DRF之简介以及序列化操作
1. Web应用模式.
在开发Web应用中,有两种应用模式:
前后端不分离

2.前后端分离
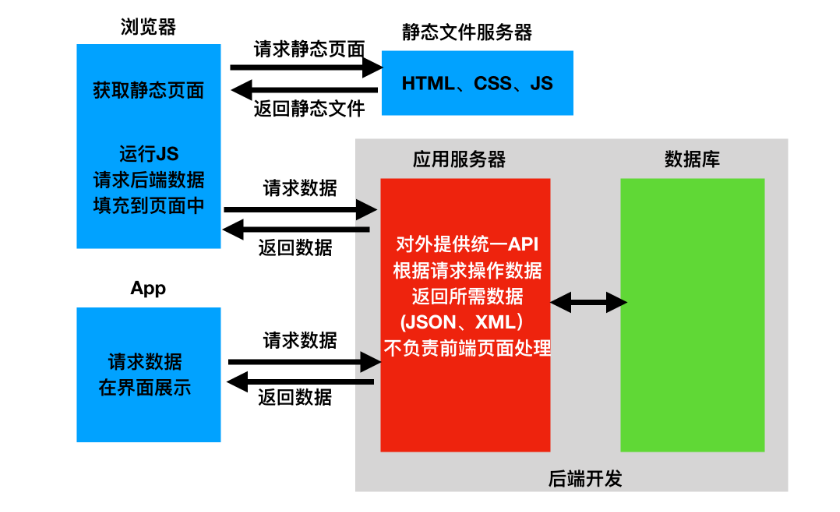
2. api接口
为了在团队内部形成共识、防止个人习惯差异引起的混乱,我们需要找到一种大家都觉得很好的接口实现规范,而且这种规范能够让后端写的接口,用途一目了然,减少双方之间的合作成本。
目前市面上大部分公司开发人员使用的接口服务架构主要有:restful、rpc。
rpc: 翻译成中文:远程过程调用[远程服务调用].
post请求
action=get_all_student¶ms=301&sex=1
接口多了,对应函数名和参数就多了,前端在请求api接口时,就会比较难找.容易出现重复的接口
restful: 翻译成中文: 资源状态转换.把后端所有的数据/文件都看成资源.那么接口请求数据,本质上来说就是对资源的操作了.
web项目中操作资源,无非就是增删查改.所以要求在地址栏中声明要操作的资源是什么,然后通过http请求动词来说明对资源进行哪一种操作.
POST http://www.lufei.com/api/students/ 添加数据
GET http://www.lufei.com/api/students/ 获取所有学生
3. RESTful API规范
REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移。 它首次出现在2000年Roy Fielding的博士论文中。
RESTful是一种定义Web API接口的设计风格,尤其适用于前后端分离的应用模式中。
这种风格的理念认为后端开发任务就是提供数据的,对外提供的是数据资源的访问接口,所以在定义接口时,客户端访问的URL路径就表示这种要操作的数据资源。
而对于数据资源分别使用POST、DELETE、GET、UPDATE等请求动作来表达对数据的增删查改。
| 请求方法 | 请求地址 | 后端操作 |
| -------- | ----------- | ----------------- |
| GET | /students | 获取所有学生 |
| POST | /students | 增加学生 |
| GET | /students/1 | 获取编号为1的学生 |
| PUT | /students/1 | 修改编号为1的学生 |
| DELETE | /students/1 | 删除编号为1的学生 |
事实上,我们可以使用任何一个框架都可以实现符合restful规范的API接口。
参考文档:http://www.runoob.com/w3cnote/restful-architecture.html
4. 序列化
api接口开发,最核心最常见的一个过程就是序列化,所谓序列化就是把数据转换格式,序列化可以分两个阶段:
序列化: 把我们识别的数据转换成指定的格式提供给别人。
例如:我们在django中获取到的数据默认是模型对象,但是模型对象数据无法直接提供给前端或别的平台使用,所以我们需要把数据进行序列化,变成字符串或者json数据,提供给别人。
反序列化:把别人提供的数据转换/还原成我们需要的格式。
例如:前端js提供过来的json数据,对于python而言就是字符串,我们需要进行反序列化换成模型类对象,这样我们才能把数据保存到数据库中。
5. Django Rest_Framework
核心思想: 缩减编写api接口的代码
Django REST framework是一个建立在Django基础之上的Web 应用开发框架,可以快速的开发REST API接口应用。在REST framework中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化与反序列化的过程,不仅如此,还提供丰富的类视图、扩展类、视图集来简化视图的编写工作。REST framework还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。REST framework提供了一个API 的Web可视化界面来方便查看测试接口。
