AndrewNG Deep learning课程笔记 - RNN
The Unreasonable Effectiveness of Recurrent Neural Networks,http://karpathy.github.io/2015/05/21/rnn-effectiveness/
https://www.csdn.net/article/2015-08-28/2825569
RNN基础
rnn是的输入和输出都是序列,如图
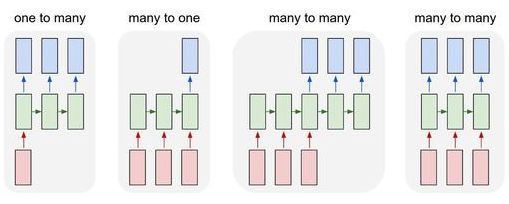
所以rnn可以认为是用于学习序列和序列之间的匹配关系
如何用符号表示
X,Y表示输入,输出
<t>,表示序列中序号
(i),表示训练集中的序号
T表示序列长度

对于NLP,X用传统的one-hot方式表示,基于字典vocabulary
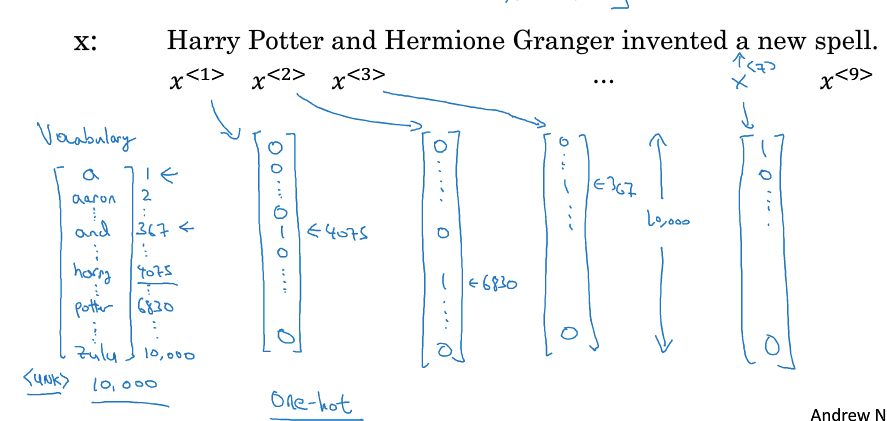
为何要使用rnn,使用标准网络有什么问题?

首先,从上面图也看的出来,序列长度是改变的,而对于标准网络,输入输出是固定的
再者,对于上面的X表示方式,可以看出X是很高维的,这样需要的参数会非常多,所以这里RNN和CNN一样,优势在于参数共享
CNN无论输入图片多大,参数是由filter大小决定
RNN无论序列多长,序列中的每一步的参数是一样的
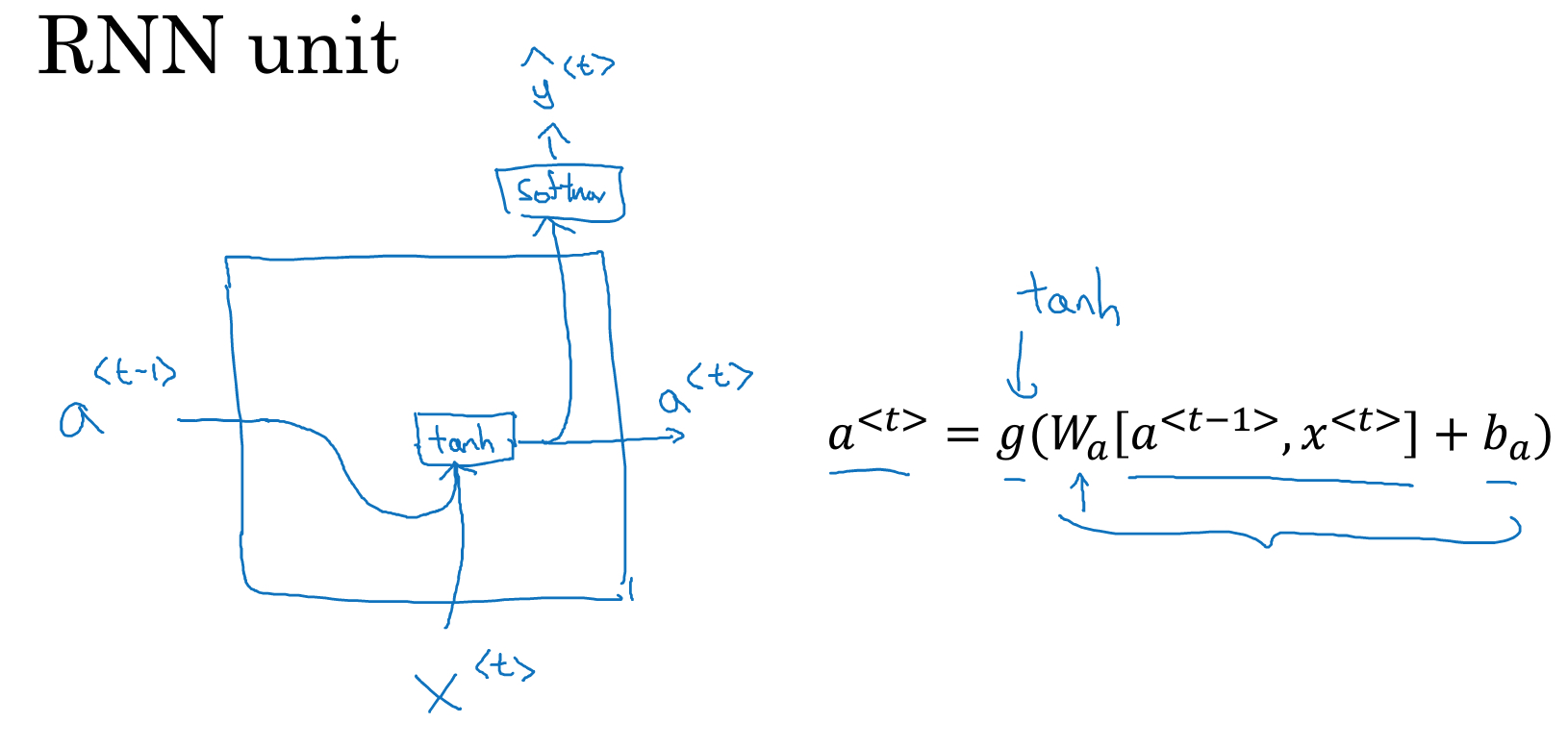
RNN的结构
下图给出一个RNN的示意图,
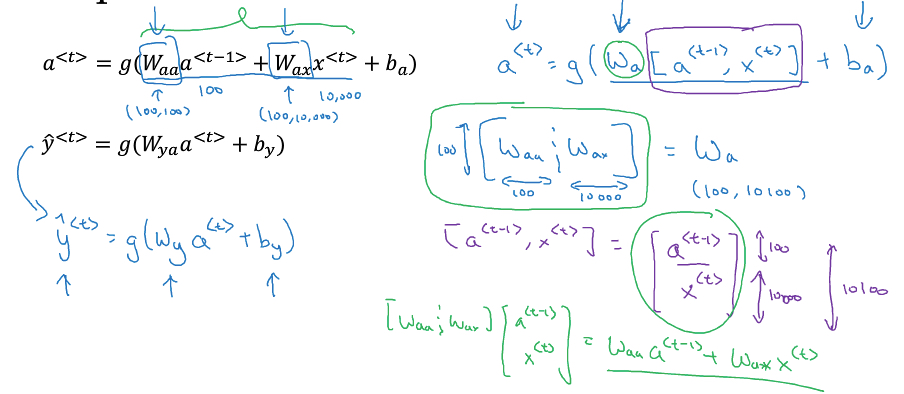
可以看到,主要有三个参数,Wax,Waa,Wya,用红色标出
可以看到RNN序列中的每一次迭代,参数是一样的,所以这是一层网络,而不是多层,也可以用右边的图表示
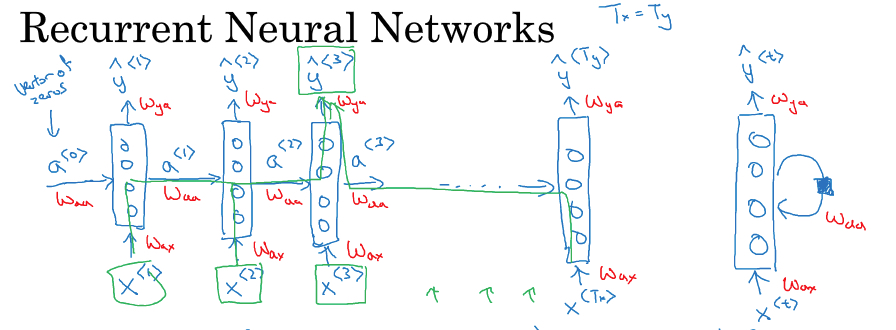
输出序列y和中间状态a,用如下公式计算出来
a0初始化成0向量
注意这里的激活函数,一般会用tanh
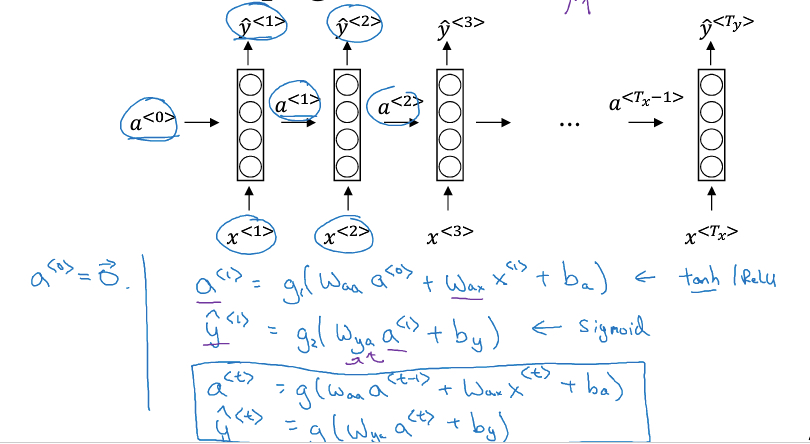
这里提供一种简写方式,把Waa,Wax合并成Wa
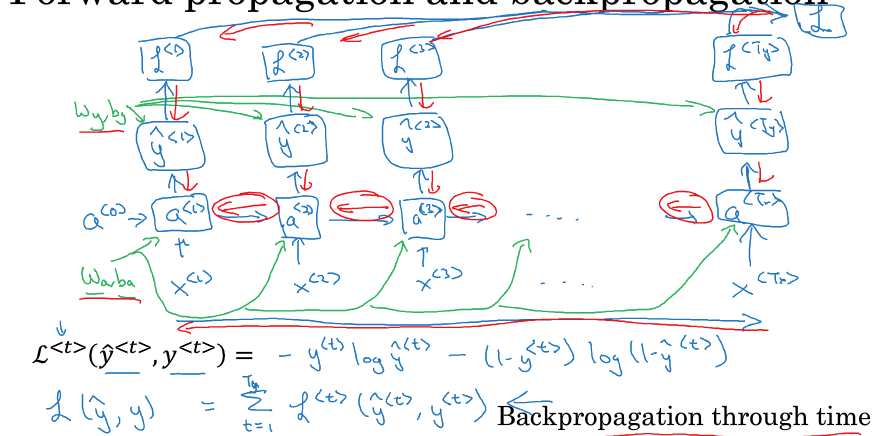
RNN的反向传播
NG没有给出具体的过程,具体的过程参考,https://www.cnblogs.com/pinard/p/6509630.html
这里只给出损失函数的定义,L<t>表示在序列t时刻的损失函数,L表示序列上所有t的损失函数和
对于Wy,by,求导比较直接,dL/dy/dWy
但是读音Wa,ba,就比较麻烦一些,因为对于a<t>的求导有两部分,
一部分是dy/da<t>,
另一部分是da<t+1>/da<t>,这一部分需要从序列尾部一级级算过来,所以叫backpropagation through time
要把两种加起来,再继续算dWa,dba
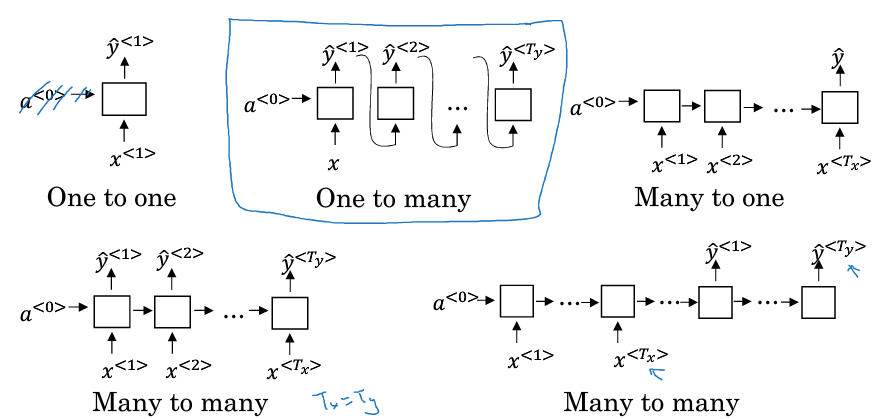
