Deeplab v3+的结构代码简要分析
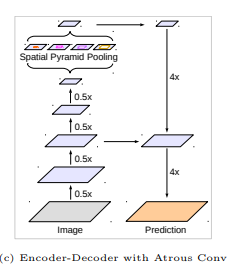
添加了解码模块来重构精确的图像物体边界。对比如图
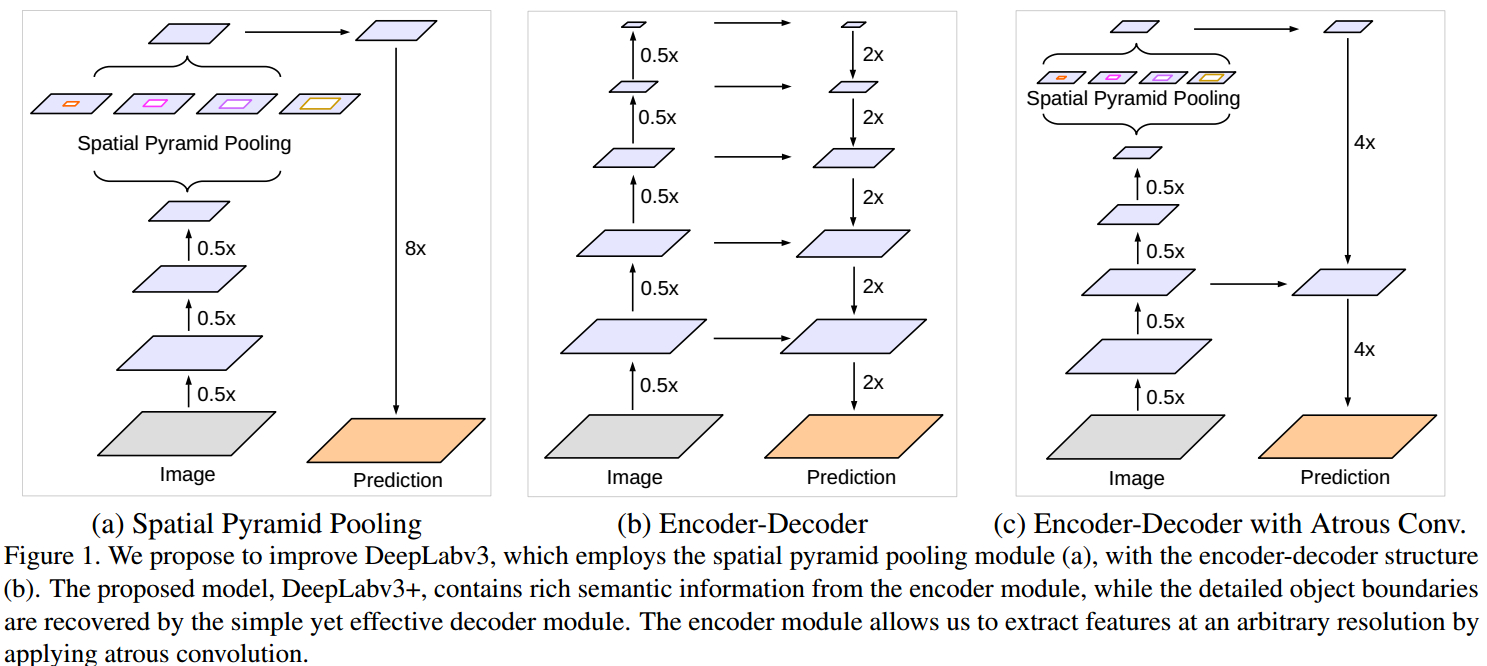
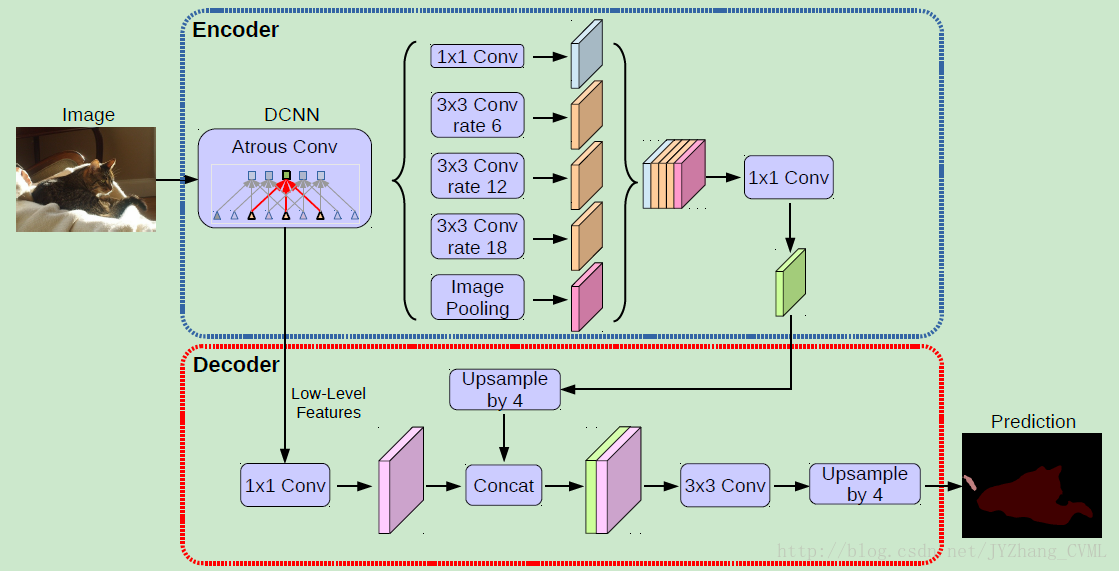
deeplab v3+采用了与deeplab v3类似的多尺度带洞卷积结构ASPP,然后通过上采样,以及与不同卷积层相拼接,最终经过卷积以及上采样得到结果。
deeplab v3:
基于提出的编码-解码结构,可以任意通过控制 atrous convolution 来输出编码特征的分辨率,来平衡精度和运行时间(已有编码-解码结构不具有该能力.).
可以用来挖掘不同尺度的上下文信息
PSPNet 对不同尺度的网络进行池化处理,处理多尺度的上下文内容信息
deeplab v3+以resnet101为backbone
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
from modeling.sync_batchnorm.batchnorm import SynchronizedBatchNorm2d BatchNorm2d = SynchronizedBatchNorm2d class Bottleneck(nn.Module):
#'resnet网络的基本框架’
expansion = def __init__(self, inplanes, planes, stride=, dilation=, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=, bias=False)
self.bn1 = BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=, stride=stride,
dilation=dilation, padding=dilation, bias=False)
self.bn2 = BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * , kernel_size=, bias=False)
self.bn3 = BatchNorm2d(planes * )
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.dilation = dilation def forward(self, x):
residual = x out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out) out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out) out = self.conv3(out)
out = self.bn3(out) if self.downsample is not None:
residual = self.downsample(x) out += residual
out = self.relu(out) return out class ResNet(nn.Module):
#renet网络的构成部分
def __init__(self, nInputChannels, block, layers, os=, pretrained=False):
self.inplanes =
super(ResNet, self).__init__()
if os == :
strides = [, , , ]
dilations = [, , , ]
blocks = [, , ]
elif os == :
strides = [, , , ]
dilations = [, , , ]
blocks = [, , ]
else:
raise NotImplementedError # Modules
self.conv1 = nn.Conv2d(nInputChannels, , kernel_size=, stride=, padding=,
bias=False)
self.bn1 = BatchNorm2d()
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=, stride=, padding=) self.layer1 = self._make_layer(block, , layers[], stride=strides[], dilation=dilations[])