中文文档:https://q1mi.github.io/Django-REST-framework-documentation/#django-rest-framework
github: https://github.com/encode/django-rest-framework/tree/master
特点
提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
提供了丰富的类视图、Mixin扩展类,简化视图的编写;
丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
多种身份认证和权限认证方式的支持;[jwt]
内置了限流系统;
直观的 API web 界面;
可扩展性,插件丰富
6. 环境安装与配置
DRF需要以下依赖:
Python (2.7, 3.2, 3.3, 3.4, 3.5, 3.6)
Django (1.10, 1.11, 2.0)
DRF是以Django扩展应用的方式提供的,所以我们可以直接利用已有的Django环境而无需从新创建。(若没有Django环境,需要先创建环境安装Django)
6.1 安装DRF
pip install djangorestframework
6.2 添加rest_framework应用
在settings.py的INSTALLED_APPS中添加'rest_framework'。
INSTALLED_APPS = [
...
'rest_framework',
]
接下来就可以使用DRF进行开发了。在项目中如果使用rest_framework框架实现API接口,主要有以下三个步骤:
将请求的数据(如JSON格式)转换为模型类对象
操作数据库
将模型类对象转换为响应的数据(如JSON格式)
创建django项目:
注意,最好使用cmd窗口命令创建原生django项目,不要用pycharm自带的工具创建,避免pycharm自身增加的一些配置,防止在项目合作开发时遇到合并代码时出现问题;
django-admin.py startproject mysite
一个完整的使用模型序列化的示例:
url:
from django.contrib import admin
from django.urls import path, include urlpatterns = [
path('admin/', admin.site.urls),
path('api/', include("demo1.urls")),
]
demo1 url:
from rest_framework.routers import DefaultRouter
from .views import BookInfoAPIView
urlpatterns = [] # 创建路由对象
routers = DefaultRouter()
# 通过路由对象对视图类进行路由生成
routers.register("books",BookInfoAPIView) urlpatterns+=routers.urls
demo1 view试图:
from rest_framework.viewsets import ModelViewSet
from demo1.models import BookInfo
from .serializers import BookInfoSerializer
# Create your views here.
class BookInfoAPIView(ModelViewSet):
# 当前视图类所有方法使用得数据结果集是谁?
queryset = BookInfo.objects.all()
# 当前视图类使用序列化器类是谁
serializer_class = BookInfoSerializer
models:
from django.db import models # Create your models here. # Create your models here.