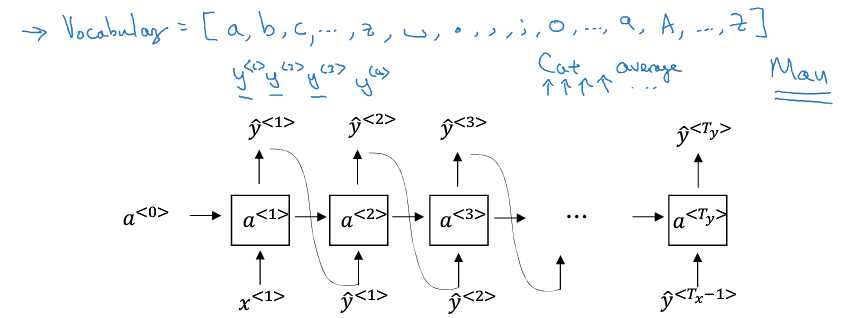
RNN的类型
One to one,普通网络
One to many, 用于序列生成场景,比较特殊,每个t的输出y<t>,会作为t+1的输入
Many to one,用于类似文本情感分析
Many to many,有两种,如果Tx = Ty,那么就是普通的RNN
如果Tx和Ty不相等,典型的场景是机器翻译,分为encoding和decoding的部分
Language model
什么是language model,是一种概率分布,
任意给一个句子,可以给出这个句子在这种language model里面出现的概率是多大
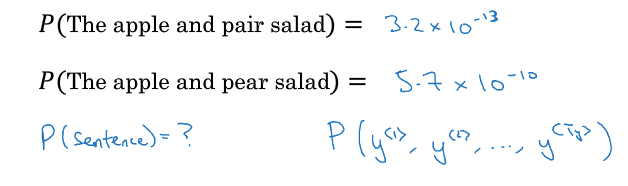
如何创建语言模型?
传统的方法是基于统计的方法,用n-gram,马尔科夫模型
那么用RNN的方式,如何创建,
然后需要使用One to many的 RNN进行训练,
过程如下,
对于训练集中的一个sample,cats average 15 hours of sleep a day. <EOS>
a<0>,x<1>都是0向量,输出是y^<1>
由于输出函数是softmax,所以y^<1>的size等同于vocabulary的大小,其中每个值的含义就是开头第一个单词是该词的概率
比如vocabulary中第一个单词是a,那么y^<1>中第一个值就是P(a),如果cats在vocabulary中是第100个词,那第100个值表示P(cats)
x<2>, 是cats,无论算出来y^<1>是啥,训练的时候,要使用y<1>
那这样通过softmax算出来y^<2>, 第一个值的含义是P(a | cats),其中有个值代表P(average | cats)
依次类推,x<3> = average, y^<3>,第一个值的含义是P(a | cats average)

这里损失函数是比较y<t>和y^<t>间的差异
用corpus来通过反向传播算法,就可以训练出language model
训练好的language模型可以干啥
首先可以判断,某个句子的出现概率,example,P(sentence) = P(cats) P(average | cats) P(15 | cats average),这些值从y^<t>中取到
然后,还可以序列生成
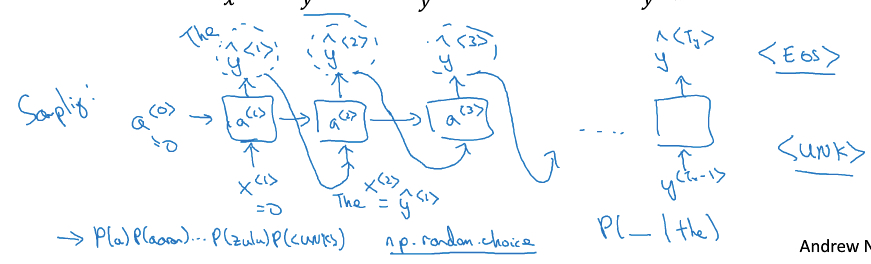
输出y^<1>时,我们要根据y^<1>中的概率,用np.random.choice选出一个词,这个函数会结合概率分布sampling一个词出来,比如sample出的词是the
那么把the作为x<2>输入
这个序列怎么算结束,当sampling的词是<EOS>时,句子结束
Character-level language model
之前看到的都是word-level的语言模型,word-level有个问题,就是depend on词典,词典中没有的词就无法表示
所以提出Character-level,对于英文,character就那么几个,所以不存在unknown的情况