self.layer2 = self._make_layer(block, , layers[], stride=strides[], dilation=dilations[])
self.layer3 = self._make_layer(block, , layers[], stride=strides[], dilation=dilations[])
self.layer4 = self._make_MG_unit(block, , blocks=blocks, stride=strides[], dilation=dilations[]) self._init_weight() if pretrained:
self._load_pretrained_model() def _make_layer(self, block, planes, blocks, stride=, dilation=):
downsample = None
if stride != or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=, stride=stride, bias=False),
BatchNorm2d(planes * block.expansion),
) layers = []
layers.append(block(self.inplanes, planes, stride, dilation, downsample))
self.inplanes = planes * block.expansion
for i in range(, blocks):
layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def _make_MG_unit(self, block, planes, blocks=[, , ], stride=, dilation=):
downsample = None
if stride != or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=, stride=stride, bias=False),
BatchNorm2d(planes * block.expansion),
) layers = []
layers.append(block(self.inplanes, planes, stride, dilation=blocks[]*dilation, downsample=downsample))
self.inplanes = planes * block.expansion
for i in range(, len(blocks)):
layers.append(block(self.inplanes, planes, stride=, dilation=blocks[i]*dilation)) return nn.Sequential(*layers) def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x) x = self.layer1(x)
low_level_feat = x
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x, low_level_feat def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[] * m.kernel_size[] * m.out_channels
m.weight.data.normal_(, math.sqrt(. / n))
elif isinstance(m, BatchNorm2d):
m.weight.data.fill_()
m.bias.data.zero_() def _load_pretrained_model(self):
pretrain_dict = model_zoo.load_url('https://download.pytorch.org/models/resnet101-5d3b4d8f.pth')
model_dict = {}
state_dict = self.state_dict()
for k, v in pretrain_dict.items():
if k in state_dict:
model_dict[k] = v
state_dict.update(model_dict)
