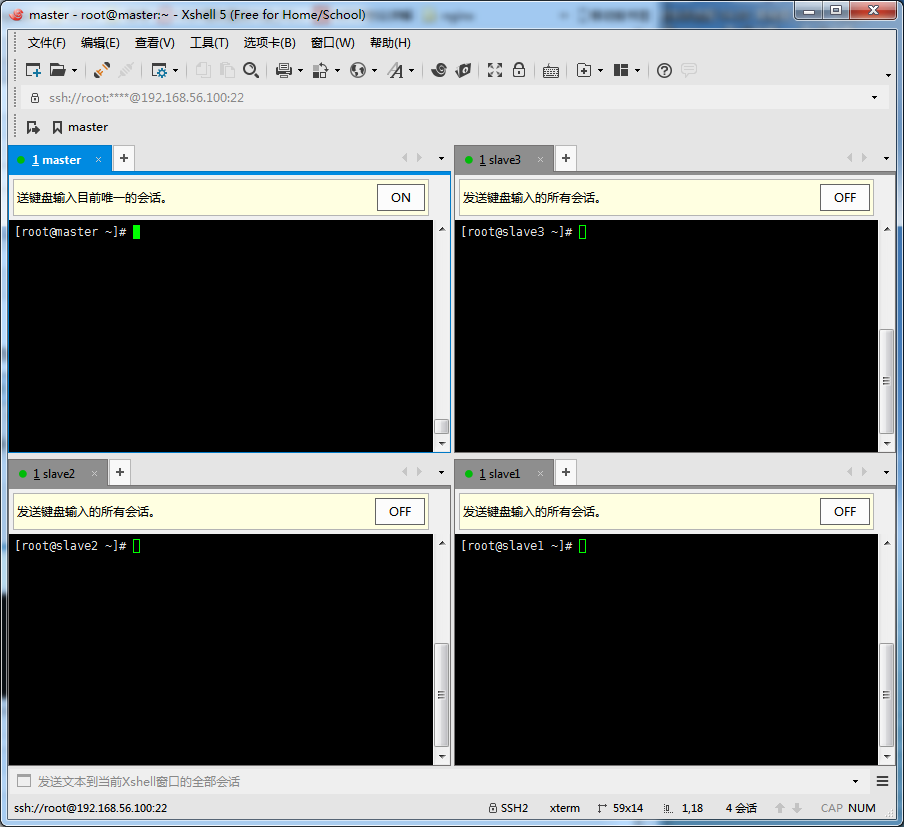
要想达到以上截图中的效果,操作:工具-->发送键输入到所有会话;选项卡-->排列-->瓷砖排序。
(10)搭建集群
在hadoop中,
跑在master机器上的组件/模块/进程有:
namenode,secondarynamenode,resource manager(job tracker),history sever,
跑在slave机器上的有:
datanode,node manager(task tracker)

a) 修改4台机器的/etc/hosts,让他们通过名字认识对方,测试一下互相用名字可以ping通。
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3
b) 修改master下的/usr/local/hadoop/etc/hadoop/slaves
slave1
slave2
slave3
这样,master就可以知道slave1,2,3对应的IP了。
c) 启动namenode和datanode
master上需要格式化namenode,执行指令:
hadoop namenode -format
启动master上的namenode,在master上执行:
hadoop-daemon.sh start namenode
启动slave上的datanode,在每个slave上执行:
hadoop-daemon.sh start datanode
使用jps查看namenode和datanode的启动情况。

至此,一个master,三个slave的hadoop集群搭建完成并启动成功。
感谢马士兵老师的无私奉献,讲解视频百度云盘地址:http://pan.baidu.com/s/1slU6QrN
虚拟机搭建和安装Hadoop及启动的更多相关文章
- 马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- Hadoop3集群搭建之——安装hadoop,配置环境
接上篇:Hadoop3集群搭建之——虚拟机安装 下篇:Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoop3集群搭建之——hbase安装及简单操作 上篇已 ...