Character-level模型的问题,就是序列长度要大一个数量级,计算成本会大很多
RNN梯度消失
RNN和普通网络一样,也有梯度消失或梯度爆炸的问题
梯度爆炸的问题,可以通过clip的方式,简单解决,就是设置梯度上限
梯度消失的问题就比较麻烦,当序列比较长的时候,后面的序列很难影响到前面序列的参数
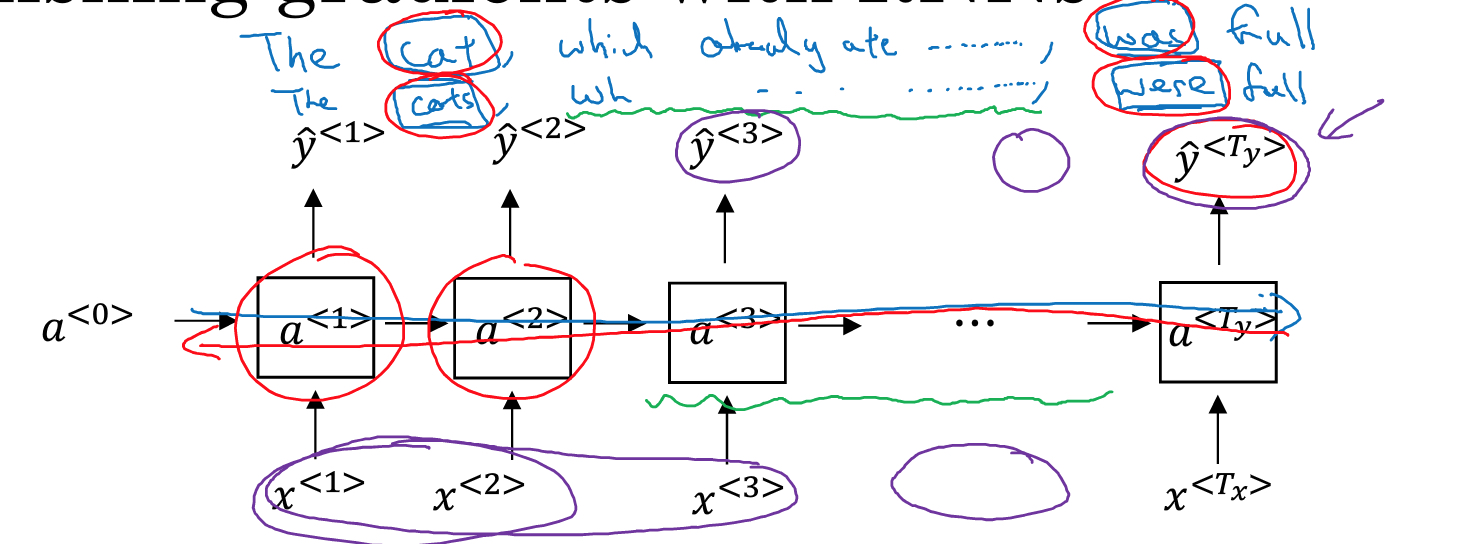
所以像例子中的cat,cats对后面was,were的对应关系,就很难学习到
在RNN中解决梯度消失的方式,是使用GRU(Gated Recurrent Unit)或LSTM(Long Short Term Memory)来解决
解决梯度消失的思路,一般都是将值直接往后传,如果每层都进行非线性变化,比如sigmod,很容易就会导致梯度消失
GRU
GRU是LSTM的简化版本,之所以先学GRU,是因为简单一些,实际使用时LSTM还是更普遍一些
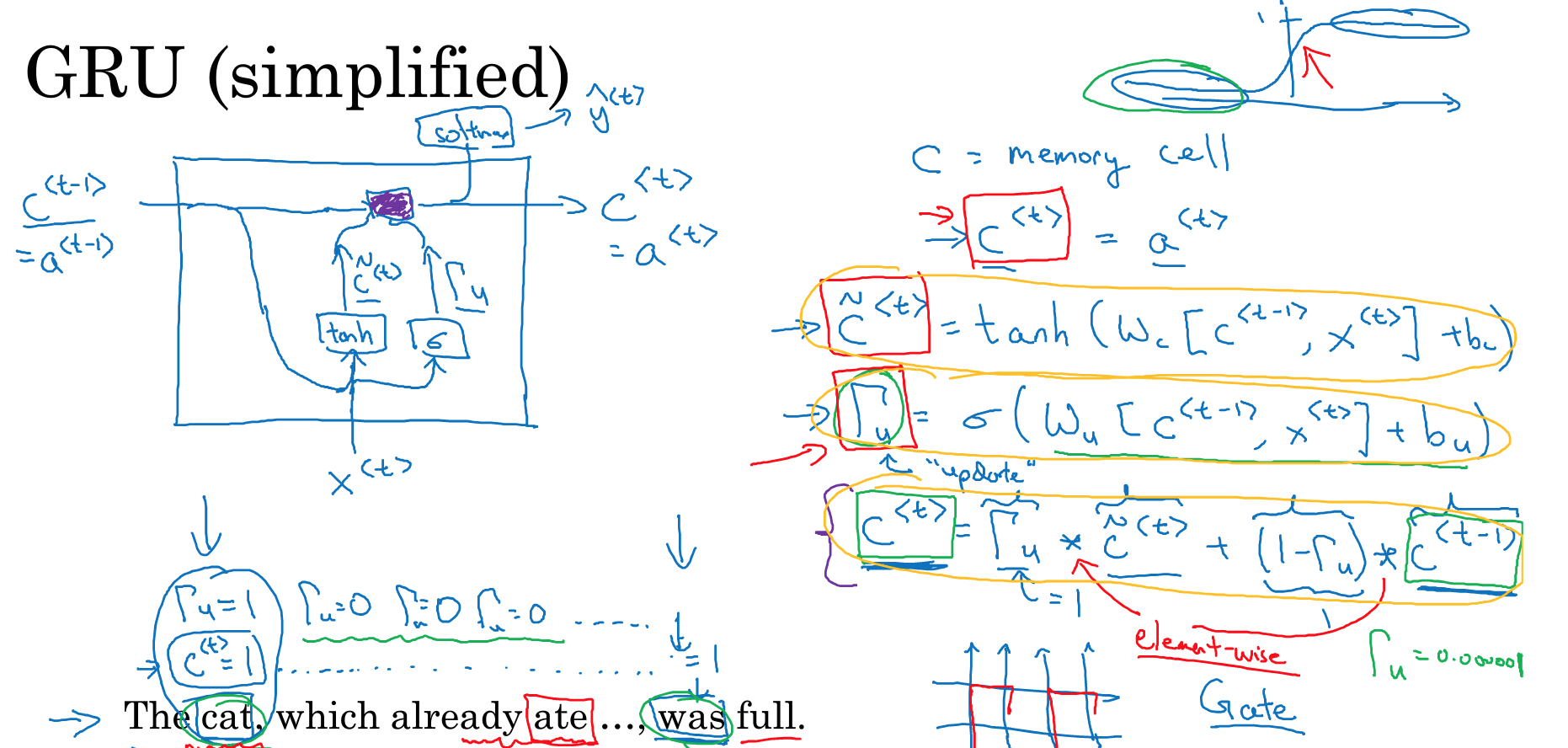
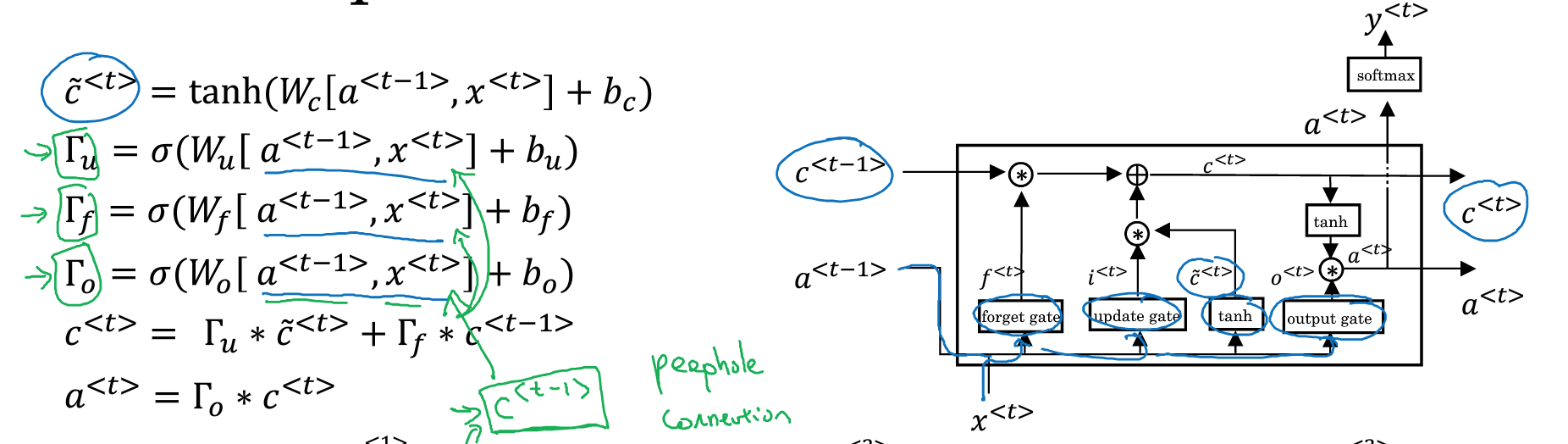
和普通RNN区别,
引入memory cell,c<t>,虽然在GRU里面,c<t>和a<t>没有区别
这里的c~<t>,等同于普通RNN的a<t>
区别就是,这里不会直接把c~<t>输出,而是要和c<t-1>做个选择,选择的标准就是G
G本身也是通过一个神经元得到,它的激活函数是sigmod,所以大部分情况下,G的值都是0或1,这是由sigmod函数的特性决定的
所以这里根据G的值,可能输出c~<t>,也可能直接把上一层的c<t-1>继续传递
这里注意,c,a都是向量,size等于vocabulary的大小
所以gate也是一个相同大小的向量,里面部分值接近0,表示保留上一层的数据,部分值接近1,表示学习这层新的内容
比如,例子中,cat用向量中的一位表示,这一位的gate值一直是0,表示保留cat,直到was
而其他的位的gate值就可能是1,用于学习中间出现的which already ate
LSTM
LSTM相对复杂些,但是理解了GRU,思路类似,
首先,c<t>和a<t>分开
再者,gate变多,一共3个,Gupdate(等同于GRU中的gate),Gforget(等同于GRU中的1-gate),增加Goutput
最后,通过Goutput算出a<t>
然后,算gate的时候,也可以考虑c<t-1>, 称为peephole connection
Bidirectional RNN
普通的RNN只能考虑之前出现的word对当前的影响,即context上下文只能考虑一半,如果要考虑前后上下文的影响,就需要使用bidirectional rnn
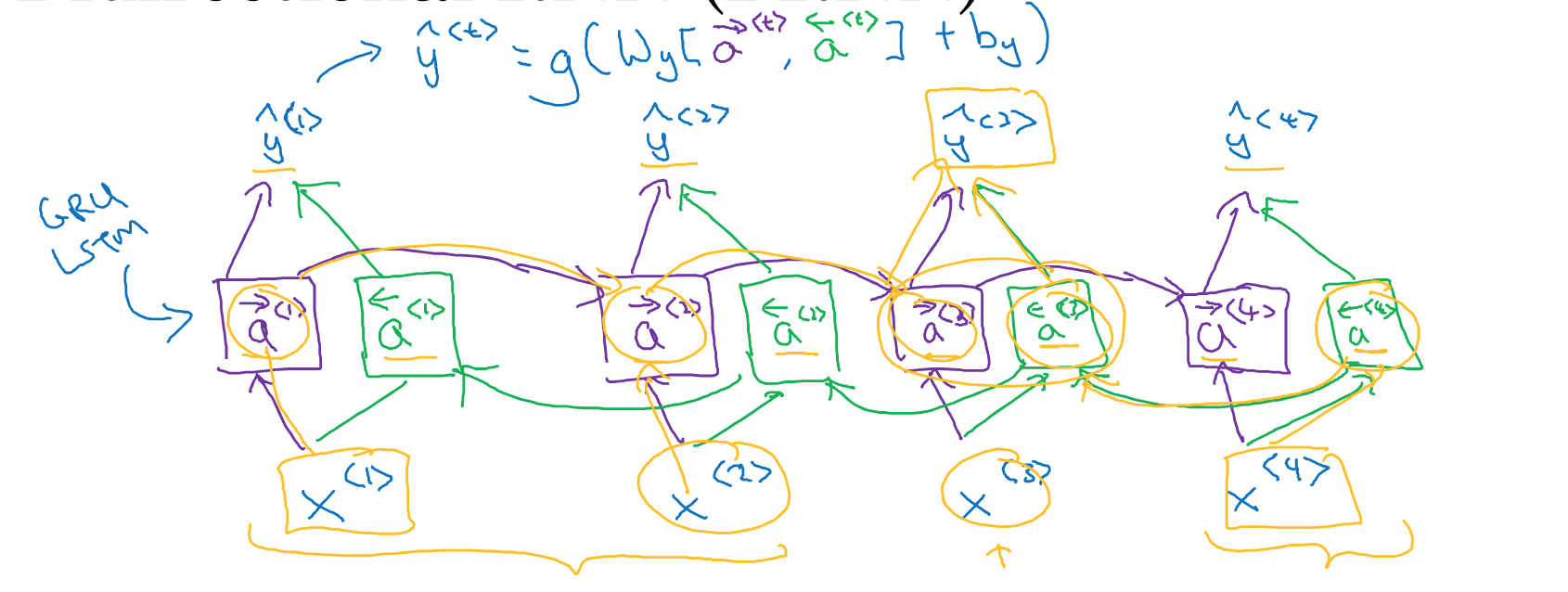
Bidirectional,需要把序列正向遍历一遍,这个和普通RNN一样
还需要把序列反向遍历一遍,然后用两遍遍历的a-><t>,a<-<t>,共同决定y^<t>