self.load_state_dict(state_dict) def ResNet101(nInputChannels=, os=, pretrained=False):
model = ResNet(nInputChannels, Bottleneck, [, , , ], os, pretrained=pretrained)
return model class ASPP_module(nn.Module):
#ASpp模块的组成
def __init__(self, inplanes, planes, dilation):
super(ASPP_module, self).__init__()
if dilation == :
kernel_size =
padding =
else:
kernel_size =
padding = dilation
self.atrous_convolution = nn.Conv2d(inplanes, planes, kernel_size=kernel_size,
stride=, padding=padding, dilation=dilation, bias=False)
self.bn = BatchNorm2d(planes)
self.relu = nn.ReLU() self._init_weight() def forward(self, x):
x = self.atrous_convolution(x)
x = self.bn(x) return self.relu(x) def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[] * m.kernel_size[] * m.out_channels
m.weight.data.normal_(, math.sqrt(. / n))
elif isinstance(m, BatchNorm2d):
m.weight.data.fill_()
m.bias.data.zero_() class DeepLabv3_plus(nn.Module):
#正式开始deeplabv3+的结构组成
def __init__(self, nInputChannels=, n_classes=, os=, pretrained=False, freeze_bn=False, _print=True):
if _print:
print("Constructing DeepLabv3+ model...")
print("Backbone: Resnet-101")
print("Number of classes: {}".format(n_classes))
print("Output stride: {}".format(os))
print("Number of Input Channels: {}".format(nInputChannels))
super(DeepLabv3_plus, self).__init__() # Atrous Conv 首先获得从resnet101中提取的features map
self.resnet_features = ResNet101(nInputChannels, os, pretrained=pretrained) # ASPP,挑选参数
if os == :
dilations = [, , , ]
elif os == :
dilations = [, , , ]
else:
raise NotImplementedError
#四个不同带洞卷积的设置,获取不同感受野
self.aspp1 = ASPP_module(, , dilation=dilations[])
self.aspp2 = ASPP_module(, , dilation=dilations[])
self.aspp3 = ASPP_module(, , dilation=dilations[])
self.aspp4 = ASPP_module(, , dilation=dilations[]) self.relu = nn.ReLU()
#全局平均池化层的设置
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((, )),
nn.Conv2d(, , , stride=, bias=False),
BatchNorm2d(),
nn.ReLU()) self.conv1 = nn.Conv2d(, , , bias=False)
self.bn1 = BatchNorm2d() # adopt [1x1, ] for channel reduction.