#定义图书模型类BookInfo
class BookInfo(models.Model):
btitle = models.CharField(max_length=20, verbose_name='图书标题')
bpub_date = models.DateField(verbose_name='出版时间')
bread = models.IntegerField(default=0, verbose_name='阅读量')
bcomment = models.IntegerField(default=0, verbose_name='评论量')
is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') class Meta:
db_table = 'tb_books' # 指明数据库表名
verbose_name = '图书' # 在admin站点中显示的名称
verbose_name_plural = verbose_name # 显示的复数名称 def __str__(self):
"""定义每个数据对象的显示信息"""
return "图书:《"+self.btitle+"》" #定义英雄模型类HeroInfo
class HeroInfo(models.Model):
GENDER_CHOICES = (
(0, '男'),
(1, '女')
)
hname = models.CharField(max_length=20, verbose_name='名称')
hgender = models.SmallIntegerField(choices=GENDER_CHOICES, default=0, verbose_name='性别')
hcomment = models.CharField(max_length=200, null=True, verbose_name='技能描述')
hbook = models.ForeignKey(BookInfo, on_delete=models.CASCADE, verbose_name='所属图书') # 外键
is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') class Meta:
db_table = 'tb_heros'
verbose_name = '英雄'
verbose_name_plural = verbose_name def __str__(self):
return self.hname
运行项目后,可进行增删改查操作:
在浏览器中输入网址127.0.0.1:8000,可以看到DRF提供的API Web浏览页面:
点击链接127.0.0.1:8000/books/ 可以访问获取所有数据的接口(查看所有,添加)
在浏览器中输入网址127.0.0.1:8000/books/d+/,可以访问获取单一图书信息的接口(id为d+的图书) (删除.修改)
序列化与反序列化(不包含DRF的视图操作):用法和forms组件很相像
定义序列化器
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
例如,我们已有了一个数据库模型类BookInfo
class BookInfo(models.Model):
btitle = models.CharField(max_length=20, verbose_name='名称')
bpub_date = models.DateField(verbose_name='发布日期', null=True)
bread = models.IntegerField(default=0, verbose_name='阅读量')
bcomment = models.IntegerField(default=0, verbose_name='评论量')
image = models.ImageField(upload_to='booktest', verbose_name='图片', null=True)
我们想为这个模型类提供一个序列化器,可以定义如下:
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
创建Serializer对象
定义好Serializer类后,就可以创建Serializer对象了。
Serializer的构造方法为:
Serializer(instance=None, data=empty, **kwarg)
说明:
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
serializer = AccountSerializer(account, context={'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
使用序列化器的时候一定要注意,序列化器声明了以后,不会自动执行,需要我们在视图中进行调用才可以。
序列化器无法直接接收数据,需要我们在视图中创建序列化器对象时把使用的数据传递过来。
序列化器的字段声明类似于我们前面使用过的表单系统。
开发restful api时,序列化器会帮我们把模型数据转换成字典.
drf提供的视图会帮我们把字典转换成json,或者把客户端发送过来的数据转换字典.
序列化器的使用
序列化器的使用分两个阶段:
在客户端请求时,使用序列化器可以完成对数据的反序列化。
在服务器响应时,使用序列化器可以完成对数据的序列化。
序列化demo:
drf-url:
from django.contrib import admin
from django.urls import path, include urlpatterns = [
path('admin/', admin.site.urls),
path('api/', include("demo1.urls")),
path('ser/', include("ser.urls")),
]
ser-url:
from django.urls import path, re_path
from . import views
urlpatterns = [
path("books/",views.BookInfoView.as_view()), ]
views:
from django.http import JsonResponse
from django.shortcuts import render
from django.views import View
from demo1.models import BookInfo from .serializers import BookInfoSerializer
class BookInfoView(View):
def get(self,request):
# 操作数据库
books = BookInfo.objects.all()
# 创建序列化器对象
# 参数1: instance=要序列化的模型数据
# 参数2: data=要反序列化器的字典数据
# 参数3: many= 是否要序列化多个模型数据,多条数据many=True,默认一条数据
# 参数4: context=序列化器使用的上下文,字典类型数据,可以通过context把视图中的数据,传递给序列化器内部使用
serializer = BookInfoSerializer(instance=books, many=True) # 通过 serializer.data 获取序列化完成以后的数据
print(serializer.data)
# 返回数据
return JsonResponse(serializer.data, safe=False)
serialize:
###############################################################################################################################
# 1. 序列化器的序列化阶段使用
###############################################################################################################################
from rest_framework import serializers
class BookInfoSerializer(serializers.Serializer):
# # 自定义要序列化的字段
id = serializers.IntegerField(label="主键ID",read_only=True)
btitle=serializers.CharField(label="图书标题")