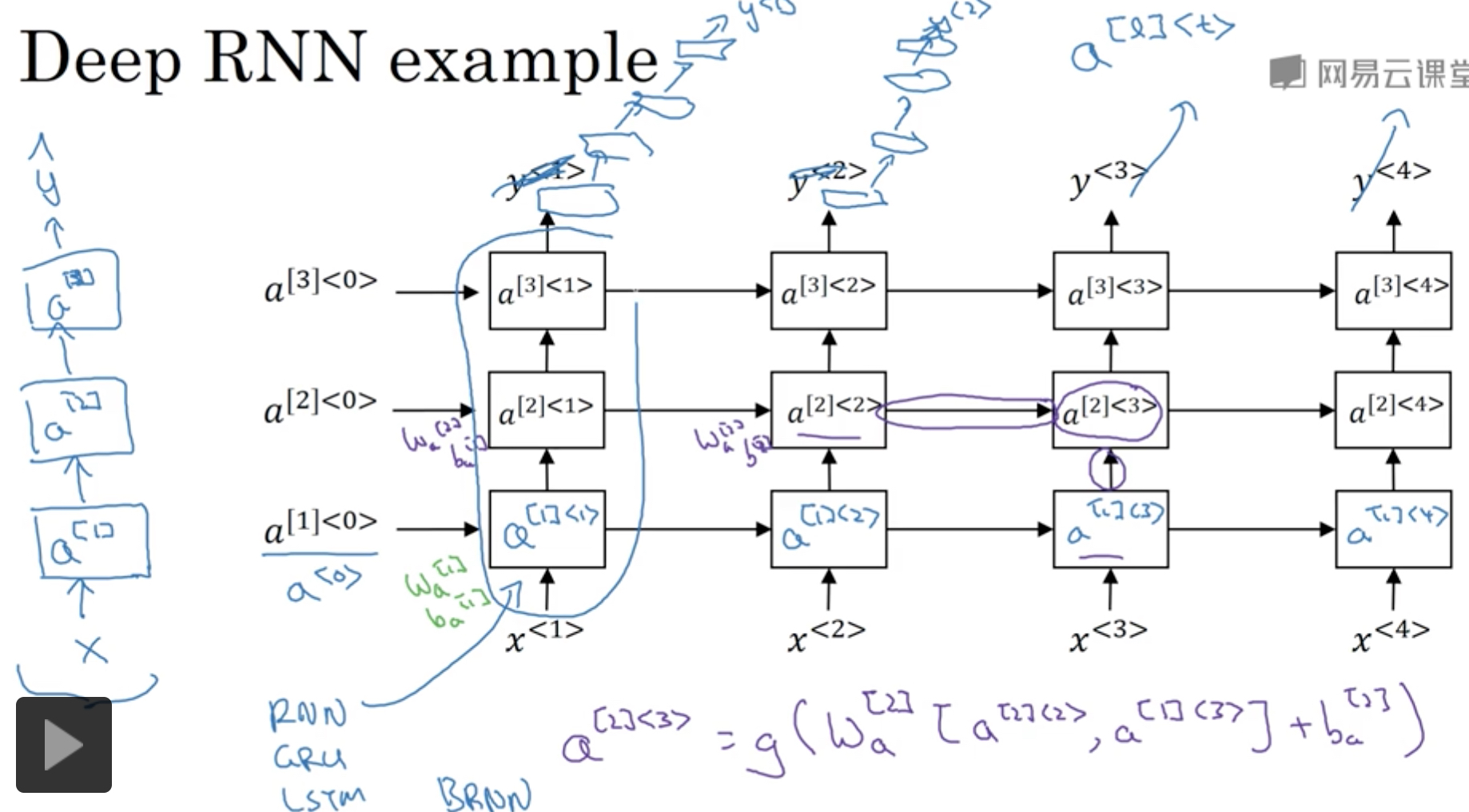
Deep RNN
RNN一个序列,只能算是一个layer,为什么?简单的理解,因为只有一组参数
我们也可以把RNN进行stack,RNN一般不会太深,3层已经比较深,因为计算量太大了
如果要加深depth,可以在output上添加一组普通的NN
Word Embedding
在NLP领域,传统使用one-hot的表示方法来表示word
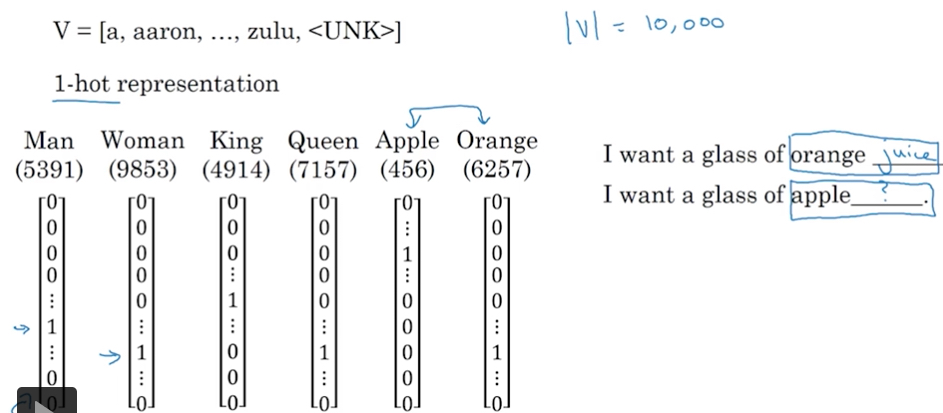
这种表示的问题,
首先维度很高,等于vocabulary的size
再者,各个词之间的是孤立的,没有相关性的,用任意两个词向量做点积,得到的结果都是0
所以看右边的例子,我们就算学习到orange juice,也无法应用到apple上
这里介绍的新的word表示方法,word embedding

这里作为例子,我们用一些可理解的features来表示word,比如gender, royal, age等
这样表示的好处,首先features数会比较少,比如这里的300,远小于vocabulary的size
关键的是,各个words间通过features具有了相关性,Apple和Orange在features上很相似,所以在orange上学习到的knowledge也可以用在apple上
word embedding是可以通过海量的无标注的语料库训练出来,这个是可以重用的,或者transfer learning
使用很简单,先将你的word的one-hot表示通过word embedding模型进行encoding成特征向量,再继续后面的学习
这样的好处,是可以只用很少的训练集来完成NLP应用,因为对于NLP,大量的知识已经包含在word embedding模型中了
word embedding还有一个很有用的特性,
可以用它来比较词与词之间的关系
并且只需要通过简单的词向量间的相减,
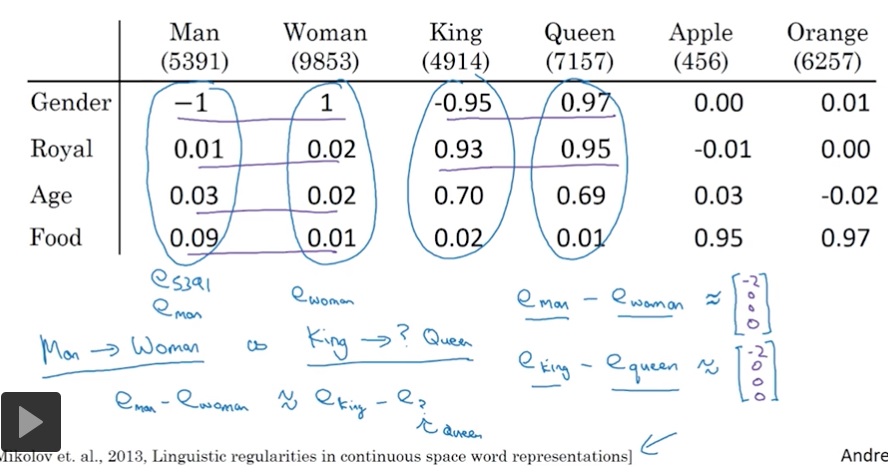
比如,回答 Man:Woman等同于 King:?
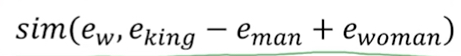
用这个公式就可以简单求出
那么下面自然的问题就是,如何训练出word embedding?
最早的方法如下,
用语料库来训练language modeling,
即这样的问题,我们以前n个词作为context来预测下一个词是什么?
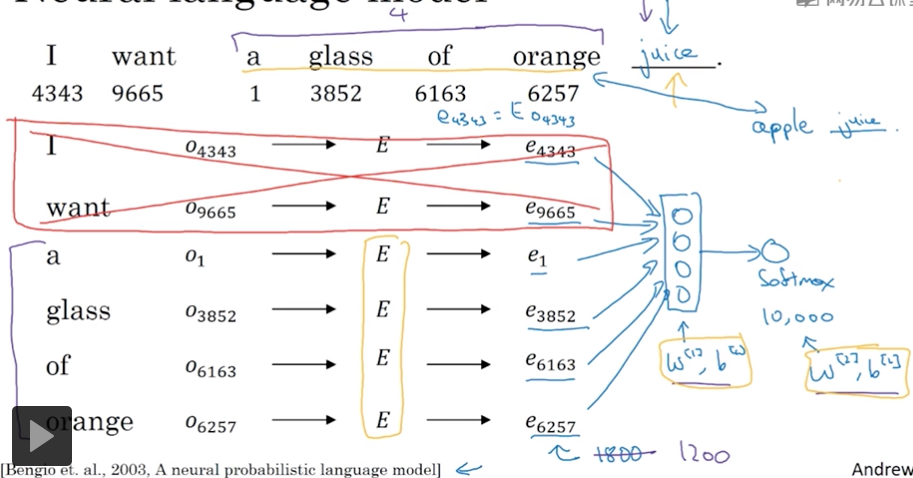
输入是one-hot向量(10000维),经过Embedding矩阵E,转化成word embedding(300维)
那么这里的E就是我们最终要训练出的word embedding模型
后面再接上一层nn和一层softmax
这样nn中要训练的参数用黄色线框出,优化目标就是后面真正出现的词
例子中就是juice
这个方法生效的原因是,如果要得到相同的输出,自然word embedding输入也要接近