- 1.如何在虚拟机ubuntu上安装hadoop多节点分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- ubuntu在虚拟机下的安装 ~~~ Hadoop的安装及配置 ~~~ Hdfs中eclipse的安装
前言 Hadoop是基于Java语言开发的,具有很好跨平台的特性.Hadoop的所要求系统环境适用于Windows,Linux,Mac系统,我们推荐选择使用Linux或Mac系统.而Linux系统则 ...
- genymotion——在虚拟机中当中安装genymotion,启动已经新增好的设备时,提示:the virtual device got no ip address
1.启动已经新增好的设备时,提示:the virtual device got no ip address,于是在网上搜索该问题,便得到提示,先启动virtual box中的该模拟设备,于是便启动,出 ...
- 虚拟机VM14.X安装Mac10.12启动出现问题的解决方法
虚拟机安装Mac系统,会出现的问题太多,于是乎变记录下来,方便以后使用或者方便大家解决问题. 一:VM14.X安装Mac10.12虚拟机,启动出现下面无限重启问题 解决方法: 亲测有效 在OS X 1 ...
- 在虚拟机下安装hadoop集成环境(centos7+hadoop-2.6.4+jdk-7u79)
[1]64为win7系统,用virtualbox建立linux虚拟机时,为什么没有64位的选项? 百度 [2]在virtualbox上安装centos7 [3]VirtualBox虚拟机网络环境解析和 ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- CentOS7 搭建Ambari-Server,安装Hadoop集群(一)
2017-07-05:修正几处拼写错误,之前没发现,抱歉! 第一次在cnblogs上发表文章,效果肯定不会好,希望各位多包涵. 编写这个文档的背景是月中的时候,部门老大希望我们能够抽时间学习一下Had ...
随机推荐
- pom.xml的第一行报错
第一行:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.or ...
- 利用navcat为mysql数据库单独的表赋权限及表结构同步
为mysql数据库单独的表赋权限 场景:考勤系统需要拿OA数据库td_oa中的flow_run和flow_run_data表中的数据做考勤计算 考勤系统只需要读取这两张表的数据,所以只需要开通一个单独 ...
- how to detect circles and rectangle?
opencv中对圆检测的函数为:HoughCircles(src_gray,circles,CV_HOUGHT_GRADIENT,1,src_gray.cols/8,200,100,0,0) circ ...
- 【转】js中的事件委托或是事件代理详解
起因: 1.这是前端面试的经典题型,要去找工作的小伙伴看看还是有帮助的: 2.其实我一直都没弄明白,写这个一是为了备忘,二是给其他的知其然不知其所以然的小伙伴们以参考: 概述: 那什么叫事件委托呢?它 ...
- LeetCode(35):搜索插入位置
Easy! 题目描述: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引.如果目标值不存在于数组中,返回它将会被按顺序插入的位置. 你可以假设数组中无重复元素. 示例 1: 输入: [1 ...
- hdu4419
对于这类面积覆盖的题,大致就两点要注意的 1.同一把矩形放在笛卡尔坐标系上做 2.pushup函数要注意下细节:及在统计子区间和之前要先判断是否有子区间 用sum数组来保存区间被覆盖的情况,如果遇到多 ...
- 性能测试三十四:jvm内存结构(栈、堆、永久代)
Java内存管理机制 Java采用了自动管理内存的方式Java程序是运行在Jvm之中的Java的跨平台的基于Jvm的跨平台特性内存的分配和对象的创建是在Jvm中用户可以通过一系列参数来配置Jvm Jv ...
- js字符串转换成数字与数字转换成字符串的实现方法
转载:点击查看地址 js字符串转换成数字 将字符串转换成数字,得用到parseInt函数.parseInt(string) : 函数从string的开始解析,返回一个整数. 举例:parseInt(' ...
- python3 + selenium 之元素定位
8种定位方式 定位一个元素 webdriver提供了一系列的对象定位方法,常用的有以下几种 driver.find_element_by_name()--最常用,简单 driver.find_elem ...
- C#中的预处理指令详解
这篇文章主要介绍了C#中的预处理指令详解,本文讲解了#define 和 #undef.#if.#elif.#else和#endif.#warning和#error.#region和#endregion ...