bpub_date = serializers.DateField(label="出版日期")
bread=serializers.IntegerField(label="阅读量")
bcomment=serializers.IntegerField(label="评论量")
is_delete=serializers.BooleanField(label="逻辑删除")
反序列化定义:
序列化的表格可以和反序列化的表公用,而且反序列化的表更加强大,因为还能验证数据,所以一般只保留反序列化的序列化表,不过对于一些只读的字段,可添加read_only 字段选项来避免
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。
验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
反序列化demo:
drf-url:
from django.contrib import admin
from django.urls import path, include urlpatterns = [
path('admin/', admin.site.urls),
# path('api/', include("demo1.urls")),
path('ser/', include("ser.urls")),
]
ser-urls:
from django.urls import path, re_path
from . import views
urlpatterns = [
path("books2/", views.BookInfo2View.as_view()),
re_path("books2/(?P<pk>\d+)/", views.BookInfo2View.as_view()), ]
views:
from django.views import View
from django.http import JsonResponse
from django.http import QueryDict
from .serializers import BookInfo2Serializer
from demo1.models import BookInfo ###############################################################################################################################
# 2 序列化器的反序列化阶段使用
# 主要用户验证数据和字典数据转换成模型
# 为了保证测试顺利进行,我们在settings.py中关闭 csrf的中间件
# 'django.middleware.csrf.CsrfViewMiddleware',
############################################################################################################################### class BookInfo2View(View):
def get(self,request):
# 操作数据库
books = BookInfo.objects.all()
# 创建序列化器对象
# 参数1: instance=要序列化的模型数据
# 参数2: data=要反序列化器的字典数据
# 参数3: many= 是否要序列化多个模型数据,多条数据many=True,默认一条数据
# 参数4: context=序列化器使用的上下文,字典类型数据,可以通过context把视图中的数据,传递给序列化器内部使用
serializer = BookInfo2Serializer(instance=books, many=True) # 通过 serializer.data 获取序列化完成以后的数据
print(serializer.data)
# 返回数据
return JsonResponse(serializer.data, safe=False) def post(self, request):
"""添加一本图书"""
# 接受数据
data = request.POST
# 反序列化
serializer = BookInfo2Serializer(data=data)
# 1. 验证数据
# raise_exception=True 把验证的错误信息返回给客户端,同时阻止程序继续往下执行
serializer.is_valid(raise_exception=True)
# is_valid调用验证方式: 字段选项validators->自定义验证方法[单字段]->自定义验证方法[多字段]
# 验证成功后的数据
# print(serializer.validated_data) # 2. 转换数据成模型,同步到数据库中
result = serializer.save() # save会自动调用序列化器类里面声明的create/update方法,返回值是当前新增/更新的模型对象 # 响应数据
return JsonResponse(serializer.data) def put(self,request,pk):
"""更新一个图书"""
# 根据id主键获取指定图书信息
instance=BookInfo.objects.get(pk=pk)
data = QueryDict(request.body) # 使用序列化器完成验证和反序列化过程
# partial=True 接下里在反序列化中允许部分数据更新
serializer = BookInfo2Serializer(instance=instance,data=data,partial=True)
serializer.is_valid(raise_exception=True) # save之所以可以自动识别,什么时候执行create ,什么时候执行update
# 主要是看创建序列化器对象时,是否有传入instance参数,
# 有instance参数,则save会调用序列化器内部的update方法
# 没有instance参数,则save会调用序列化器内部的create方法
result = serializer.save() return JsonResponse(serializer.data)
serialize:
###############################################################################################################################
# 2 序列化器的反序列化阶段使用
# 主要用户验证数据和字典数据转换成模型
###############################################################################################################################
from rest_framework import serializers
from demo1.models import BookInfo # 自定义验证字段选项函数,很少用
def check_btitle(data):
if data=="西厢记":
raise serializers.ValidationError("西厢记也是禁书~")
# 一定要返回数据
return data class BookInfo2Serializer(serializers.Serializer):
# 自定义要反序列化的字段
id = serializers.IntegerField(label="主键ID",read_only=True)
btitle = serializers.CharField(label="标题",required=True,min_length=1,max_length=20,validators=[check_btitle]) #通过validators=[check_btitle,]调用自定义选项函数
bpub_date=serializers.DateField(label="出版日期")
bread=serializers.IntegerField(label="阅读量",min_value=0)
bcomment=serializers.IntegerField(label="评论量",default=0)
# required=False 反序列化时, 当前字段可以不填
is_delete=serializers.BooleanField(label="逻辑删除") # 自定义验证方法[验证单个字段,可以有多个方法]