如果我们训练nn的目标是得到语言模型,language modeling,那么一般这里的context都是用前n个词,来预测后一个词
但是如果我们的目标是得到word embedding,实验证明我们可以用一些更简单的context也能达到比较好的效果
比如,前一个word,或 nearby a word
Word2Vec
Word2Vec,顾名思义,就是一种生成 word embedding的算法
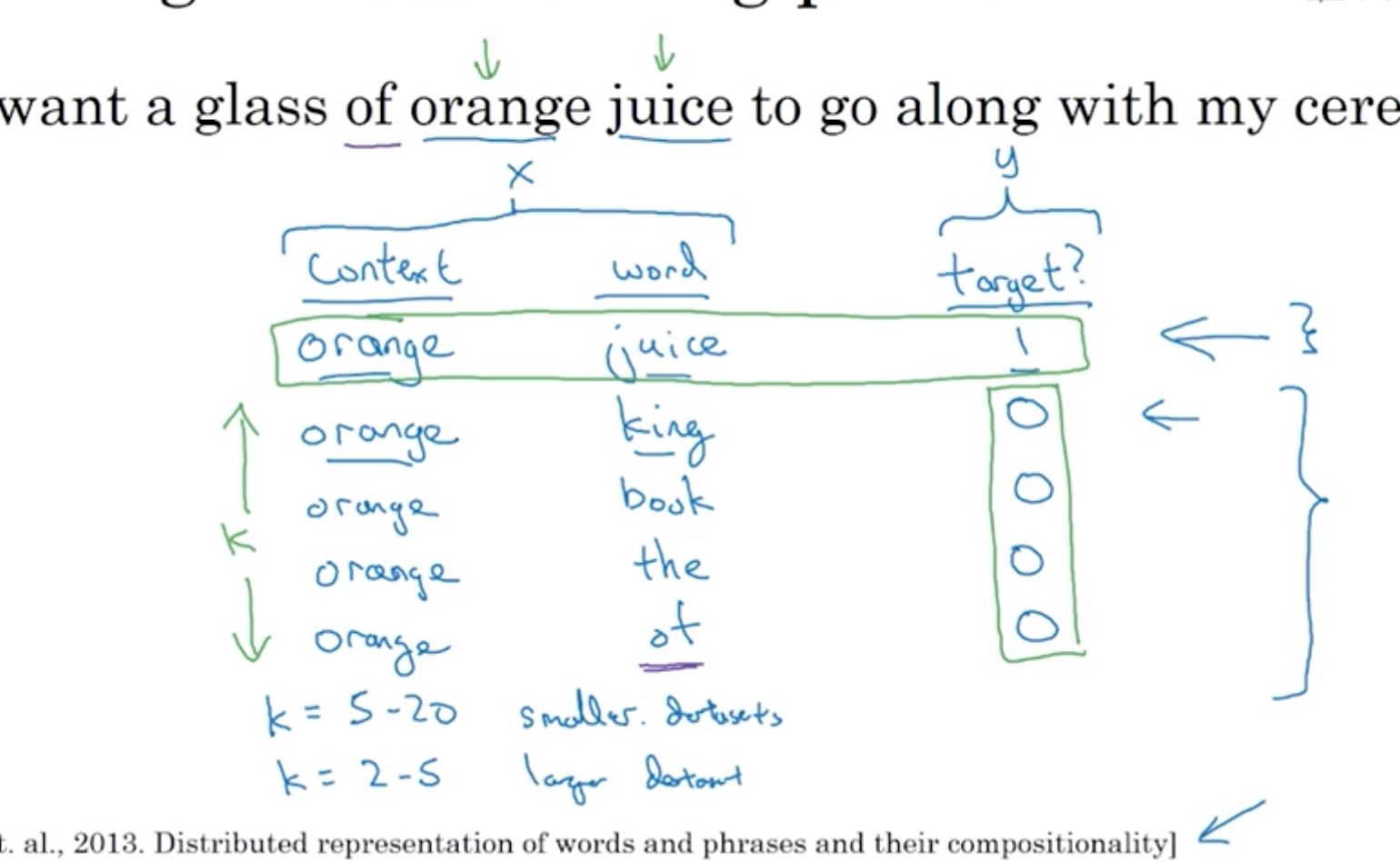
context选取,
以任一个词为context,然后以这个词的前后10个词中,随机选择一个词作为target
如下面的例子,看起来很随性,这称为skip-gram
但是这里的采样也不是完全随机和均匀分布的,因为这样很容易导致大部分采样都是常见词,a, of, the;所以还是要采用些启发式的方式去合理选择常见,不常见的word
Word2Vec里面还有另外一种context版本,CBow,用两边的词预测中间的词

模型如下,
可以看到,这个模型确实简单
用E转化成embedding后,只接了一层softmax
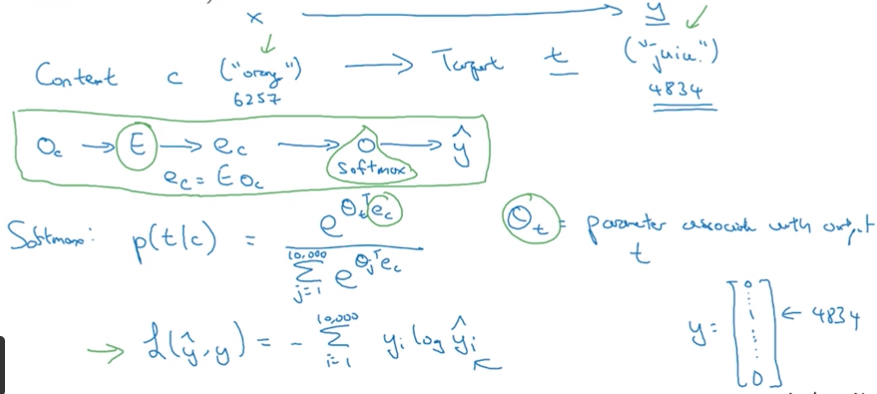
这个模型虽然简单,但是最大的问题的是,Softmax的分母要遍历计算整个vocabulary,这个计算量非常的大
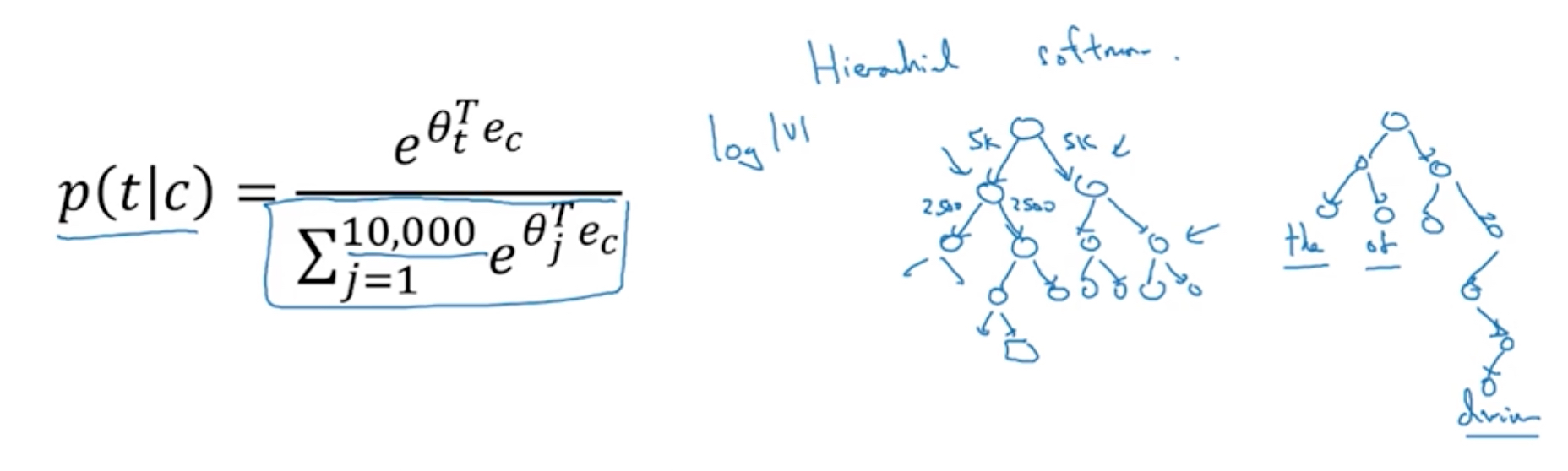
有一种优化就是把softmax分层,如何分层可以二分,也可以更高效的按熵值进行分层
Negative sampling
softmax之所以计算复杂度比较高,是因为它是一个多元分类,比如vocabulary里面有100000个word,一次分类就需要同时考虑所有的word
其实softmax等价于多个二元分类,100类的softmax也可以用100个二元分类器
但是如果我们要训练的是分类器本身,那么这样一点用也没有,同时训练100个二元分类器肯定更加低效
但是我们这里是要训练前面的E,
所以我们先把一个多元分类问题转化成一个二元分类问题,
这里的问题转换为,判断orange的context window中是否有另一个词,比如juice
这样从corps中,我们可以得到一个正样本,但是二元分类还需要负样本
这里我们随机从vocabulary中选取word作为负样本,哪怕选中的词恰巧也在context窗口中,也没有关系,比如例子中的of
每产生一个正样本,我们会产生k个负样本,k可以随着数据集的变大而变小,这里选择4
所以这个方法称为negative sampling, 负采样
所以模型就变成如下图,
只是最后一步从一个softmax变成10000个二元分类器,这里并不需要一次训练所有的分类器
一次只需要训练其中k+1个二元分类器,比如例子中一个正样本,4个负样本
因为我们的目的是通过分类器来训练E,而不是训练分类器本身,所以这样是可行的

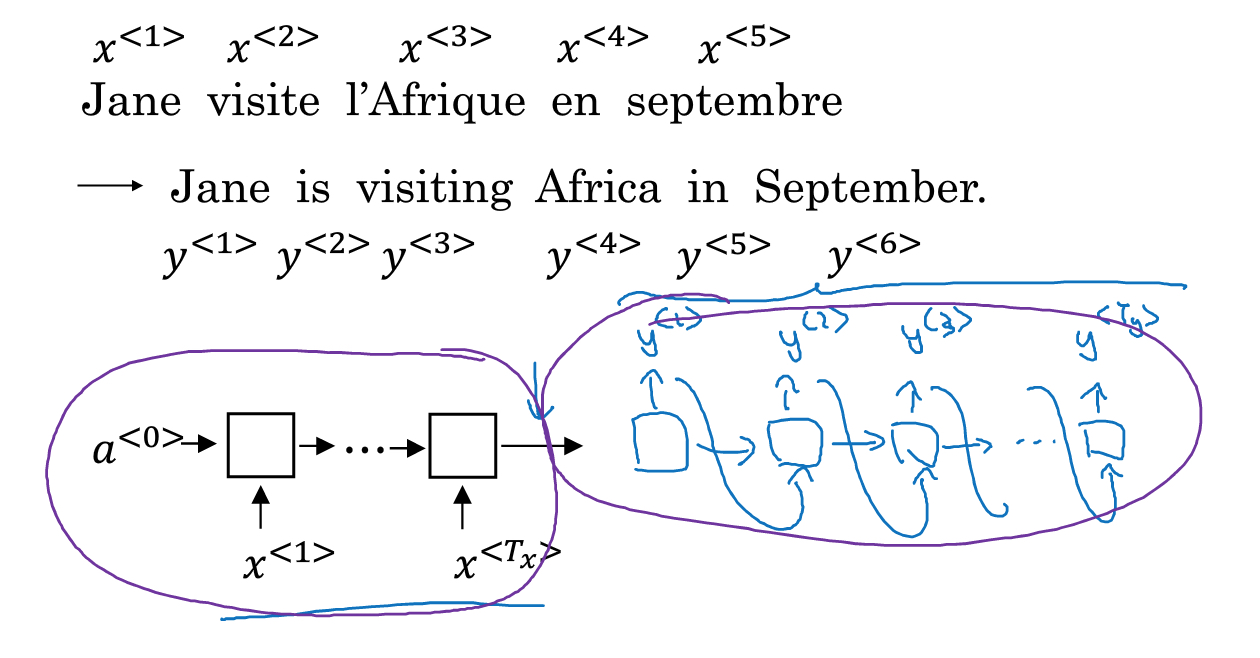
