scrapy 爬虫框架之持久化存储
scrapy 持久化存储
一.主要过程:
以爬取校花网为例 :
http://www.xiaohuar.com/hua/
1. spider
回调函数 返回item 时 要用yield item 不能用return item
爬虫 xiahua.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import XiaohuaItem class XiahuaSpider(scrapy.Spider):
name = 'xiahua' # 该名字 启动爬虫: scrapy crawl xiaohua --nolog
allowed_domains = ['xiaohuar.com']
start_urls = ['http://www.xiaohuar.com/hua/'] # 起始url列表 # 默认的回调函数
def parse(self, response):
# 进行解析
# print(response.text)
items=response.xpath('//*[@id="list_img"]/div/div[1]/div/div/div[1]')
# 持久化存储 for tag in items:
dic={}
name=tag.xpath("./span[1]/text()").extract_first()
url=tag.xpath("./a[1]/@href").extract_first()
if name: # 姓名存在是存入数据库
item = XiaohuaItem()
dic["name"] = name
dic["url"]=url
item['name']=name
item['url']=url
print(dic) yield item # 需要注意的: 不能是 return item
2. items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class XiaohuaItem(scrapy.Item):
# define the fields for your item here like:
name=scrapy.Field()
url=scrapy.Field()
3.pipeline.py
1. 到settings 中 :
(1)ROBOTSTXT_OBEY = False # 改为Flase
(2)放开 ITEM_PIPELINES和修改机器人协议
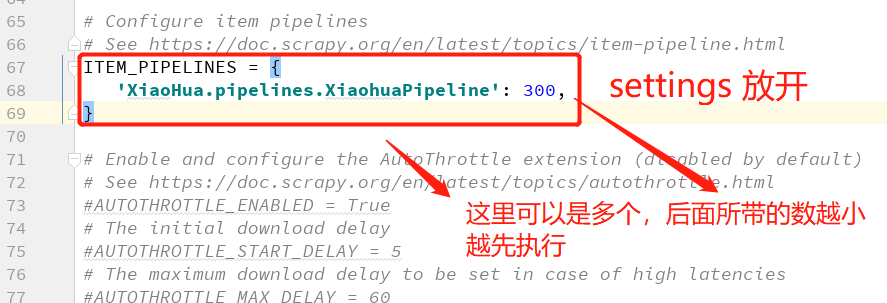
2. 数据持久化储存:
方式一: 不去配置文件取值的方式:
存数据库之前,先启动数据库服务端
必须先将item对象转化为字典 dict(item) 存入数据库
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo class XiaohuaPipeline(object):
def __init__(self):
self.client=None
self.db=None def process_item(self, item, spider): # 持久化储存
#将数据存入数据库 self.db.xiahua.insert(dict(item)) # 必须先将item对象转化为字典 return item def open_spider(self,spider):
# 爬虫开始 打开数据库
# 连接MongoDB服务端
self.client = pymongo.MongoClient(host="localhost",port=27017)
# 连接数据库
self.db = self.client.spider print("爬虫开始-------") def close_spider(self,spider): # 关闭数据库
print('爬虫结束-----') self.client.close()
方式二 : 数据库配置到配置文件中的写法:
用到 类中的一个函数,如果该类是先找 ,自己是否定义了 from_crawler 类方法,
如果有自定义,则先执行该类方法,实例化一个对象。然后再执行 __init__ 方法。
1. settings.py 文件中配置以下信息:
### Mongdb配置参数 HOST="127.0.0.1"
PORT=27017
USER="root"
PWD=""
DB="spider"
2. pipeline.py 中增加 类方法 from_crawler
# -*- coding: utf-8 -*-
import pymongo
class XiaohuaPipeline(object):
@classmethod
def from_crawler(cls, crawler):
"""
Scrapy会先通过getattr判断我们是否自定义了from_crawler,有则调它来完
成实例化
"""
HOST = crawler.settings.get('HOST')