#写法必须是 def validate_<字段名>(self,data): # data当前字段对应的值
def validate_btitle(self,data):
# 例如,图书名不能是红楼梦
if data=="红楼梦":
# 抛出错误
raise serializers.ValidationError("红楼梦是禁书~")
# 验证方法中,把数据值必须返回给字段,否则字段值为空
return data # 自定义验证方法[验证多个或者所有字段,只能出现一次] 写法必须是validate(self,data)
def validate(self,data): # data 这个是所有字段的内容,字典类型
bread = data.get("bread")
bcomment = data.get("bcomment") if bread>=bcomment:
return data
raise serializers.ValidationError("阅读量小于评论量,数据太假了") def create(self,validated_data):
"""
保存数据,把字典转换成模型
validated_data 客户端提交过来,并经过验证的数据
"""
instance = BookInfo.objects.create(
btitle = validated_data.get("btitle"),
bread = validated_data.get("bread"),
bcomment = validated_data.get("bcomment"),
bpub_date = validated_data.get("bpub_date"),
is_delete = validated_data.get("is_delete"),
)
#返回模型对象
return instance def update(self,instance,validated_data):
"""更新数据
instance 本次更新操作的模型对象
validated_data 客户端提交过来,并经过验证的数据
"""
instance.btitle=validated_data.get('btitle')
instance.bread=validated_data.get('bread')
instance.bcomment=validated_data.get('bcomment')
instance.bpub_date=validated_data.get('bpub_date')
instance.is_delete=validated_data.get('is_delete') # 调用ORM的保存更新操作
instance.save()
# 返回模型对象
return instance
######################################################################################
模型类序列化:相当于modelform组件....用法等
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
ModelSerializer与常规的Serializer相同,但提供了:
基于模型类自动生成一系列字段
基于模型类自动为Serializer生成validators,比如unique_together
包含默认的create()和update()的实现
demo:
views:
###############################################################################################################################
# 3 模型序列化器
# 1. 可以帮我们自动完成字段的声明[主要是从模型中的字段声明里面提取过来]
# 2. 模型序列化器也可以帮我们声明了create和update方法的代码
###############################################################################################################################
from django.views import View
from django.http import JsonResponse
from .serializers import BookInfoModelSerializer
class BookInfo3View(View):
def post(self, request):
data = request.POST
serializer = BookInfoModelSerializer(data=data)
serializer.is_valid(raise_exception=True)
result = serializer.save()
# 响应数据
return JsonResponse(serializer.data) def put(self, request, pk):
"""更新一个图书"""
book = BookInfo.objects.get(pk=pk) # 获取put提交的数据
data = QueryDict(request.body) #允许部分更新partial=True
serializer = BookInfoModelSerializer(instance=book, data=data, partial=True)
serializer.is_valid(raise_exception=True)
serializer.save()
# 响应数据
return JsonResponse(serializer.data)
serialize:
###################################################################################### from rest_framework import serializers
from demo1.models import BookInfo class BookInfoModelSerializer(serializers.ModelSerializer):
class Meta:
model = BookInfo
# fields = ["id", "btitle"]
fields='__all__'
# 可以给模型序列化器里面指定的字段设置限制选项
extra_kwargs = {
"bread": {"min_value": 0, "required": True},
}
def validate_btitle(self,data):
# 例如,图书名不能是红楼梦
if data=="红楼梦":
# 抛出错误
raise serializers.ValidationError("红楼梦是禁书~")
# 验证方法中,把数据值必须返回给字段,否则字段值为空
return data # 自定义验证方法[验证多个或者所有字段,只能出现一次]
def validate(self,data): # data 这个是所有字段的内容,字典类型
bread = data.get("bread")
bcomment = data.get("bcomment") if bread>=bcomment:
return data
raise serializers.ValidationError("阅读量小于评论量,数据太假了")
补充一些参数:
1.常用字段类型:
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format='hex_verbose') format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol='both', unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
2.选项参数:
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
3.通用参数:
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
DRF之简介以及序列化操作的更多相关文章
- DRF框架之Serializer序列化器的序列化操作
在DRF框架中,有两种序列化器,一种是Serializer,另一种是ModelSerializer. 今天,我们就先来学习一下Serializer序列化器. 使用Serializer序列化器的开发步骤 ...