seq2seq模型
该模型的最典型的场景,就是翻译
如下图,法语翻译成英语,由于输入,输出的个数不一致,所以需要分成两部分,encoding和decoding部分
这个模型也可以用于训练一个序列的embedding,比如把sql query encoding,保证输入输出一致,就可以训练encoding部分
还有一个有意思的场景是看图说话,这个和翻译的差别就是input不一样
input不是一个query,而是一个图片
所以encoding部分不能用RNN,这里用的是CNN,通过CNN生成encoding后,再继续接上用RNN的decoding的部分
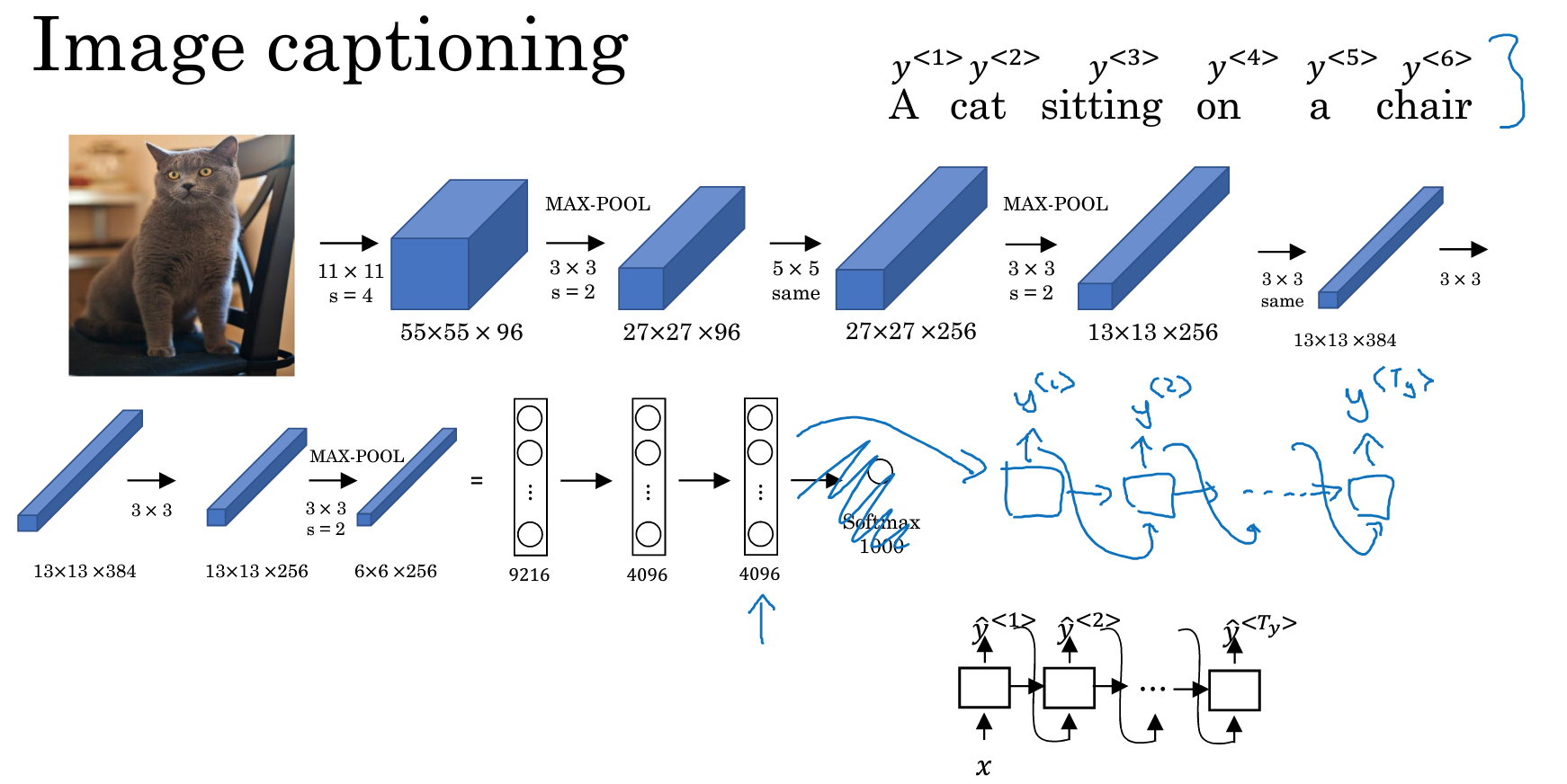
和简单的RNN模型相比
Seq2seq模型在概率模型是不一样的
对于语言模型的概率模型就是单纯的,P(y1,y2,y3,y4)
而在机器翻译时,概率模型是,P(y1,y2,y3,y4| x1,x2,x3)
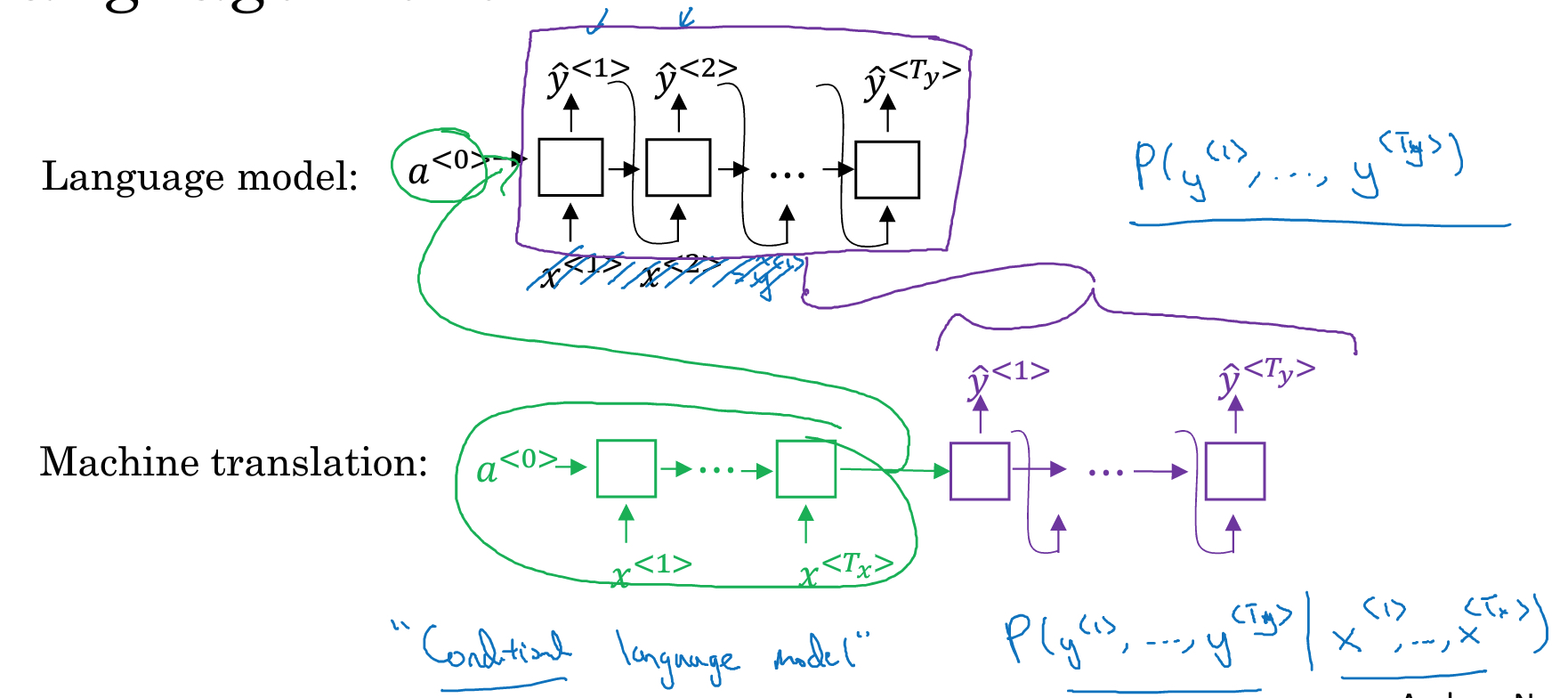
机器翻译的问题在于,
decoding的时候,因为y1,y2,y3是softmax输出,是一个所有word的概率
所以可能有多种可能的输出,如下图,

所以我们需要找出其中最合适的
直观的想法就是贪婪算,每一步都挑概率最大的输出,这个效果一定不会太好,如下面的例子,
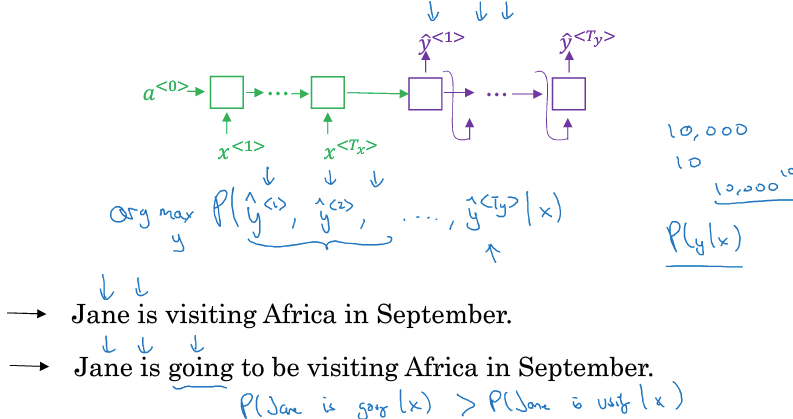
第三个词是going的概率是要大于visiting的,但从整体上看,上面的翻译会更加好些
Beam Search
既然greed算法无法找到全局最优
这里提出Beam search来试图找出更优解
beam search的思路很简单,既然每次用最优的考虑的case太少了,那就多考虑些
比如我们设置beam width=3,即每次考虑top3的可能性
第一步,算P(y1 | x),找出p最大的3个,比如,in,jane,september
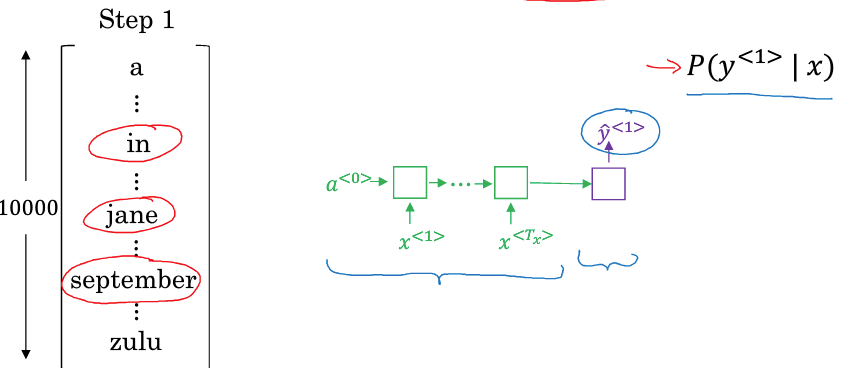
第二步,基于y1,找到y2
目标是,P(y1,y2|x) = P(y1|x) P(y2|x, y1)
在第一步中找到3个word,第二步对每一个都有10000种可能性,一共300000种可能性,从其中再找出 P(y1,y2|x) top3的组合
比如这里,是In september,jane is,jane was
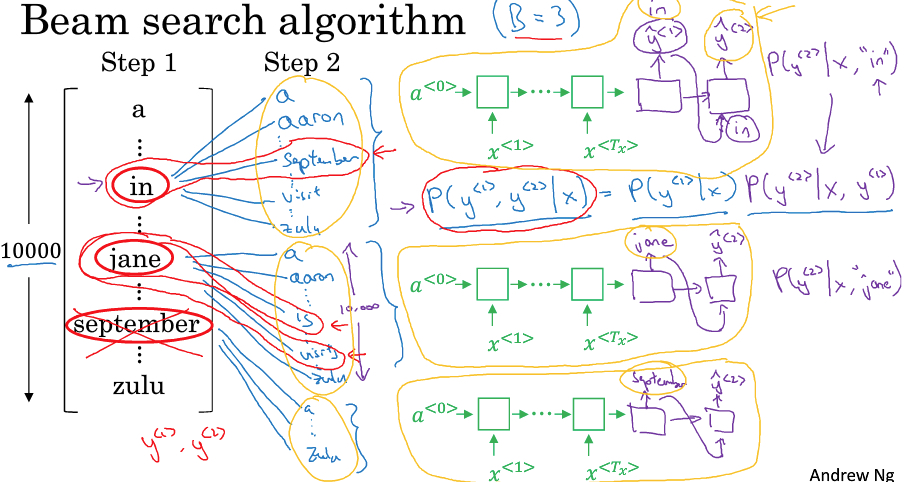
这样一步步迭代下去,每一步都选最优的3个组合,最终可以找到较优的组合
beam search的优化
beam seach在求P(y1, y2, y3, ...| x)的时候,是连乘,一堆很小的数连乘,很容易就溢出
所以典型的思路,用log转换成连加
然后为了解决sentence长度带来的对P的影响,除上sentence长度进行平均normalization

beam search 误差分析