self.conv2 = nn.Conv2d(, , , bias=False)
self.bn2 = BatchNorm2d()
#结构图中的解码部分的最后一个3*3的卷积块
self.last_conv = nn.Sequential(nn.Conv2d(, , kernel_size=, stride=, padding=, bias=False),
BatchNorm2d(),
nn.ReLU(),
nn.Conv2d(, , kernel_size=, stride=, padding=, bias=False),
BatchNorm2d(),
nn.ReLU(),
nn.Conv2d(, n_classes, kernel_size=, stride=))
if freeze_bn:
self._freeze_bn()
#前向传播
def forward(self, input):
x, low_level_features = self.resnet_features(input)
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = self.global_avg_pool(x)
x5 = F.upsample(x5, size=x4.size()[:], mode='bilinear', align_corners=True)
#把四个ASPP模块以及全局池化层拼接起来
x = torch.cat((x1, x2, x3, x4, x5), dim=)
#上采样
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = F.upsample(x, size=(int(math.ceil(input.size()[-]/)),
int(math.ceil(input.size()[-]/))), mode='bilinear', align_corners=True) low_level_features = self.conv2(low_level_features)
low_level_features = self.bn2(low_level_features)
low_level_features = self.relu(low_level_features) #拼接低层次的特征,然后再通过插值获取原图大小的结果
x = torch.cat((x, low_level_features), dim=)
x = self.last_conv(x)
x = F.interpolate(x, size=input.size()[:], mode='bilinear', align_corners=True) return x def _freeze_bn(self):
for m in self.modules():
if isinstance(m, BatchNorm2d):
m.eval() def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[] * m.kernel_size[] * m.out_channels
m.weight.data.normal_(, math.sqrt(. / n))
elif isinstance(m, BatchNorm2d):
m.weight.data.fill_()
m.bias.data.zero_() def get_1x_lr_params(model):
"""
This generator returns all the parameters of the net except for
the last classification layer. Note that for each batchnorm layer,
requires_grad is set to False in deeplab_resnet.py, therefore this function does not return
any batchnorm parameter
"""
b = [model.resnet_features]
for i in range(len(b)):
for k in b[i].parameters():
if k.requires_grad:
yield k def get_10x_lr_params(model):
"""
This generator returns all the parameters for the last layer of the net,
which does the classification of pixel into classes
"""
b = [model.aspp1, model.aspp2, model.aspp3, model.aspp4, model.conv1, model.conv2, model.last_conv]
for j in range(len(b)):
for k in b[j].parameters():
if k.requires_grad:
yield k if __name__ == "__main__":
model = DeepLabv3_plus(nInputChannels=, n_classes=, os=, pretrained=True, _print=True)
model.eval()
image = torch.randn(, , , )
with torch.no_grad():
output = model.forward(image)
print(output.size())
Deeplab v3+的结构代码简要分析的更多相关文章
- Deeplab v3+的结构的理解,图像分割最新成果
Deeplab v3+ 结构的精髓: 1.继续使用ASPP结构, SPP 利用对多种比例(rates)和多种有效感受野的不同分辨率特征处理,来挖掘多尺度的上下文内容信息. 解编码结构逐步重构空间信息来 ...
- tolua#代码简要分析
简介 tolua#是Unity静态绑定lua的一个解决方案,它通过C#提供的反射信息分析代码并生成包装的类.它是一个用来简化在C#中集成lua的插件,可以自动生成用于在lua中访问Unity的绑定代码 ...
- Deeplab v3+中的骨干模型resnet(加入atrous)的源码解析,以及普通resnet整个结构的构建过程
加入带洞卷积的resnet结构的构建,以及普通resnet如何通过模块的组合来堆砌深层卷积网络. 第一段代码为deeplab v3+(pytorch版本)中的基本模型改进版resnet的构建过程, 第 ...