- DRF框架之 serializers 序列化组件
1. 什么是序列化,其实在python中我们就学了序列化工具json工具,就是吧信息存为类字典形式 2. DRF框架自带序列化的工具: serializers 3. DRF框架 serializers ...
- 写写Django中DRF框架概述以及序列化器对象serializer的构造方法以及使用
写写Django中DRF框架概述以及序列化器对象serializer的构造方法以及使用 一.了解什么是DRF DRF: Django REST framework Django REST framew ...
- Ajax(简介、基础操作、计算器,登录验证)
Ajax简介 Ajax 即"Asynchronous Javascript And XML"(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术. ...
- Python json.dumps 特殊数据类型的自定义序列化操作
场景描述: Python标准库中的json模块,集成了将数据序列化处理的功能:在使用json.dumps()方法序列化数据时候,如果目标数据中存在datetime数据类型,执行操作时, 会抛出异常:T ...
- C# XML序列化操作菜单
鉴于之前写的一篇博文没使用XML序列化来操作菜单,而且发现那还有一个问题,就是在XML菜单的某个菜单节点前加上一些注释代码的就不能读取,现在使用XML序列化后可以很方便的读取,故在此写一写. XM ...
- Java 持久化之 --io流与序列化操作
1)File类操作文件的属性 1.File类的常用方法 1. 文件的绝对完整路径:getAbsolutePath() 文件名:getName() 文件相对路径:getPath() 文件的上一级目录:g ...
- Asp.Net Core 2.0 项目实战(8)Core下缓存操作、序列化操作、JSON操作等Helper集合类
本文目录 1. 前沿 2.CacheHelper基于Microsoft.Extensions.Caching.Memory封装 3.XmlHelper快速操作xml文档 4.Serializatio ...
- Django(八)下:Model操作和Form操作、序列化操作
二.Form操作 一般会创建forms.py文件,单独存放form模块. Form 专门做数据验证,而且非常强大.有以下两个插件: fields :验证(肯定会用的) widgets:生成HTML(有 ...
随机推荐
- loj#2510. 「AHOI / HNOI2018」道路 记忆化,dp
题目链接 https://loj.ac/problem/2510 思路 f[i][a][b]表示到i时,公路个数a,铁路个数b 记忆化 复杂度=状态数=\(nlog^2n\) 代码 #include ...
- 微生物增殖|2012年蓝桥杯B组题解析第一题-fishers
(3')微生物增殖 假设有两种微生物 X 和 Y X出生后每隔3分钟分裂一次(数目加倍),Y出生后每隔2分钟分裂一次(数目加倍). 一个新出生的X,半分钟之后吃掉1个Y,并且,从此开始,每隔1分钟吃1 ...
- X-Pack for the Elastic Stack [6.2] » Securing the Elastic Stack »Setting Up User Authentication
https://www.elastic.co/guide/en/x-pack/current/setting-up-authentication.html Active Directory User ...
- Graph Convolutional Networks (GCNs) 简介
Graph Convolutional Networks 2018-01-16 19:35:17 this Tutorial comes from YouTube Video:https://www ...
- 使用 node 创建代码服务器
var express = require('express'); var proxy = require('http-proxy-middleware'); var app = express(); ...
- Lintcode214-Max of Array-Naive
Given an array with couple of float numbers. Return the max value of them. Example Example 1: Input: ...
- ERP系统知识笔记
中心思想: 1.不管哪一家的ERP系统,都是以“平衡供需”为目的.以计划为中心思想的,并将各管理职能作紧密的集成 2.手工管理方式下,对库存量的掌握是不完整的.手工方式下,我们的数据只有现存量,无法记 ...
- mysql5.7.23手动配置安装windows版
1.mysql下载地址 官网:https://dev.mysql.com/downloads/mysql/5.7.html#downloads 官网我下载的是: 百度网盘:链接: https://pa ...
- OpenModelica Debug
assertion只触发一次 The gdb process has not responded to a command within 40 second(s).This could mean it ...
- 学习笔记20—MATLAB特殊函数
1.qfunc就是Q函数 2.mae(平均绝对误差)函数,mae(abs(A-B)) 3.Z = zscore(x) 等价于 Z=(X-repmat(mean(X),57,1))./repmat(st ...