如下面的例子,如果通过算法得到的结果没有训练集中的好,那我们怎么分析原因
y*是正确的结果
y^是算法得到的结果
做法,比较P(y* | x) 和 P(y^ | x)
P(y* | x) 大,说明RNN 的language model没有问题,beam search算法没有找出最优解,可以增加beam width
P(y^ | x)大,说明RNN 的language model本身有问题,需要从新去训练

AndrewNG Deep learning课程笔记 - RNN的更多相关文章
- AndrewNG Deep learning课程笔记 - CNN
参考, An Intuitive Explanation of Convolutional Neural Networks http://www.hackcv.com/index.php/archiv ...
- AndrewNG Deep learning课程笔记
神经网络基础 Deep learning就是深层神经网络 神经网络的结构如下, 这是两层神经网络,输入层一般不算在内,分别是hidden layer和output layer hidden layer ...
- 吴恩达《深度学习》-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-第一周:深度学习的实践层面 (Practical aspects of Deep Learning) -课程笔记
第一周:深度学习的实践层面 (Practical aspects of Deep Learning) 1.1 训练,验证,测试集(Train / Dev / Test sets) 创建新应用的过程中, ...
- Neural Networks and Deep Learning 课程笔记(第四周)深层神经网络(Deep Neural Networks)
1. 深层神经网络(Deep L-layer neural network ) 2. 前向传播和反向传播(Forward and backward propagation) 3. 总结 4. 深层网络 ...
- Neural Networks and Deep Learning 课程笔记(第二周)神经网络的编程基础 (Basics of Neural Network programming)
总结 一.处理数据 1.1 向量化(vectorization) (height, width, 3) ===> 展开shape为(heigh*width*3, m)的向量 1.2 特征归一化( ...
- Neural Networks and Deep Learning 课程笔记(第三周)浅层神经网络(Shallow neural networks)
3.1 神经网络概述(Neural Network Overview ) (神经网络中,我们要反复计算a和z,最终得到最后的loss function) 3.2 神经网络的表示(Neural Netw ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