- Uboot优美代码赏析1:目录结构和malkefile分析
Uboot优美代码赏析1:目录结构和malkefile分析 关于Uboot自己选的版本是目前最新的2011.06,官方网址为:http://www.denx.de/wiki/U-Boot/WebHom ...
- Android Hal层简要分析
Android Hal层简要分析 Android Hal层(即 Hardware Abstraction Layer)是Google开发的Android系统里上层应用对底层硬件操作屏蔽的一个软件层次, ...
- RxJava && Agera 从源码简要分析基本调用流程(2)
版权声明:本文由晋中望原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/124 来源:腾云阁 https://www.qclo ...
- CVPR2018 关于视频目标跟踪(Object Tracking)的论文简要分析与总结
本文转自:https://blog.csdn.net/weixin_40645129/article/details/81173088 CVPR2018已公布关于视频目标跟踪的论文简要分析与总结 一, ...
- 转:InnoDB多版本(MVCC)实现简要分析
InnoDB多版本(MVCC)实现简要分析 基本知识 假设对于多版本(MVCC)的基础知识,有所了解.InnoDB为了实现多版本的一致读,采用的是基于回滚段的协议. 行结构 InnoDB表数据的组织方 ...
- java AST JCTree简要分析
JCTree简要分析 [toc] JCAnnotatedType 被注解的泛型:(注解的Target为ElementType.TYPE_USE时可注解泛型) public static class A ...
随机推荐
- {MySQL的逻辑查询语句的执行顺序}一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析
MySQL的逻辑查询语句的执行顺序 阅读目录 一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析 一 SEL ...
- [No0000CF]想有一辈子花不完的钱?从了解“被动收入”开始吧
我想从理清自己所说被动收入的含义,开始创作此被动收入系列文章. 我更喜欢把被动收入较宽泛地定义为,甚至当你没有主动工作时,仍可赚取的收益.被动收入的另一个名称是剩余收入. 相比之下,当你停止工作时,通 ...
- C和C指针小记(六)-基本声明、指针声明、typedef 、常量、作用域、链接属性、存储类型、static
1.变量的声明 声明变量的基本形式: 说明符号(一个或者多个) 声明表达式列表 说明符 (specifier) 包含一些关键字,用于描述被声明的标识符的基本类型,它也可用户改变标识符的缺省存储类型和作 ...
- PCI 设备调试手段
Author: Younix Platform: RK3399 OS: Android 6.0 Kernel: 4.4 Version: v2017.04 一PCI 设备调试手段 busybox ls ...
- 最全的MonkeyRunner自动化测试从入门到精通(1)
一.环境变量的配置 1.JDK环境变量的配置 步骤一:在官网上面下载jdk,JDK官网网址: http://www.oracle.com/technetwork/java/javase/downloa ...
- Java如何编写Servlet程序
一:Servlet Servlet是Java服务器端编程,不同于一般的Java应用程序,Servlet程序是运行在服务器上的,服务器有很多种,Tomcat只是其中一种. 例子: 在Eclipse中新建 ...
- 洛谷 P3521 ROT-Tree Rotations [POI2011] 线段树
正解:线段树合并 解题报告: 传送门! 今天学了下线段树合并,,,感觉线段树相关的应用什么的还是挺有趣的,今天晚上可能会整理一下QAQ? 然后直接看这道题 现在考虑对一个节点nw,现在已经分别处理出它 ...
- Vue双向数据绑定原理分析(转)
add by zhj: 目前组里使用的是前端技术是jQuery + Bootstrap,后端使用的Django,Flask等,模板是在后端渲染的.前后端没有分离,这种做法有几个缺点 1. 模板一般是由 ...
- 第四章:初识CSS3
1.CSS规则由两部分构成,即选择器和声明器 声明必须放在{}中并且声明可以是一条或者多条 每条声明由一个属性和值构成,属性和值用冒号分开,每条语句用英文冒号分开 注意: css的最后一条声明,用以结 ...
- BeanFactoryPostProcessor vs BeanPostProcessor
BeanFactoryPostProcessors affect BeanDefinition objects because they are run right after your config ...