PORT = crawler.settings.get('PORT')
USER = crawler.settings.get('USER')
PWD = crawler.settings.get('PWD')
return cls(HOST, PORT, USER, PWD) # 返回实例化对象
def __init__(self, host, port, user, pwd):
self.host = host
self.port = port
self.user = user
self.pwd = pwd
self.db = None
def process_item(self, item, spider):
#将数据存入数据库
print(type(dict(item)))
self.db.xiahua.insert_one(dict(item)) # xiahua 为文档名(表名)
return item
def open_spider(self,spider):
# 爬虫开始 打开数据库
# 连接MongoDB服务端
self.client = pymongo.MongoClient(host=self.host,port=self.port)
# 连接数据库
self.db = self.client.spider
print("爬虫开始-------")
def close_spider(self,spider):
# 关闭数据库
print('爬虫结束-----')
self.client.close()
总结:
1. 先找 from_crawl 类方法, 有就先执行该该方法,返回一个实例化对象,再执行 __init__ 方法。
2. pipeline 类下,主要有5中方法:
from_crawl : 实例化一个对象 返回 # 该方法 去配置文件中取值时需要写
__init__ : 初始化
open_spider 爬虫开始 时执行 ( 数据库开启)
process_item 持久化存储 处理 (存数据)
close_spider 爬虫结束执行 (数据库关闭)
scrapy 爬虫框架之持久化存储的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
随机推荐
- 远程调试Spring项目
目录 服务端启动: 启动jar包: 使用环境变量参数调试jar包: 使用mvnDebug启动SpringMVC项目: 使用mvn启动: 使用Tomcat,非嵌入式启动: 客户端设置: IDEA设置: ...
- (转)WebSocket学习
石墨文档:https://shimo.im/docs/3UkyOPJvmj4f9EAP/ (二期)17.即时通讯技术websocket [课程17]java We...实现.xmind0.1MB [课 ...
- C语言变量的作用域和存储类型
1.动态局部变量:也称局部变量.自动变量,是指在函数内部定义的自动变量,不带static修饰,作用域是定义该变量的子程序.在退出函数后,变量自带内存会自动释放. 2.静态局部变量:是指在函数内部定义的 ...
- 论文笔记:Capsules for Object Segmentation
Capsules for Object Segmentation 2018-04-16 21:49:14 Introduction: ----
- 深度学习课程笔记(二)Classification: Probility Generative Model
深度学习课程笔记(二)Classification: Probility Generative Model 2017.10.05 相关材料来自:http://speech.ee.ntu.edu.tw ...
- (zhuan) 大牛讲堂 | 算法工程师入门第二期-穆黎森讲增强学习
大牛讲堂 | 算法工程师入门第二期-穆黎森讲增强学习 2017-07-13 HorizonRobotics
- SHOI 2017 相逢是问候(扩展欧拉定理+线段树)
题意 https://loj.ac/problem/2142 思路 一个数如果要作为指数,那么它不能直接对模数取模,这是常识: 诸如 \(c^{c^{c^{c..}}}\) 的函数递增飞快,不是高精度 ...
- VHDL 例程
以下程序未经仿真,仅供说明 语法 声明参考库ieee,使用ieee中的std_logic_1164包全部条目可见 library ieee; use ieee.std_logic_1164.all; ...
- VHDL 数字时钟设计
序言 这个是我在做FPGA界的HelloWorld--数字钟设计时随手写下的,再现了数字钟设计的过程 目标分析 时钟具有时分秒的显示,需6个数码管.为了减小功耗采用扫描法显示 按键设置时间,需要对按键 ...
- 每天一个小程序—0000题(python图像处理)
第 0000 题: 将你的 QQ 头像(或者微博头像)右上角加上红色的数字,类似于微信未读信息数量那种提示效果. 类似于图中效果 python中的pillow库是专门用于处理图像的. from PIL ...