随机推荐
- 《深入应用C++11:代码优化与工程级应用》勘误表
<深入应用C++11:代码优化与工程级应用>勘误表,会不断更新,欢迎读者留言或发邮件(cpp11book@163.com)给我提出宝贵意见. 1.第7.3节目录final和override ...
- js实现鼠标拖动框选元素小狗
方法一: <html> <head></head> <style> body{padding:100px;} .fileDiv{float:left;w ...
- Git -- 自定义git样式
在安装Git一节中,我们已经配置了user.name和user.email,实际上,Git还有很多可配置项. 比如,让Git显示颜色,会让命令输出看起来更醒目: $ git config --glob ...
- 阿里云ECS服务器主机安装多个网站
web|服务器|站点 Windows 2000 Server安装成功后,一般会启动一个默认的Web站点,为整个网络提供Internet服务.在中小型局域网中,服务器往往只有一台,但是一个Web站点显然 ...
- How can I get the baseurl of site?
string baseUrl = Request.Url.Scheme + "://" + Request.Url.Authority +Request.ApplicationPa ...
- 【SQLSERVER】How to check current pool size
SELECT des.program_name , des.login_name , des.host_name , COUNT(des.session_id) [Connections] FROM ...
- 斯坦福2011秋季 iPad and iPhone Application Development 资源
1. MVC and Introduction to Objective-C (September 27, 2011) - HD 2. My First iOS App (September 29, ...
- 【转载】eclipse常用插件在线安装地址或下载地址
一,反编译插件: A.Jadclipse 1.打开eclipse增加站点:http://jadclipse.sf.net/update,在线安装好JDT Decompiler 3.4.0 2.http ...
- [原]NTP时间服务器简单设置
====server edit /etc/ntp.conf 添加 server 127.127.1.0 fudge 127.127.1.0 stratum 1 fudge 127.127.1.0 ...
- Xshell登录Ubuntu12.04
Ubuntu安装ssh服务: sudo apt-get install openssh-server 打开Xshell,选择“新建”,“连接”设置里选择SSH,主机填入需要连接的主机的IP地址.在“用 ...